Project Page
arXiv
[Submitted on 13 Jun 2024 (v1), last revised 20 Oct 2024 (this version, v2)]
1. Introduction
⭐ Monocular Depth Estimation(MDE): 하나의 이미지로만 깊이를 추정
3D reconstruction, navigation, autonomous driving 등 다양한 분야에서 사용되고 있다.
MDE는 backbone이 되는 모델 구조에 따라 discriminative model, generative model로 나눌 수 있다.
Discriminative model은 BEiT, DINOv2 기반이고, 대표적인 모델로 Depth Anything이 있다. 빠르지만 투명한 물체와 반사 표면에 약하다.
Generative model은 Stable Diffusion 기반으로, Marigold, ZeroDepth 같은 모델들이 있다. 복잡한 장면도 잘 예측하지만 연산 비용이 높다.
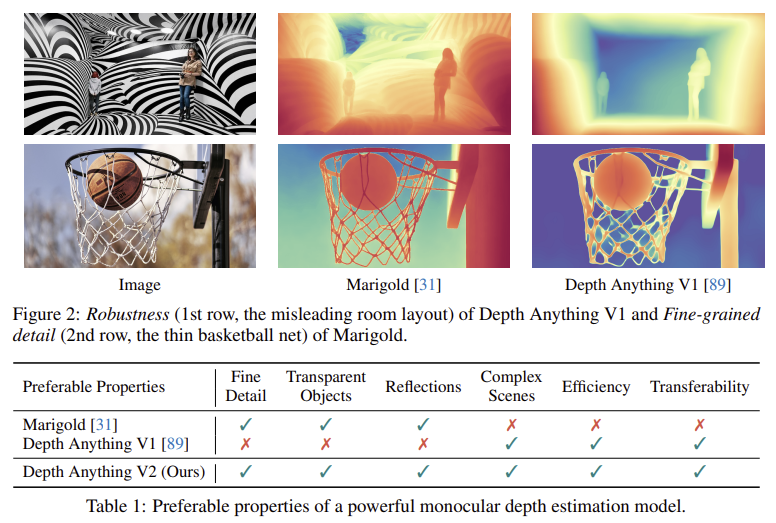
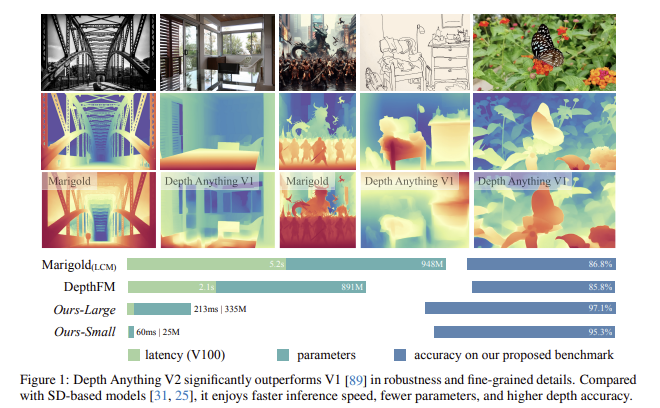
Depth Anything V2는 위 표처럼 기존 MDE 모델들의 단점을 극복하고자 한다.
- 복잡한 장면(투명 물체, 반사 표면)도 잘 처리
- 세밀한 디테일 표현 (ex. 얇은 물체, 작은 구멍)
- 빠른 추론 속도 (경량-대형 모델 제공)
- 다양한 downstream task에 쉽게 적용
2. Revisiting the Labeled Data Design of Depth Anything V1
Depth Anything V1 등 기존 연구들은 거의 real labeled depth map 사용했다.
하지만 real labeled depth map는 깊이 센서의 한계 때문에 깊이 정보가 부정확하고, 디테일이 무시되는 문제가 있다. 이런 데이터를 학습하면 경계선을 정확하게 구별하지 못해서 세밀한 깊이 정보를 예측하는 능력이 저하된다.

Solution
Real label 데이터 대신 detail과 label이 정확한 synthetic 데이터를 사용했다.
위 사진들 보면 (a) real data보다 (b) synthetic data에서 얇은 선이 더 잘 묘사되고 더 디테일하다는걸 볼 수 있다. 그리고 (c)를 보면 가장 우측(synthetic)이 반사 표면도 더 잘 표현한다는 것을 볼 수 있다.
3. Challenges in Using Synthetic Data
그럼 synthetic data가 더 정밀한 정보를 제공하는데 왜 아직 real data를 많이 사용할까?
Synthetic data에는 한계점이 있는데 . .
일단 (1) synthetic과 real 간 distribution shift가 있다. 현실이랑 style, color 분포 등이다르고 이미지가 너무 깔끔하거나 정렬되어 있다. 따라서 real image에 대해 일반화가 어려워서 성능이 저하된다. 또한 (2) Scene coverage가 제한되었다. 대부분의 synthetic data는 그래픽 엔진에서 미리 정의된 장면을 기반으로 생성되는데, 현실은 더 다양한 장면을 포함한다. (ex. 사람 많은 거리 등) 따라서 특정 장면에 대한 학습이 부족한 모델은 실제 복잡한 환경에 대해 일반화되지 않는다.
Synthetic data를 현실에 적용하려면 Synthetic-to-Real 전이학습이 필요하다.
Pilot study

Pre-trained image encoder를 synthetic만 사용해서 MDE로 학습하면 어떻게 되는지 실험을 했는데, 그 결과 DINOv2-G만 만족스러운 결과를 냈다.

하지만 DINOv2-G도 구름이나 사람 머리를 잘 모델링하지 못하는 문제가 있었다.
4. Key Role of Large-Scale Unlabeled Real Images
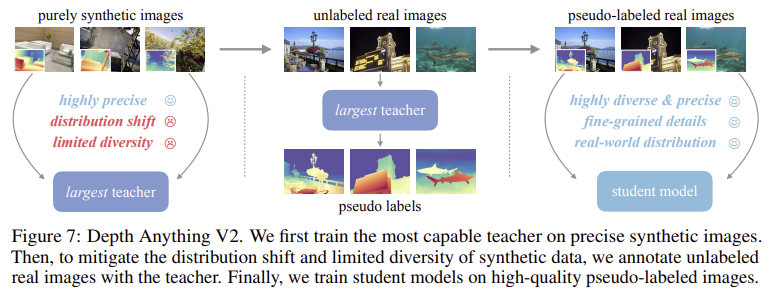
Depth Anything V2는 단순히 synthetic만 사용하지 않고, Unlabeled real image도 활용하여 성능을 높였다.
먼저, synthetic 이미지로만 학습된 DINOv2-G를 backbone으로 한 teacher 모델을 만든다. 이 모델을 통해 unlabeled real 이미지에 pseudo label(예측한 깊이 값)을 생성한다. 이 pseudo labeled real image로 student 모델을 학습시킨다.
이때 Real 데이터는 (1) 도메인 차이를 줄인다. Synthetic 데이터로만 학습한 모델은 실제 이미지에 잘 대응하지 못하는 경우가 많은데, 부여된 pseudo label을 학습에 활용해서 실제 데이터 분포에 익숙해져 일반화 성능이 향상된다. (2) 장면 다양성이 보완된다. 실제 이미지가 더 다양한 환경을 담고 있다. (3) Knowledge transfer. Synthetic 데이터는 대형 모델에 적합해서 작은 모델은 성능이 떨어질 수 있는데, teacher 모델에서 생성한 pseudo label로 student 모델을 학습시켜서 효과적이다.
5. Depth Anything V2
5.1. Overall Framework
1. Synthetic data로 teacher 모델(DINOv2-G) 학습
2. Teacher 모델로 real 이미지에 pseudo label 부여
3. Pseudo labeled real image로 student 모델 학습
→ 더 작은 모델에서도 성능 유지
Depth Anything V2는 다양한 크기(small, base, large, giant)의 4가지 student model이 배포되었다.
5.2. Training Details
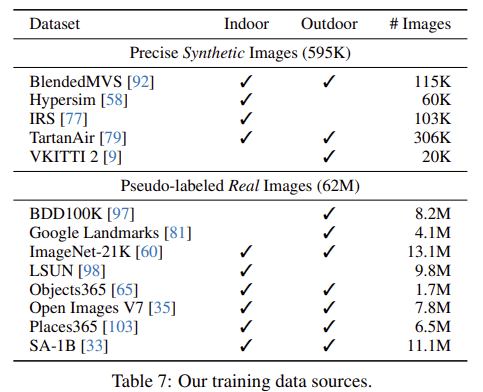
Synthetic data vs. Real data
→ 595K images: 62M images
6. A New Evaluation Benchmark: DA-2K

기존 벤치마크들은 label이 부정확하거나, 장면의 다양성이 제한되거나 해상도가 낮다는 한계가 있었다.
이 한계점들을 보완하기 위해 정확하고 다양한 장면을 포함하는 새로운 벤치마크 DA-2K를 제안했다.
모든 픽셀에 깊이 값을 라벨링하는건 어렵기 때문에, 이미지마다 두 점을 선택해서 어떤 점이 더 가까운지 판단하는 상대 깊이 비교 방식을 사용했다.
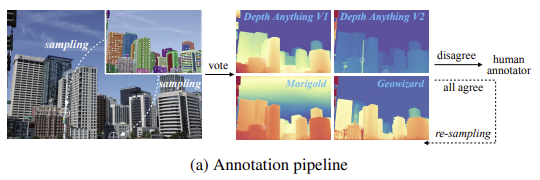
먼저 SAM 모델로 객체 마스크를 예측하고, 그 마스크의 중요한 픽셀을 샘플링한다. 그 다음 깊이 추정 모델 4개(Depth Anything V1, Marigold, GeoWizard, Depth Anything V2)가 두 픽셀 중 어떤 점이 더 가까운지 예측하고 투표한다. 모든 모델의 예측이 일치하면 그대로 사용하고, 예측이 엇갈리면 수동으로 라벨링하거나 re-sampling한다.
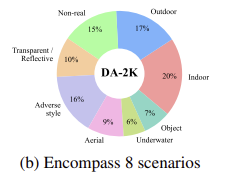
DA-2K는 8가지 다양한 시나리오(Indoor, Transparent...)를 포함하고, GPT-4로 생성한 키워드를 기반으로 Flickr에서 이미지를 수집해 구성되었다.
7. Experiment
7.1. Implementation Details
Model architecture
-
Encoder: DINOv2
-
Depth decoder: DPT
(Depth Anything V1과 동일)
Training details
-
Input image resolution: 518 x 518
-
Teacher model
- batch size: 64- iteration: 16K
-
Student model
- batch size: 192- iteration: 480K
-
Optimizer: Adam
-
Learning rate
- Encoder: , Decoder: -
Weight ratio
- = 1 : 2
7.2. Zero-shot Relative Depth Estimation
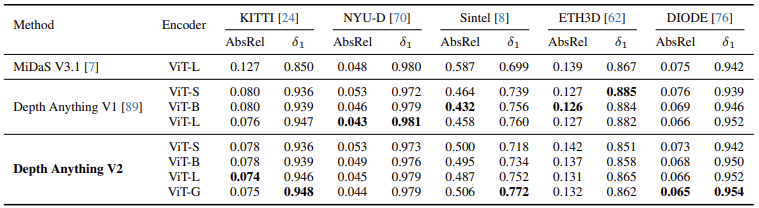
기존 test set(NYU-D, KITTI 등 5개)을 기준으로 MiDaS와 V1을 비교했을 때, V2는 MiDaS보다 우수하고, 대부분 V1과 비슷하거나 살짝 뒤처지는 성능을 보였다.
하지만 V2는 단순 수치가 아니라 디테일을 표현하거나 복잡한 장면, 투명하거나 반사되는 물체를 처리하는 능력 향상에 집중했기 때문에 기존 벤치마크 수치가 절대적인 기준은 아니다.

다양한 실제 장면을 포함한 DA-2K benchmark에서는 가장 작은 모델도 Marigold, GeoWizard 같은 대형 diffusion 기반 모델보다 좋은 성능을 보였다. (Marigold보다 10.6% 높은 정확도)
7.3. Fine-tuned to Metric Depth Estimation
모델의 일반화 성능을 검증하기 위해 MiDas encoder 대신 Depth Anything V2 encoder를 넣어 fine-tuning했다.
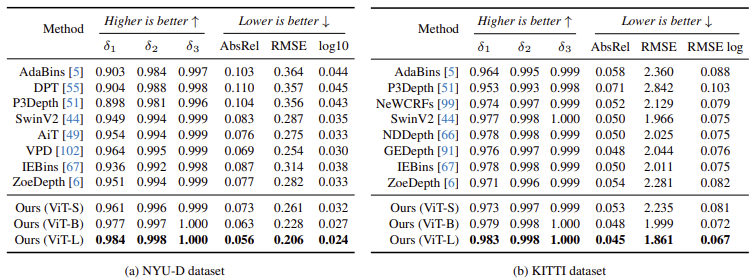
NYU-D, KITTI에서 기존 방식 보다 성능 우수 👍
가장 작은 모델(ViT-S)도 기존 ViT-L 기반보다 높은 성능
7.4. Ablation Study
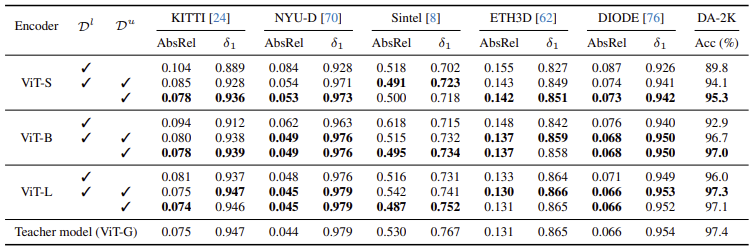
Pseudo label이 있는 real 이미지 에 대한 실험 결과이다. 은 labeled synthetic data이다.
작은 모델(ViT-S, ViT-B)도 합성 데이터 없이, pseudo labeled 데이터만 사용했을 때 더 나은 성능을 보였고, DA-2K 기준으로도 가장 높은 정확도를 기록했다.
