
ETL(Extract, Transform, Load)이란?
난잡한 원시데이터에서 데이터 분석이 원활하게 할 수 있도록 분석하기 쉬운 데이터로
추출, 변환 시켜서 불러오는 작업
데이터 분석의 흐름
수집 -> 보존 -> 처리 -> 분석 -> 시각화
AWS Data Pipeline
온프레미스 데이터 소스뿐 아니라 여러 AWS 컴퓨팅 및 스토리지 서비스 간에 데이터를 안정적으로 처리하고 지정된 간격으로 이동할 수 있게 지원하는 웹 서비스
◾ AWS 관리 서비스
◾ EC2 인스턴스 위에서 실행
◾ 노드 사이에서 데이터 마이그레이션 및 ETL 작업 수행
◾ 스케쥴러 기능(시간지정 및 사이클링 의존성 지정 등)
◾ 온프레미스에서 AWS로 데이터 이동 가능
구성요소
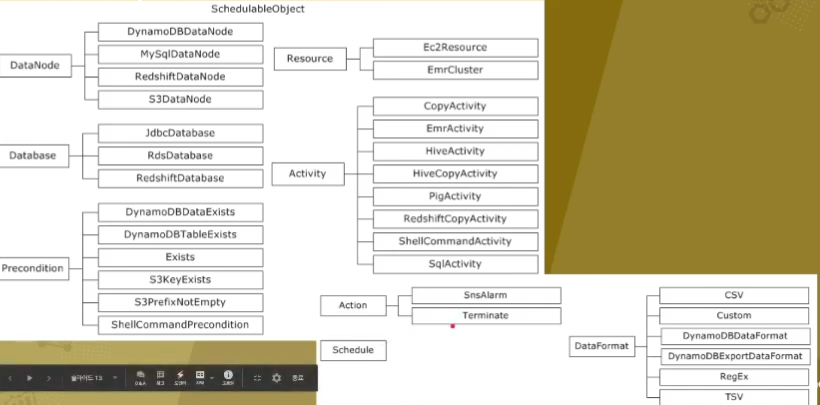
< AWS 관리 서비스 >
- 어려운 작업은 아니지만 직접 만들려면 귀찮다.
- 작업을 수행하기 위한 환경
- 컴퓨팅 리소스
- 소프트웨어
- 스케쥴러(시계열 방식, 크론 방식)
- 관리 및 유지보수
< 데이터 마이그레이션 및 ETL >
- 개발용 GUI 지원
- 대표적인 모델 템플릿 지원
- 자신이 사용하던 코드로 실행 시킬 수 있음
- EC2 인스턴스 or EMR 클러스터 위에서 수행
- 실패한 작업 자동으로 재실행
AWS GLUE
완전 관리형 ETL 서비스로, 효율적인 비용으로 간단하게 여러 데이터 스토어 및 데이터 스트링 간에 원하는 데이터를 분류, 정리, 보강, 이동할 수 있게 지원하는 웹 서비스
즉, 데이터 정제 기능을 가지고 있다.
- 테이블
- 데이터 카탈로그
- 데이터의 스키마 정보(칼럼, 데이터 형식)를 저장
- DB마다 관리
- 작업
- ETL처리의 실행기반
- 3종류 선택가능(Python Shell, Spark, Spark Streaming)
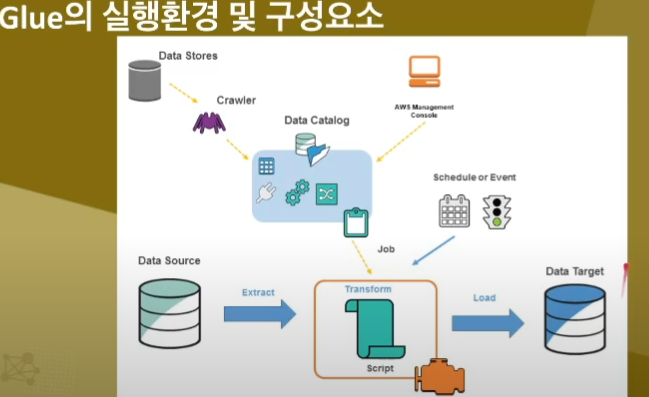
◾ 서버리스로 관리할 인프라가 없음
◾ 크롤러(데이터 카탈로그를 추출)를 통해서 자동으로 스키마 생성
◾ GUI 클릭으로 자동으로 ETL 코드 자동 생성 및 수정
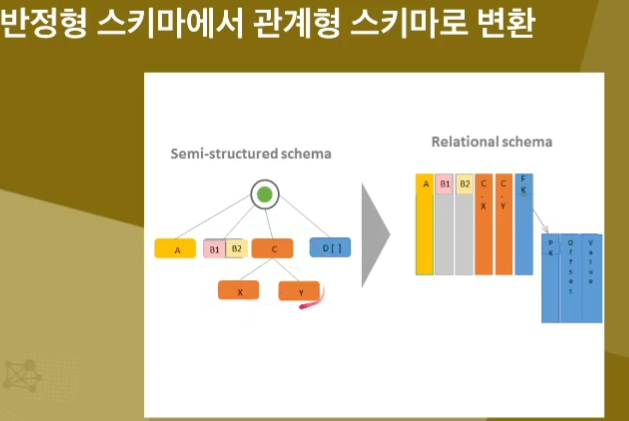
◾ 반정형 데이터를 관계형 데이터로 변환 가능
◾ 반복 일정과 이벤트에 따른 작없 실행
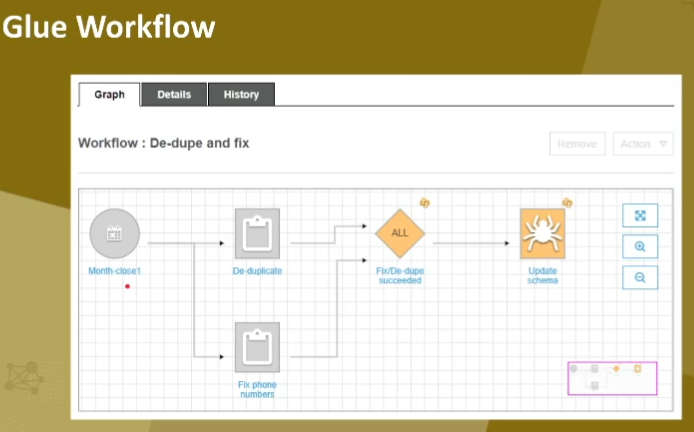
◾ Workflow, Step Functions를 통한 작업관리
<GLUE의 ETL 작업 수행과정>
1) 데이터의 원본을 크롤링하여 데이터 카탈로그에 메타데이터 생성
2) 데이터 카탈로그의 정보를 바탕으로 작업 정의
3) 정의된 작업에 따라서 ETL의 코드가 자동으로 생성
4) 작업 실행으로 소스 데이터에서 추출, 변환하여 타켓으로 로드

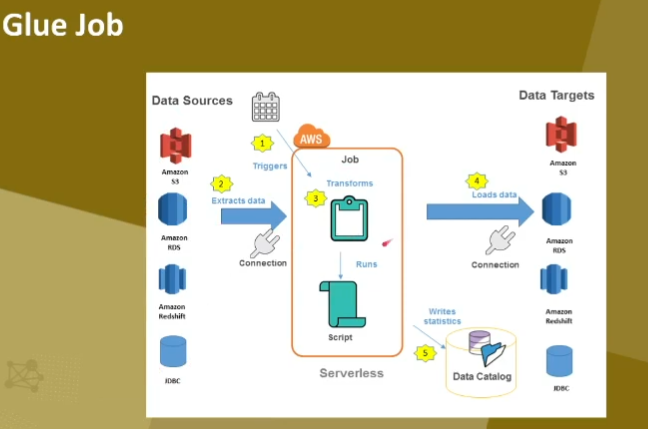
< GLUE Job >
- 규모와 유형에 따라서 Python Shell, Spark, Streaming ETL 선택
- 작업 제한시간 기본값 2880분 (Lambda는 15분..) -> 데이터 규모가 크면 Glue 권장
- 트리거를 사용하여 자동으로 작업 시작 가능
- 다양한 형식의 출력파일 : JSON, CSV, ORC, Apache Parquet 등
- 오류시 자동으로 재시도
- end point를 사용하여 스크립트 개발 및 테스트 가능 -> 나의 환경에 맞추어 개발 가능
AWS Data Pipeline 와 AWS GLUE에 대한 최종 정리
| AWS Data Pipeline | AWS GLUE |
|---|---|
| EC2 인스턴스 사용 | 서버리스 |
| 데이터의 이동 및 변환 자동화 | 데이터 카탈로그 수집 |
| 미리 작성된 템플릿 제공 | 규모와 목적에 따른 작업 실행환경 선택 |
| 온프레미스에서도 가능 | ETL 코드 자동으로 생성 |
| 대부분의 Data Pipeline 기능 할 수 있음 |
기존 Data Pipeline의 유저 덕분에 Data Pipeline이 유지되고 있는 것
전반적으로 요즘은 Glue를 많이 사용하는 것 같다. Glue의 장점등을 알게되었고 앞으로의 프로젝트에 Glue를 활용할 수 있는 기획을 구상해 보아야겠다는 생각을 하게되었다.
추후 공부해보면 좋을 사이트1
추후 공부해보면 좋을 사이트
