Neural Networks는 직선과 평형성을 유지하는 변환(Wx+b)인 affine transformation 과 비선형 연산(Nonlinear Tranformations)의 합이다.
구체적인 과정에 대해 쉬운 예시로 시작해보자.
우리의 목표는 최적의 모델을 찾는 것. 이 예시에서는 가중치행렬 w와 bias b를 잘 찾는게 중요하다. 모두 알다시피 아래의 loss는 MSE를 사용하고 있다. 일일히 말하자면 다음과 같다.
1) 적절한 데이터를 준비하고
2) 가장 적합할 것 같은 모델을 마련한다.
3) 그리고 적절한 loss function을 마련한다.
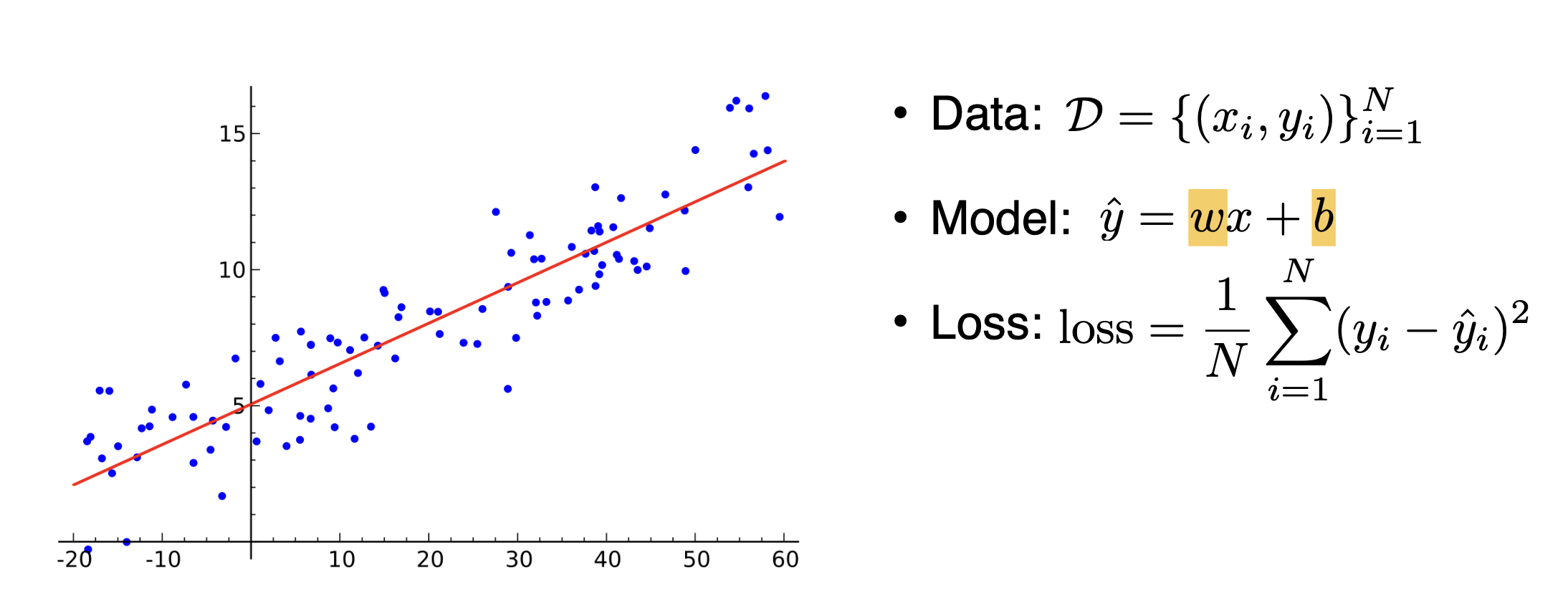
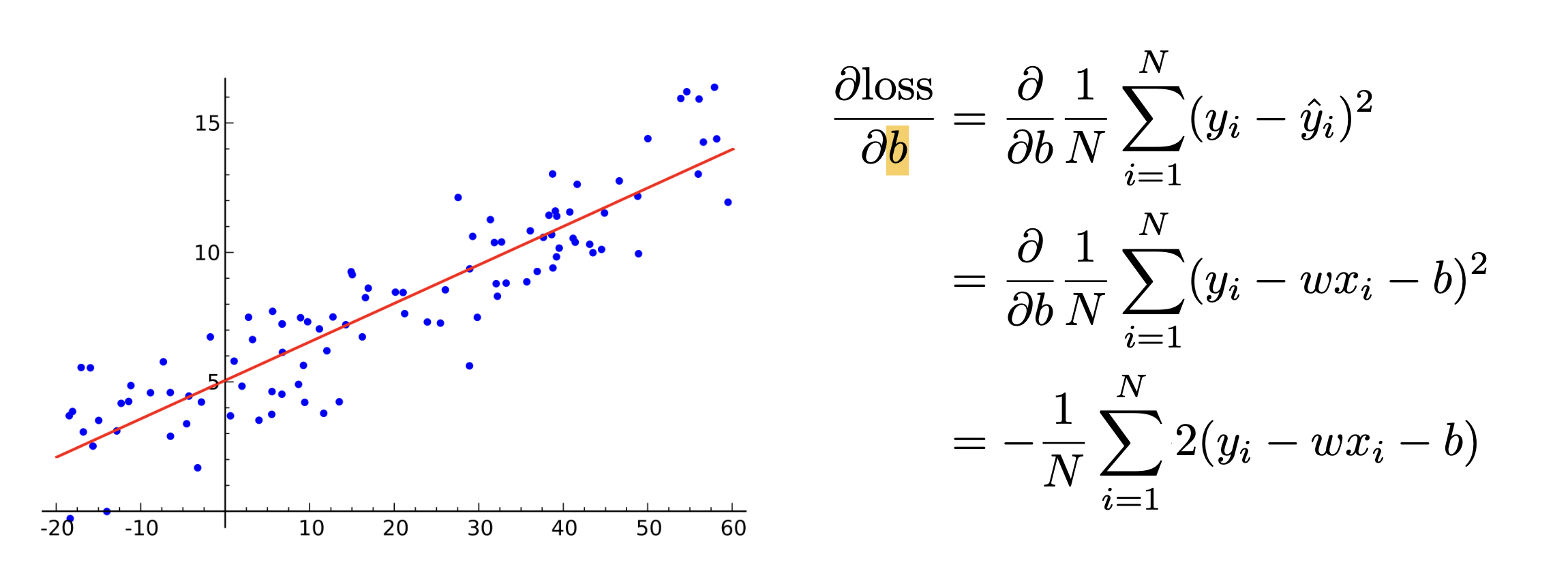
4) 그 다음 해야할 것은 loss function을 편미분해준다. 특히 각각 w와 b에 대해 편미분을 해준다. 
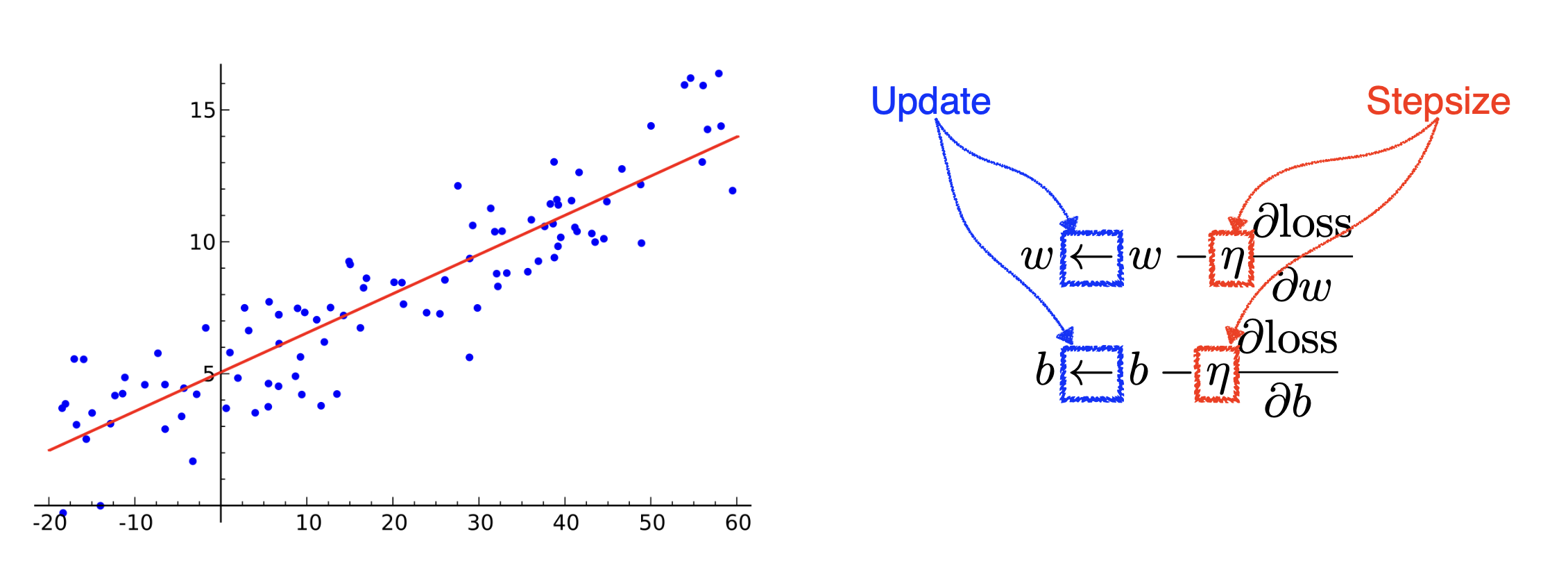
5) gradient descent를 수행한다. 즉, gradient 값에 적절한 learning rate (stepsize)를 지정하여 곱해준 값을 빼가면서 weight와 bias를 업데이터 해간다. 점점 오차를 줄이는 방향으로 간다고 생각하면 된다. 이 때 learning rate를 적절하게 잡는 것이 중요하다.
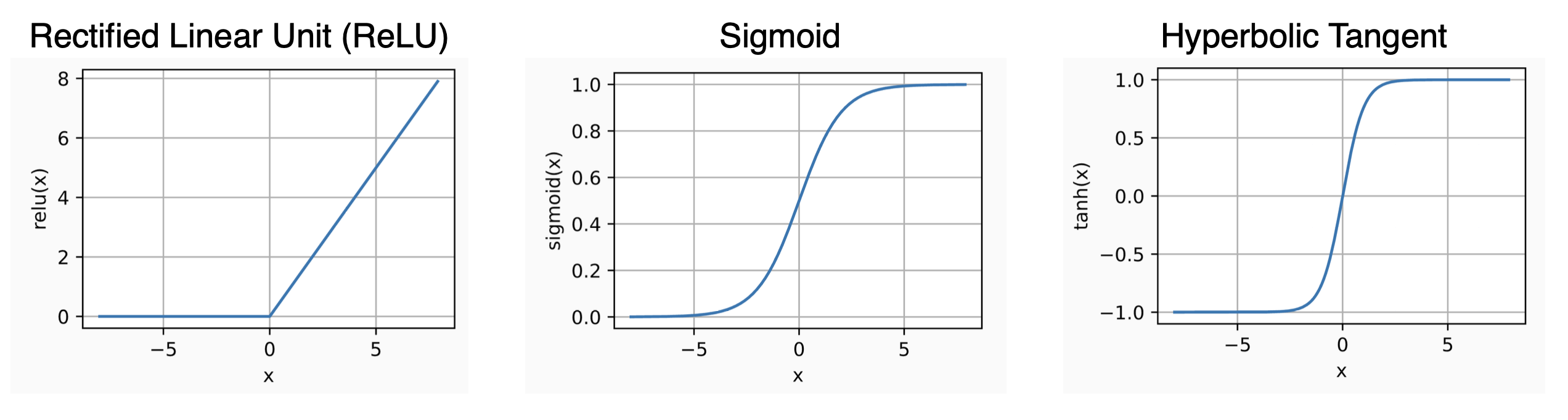
Activation Function
그냥 단순히 linear한 layer를 쌓는 것은 의미가 없다. linear * linear = linear이기 때문이다. 우리는 nonlinear transform을 해줄 수 있는 activation function이 필요하다. 다음과 같은 activation function이 존재하며, 어떤게 가장 좋을지는 문제마다 다르다. 주로 leaky ReLU를 사용하는 것으로 알고 있다.
Loss Function
다양한 loss function이 있다. 각 함수가 어떤 성질을 가지고 있는지를 파악함으로써, 이 함수를 통해 내가 원하는 결과를 얻어낼 수 있는지를 명확히 아는 것이 중요하다.
1) Mean Squared Error (MSE)
노이즈, outlier에 취약하다는 단점이 있다. 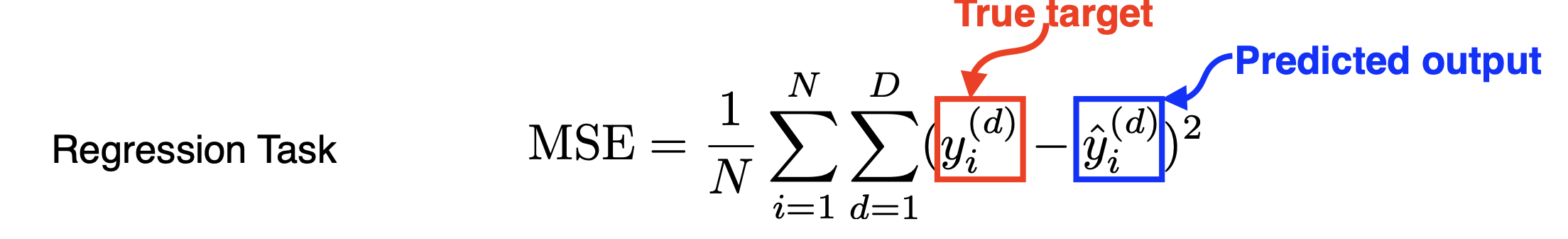
2) Cross Entropy Loss (CE)
분류문제의 output은 주로 one-hot vector이다. 즉, 정답()만 1이고 나머지는 0인 벡터라는 의미이다.
따라서 cross entropy loss를 활용해서 loss를 minimize하게 되면 logit (), 즉 나의 neural network 출력값 중 정답 클래스의 값만 높인다는 뜻이다. 다른 클래스에 비해 얼마나 높은지가 사실상 중요한데 말이다.
구체적으로 말하자면, 사실 정확도 관점에서 정답 클래스의 output 값이 10인지 1000인지가 중요한게 아니라 다른 클래스의 output대비 정답 클래스의 값이 높으면 되는 것이다. 그런데 이걸 수학적으로 구현하기 어려워서 그냥 이걸 사용하는 것이라고 한다. 
3) Maximum Likelihood Estimation (MLE)
log likelihood를 maximize하는 식이다. 이는 probabilistic task에서 주로 활용되는데, probabilistic task란, 각 클래스에 속할 확률을 예측하는 작업이다. 즉, output이 숫자가 아니라 확률적인 모델이 되도록 하고 싶을 때 사용하며, uncertainty 정보를 같이 확인하고 싶을 때 이용한다.
예를 들어, 강아지 고양이 사진 분류 예제에서 강아지일 확률 30%, 고양이일 확률 70% 이런 방식으로 예측하는 것이다.
이러한 probabilistic task에 MLE가 사용되는 이유는 무엇일까?
확률적 작업에서는 데이터가 특정 확률 분포를 따른다고 가정한다. 이때 MLE는 그 분포의 파라미터를 추정하는 데 가장 적합한 방법이다. MLE는 확률적 모델의 파라미터를 추정하는 방법이기 때문이다. 즉, MLE는 모델이 데이터를 생성할 확률을 최대화하는 파라미터를 찾는다.
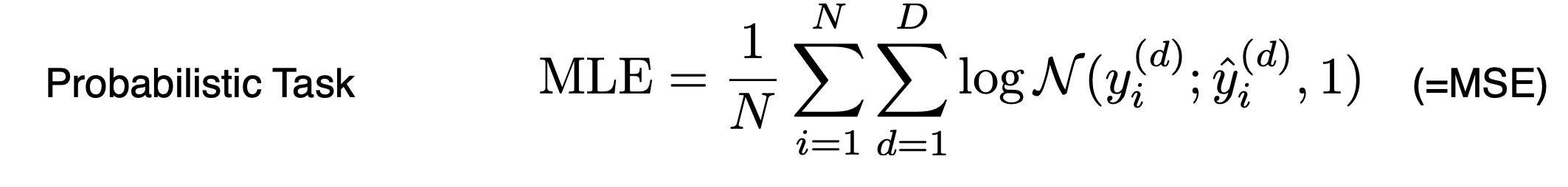
Chat GPT에게 물어본 결과, MLE의 단점은 다음과 같다.
-
샘플 크기 의존성: 작은 샘플에서는 MLE가 편향될 수 있습니다. 충분히 큰 샘플이 필요하므로 작은 데이터 세트에서는 덜 신뢰할 수 있습니다.
-
복잡한 모델에 대한 계산 비용:우도 함수를 최대화하는 과정이 복잡한 모델에서는 계산 비용이 매우 높아질 수 있습니다. 특히, 고차원 데이터나 복잡한 확률 모델에서는 최적화 과정이 어렵습니다.
-
초기 가정에 민감: MLE는 모델이 올바르게 지정되었을 때만 좋은 성능을 보입니다. 모델이 잘못 지정되면 MLE는 불완전하거나 편향된 추정치를 제공할 수 있습니다.
-
오버피팅 위험: MLE는 데이터에 가장 잘 맞는 파라미터를 찾으므로, 데이터가 적거나 노이즈가 많은 경우 오버피팅의 위험이 있습니다.
