
1. 시퀀스(Sequence)
- 리스트, 튜플, range, 문자열이 연속적으로 이어진 자료형
- bytes, bytearray 포함
📌 시퀀스 자료형 활용
- 시퀀스 객체: 시퀀스 자료형으로 만든 객체
- 요소(element): 시퀀스 객체에 들어 있는 값
✔ 값 in/not un 시퀀스객체: 특정 값이 있는지 확인
a = [0, 10 ,20 ,30 ]
30 in a
>> True✔ + : 시퀀스 객체 연결하기
a = [1, 2, ,3, 4]
b = [5, 6, 7, 8]
a + b
>> [1, 2, 3, 4, 5, 6, 7, 8]
** range는 리스트 또는 튜플로 만들어 연결 **
range(1, 5)
range(6,10)
list(range(1,5)) + list(range(6,10))
>> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
✔ * : 객체를 특정횟수만큼 반복(정수만 가능)
[0,1,3,5] * 2
>> [0, 1, 3, 5, 0, 1, 3, 5]
✔ len(): 시퀀스 객체 요소 개수 구하기
** range에 len을 사용하면 생성되는 요수 개수 구함 **
len(range(0,10,2) # 0~10까지 2씩 증가
>> 5
✔ del a()/a.remove(): 시퀀스 요소 삭제
#del
alp = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
index_alp = alp.index('d')
del alp[index_alp]
print(alp)
#remove
alp.remove('d')
print(alp)
>> ['a', 'b', 'c', 'e', 'f', 'g', 'h', 'i', 'j']✔ insert(): 시퀀스 요소 삽입
mylist = [1, 5, 1, 7, 1]
mylist[mylist.count(1)] = 70
mylist[len(mylist) - 1] = 80
mylist.insert(1, 50) 인덱스 [1]자리에 50추가
print(mylist)
>> [1,50,1,70,80]📌 인덱스
- 시퀀스 객체 각 요소의 정해진 순서
- 시퀀스 객체에 '[]'를 붙이고 요소의 인덱스를 지정하면 해당 인덱스로 접근 가능
- 인덱스는 항상 0부터 시작
- 음수는 인덱스뒤에서부터 접근, -1부터 시작
a = [38, 21, 53]
a[0]
>> 38
a[1]
>> 21
a[2]
>> 53
- 요소 값을 수정할 수 있는 것은 리스트뿐
- 튜플, range, 문자열은 읽기 전용
📌 슬라이스
- 시퀀스 객체 일부를 잘라냄
- 인덱스 처음부터 슬라이스한다면 0 생락가능(a[ :2])
- 시작과 끝을 가져온다면 둘 다 생략가능 (a[ : ])
a=[1, 2, 3, 4, 5]
a[0:2]
>> [1, 2, 3]
** 음수 인덱스 지정 가능 **
a = [2, 4, 6, 8, 10]
a[0:-2]
>> [2, 4, 6, 8]
✔ 튜플 슬라이스
range(0,10) # (0,1,2,3,4,5,6,7,8,9)
r[4:7]
>>(4, 5, 6)
✔ 슬라이스에 요소 할당
- 원래 있는 요소가 변경
- 할당된 요소 수가 적으면/크면 그만큼 리스트 요소 개수도 감소/증가
a = [1, 2, 3, 4, 5]
a[1:3] = ['a', 'b']
>> [1, 'a', 'b', 4, 5]
- 증가폭을 지정했을 때는 슬라이스 범위 요소 개수 = 할당할 요수 개수
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a [2:8:2] = ['a', 'b']
>> ValueError, 크기가 3이어야 오류 x
2. 리스트 컴프리헨션
리스트를 간결하게 읽기 쉽게 작성하는 형태
[expression for item in iterable if conditon]
- expression: 반복에 생성할 요소(조건이 있다면 만족됐을 때)
- for item in iterable: 'iterable'에서 각 요소 반복
- if conditon: 조건을 만족하는 경우에만 그 요소 포함(선택 사항)
my_tuple = (1, 2, 3, 4, 5)
remove_num = 2
list_numbers = [n for n in my_tuple if n != remove_num]
print(list_numbers)
- 중첩 리스트 컴프리헨션
#1 2차원 배열을 1차원 배열로 변환
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
flattened = [num for row in matrix for num in row]
print(flattened)
>> [1, 2, 3, 4, 5, 6, 7, 8, 9]📍 [num for row in matrix for num in row] 📍
1) 외부 반복문 num for row in matrix
:각 리스트 행에 대한 반복
2) 내부 반복문 for num in row
: 각 행 내 리스트 요소 반복
#2 2차원 배열 각 요소를 제곱한 값을 포함하는 리스트 생성
squared_matrix = [[num**2 for num in row] for row in matrix]
print(squared_matrix)
>> [[1, 4, 9], [16, 25, 36], [49, 64, 81]]📍 [num for row in matrix for num in row] 📍
1) 외부 반복문 for row in matrix
:각 리스트 행에 대한 반복
2) 내부 반복문 [num**2 for num in row]
: 각 행 내 리스트 요소 반복
💡 컴프리헨션 코드로 변환하기
#1
even = []
for i in range(2, 11, 2):
even.append(i)
print(even)
*****
even = [i for i in range(2,11,2)]
print(even)
>> [2, 4, 6, 8, 10]
#2
s = []
for i in range(10):
if i % 2 == 1:
s.append(i**2)
print(s)
*****
s = [ i**2 for i in range(10) if i % 2 ==1]
print(s)
>> [1, 9, 25, 49, 81]
💡 주어진 문자열을 리스트로 만들고 리스트 메소드인 sort() 함수를 사용하여 오름차순으로 정렬하자
이후, sort()함수에 매개변수 reverse=True를 설정하여 역순으로 정렬한 리스트를 출력하는 프로그램을 작성해보자
>> 문자열: data = '잣밤배귤감'
#1
def list_sort(d):
d.sort()
print(d)
return
def list_reverse(d):
d.sort(reverse=True)
print(d)
return
data = '잣밤배귤감'
list_data = []
for i in data:
if i not in list_data:
list_data.append(i)
list_sort(list_data)
list_reverse(list_data)
#2
def list_sort(s):
list_s = list(s)
list_s.sort()
return list_s
def list_revers_sort(s):
list_s = list(s)
list_s.sort(reverse=True)
return list_s
s = '잣밤배귤감'
result = list_sort(s)
print(result)
result_reverse = list_revers_sort(s)
print(result_reverse)
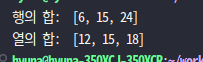
💡 중첩된 리스트 data에서 각 행의 합과 열의 합을 리스트 rsum과 csum에 저장해 출력하는 프로그램을 작성해보자
>> data = [ [1,2,3], [4,5,6], [7,8,9]]
data = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
rsum = [sum(row) for row in data]
csum_data = list(map(list,zip(*data)))
csum = [sum(row) for row in csum_data]
print("행의 합: ",rsum)
print("열의 합: ",csum)
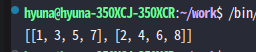
💡 리스트 컴프리헨션을 활용해 행과 열이 바뀐 형태의 리스트를 만들고, 이 변환된 리스트를 출력해보자
>> m = [[1,2], [3,4], [5,6], [7,8]]
m = [[1, 2], [3, 4], [5, 6], [7, 8]]
result = list(map(list, zip(*m)))
print(result)
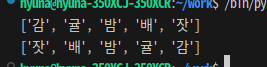
💡 strings에서 중복되는 단어를 제거하고 오름차순으로 정렬해보자
>> 길이를 기준으로 정렬하되, 길이가 같으면 사전 순서로 정렬
def get_key(s):
return len(s), s
# set으로 집합으로 만들어 중복제거 후 오름차순 정렬
def get_sort_list(s):
list_s = list(set(s))
list_s.sort(key = get_key)
return list_s
strings = ["mango", "apple", "banana", "cherry", "date", "fig", "apple", "banana"]
result = get_sort_list(strings)
print(result)
strings = ["mango", "apple", "banana", "cherry", "date", "fig", "apple", "banana"]

