
INDEX
인덱스란 테이블의 검색 속도를 향상시킬 수 있는 자료구조이다.
데이터베이스의 크기가 크면 클수록 인덱스가 반드시 필요히다.
인덱스는 데이터베이스의 성능을 좌우하는 요소이기 때문이다.
따라서 인덱스를 사용하는 SQL을 만들어 효율적으로 사용한다면 매우 빠른 응답 속도를 얻을 수 있고, 쿼리의 부하가 줄어들기 때문에 시스템 전체 성능이 향상되는 효과를 얻는다.
INDEX 사용 왜 빠를까 ?
특정 컬럼에 인덱스를 생성하면, 해당 컬럼의 데이터들을 정렬하여 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장되는데 인덱스에 저장된 물리적 주소를 가져오는 방식으로 동작하기 때문에 검색 속도가 빨라진다.
INDEX 생성
CREATE INDEX [인덱스 컬럼명]
ON [테이블명] (컬럼명);INDEX 참고 링크
INDEX 조회
Show Index From 테이블명; 
여기서 Cardinality란 해당 컬럼의 중복 수치를 나타낸 것이다.
컬럼의 Cardinality 숫자가 높아야 인덱스 조회 시 더 효율적이다.
기본키 컬럼은 항상 중복이 불가능하므로 기본키에 대한 인덱스의 Cardinality는 테이블의 행의 갯수만큼 나오게된다.
INDEX 재생성
ANALYZE TABLE 테이블명;INDEX 테이블은 인덱스 생성 후에 insert된 데이터들에 대해서는 인덱스 정렬이 최적화되어있지 않다.
인덱스를 재생성 하고 인덱스를 다시 조회해보면 Cardinality가 재계산되어 늘어난 것을 볼 수 있다.
INDEX 삭제
DROP INDEX 인덱스명 ON 테이블명;
INDEX 사용여부 확인
EXPLAIN
SELECT ...; 
SQL 문 앞에 explain을 붙여주고 쿼리문을 작성해주면
Extra에 Using Index로 인덱스를 사용한 것을 알 수 있다.
인덱스 사용 전 쿼리 실행 시간
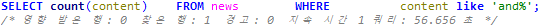
인덱스 사용 후 쿼리 실행 시간
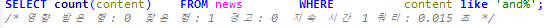
인덱스 사용 시 주의할 점
속도 향상을 위해 인덱스를 많이 만드는 것은 좋지 않다.
인덱스를 관리하기 위해서는 데이터베이스의 약 10%에 해당하는 저장공간이 추가로 필요하다. 따라서, 조회 시 자주 사용하고 고유한 값 위주로 인덱스를 생성하는 것이 좋다.
INSERT / UPDATE / DELETE 성능에 영향을 미친다.
데이터를 삽입, 수정, 삭제하는데 인덱스를 생성한 컬럼의 데이터가 바뀌게 되면 악영향을 미치게 되고 인덱스 테이블에도 수정이 필요하기 때문에, 삽입, 수정, 삭제의 작업이 2번씩 이루어지게 되는 단점이 있다. 데이터 갱신보다는 조회에 주로 사용되는 컬럼에 인덱스를 생성하는 것이 유리하다.
운영 중인 테이블에 인덱스를 생성하면 인덱스가 생성되는 동안 서비스가 중지될 수 있다.
테이블에 인덱스를 생성하면, 인덱스를 구성하는 동안 테이블에 Lock이 걸릴 수 있어 인덱스를 생성하려면 신중한 판단이 필요하다.
인덱스 생성 전 쿼리문에는 문제가 없는지 확인한다.
쿼리문을 최적화 하는 것으로도 쿼리 실행 속도를 개선할 수 있다. 인덱스 생성 전에 쿼리를 최적화 할 수는 없는지 확인한다.
