1. 딥러닝의 key component
1) Data
모델이 학습할 데이터.
이 데이터의 종류/형태는 우리가 해결하고자하는 문제의 종류에 따라 달라지게 된다.
2) Model
Input 데이터를 Output의 형태로 변형시킬 모델.
구체적으로 AlexNet, GoogLeNet, ResNet, LSTM, GAN 등이 해당된다.
3) Loss function
모델의 성능을 평가할 수 있는 loss function.
주의해야할 것은 loss function이 줄어든다고 문제가 해결되는 것이 아니다. loss function은 오차 그 자체가 아니라 우리가 해결하고자 하는 문제에 대한 근사치에 불과하다는 것을 인지해야 한다. 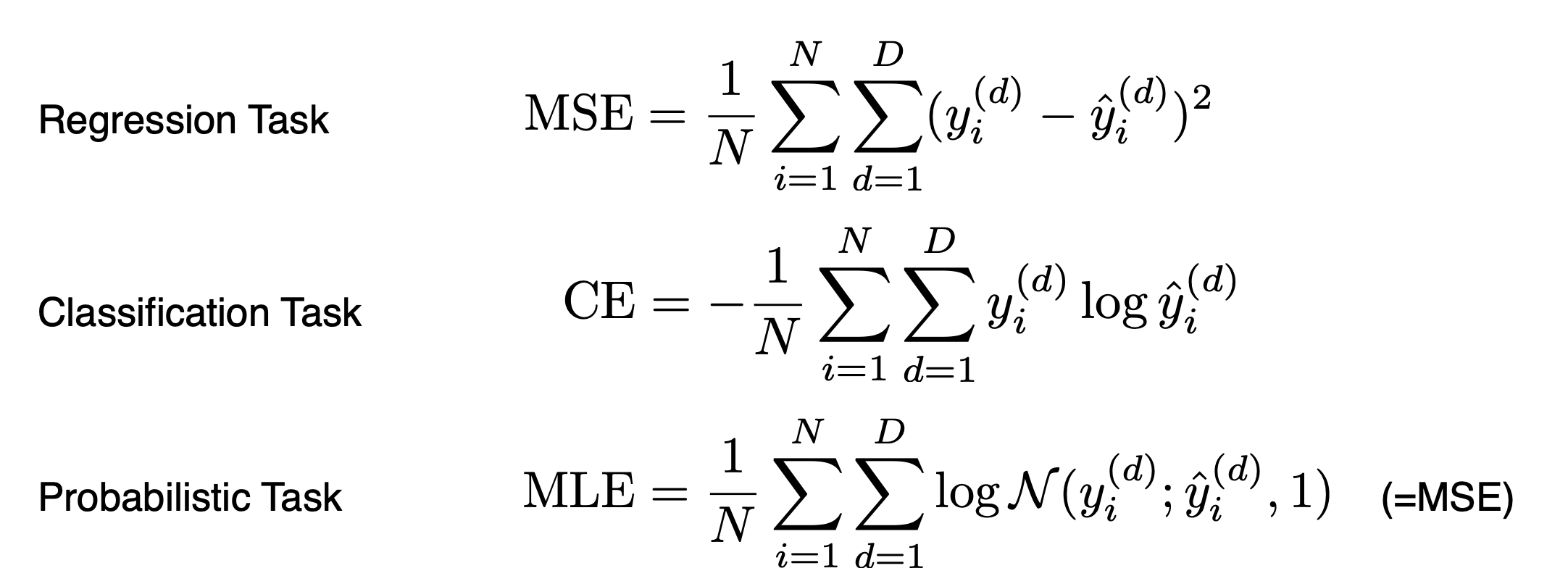
(참고) Classification task에 활용되는 CE는 Cross Entropy 의 약자로, 주로 분류 문제에서는 cross entropy loss 를 최소화하도록 모델링을 한다.
Probabilistic Task에 활용되는 MLE는 Maximum Likelihood estimation으로, 이를 최소화하는 것이 목표이다.
4) Algorithm
Loss를 최소화할 수 있도록 조정하는 파라미터 (e.g., SGD, Adam etc.)
Dropout, k-fold validation 등 다양한 테크닉을 통해 test data에서도 잘 동작하도록 모델을 설계하는 것이 중요하다.
History of DL
(2012) AlexNet: CNN형태의 간단한 DL
(2013) DQN: 알파고를 만든 장본인
(2014) Encoder/Decoder: 번역기의 엄청난 발전...
(2014) Adam Optimizer: adaptive momentum 활용
(2015) Generative Adversarial Network
(2015) Residual Networks
(2017) Transformer
(2018) BERT (fine-tuned NLP models)
(2019) BIG Language Models: GPT-3..
(2020) Self Supervised Learning
