Tintanic 생존 예측 ML
Tintanic ML Report
데이터 엔지니어링 28기
결과
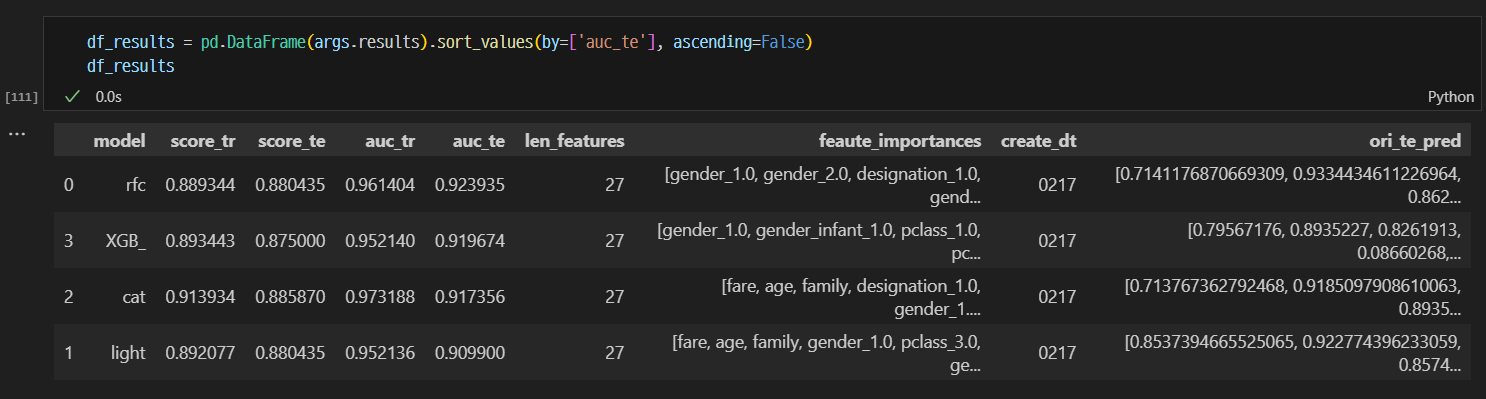
RFC의 Test 결과 confusion matrix
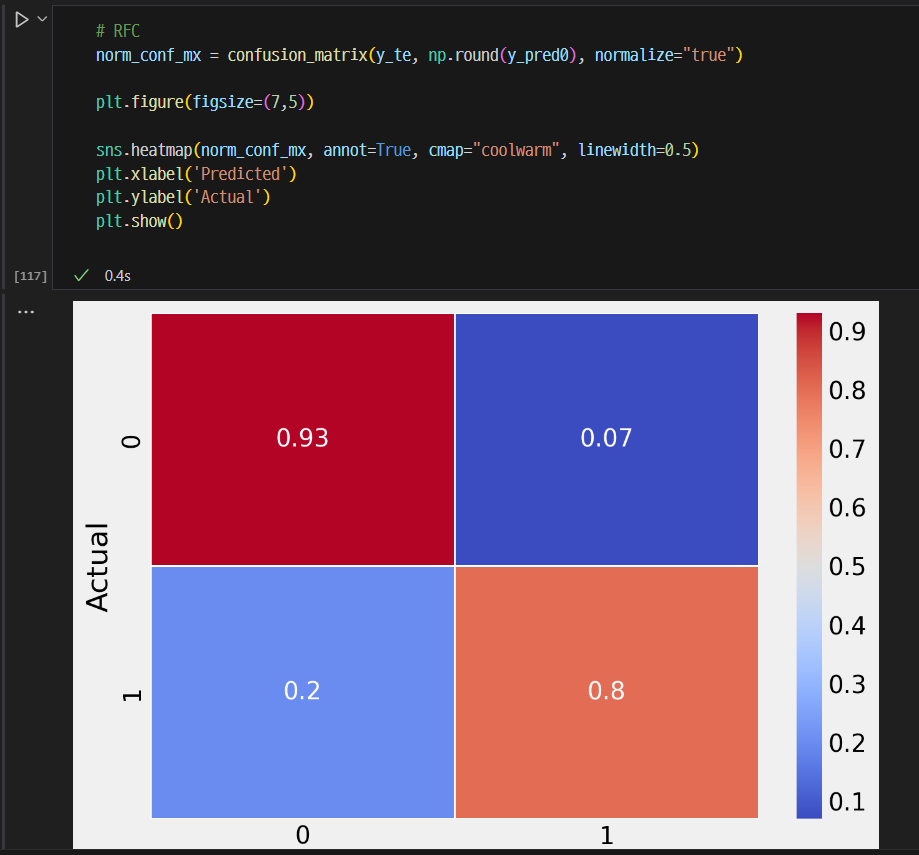
RFC의 Test 결과 confusion matrix
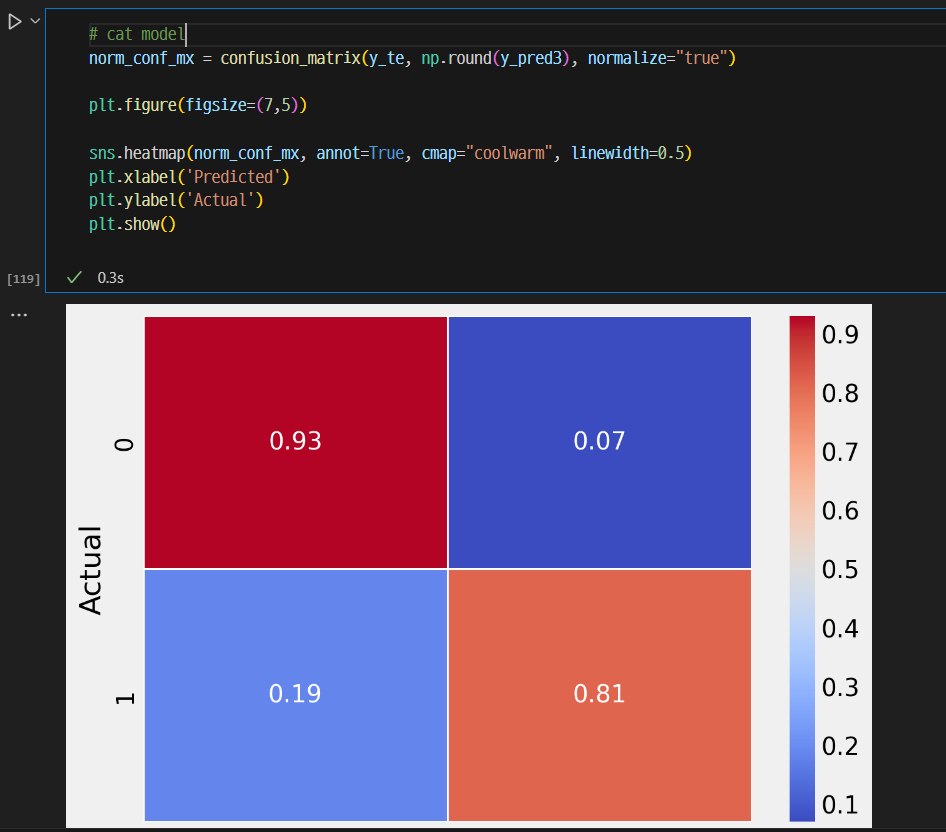
RFC의 Feature importance

Cat의 Feature importance
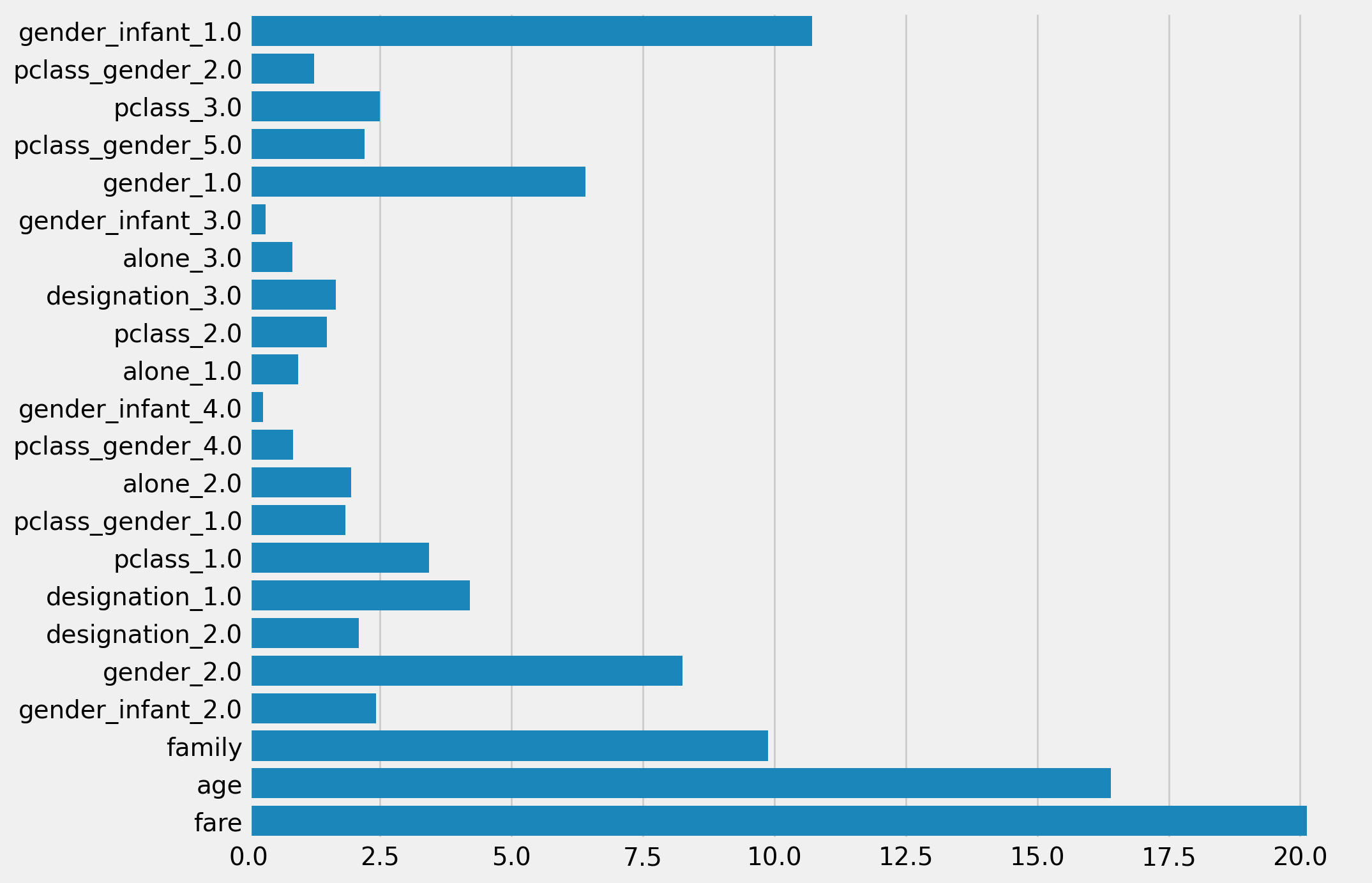
점수를 올리기위한 노력부터 적어보려 한다.
Feature 분석 및 추가
모델이 학습을 잘 시키기 위해서는 좋은 Feature를 분석하고 새로운 Feature 를 추가하는 것이 정말 중요하다. 처음 EDA를 진행했을 때, 생존과 연관이 높은 Feature 2개를 발견하였다. 그것은 gender Pclass였다. 여자의 평균 생존율이 남자에 비하여 상당히 높게 나왔다. 그리고 Pclass에서도 1등석에 탄 승객이 2, 3등석에 탄 승객보다 생존율이 높게 나왔다. 이것은 궁금하여 조금 더 찾아보니 타이타닉호의 설계도에서 1등석은 위쪽에 위치하여 있었고, 3등석은 배 아래 부분에 위치하고 있었다. 다음으로 확인된 것은 age와 fare인데, 이것은 특정 구간에서 생존율이 다른 구간에 비하여 높게 측정된 구간이 몇 개 존재하였다. 그래서 그 구간을 따로 뽑아내고 특정성이 없는 구간은 others로 분류하였다. 이렇게 하나의 Feature에서 특정성을 확인하여 새로운 Feature를 만들어 낼 수도 있지만, 두개의 Feature를 하나로 합쳐 또 다른 Feature를 만들어 낼 수 있었다. 내가 만들어 낸 것 중 하나는 Pclass_gender로 Pclass 3가지와 성별 2가지를 합쳐 특정성이 있는 부분을 찾아내어 새로운 Feature를 만들었다. 특정성이 크지 않은 구간은 마찬가지로 others로 묶어 뒀다.
처음 EDA를 진행했을 때 확인했던 것처럼 gender Pclass가 높은 생존과 직결되는 지표였다. 하지만 모델을 학습 시키고 결과를 확인했을 때, gender Pclass의 중요도가 높게 측정되지 않았었다. 이것을 해결하기 위하여 모델의 Feature별 Weight를 각기 다르게 넣어주어 학습을 진행시키려 했지만, 이 부분에서는 아직 숙련도가 부족하여 진행하지 못하였다. 이것을 해결하기 위하여 이 두 Feature들과 연관된 다른 Feature를 추가로 만들어 주었다. 그 결과 Pclass의 중요도는 크게 증가하지 않았지만, gender 관련된 Feature들은 상당히 증가한 것을 확인할 수 있었다.
코드
name으로 만든 feature
# designation feature를 추가할시 해야할것:
# 위에 feature drop에서 name 지우기, enc cols에 desigantion 추가하기
# 종류가 다양하지만 Mr. Mrs. Miss. 3가지로만 분류했다.
train["name"] = train["name"].map(lambda x: x.strip())
test["name"] = test["name"].map(lambda x: x.strip())
ori_te["name"] = ori_te["name"].map(lambda x: x.strip())
dict_designation = {
'Mr.': '남성',
'Master.': '남성', #남
'Sir.': '남성', #남
'Miss.': '미혼 여성',
'Mrs.': '기혼 여성',
'Ms.': '미혼/기혼 여성',#여 Miss
'Lady.': '숙녀', #여 Miss
'Mlle.': '아가씨',#여 Miss
# 직업
'Dr.': '의사', #남 시대상.
'Rev.': '목사', #남
'Major.': '계급', #남
'Don.': '교수', #남
'Col.': '군인', #남
'Capt.': '군인', #남
# 귀족
'Mme.': '영부인', #여 Mrs.
'Countess.': '백작부인', #여 Mrs.
'Jonkheer.': '귀족' #남
}
Mr = ['Mr.','Master.', 'Sir.', 'Dr.', 'Rev.' ,'Major.', 'Don.' , 'Col.' , 'Capt.']
Miss = ['Miss.', 'Ms.', 'Lady.', 'Mlle.']
Mrs = ['Mrs.', 'Mme.','Countess.', 'Jonkheer.' ]
#위의 호칭중 없는것이 있다면 Miss으로 대체
#호칭함수
def add_designation(name):
designation = "Miss."
for i in Mr:
if i in name:
designation = 'Mr.'
break
for j in Miss:
if j in name:
designation = 'Miss.'
break
for k in Mrs:
if k in name:
designation = 'Mrs.'
break
return designation
train['designation'] = train['name'].map(lambda x: add_designation(x))
test['designation'] = test['name'].map(lambda x: add_designation(x))
ori_te['designation'] = ori_te['name'].map(lambda x: add_designation(x))
train.drop('name', axis=1, inplace=True)
test.drop('name', axis=1, inplace=True)
ori_te.drop('name', axis=1, inplace=True)pclass와 gender로 만든 feature
#특정성이 없는 구간은 others로 설정하였다.
def make_pclass_gender(p,g):
p_g=''
if p ==1:
if g =='female':
p_g= 1
else:
p_g=5
elif p ==2:
if g =='female':
p_g= 2
else:
p_g=4
else:
if g =='female':
p_g=5
else:
p_g=5
return p_g
train['pclass_gender']= train.apply( lambda x : make_pclass_gender(x['pclass'], x['gender']), axis =1 )
test['pclass_gender']= test.apply( lambda x : make_pclass_gender(x['pclass'], x['gender']), axis =1 )
ori_te['pclass_gender']= ori_te.apply( lambda x : make_pclass_gender(x['pclass'], x['gender']), axis =1 )
train['family']=train.apply(lambda x : x['sibsp'] + x['parch'],axis = 1)
test['family']=test.apply(lambda x : x['sibsp'] + x['parch'],axis = 1)
ori_te['family']=ori_te.apply(lambda x : x['sibsp'] + x['parch'],axis = 1)특정성이 있는 나이와 성별로 분류한 Feature
def add_infant(age):
result = 0
try:
if age <= 4:
result = 1
except:
pass
return result
train['infant'] = train['age'].map(lambda x: add_infant(x))
test['infant'] = test['age'].map(lambda x: add_infant(x))
ori_te['infant'] = ori_te['age'].map(lambda x: add_infant(x))
train.shape, test.shape, ori_te.shape
train['gender_infant'] = train.apply(lambda row: row['gender']+'_'+str(row['infant']), axis=1)
test['gender_infant'] = test.apply(lambda row: row['gender']+'_'+str(row['infant']), axis=1)
ori_te['gender_infant'] = ori_te.apply(lambda row: row['gender']+'_'+str(row['infant']), axis=1)
train.drop(['infant'],axis=1, inplace=True)
test.drop(['infant'],axis=1, inplace=True)
ori_te.drop(['infant'],axis=1, inplace=True)Test size를 변경해가며 스코어 확인하기
이번 Kaggle에서 사용된 데이터의 수는 900개 정도로 매우 작은 수의 데이터이다. 그렇기에 처음에 주어진 0.3으로 데이터를 학습시킬경우 학습하는 데이터양이 부족할 수 있기 떄문에 최적의 Test size를 확인하는 과정을 거쳤다. Manual Search를 통하여 확인하였다. Grid search를 사용하여 확인했을 때는 0.4의 Test size일 때 스코어가 가장 높다고 나왔는데, 이것을 믿을 수 없었기에 Manual Search 기법을 사용하였다. 코드에 대한 이해도가 부족할 때는 Manual Search기법도 좋은 방법이라고 생각되지만, 이러한 기간이 길어지면 최종적으로는 악영향을 끼칠 수 있기 때문에 코드에 대한 이해도를 높여야한다고 생각된다.
이부분은 따로 코드를 작성하지 않겠다. 위에서 설명한대로 코드를 사용하여 확인하였을 때보다 손으로 확인하였을 때가 더 정확한 결과를 알려주기 때문이다.
최적의 Test size = 0.2
최적의 파라미터를 찾기
모델의 스코어가 높게 나오기 위해선 파라미터를 튜닝하는 것도 좋은 방법이라고 생각했다. 처음에는 하나하나 손으로 바꿔가며 찾는 Manual Search 기법을 사용하였다. 반복 작업을 하는 도중 이런 걸 해결해 놓은 코드가 있지 않을까 싶어 구글링을 통해 Grid Search함수를 찾아 활용하였다. 이전에는 CPU만을 사용해도 실행되는 시간이 그렇게 길지 않았지만, 반복을 통해 파라미터를 찾기 때문에 코드가 무거워졌다. 마지막으로 알게된 Randomized Search는 Grid Search를 알게되고 사용한지 하루가 지난 날 수업에서 진행해여 더 좋은 파라미터 튜닝 방법을 알게 되었다. 이제는 이것을 통해 최적의 파라미터를 찾아내고 그것을 다시 모델에 넣어 Cross Validation을 진행하여 학습의 효율을 더 증가시켰다.
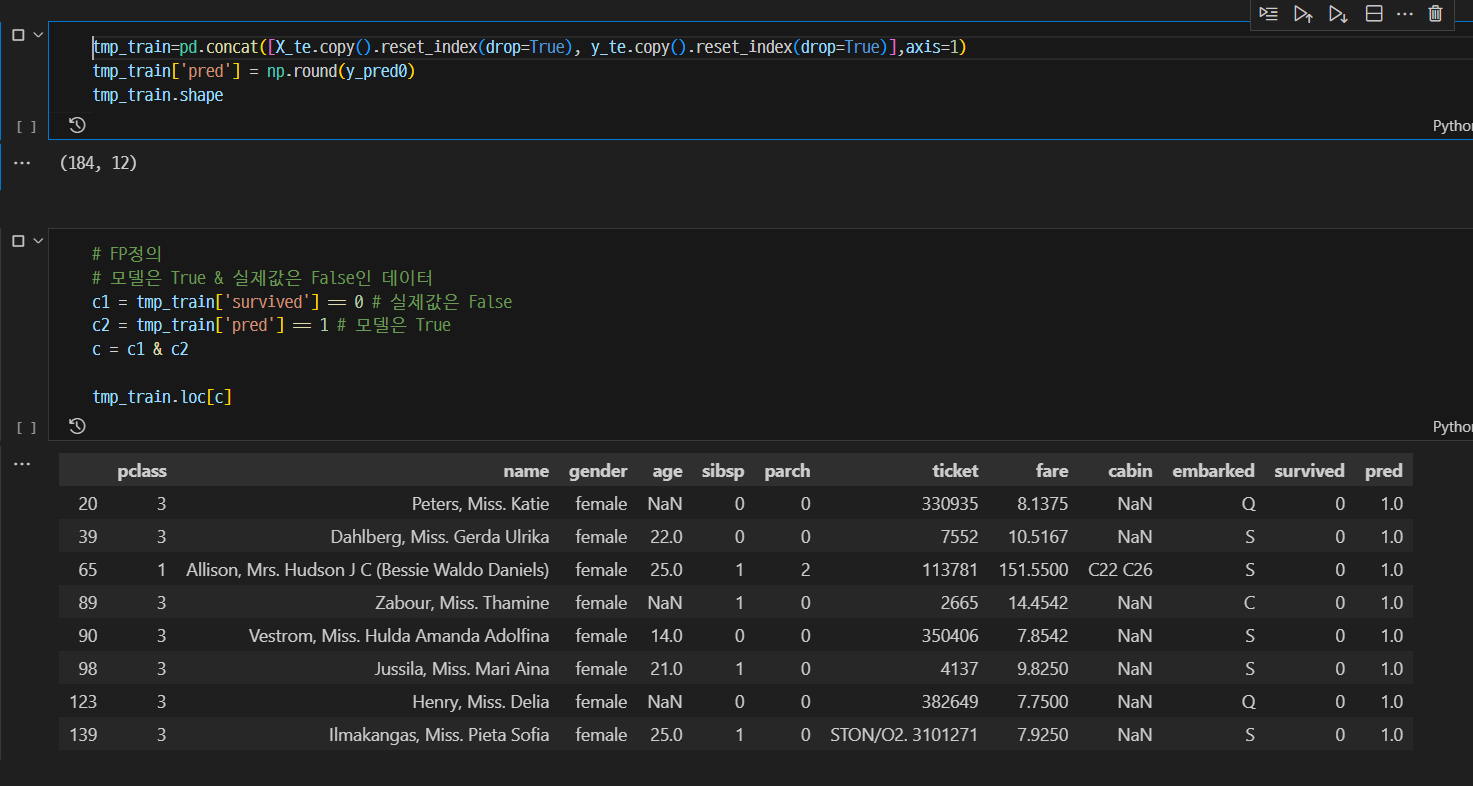
예측이 틀린 것을 EDA
Data의 전처리를 충분히 진행했고, 모델링 또한 어느정도 완성되었다고 생각된 후에 진행한 분석이다. 예측결과중 실제값과 틀린 부분들을 분석하였다. 우선 FP보다 FN이 높게 측정되었기 때문에 파라미터 튜닝 과정에서 평가로 사용된 Score를 roc_auc에서 recall으로 변경하였다. FN은 Precision과 연관된 값이기에 Precision의 값을 높일수 있게끔 Recall을 기준으로 튜닝을 진행했었다. 또한 예측결과중 틀린 값들만 모아서 EDA를 진행했다. FP 부분에서는 age는 20~30, 3등석에 1명 이하의 관련자(친인척)과 탑승한 여자 승객을 잘못 예측하였다. 이 부분은 새로운 Feature 추가해주었다. 마찬가지로 FN에서도 EDA를 진행하여 확인해본 결과, 2명 이하의 관련자와 탑승한 20~40세의 남성 승객이 많이 확인되었다. 이 부분도 새로운 Feature를 추가해주었다.
모델링
사용한 모델은 RandomForestClassifeir, XGClassifier, CatboostClassifier, lgbmclassifier 총 4가지이다. RFC는 경진대회가 시작된 첫날부터 사용한 모델이기에 긴 분석 시간이 주어지기도 했고, 학습 결과 또한 잘 나왔다. 다른 3개의 학습 모델은 주어진 시간이 부족하여 숙달하는데 어려움이 있었다. 학습 결과가 가장 잘나오는 모델은 RFC와 Catboost 두가지였다. 결과적으로 가장 높은 점수가 나온 것은 RFC였다. 이번 대회 기간에서 모델이 어떤 방식으로 학습을 하는 지 분석은 하지 못하고 사용을 했지만, 이 학습 모델들이 좋은 것은 알겠다.
개선점
대회에 사용한 모델에 대하여 조금 더 공부를 해야겠다고 생가되었고, 마지막 날 수업했던 내용을 아직 정리하지 못하여 지식이 부족하다. 또한 모델에서 클래스별 가중치를 부여하는 방법에 대하여 공부해보고 싶다는 생각이 들었다. 마지막으로 다음에 ML을 해야하는 상황이 있다면 catboost나 lgbm를 사용할 생각이다. 이 두가지 모델에 data를 encoding하지않고 바로 집어넣는 방법에 대하여 알아보면 좋을 것이라 생각된다.
중요도가 높은 feature를 잘 활용하였고, 조금 원리적인 부분에 대한 학습을 하면 좋을 것이라고 생각된다.

오버피팅이 하나도 발생하지 않은 모델을 확인했으나, 따로 저장해두지 않아서 찾을수가 없었다.
