강화학습이란?
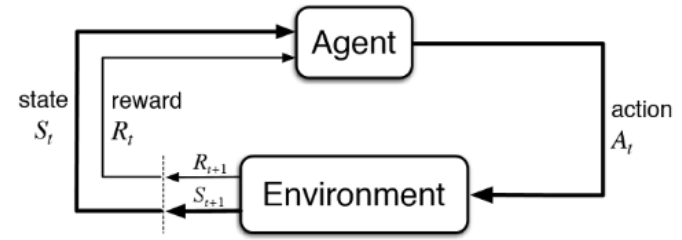
강화학습은 discrete time 에서 stochastic 하게 agent를 control하는 문제이다.
- Agent는 Policy에 따라 행동을 결정한다
- Agent의 행동에 따라 상태가 전이된다
- 전이된 상태에서의 Reward를 Agent에게 준다
- Agent는 Reward에 따라 자신의 Policy를 수정한다
-> Reward가 높았던 행동은 확률을 높여 다음 번엔 더 많이 하도록 기록 / 낮은 경우는 반대로
-> 직접 반복적으로 수행하며 학습된다 / " 시행착오를 통해 배운다" 라고 표현한다
-
Agent : 학습하는 대상으로 환경 속에서 행동하는 개체를 의미한다
-
Environment : Agent와 상호작용하는 환경 / 강화학습은 Agent와 Environment간의 상호작용이다
-
Policy : Agnet가 행동을 결정하는 규칙
-
Reward : Agent에게 주는 보상(쾌락)
-
Discrete time(이산 시간) : 시간 변수가 특정 지점에서만 값을 갖는다 / 시점 구분이 가능하다
-
Stochastic : 확률적
-
State transition(상태 전이) : 한 상태에서 다른 상태로 넘어가는 행위 / 단, 의사결정 없이 엔트로피 증가와 같이 자연스럽게 일어나는 상태의 이동만을 의미한다
-
Stochastic Control : 확률적으로 의사 결정을 한다
다른 머신러닝과 차이점?
- supervisor(지도자) 없이 스스로 학습하여 결정
- action을 했을 때 reward가 즉각적으로 나오지 않을 수 있다 = Feedback is delayed
- Time really matters
- 별개의 데이터 set이 존재하는 것이 아니기 때문에 Agent의 action이 데이터에 영향을 준다
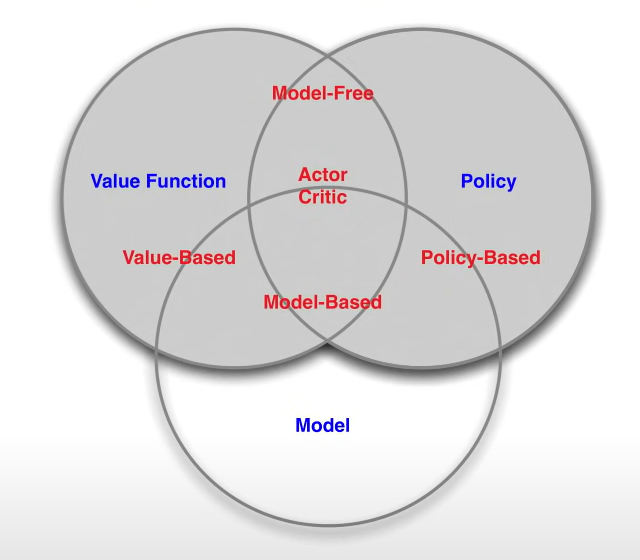
Agent
학습하는 대상으로 환경 속에서 행동하는 개체
- Policy
- Value function
- Model
-> 이 세 요소들을 가진다 / 무조건 다 가져야하는 것이 아님! 하나만 가질 수도 있다
Rewards
Reward = scalar 값 = feedback signal
축적된 reward를 최대화 하는 것이 Agent의 목적
Reward는 명확하게 좋고 나쁨을 따질 수 있어야하기 때문에 잘 정의하는 것이 중요하다
ex) 로봇이 잘 걷는다 -> +10 / 로봇이 넘어졌다 -> -10
Policy
Agent의 행동을 결정하는 규칙
- Deterministic policy : a= π(s)
= state를 던져주면 바로 action이 매핑된다- Stochastic Policy : π(a|s) : S,A -> [0,1]
= action a를 state s에서 행할 확률 = state s에서 할 수 있는 모든 행동들 중에 한 a를 선택하는 것
Value Function
Prediction of future reward -> 상황이 얼마나 좋은지 평가해준다
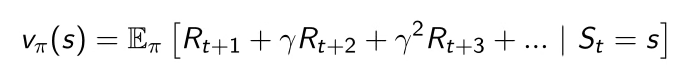
Model
Predicts what the environment will do next
-> 불완전할 수 있다
Model-base vs Model-free
- Model-free 알고리즘 : agent가 환경을 완전히 알지 못하는 문제(MDF를 모를 때 = 보상함수와 전이 확률을 모를 때)에 적용하는 알고리즘
-> 현실의 대부분 문제들은 모든 것을 완벽히 통제할 수 없기 때문에- Modle-based 알고리즘 : agent가 환경에 대해 모든 확률을 알고 있을 경우(MDF를 알고있을 때)에 적용하는 알고리즘
Exploration vs Exploitation
- Exploration(탐험) : finds more information about the environment
- Exploitation : exploits known information -> Reward 최대화
Prediction & Control
- Prediction : 미래를 예측 = Value Funcion을 학습시킨다
- Control : 미래를 최적화 = best policy를 찾는 것
