🔨 Node Embedding
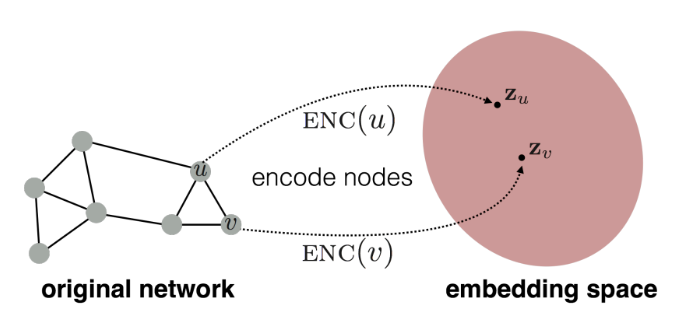
- 입력값으로 주어지는 그래프의 각 노드가 임의의 인코더를 통과하여 임베딩 공간에 위치하는 벡터로 바뀌는 과정.
- 이 과정을 통해 그래프에서 유사한 노드들이 임베딩 공간에서도 근처에 있도록 맵핑한다.
✔️ Framework
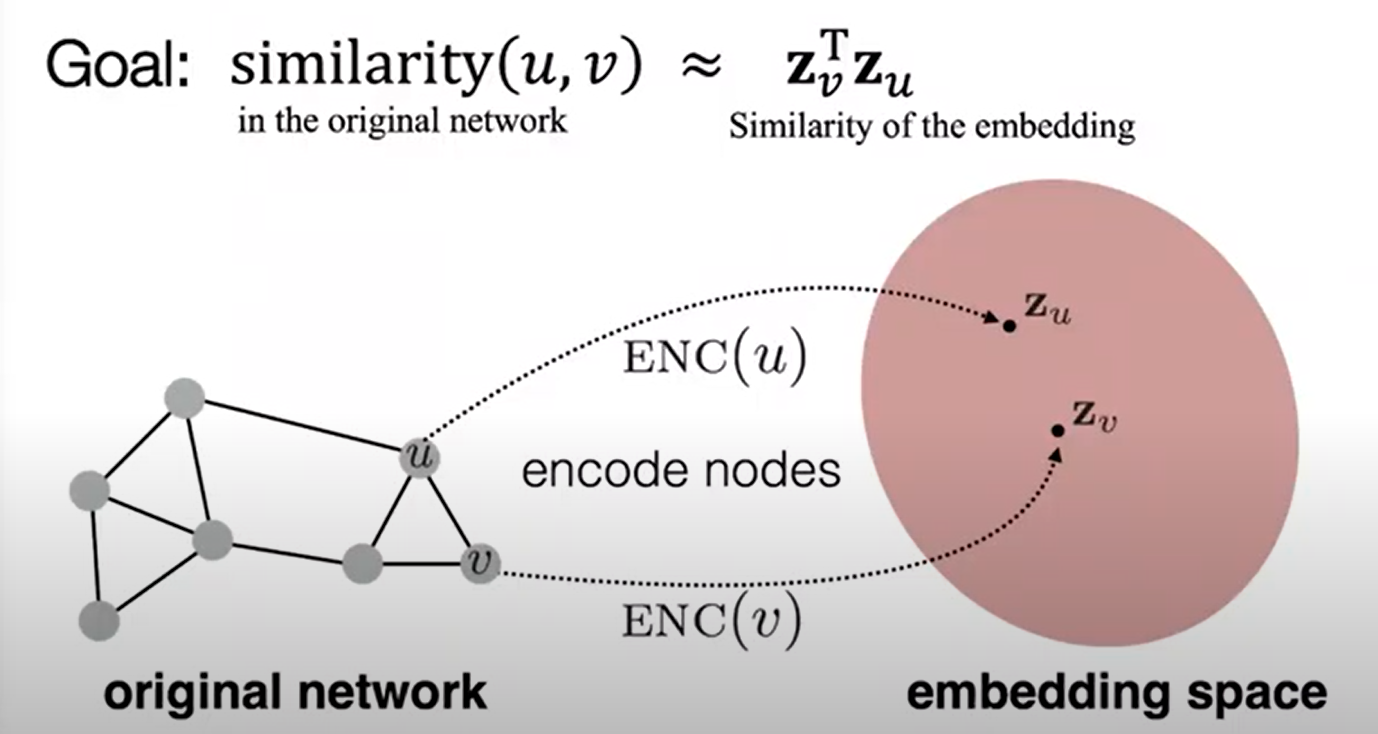
- Incoder가 Node를 Embedding space로 매핑하여 벡터를 생성한다.
- 노드 유사도 함수를 정의하여 그래프 노드 간 유사도를 측정한다.
- Decoder가 매핑된 벡터에 대해 유사도를 측정한다.
- 2와 3에서 측정된 유사도가 비슷해지도록 Encoder의 파라미터를 최적화한다.
📁 Random Walk
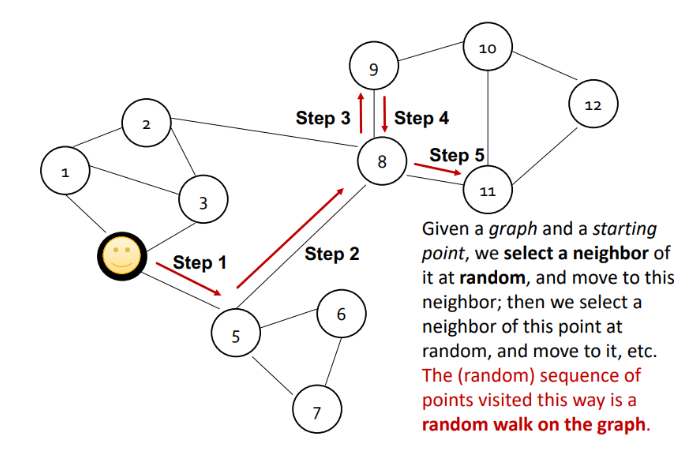 그래프가 주어지고 특정 노드에서 시작하여 한번에 하나씩 이웃 노드로 랜덤하게 옮겨간다고 할 때, 연속적으로 옮겨가는 노드 시퀀스를 랜덤워크라고 한다. 위 사진의 랜덤워크는 [5, 8, 9 , 11]이 된다.
그래프가 주어지고 특정 노드에서 시작하여 한번에 하나씩 이웃 노드로 랜덤하게 옮겨간다고 할 때, 연속적으로 옮겨가는 노드 시퀀스를 랜덤워크라고 한다. 위 사진의 랜덤워크는 [5, 8, 9 , 11]이 된다.
각 노드에 대해 랜덤워크를 기록하게 되면, 총 V개의 랜덤워크가 있게 됩니다. 만약 노드 u와 노드 v가 전체 랜덤워크에서 같이 등장하는 확률이 높다면, 두 노드는 서로 가까이 있다는 의미가 된다. 두 노드 사이에 edge가 많거나 경로가 짧아서 자주 함께 등장한 것이기 때문이다.
따라서 그래프에서의 두 노드 (u,v)의 유사도는 랜덤워크를 통해 도출된 확률을 통해 계산할 수 있다.
장점
- Expressivity : 확률로 표현되기 때문에 두 노드의 경로가 긴 경우에도 이웃 정보를 잡아낼 수 있다.
- Efficiency : 모든 노드를 고려할 필요없이 랜덤워크 시에 동시 등장하는 노드 쌍만 고려하면 된다.
✔️ Random Walk Optimization
- Process
- Graph 의 각 node 에서 정해진 짧은 길이 만큼의 random walk 수행한다 (using Strategy R)
- 각 node 의 neighborhood N(u)를 수집.
- node u가 주어졌을 때, 해당 node의 N(u)를 찰 예측하는 방향으로 node embedding.
- Graph의 모든 node에 대해서 각 node의 neighborhood가 random walk 시에 동시에 발견될 확률이 높아지도록 embedding 학습
- Loss를 최소화 하는 방향으로 계속 업데이트
- 그러나, 시간복잡도가 너무 커져버린다.
Negative Sampling
전체 노드에 대해 내적값을 구하는 대신 노드 u와 이웃하지 않은 노드 중 k개를 샘플링하여 사용한다.
- 이웃 노드 간의 확률은 높아지고, 이웃하지 않은 노드 간 확률은 낮아지도록 최적화
- k가 커질수록 근사한 값을 구할 수 있지만 네거티브 샘플에 너무 bias될 수 있기 때문에 보통 5~20을 사용한다.
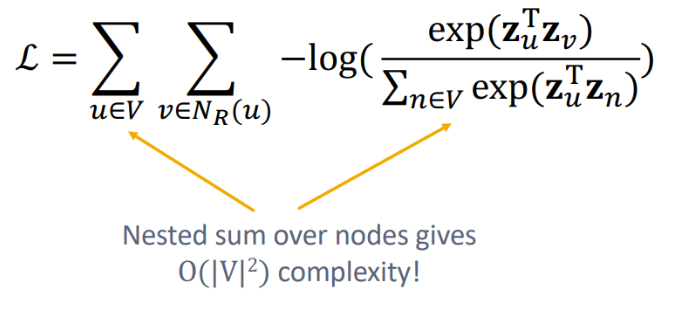
📁 Node2Vec
flexible, biased random walk를 이용하여 지역적 정보와 그래프 전체 정보 간의 tradeoff 관계를 확보하는 것
- 장점 : 빠르게 학습할 수 있다
- 단점 : 그래프 크기가 커질 수록 임베딩 차원의 수가 커진다
✔️ Biased Random Walks
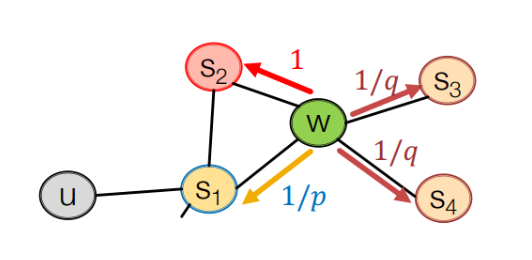
두가지 파라미터를 가진다
- p : 직전 노드로 돌아갈 확률을 정하는 파라미터
- q : 직전 노드에서 먼 노드로 갈 확률을 정하는 파라미터
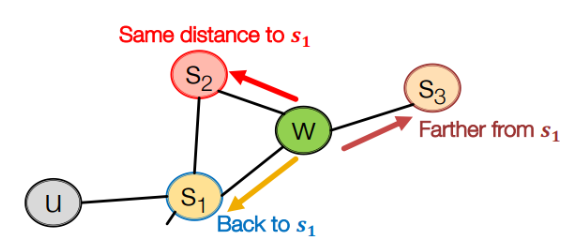
위 그림에서 랜덤워크가 s1에서 w로 이동한 상태라고 할 때, 다음 방향은 세가지이다.
- S1 : 직전 노드로 돌아가기
- S2 : 현재 노드와 직전 노드 간의 거리와 동일한 노드로 이동
- S3 : 현재 노드와 직전 노드 간의 거리보다 먼 노드로 이동
- 각 노드로 이동할 확률분포가 p와 q에 의해 결정된다.
- 랜덤워크이지만 확률 분포가 uniform하지 않고 p와 q에 따라 biased되기 때문에 biased random walk라고 부른다.
- p가 작은 값을 가지게 되면 직전 노드로 돌아갈 확률이 커진다 -> 너비 우선 탐색(BFS)과 비슷
- q가 작은 값을 가지면 먼 노드로 이동할 확률이 커진다 -> 깊이 우선 탐색(DFS)과 비슷
✔️ node2vec algorithm
- Random walk 확률 계산
- 각 노드 u에서 출발하여 길이 l짜리 random walk를 r개 simulate
- SGD를 이용하여 node2vec objective 최적화
📁 Embedding Entire Graphs
Approach 1.
graph의 각 노드를 임베딩하고, 임베딩 값을 모두 더하거나 평균을 낸다.
Approach 2.
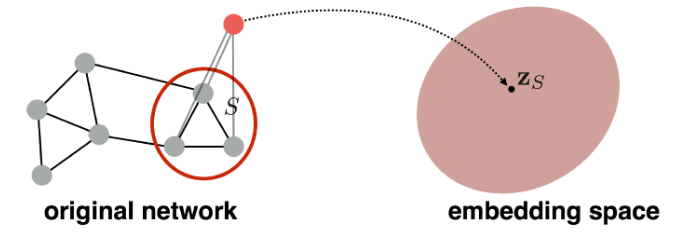
graph를 대표하는 virtual node(= super-node)만 임베딩하여 사용
Approach 3. Anonymous Walk Embeddings
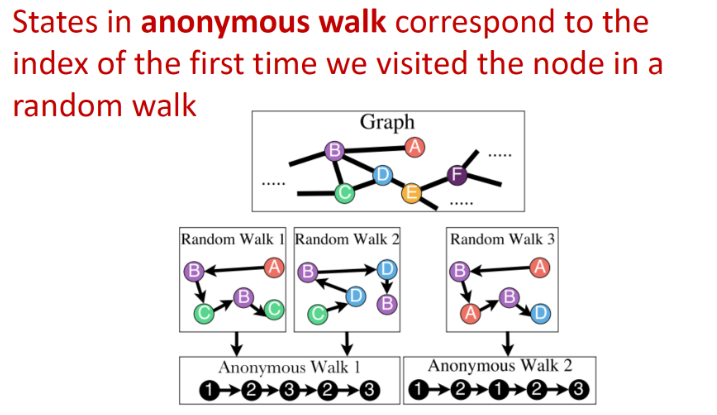
랜덤 node에서 시작해 random walk를 진행. 방문 순서대로 index를 뽑아서 저장
📁 How to Use Embeddings
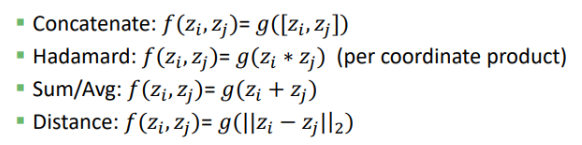
임베딩 벡터 = zi
- 클러스트링, 소셜 네트워크 군집화
- 노드 분류 : zi를 이용해 노드 i의 레이블을 예측한다
- 링크 예측 : (i,j)의 edge를 두 노드의 임베딩 벡터 (zi, zj)를 이용하여 예측할 수 있다.
- 그래프 분류 : 노드 임베딩을 결합해 그래프 임베딩을 생성하거나 anonymouse random walks를 이용해 만든 그래프 임베딩을 통해 분류 task를 수행할 수 있다.
🔨 Summary
Encoder-decoder framework
- Encoder: embedding lookup
- Decoder: predict score based on embedding to match node similarity
Node similarity measure
= (biased) random walk / ex) deepwalk, node2vec
Extension to Graph embedding
= Node embedding aggregation and Anonymous Walk Embeddings
Reference
https://www.youtube.com/watch?v=rMq21iY61SE&list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn&index=7
