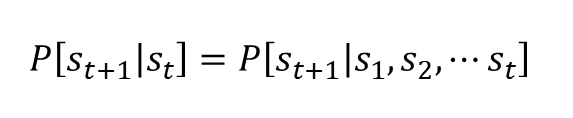Markov Decision Process(MDP)
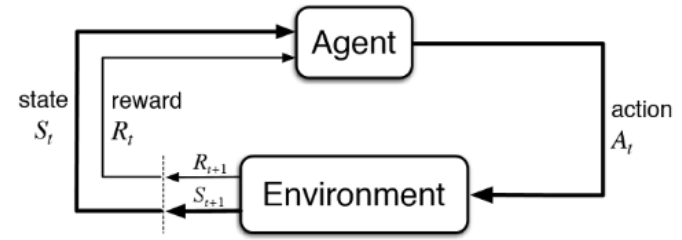
State에서 action을 해서 그에 대한 reward를 받고 새로운 state로 나아간다
- S - A - R - S' 가 계속 반복된다 / S0 A0 R1 S1 A1 R2 S2 A2 ....
- Agent : MDP에서 문제를 학습하고 행동을 결정하는 주체
- Environment : Agent와 상호작용하는 모든 외부 환경
- Policy π : 특정 시점에 agent가 수행할 행동을 결정하는 규칙
- State St : Agent의 t 시점의 상태나 얻은 정보
- Reward Rt : Agent가 t-1 시점의 action으로 받은 보상
- Action At : Agent가 t 시점에 행한 행동
Goal
= Expected(평균) Return(Gt)을 Maximize 하는 최적의 Poilcy를 찾는 것
- Return(Gt) = 현재 시점에서 에피소드가 끝날 때까지 받은 장기적인 보상
- 에피소드 : 초기상태(intial state)부터 종결 상태까지의 과정
- γ = discount rate
-> [ 0,1 ] 의 값이며, 값을 step마다 곱해주어 미래의 보상에 대한 페널티를 준다
-> Return을 구하기 위해서는 종결 시점까지 모두 경험한 후에야 계산이 가능하다. 종결까지 시점마다의 Reward를 모두 저장해두고, 에피소드가 끝나면 뒤에서부터 저장한 Reward를 하나씩 더해가며 계산할 수 있다.
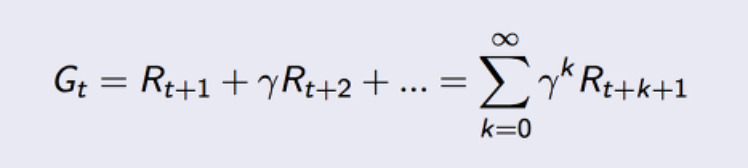
Markov property (마르코프 성질)
미래 상태로의 변화가 과거 상태와는 독립적으로 현재 상태에만 의해서만 결정된다
현재 상태에 과거 상태의 정보가 모두 포함되어 있다
- 과거 상태를 전부 고려하는 확률 = 현재 상태만 고려한 확률
- memoryless한 성질 - 과거를 잊어버린다