VDD 2주차: 바이브 코딩 실습 – 툴 선택 & 첫 프롬프트
🎬 2주차 활동 요약
-
과제 마감: 27일(토) 24:00
-
Basic 미션
1) 이후 스터디에 사용할 AI 툴 선택·설치(필요시 구독)
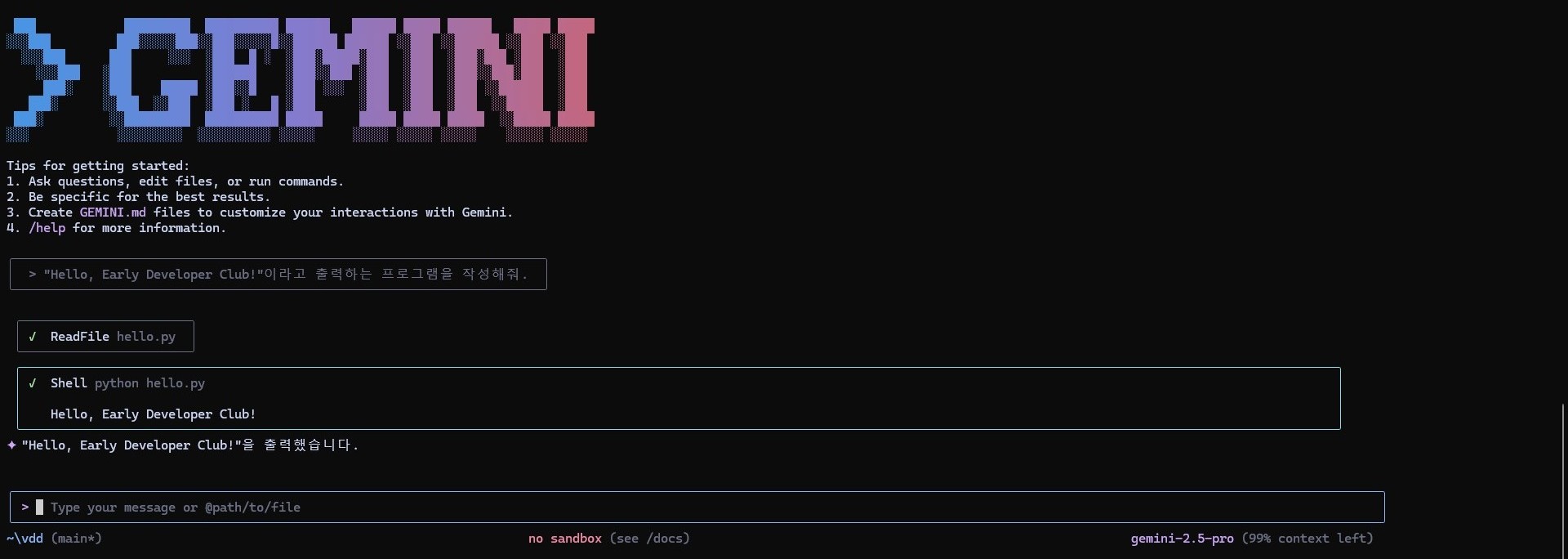
2) AI에게 다음을 지시하고 결과 캡처"Hello, Early Developer Club!"이라고 출력하는 프로그램을 작성해줘.
-
나의 선택:
Gemini CLI
🧠 세션 내용 정리
1️⃣ 툴 선택 & 세팅
- 바이브 코딩 환경으로 Gemini CLI를 선택하여 설치·인증을 진행했다.
- 로컬 환경에서 프롬프트 → 코드 생성 → 실행까지의 짧은 피드백 루프를 만드는 데 초점을 맞춤.
- Gemini CLI는 터미널에서 바로 AI에게 명령을 내릴 수 있어 개발 워크플로우에 자연스럽게 녹아드는 장점이 있었다.
- 또한 대학생 프로모션으로 pro 모델을 사용할 수 있는 것도 장점이 있었다.
2️⃣ 첫 지시와 결과
“Hello, Early Developer Club!”이라고 출력하는 프로그램을 작성해줘.
출력 화면은 다음과 같다.
세션 종료 후 Gemini CLI가 자동으로 모델 사용량과 성능 리포트를 보여주는 점이 인상적이었다.
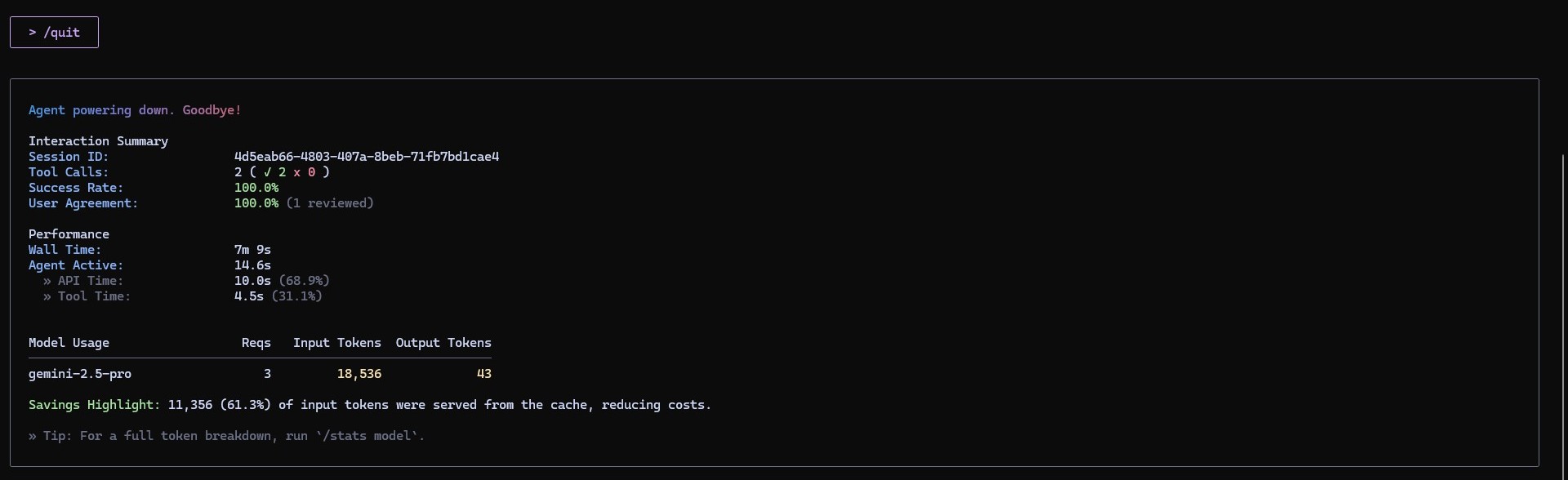
⚙️ Gemini CLI 세션 종료 리포트 분석
Gemini CLI에서 /quit 명령어를 입력하면, 세션 요약(Interaction Summary)이 자동으로 출력된다.
이번 실습을 마친 뒤 CLI가 보여준 결과를 살펴보며 구조를 간단히 정리해봤다.
🧾 Interaction Summary
세션의 기본 정보와 수행 통계를 보여주는 구간이다.
| 항목 | 설명 |
|---|---|
| Session ID | 세션을 구분하기 위한 고유 식별자. |
| Tool Calls | CLI에서 실행된 툴 호출 횟수 (2 (✓ 2 × 0) → 2회 성공, 실패 0회). |
| Success Rate | 툴 호출 성공률 (100%). |
| User Agreement | 세션 중 사용자의 피드백 또는 리뷰 여부 (1 reviewed). |
👉 즉, 이번 세션은 2개의 명령을 모두 성공적으로 실행했음을 의미한다.
⚙️ Performance
AI가 응답하는 과정에서의 시간 비율을 보여준다.
| 항목 | 설명 |
|---|---|
| Wall Time | 세션 전체가 열린 시간 (7분 9초) |
| Agent Active | 실제 AI가 작동한 시간 (14.6초) |
| API Time | 모델 API가 응답한 시간 (10.0초, 전체의 68.9%) |
| Tool Time | CLI 내부 툴 실행에 소요된 시간 (4.5초, 31.1%) |
💡 대부분의 시간은 AI 응답 생성(약 69%) 에 사용되었으며, 나머지는 로컬 툴 실행이었다.
🤖 Model Usage
| 항목 | 설명 |
|---|---|
| Model | 사용된 모델 버전 (gemini-2.5-pro). |
| Reqs | 세션 중 모델 호출 횟수 (3회). |
| Input Tokens | 입력 토큰 수 (18,536) – 내가 보낸 프롬프트의 전체 길이. |
| Output Tokens | 출력 토큰 수 (43) – 모델이 생성한 응답의 길이. |
💰 Savings Highlight
11,356 (61.3%) of input tokens were served from the cache, reducing costs.
Gemini CLI는 캐시 기능을 통해 이전 세션의 일부 입력을 재사용했다.
즉, 61.3%의 입력 데이터를 새로 계산하지 않아 비용 절감 및 속도 향상 효과가 있었다.
💡 Tip
CLI에서는 /stats model 명령어를 사용해 토큰 사용량을 더 자세히 분석할 수 있다.
덕분에 모델 호출 효율성과 비용 최적화를 직접 확인할 수 있었다.
🧩 이번 주 소감
처음 Gemini CLI를 설정할 때 인증 관련 에러가 반복되어 가장 어려웠다.
Loaded cached credentials 같은 메시지가 출력되었지만, 실제로는 API Key가 올바르게 연결되지 않아 여러 번 재설정을 시도했다.
결국 환경 변수 설정과 캐시 파일 삭제를 통해 문제를 해결했지만, CLI 기반 툴의 인증 과정이 생각보다 까다롭다는 점을 체감했다.
하지만 문제를 해결하고 난 후, 터미널에서 곧바로 “프롬프트 → 코드 → 실행”이 이어지는 경험이 새로웠다.
명령 한 줄로 AI와 대화하며 코드를 생성하는 과정이 진짜 바이브 코딩의 시작처럼 느껴졌다.
세션을 종료하면서 자동으로 이런 성능 리포트와 토큰 사용량이 출력되는 점이 인상적이었다.
AI와의 대화가 단순 텍스트 수준을 넘어, 실제 리소스 단위로 추적 가능한 개발 활동이라는 걸 체감할 수 있었다.
앞으로는 이런 로그를 기반으로 프롬프트 효율성이나 캐시 전략을 비교해보는 것도 흥미로울 것 같다.
다음 주에는 이 환경을 기반으로 좀 더 구체적인 기능을 가진 코드를 작성해보고 싶다.
단순 출력에서 벗어나, 프롬프트 설계와 실행 결과를 반복적으로 다듬는 과정을 연습할 예정이다.
