
[SUMMARY]
다중회귀분석 표본 수 산출하기
[다중회귀분석]
(Multiple Regression Analysis)
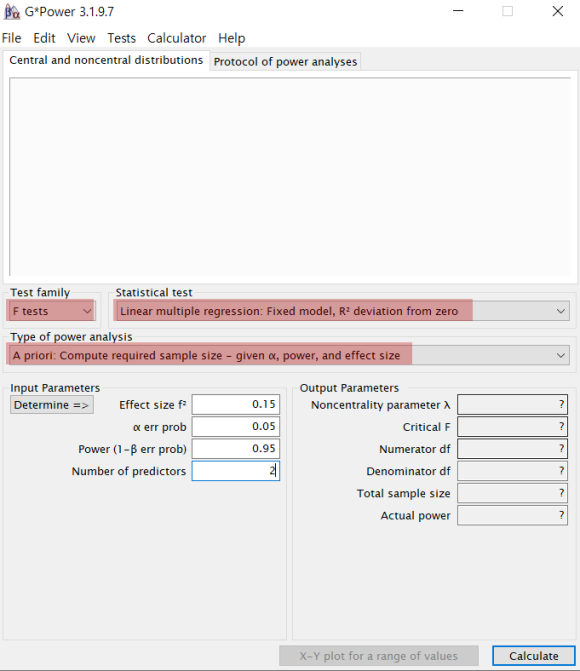
g-power 프로그램에서 위에 사진과 같이 3번째 영역까지 설정한다.
1) Test family ▶ F tests
2) Statistical test ▶ Linear multiple regression ~ from zero
3) Type of power analysis ▶ A priori: ~ effect size이렇게 설정하면,
f 검정 중에서도 다중회귀분석의 표본 수를 산출한다는 뜻이다.이제 4번째 Input parameters 영역을 살펴보자.
이 부분은 연구자가 선행 논문 등을 참고하여각자의 연구 설계에 맞게 설정하면 된다.
※ 출처:
복막 투석 환자의 사회적 지지, 피로 및 우울이 삶의 질에 미치는 영향 13p, 14p
(정지혜, 2022)
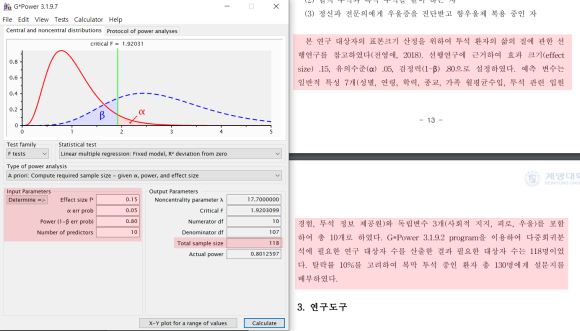
1) Effect size f2 ▶ 0.15
2) α err prob ▶ 0.05
3) Power(1-β err prob) ▶ 0.80
4) Number of predictors ▶10논문에서 나온 대로 각각
효과크기 0.15, 유의수준 0.05, 검정력 0.80, 예측변수 10개로 기입한다.논문과 마찬가지로 Total sample size 118가 나온다.
아마 여기서 가장 궁금한 부분은 예측되는 독립변수 개수 정하기 일 것 같다.
예측변수 개수는 연구자가 회귀분석에서 독립변수로 설정하여
살펴볼 변수의 개수로 설정하면 될 것 같다.
조절변수나 매개변수가 있으면 이것도 여기에 포함해서 설정값을 정한다.위 논문에서는 일반적인 특성 7개+독립변수 3개 합해서 총 10개의 변수를
회귀분석에서 독립변수로 설정하여 살펴본다고 했다.
그래서 Number of predictors에 10을 기입했다.연구자가 회귀분석으로 살펴볼 종속변수에
영향을 미친다고 예상하는 독립변수의 개수라고 생각하면 되겠다.또한 어떤 변수는 하위 영역으로 나누어져 있기도 하다.
회귀분석에서 나눠져 있는 하위 영역을 각 독립변수로 살펴보는 경우도 있다.
※ 출처:
간호사 직무만족과 이직의도의영향요인 : 경력 닻을 중심으로 22p
(홍정원, 2024)
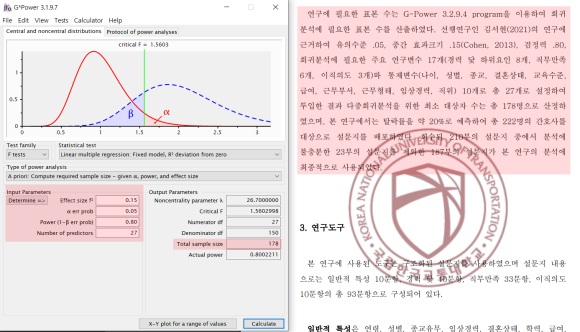
1) Effect size f2 ▶ 0.15
2) α err prob ▶ 0.05
3) Power(1-β err prob) ▶ 0.80
4) Number of predictors ▶27논문에서 나온 대로 각각
효과크기 0.15, 유의수준 0.05, 검정력 0.80, 예측변수 27개로 기입한다.논문과 마찬가지로 Total sample size 178이 나온다.
여기서 예측 독립변수로 설정한 27에 대해 살펴보자.
먼저 연구에서 사용하는 독립변수는 경력 닻, 직무만족, 이직의도 3개이다.이 3개 변수는 각각
경력 닻 하위 영역 8개+직무만족 하위 영역 6개+이직의도 하위 영역 3개
합해서 총 17개로 이루어져 있다.연구자는 이렇게 각 변수의 하위 영역까지도 나눠서
회귀분석의 독립변수로 설정했다.여기에 일반적인 특징 10개까지 합해서 총 27개를
회귀분석에서 예측변수로 설정했다고 이해하면 된다.
