
Deep Learning
Introduction of Deep Learning
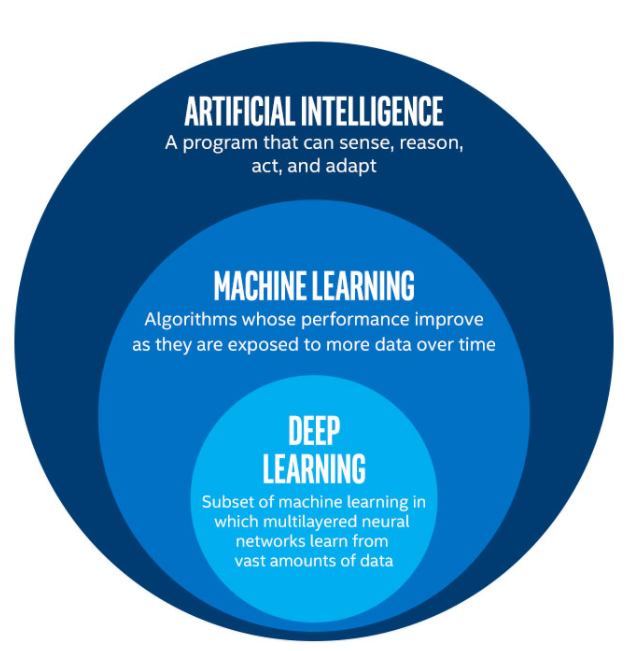
딥러닝은 머신러닝안에 있는 하나의 범주이다. AI, ML, DL 순으로 세부 집단이 정의된다. 딥러닝은 머신러닝이 처리하기 어려운 데이터, 예를 들면 비정형 데이터와 같은 것을 처리하기 위하여 만들어진 기법이다.
딥러닝의 진행방식을 가장 간단히 표현한 것은 아래 사진과 같다. (퍼셉트론)
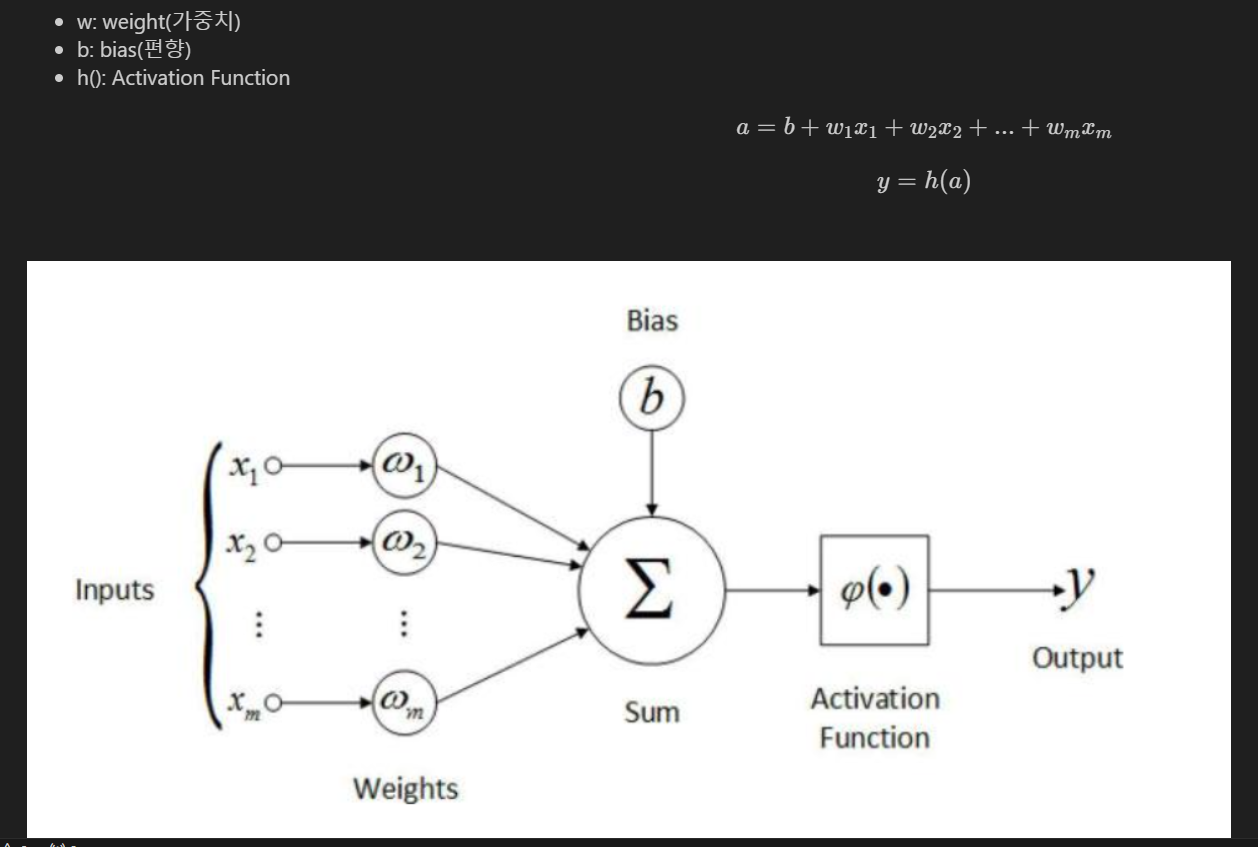
여러개의 input data(x)를 각각의 해당하는 가중치(w)를 곱해주고 그것들을 Sum한다. 여기서 bias를 더해주고 활성화 함수에 넣어주어 output(y)를 구한다. 이곳이 가장 간단한 딥러닝 모델이고 여기에 여러가지 기법과 손실함수(Loss Function)와 다양한 활성화 함수를 적용시켜 세분화한다.
input layer -> hidden layer -> output layer
Activation Function (활성화 함수)
활성화 함수는 hidden layer를 활성화하기 위하여 필요한 함수이다. 그냥 수치로만 되어있는 입력값을 함수에 넣어 데이터를 가공시켜준다고 생각하면 될 것 같다. 뒤에서 나오겠지만 활성화 함수를 어떤 것을 사용하는 지에 따라서 Gradient Vanishing이 발생할 수 있다. 요즘 가장 많이 사용하는 것은 ReLU이다.
Loss Function (손실 함수)
손실함수는 예측값과 실제값의 차이를 어떻게 계산할지를 정의하는 함수이다. Loss Function은 어떤 기능을 하는 모델을 구현할 지에 따라서 다양한 손실함수가 존재한다.
Gradient Descent (경사 하강법)
손실함수로 구한 Loss값을 통하여 새로운 weight와 bias를 만들어 loss를 줄여가는 방법이다. 여기서 Learning rate를 어떻게 설정하냐에 따라서 어느 지점을 loss 최솟값을 만드는 weight와 bias로 정의할지가 정해진다. 학습율이 너무 작을 때는 local minimum에서 벗어나지 못하는 경우가 발생할 수 있고 학습율이 높을 경우에는 아예 minimum값을 찾지 못할 수도 있다.
Back Propagation (역전파)
역전파는 Loss가 계산되는 output layer에서부터 input layer로 이동해가면서 weight와 bias를 최신화해준다. Loss를 구함으로써 weight와 bias를 새로 정의해준다.
Gradient Vanishing (기울기 소실)
Gradient를 구하는 과정에서 활성화 함수를 미분하여 계산한다. 이때, 활성화 함수의 미분값이 매우 작을 경우 layer를 거쳐가면서 점점 gradient 값이 소실되어가는 것을 말한다. ReLU는 미분값이 0과 1이기 때문에 이러한 소실이 적게 발생한다. 하지만 미분이 0이되는 구간에서는 그 node를 사용할수 없게 되기떄문에 그러한 소실이 발생할 수는 있다.
Batch
배치는 한번에 처리되는 집단이다. 처리할 뭉탱이라고 생각하면 된다. Batch normalization을 통해 각 batch마다 분포도의 차이를 일반화 시켜준다.
Epoch
전체 학습을 한바퀴 도는 것을 의미한다. for문으로 만들면 된다.
Optimizer
Gradient Descent의 한 종류로 기존의 단점들을 보완하였다. 두개를 함께 쓰는게 일반적이다.
Tensor
Tensor는 다차원의 배열을 나타낸다.
torch의 간단 함수들
-
torch.tensor(a) : a를 tensor로 바꾼다.
-
torch.from_numpy(a) : a라는 numpy array를 tensor로 바꾼다.
하지만 여기서는 a의 값이 변하면 해당 tensor값도 변한다. (깊은 복사) -
torch.ones_like(a) : a라는 tensor와 같은 shape을 갖고 원소를 1로 갖는 tensor를 만듦
-
torch.rand_like(a) : 위와 같은데 0~1의 랜덤한 원소를 갖음
-
torch.rand(shape) : shape에 맞는 0~1의 랜덤한 원소를 갖는 tensor
-
torch.randn(shape) : 정규분포 -1 ~ 1로 반환
-
torch.ones(shape) , torch.zeros(shape), torch.empty(shape) 위와 같음
-
torch.cat((a,b),dim = 1) : a랑 b를 합친다, dim은 axis라 보면 될듯
-
torch.mm(a,b) : a와 b의 행렬곱을 진행한다. 크기가 맞아야 곱샘가능
-
torch.matmul(a,b) : a와 b의 행렬곱을 진행하는데, 크기가 맞지 않으면 broadcasting 해준다.
-
broadcasting : 이것은 크기를 맞춰준다는게 아니라 차원은 맞는 상황에서 부족한 부분이 생긴다면 그 부분을 채워주는 것이다. 확장개념
-
torch.mul(a,b) : 크기가 맞지 않으면 a에 맞춰서 b의 형태를 바꿔준다.
-
torch.bmm(a,b) : a와 b는 (x,y,z) 형태를 가지고 있다고 하면 x는 batch를 의미한다. 따라서 torch.bmm(a,b)는 batch x는 그대로 두고 y,z에 대해여 행렬곱을 진행한다. a @ b로도 표현 가능
-
.item() : 형변환해준다. tensor에서 python으로 형변환
-
X.add_(a) : 앞에 변수(X)에 a를 더하고 변수를 대체한다. (inplace =True)
-
X.reshape(a,b) : X의 모양을 a * b의 크기로 바꾼다. a,b중 -1로 설정할 경우 나머지 인자에 의해서 결정된다. ex) X의 크기가 4x6일때 X.reshape(2,-1)이면 2x12 tensor로 변환된다. 이것은 행렬곱에서 활용하면 좋다. numpy에서도 사용가능하긴함.
view함수에 관해서는 메모리가 절약된다고는 하는데 자세한 사항은 필요할때 알아보자. -
X.permute(a,b,c) : .transpose()의 확장판으로 3개 이상의 차원을 한번에 변경할 수 있다. 지금같은 경우에서 3차원에서 변경하는 것이기때문에, a,b,c는 0,1,2 정수중 하나의 값을 갖는다.
-
X.squeeze() : 차원의 값이 1이면 삭제한다. 인자로 dim = n이 오면 n차원의 값이 1이면 삭제한다.
-
X.unsqueeze(dim=n) : n번째 차원을 1으로 생성한다.
Dataset
Dataloader
DataLoader는 test data를 batch size로 나누는 클래스이다.
test_dataloader = DataLoader(test_data, batch_size=64, shuffle =True)
↑ 인스턴스 ↑ 클래스
image의 shape는 ex) (1,28,28)이면 1은 color를 나타내고 28은 높이와 너비이다.
-
next(iter(test_dataloader)) : 다음 batch data를 가져온다.
-
nn.flatten() : dim으로 이루어진 것을 tensor로 바꾼다.( 1자로 쭉 늘린다는 뜻 )
-
nn.sequential() : 괄호에 들어가는 것을 순서대로 실행시킨다.
-
nn.linear(x,y) : input의 size는 x, output의 사이즈는 y로 간다. x와 y는 tensor이기에 flatten 되어 있다고 보면 된다. 내부 계산은 y=xA+b 이다.
-
nn.ReLU() : ReLU활성화 함수를 진행한다.
-
nn.Softmax(dim= a)(b) : a에는 보통 1이 들어간다 dim=0은 batch size가 할당되었기 때문에 dim =1에서 진행된다. b는 softmax에 들어갈 값이다. 출력 값은 0~1까지의 확률값이다.
-
x.detach() : 학습이나 연산부분에서 떼어낸다는 뜻이다. 즉 모델과 상관없어진다.
Loss Function
어떤 역할을 수행하는 모델이냐에 따라서 사용되는 Loss function이 다르다
회귀 모델에서는 MSELoss가 사용되고 L1Loss가 주로 사용된다.
이진분류에서는 BCELoss와 BCEWithLogitsLoss가 사용된다.
다중분류에서는 CrossEntropyLoss가 사용된다.
이것보다 더 다양한 함수가 사용될 수 있으니 찾아보기.
Training loop
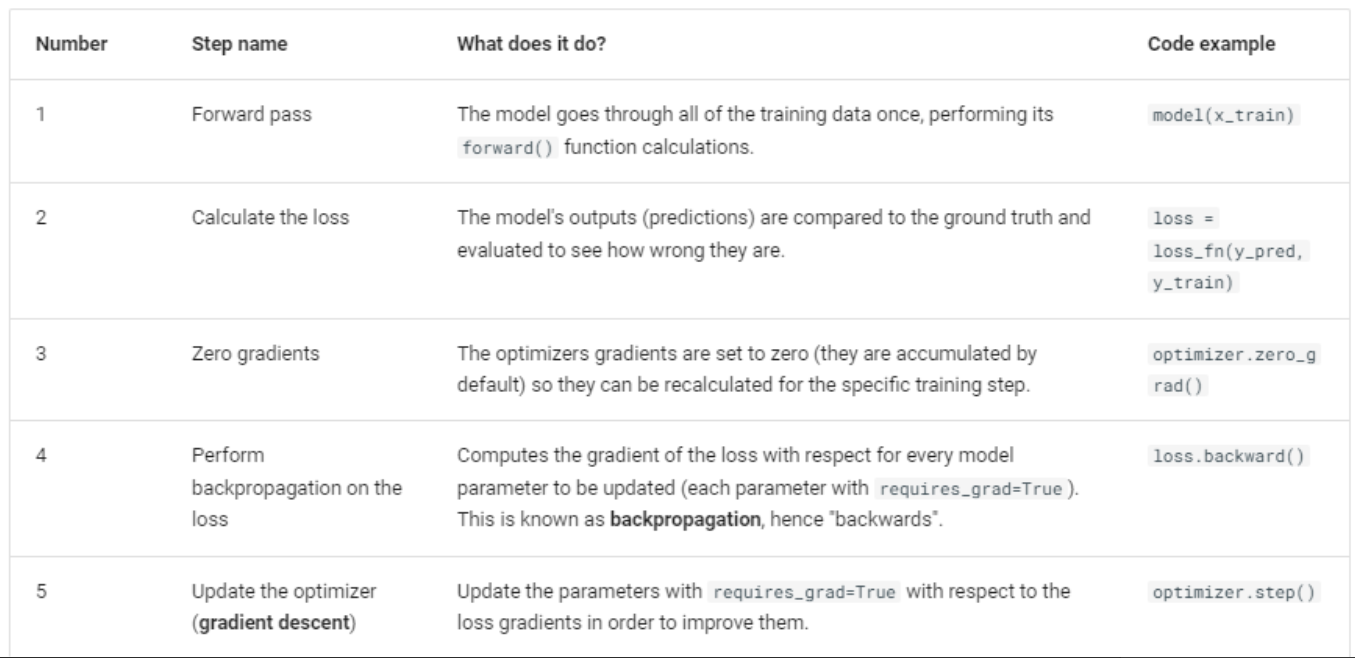
Test loop

with torch.inference_mode()
with torch.no_grad()
위 두개는 인스턴스(모델)의 파라미터(weight, bias etc..)를 고정한 모드로 설정한다. 평가할 때는 위에 범위 안에서 작동해야한다.
model save와 load하는법이 있다.
torch.save(obj=model_0.state_dict(), f=MODEL_SAVE_PATH)
loaded_model_0 = LinearRegressionModel() #인스턴스 생성
loaded_model_0.load_state_dict(torch.load(f=MODEL_SAVE_PATH
모델을 향상시키는 방법
- Layer를 증가시킨다.
- Hidden unit을 추가한다.
- Epoch를 증가시킨다.
- Activation function을 바꿔본다
- Loss function을 바꿔본다.
- Learning rate를 변경시킨다.
Modular
- data_setup.py : data를 준비하고 전처리 하는 파일
- engine.py : 사용되는 training function들을 저장
- model_builder.py : model을 만드는 파일
- train.py : 다른 파일들을 모두 사용하고 학습을 진행하는 파일
- utils.py : 유용한 utility function들의 파일
Image Processing
이미지를 가공하여 학습에 용이한 data로 바꾸는 과정을 말한다.
Gaussian processing, padding, resizing 등이 있다.
