Regularization이란?
train data의 학습을 방해함으로써 test data에도 잘 동작하도록 하는 기법이다.
1) Early stopping
개념
아래에서 loss가 더 커지기 전에 멈추는 것이다.
훈련 중에 모델의 성능(주로 검증 데이터에 대한 손실 또는 정확도)을 지속적으로 평가한다.
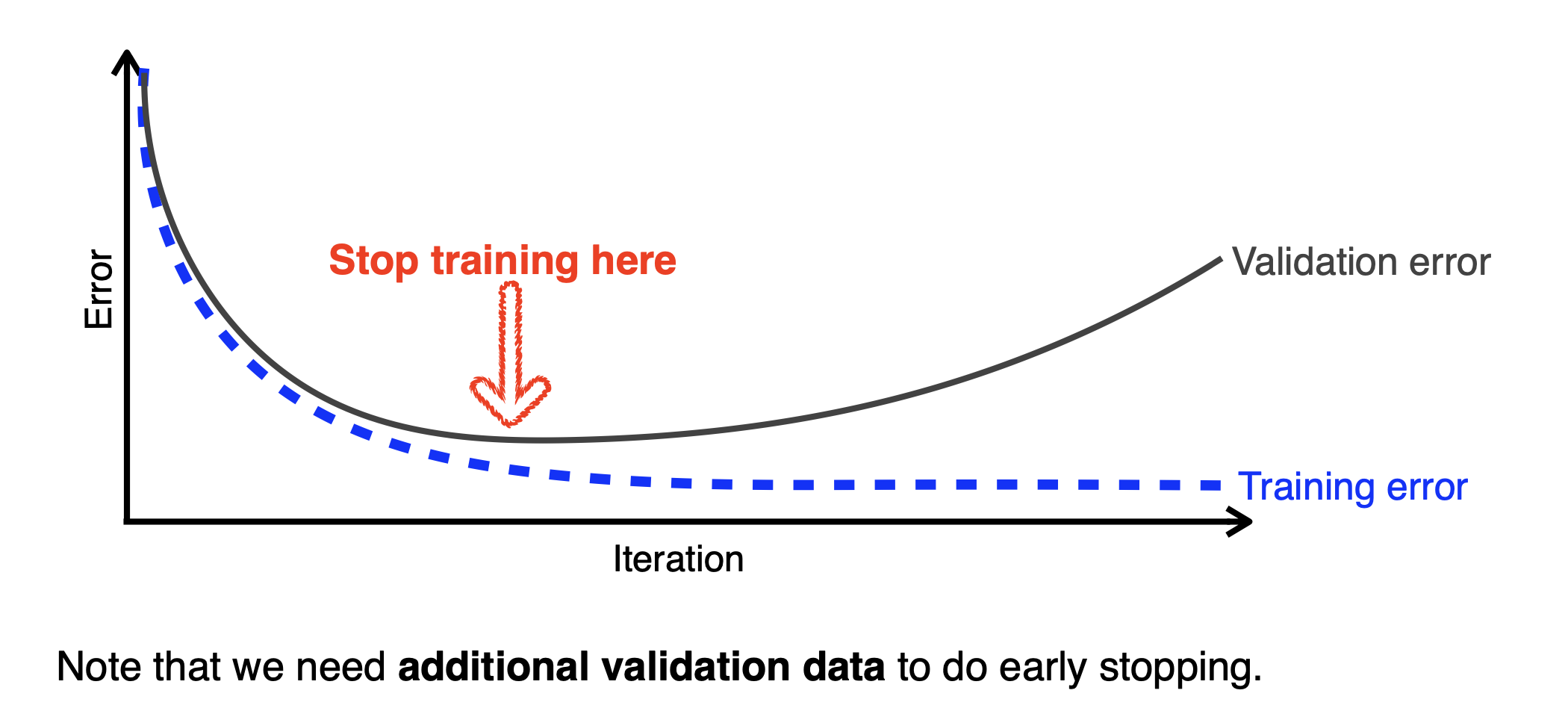
방법
위 개념을 활용하는 구체적인 과정은 다음과 같다.
1. train data 와 validation 분리
2. 모델 학습
모델이 train data를 사용하여 한번의 전체 훈련 사이클(epoch)을 완료한다.
3. validation data를 통한 모델 평가
각 epoch 후, 혹은 epoch 중 일정 간격마다 validation data를 활용하여 모델의 성능(loss, accuracy ...)을 평가한다.
4. 모델 성능 모니터링
일정 epoch 동안 validation 성능이 개선되지 않으면 훈련을 중단한다.
2) Parameter norm penalty (정규화 항)
개념
모델의 복잡도를 제어하기 위해 손실 함수에 정규화 항을 추가하는 방법이다.
구체적으로 설명하면 다음과 같다. Neural Network 파라미터를 다 제곱한 후 더하면 어떤 숫자가 나온다. 이 숫자를 loss function에 더하고, 이 숫자까지 함께 줄이자는 방법론이다. 즉, weight 자체의 숫자를 작게 만듦으로써 함수공간 속에서 최대한 부드러운 함수를 만들자는 것이다. (물론 여기에는 부드러운 함수일수록 generalization performance가 높을 것이다라는 가정이 있는 것이다.)
방법
대표적인 정규화 기법으로는 L1 정규화와 L2 정규화가 있다.
- L1 정규화: 가중치의 절대값의 합을 최소화한다:
- L2 정규화: 가중치의 제곱합을 최소화한다:

3) Data augmentation
개념
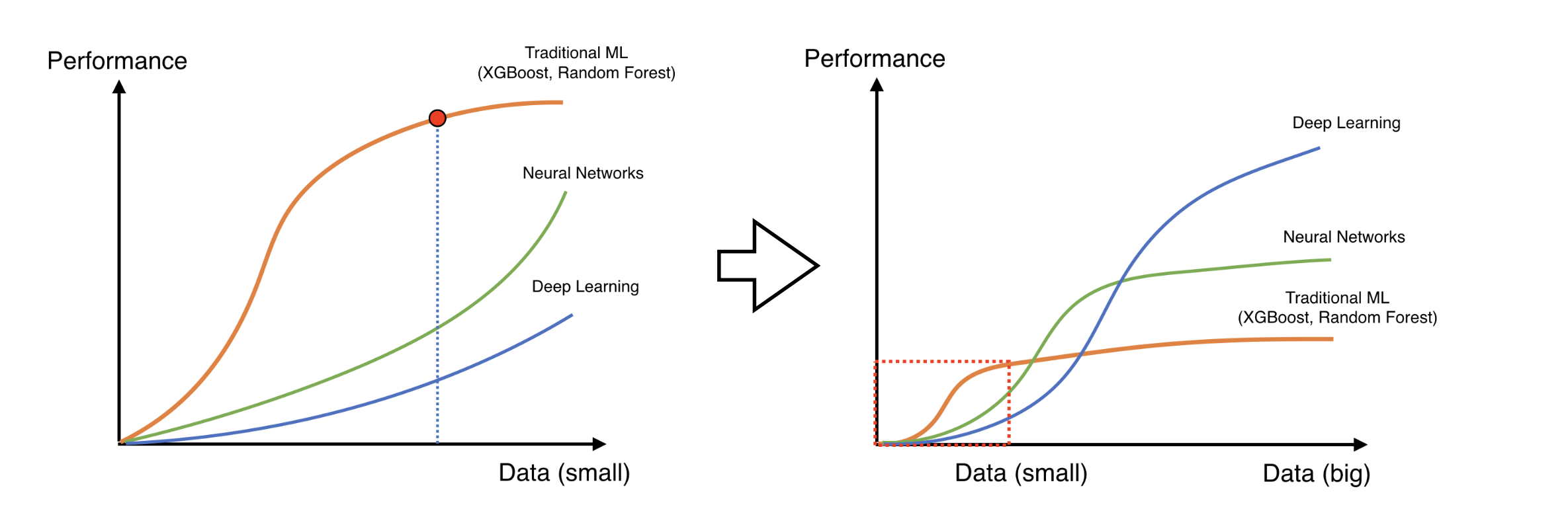
대부분 training data가 많을수록 모델의 성능이 좋아진다. 그런데 우리가 가지고 있는 데이터는 한정적이지 않는가. 따라서 우리가 가지고 있는 데이터를 이미지 라벨이 바뀌지 않는 한도 내에서 변화시킴으로써 데이터 수를 늘리는 것이다.
예를 들어 MNIST Data에서 6 이미지를 뒤집어서 9로 만들어버리면 라벨 자체가 바뀌니까 이건 잘못 augment한 것이다. 이렇게 되지 않는 한도 내에서 augment하면 된다.
방법
대표적인 변형 방법으로는 회전, 이동, 확대/축소, 색상 변화 등이 있다.
4) Noise robustness
개념
모델이 데이터의 노이즈에 robust하도록 설계하는 방법이다.
방법
1. training data에 인위적으로 노이즈 추가함으로써 모델이 노이즈에 내성을 가지도록 훈련한다.
예를 들어, 이미지 데이터에서 각 픽셀 값에 작은 랜덤 값을 더하거나, 텍스트 데이터에서 단어를 무작위로 변환 또는 생략하는 방식이 해당된다.
2. 모델의 weight에 노이즈 추가함으로써 모델이 더 robust하게 학습되도록 한다.
구체적으로, 매 학습 단계마다 작은 랜덤 노이즈 (평균이 0이고, 작은 분산을 가지는 정규분포를 따르는 가중치 노이즈)를 더해주게 된다.
이는 weight를 흔들어주면 오히려 학습 과정에서 더 다양한 경로를 탐색하게 되어, 더 좋은 최적해를 찾을 가능성을 높인다는 장점이 있으며, 모델의 가중치가 특정 값에 과도하게 수렴하는 것을 방지함으로써 모델의 generalization performance를 높이게 된다.

5) Label smoothing
개념
training data 2개를 뽑아서 섞어줌으로써 model의 decision boundary를 부드럽게 만들어 generalization performance를 향상시키는 방법이다. 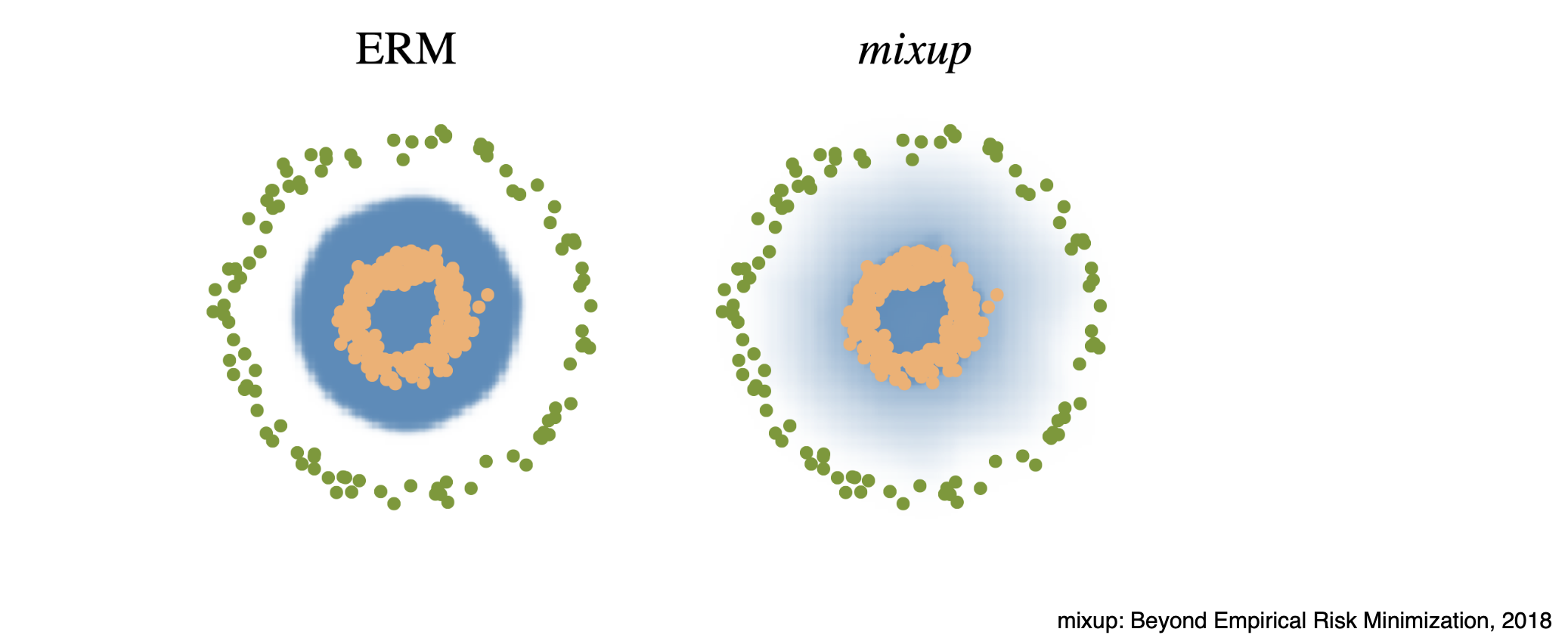
방법
원-핫 인코딩된 레이블을 약간 부드럽게 하여 정답 레이블의 확률 값을 1에서 약간 감소시키고 나머지 클래스에 약간의 확률을 분배한다.

실제로 교수님 말씀에 따르면, 위의 Mixup을 해줄 경우 성능이 확 올라간다고 한다.
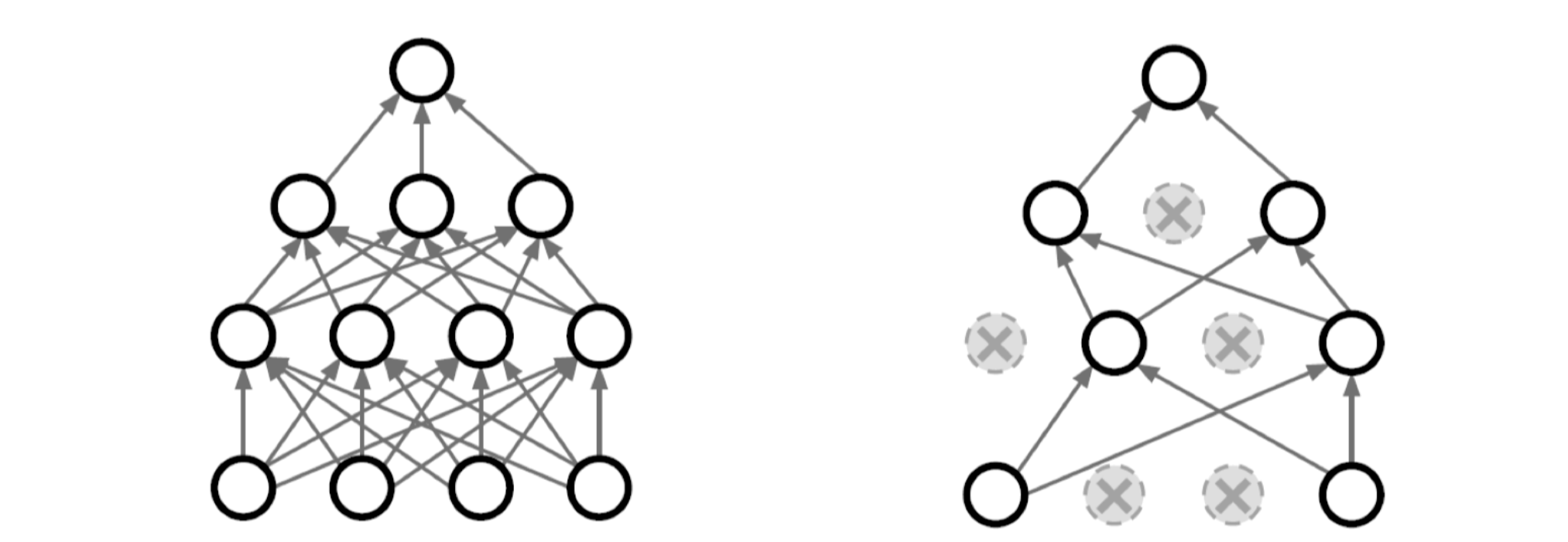
6) Dropout
개념
훈련 과정에서 뉴런의 일부를 무작위로 비활성화하여 과적합을 방지하는 기법이다.
방법
각 훈련 단계에서 neural network의 weight를 무작위로 0으로 바꾸는 것이다.
예를들어, p(dropout ratio)=0.5이면, neural network inference할 때 뉴런의 출력을 레이어마다 50%를 0으로 바꿔준다(비활성화 한다). 이렇게 함으로써 특정 뉴런이나 특정 경로에 과도하게 의존하는 것을 방지하고, 각 뉴런이 좀 더 robust한 feature를 잡을 수 있도록 한다.
7) Batch normalization
논란이 많은 정규화 방법이다. 그러나 대부분 간단한 분류 문제에서, 특히 layer가 깊을수록 성능이 높아진다. 특히 Batch normalization은 Dropout과 함께 사용하면 더욱 효과적이라고 알려져있다.
개념
각 배치마다 입력의 평균과 분산을 정규화하여 학습을 안정화하고 가속화하는 기법이다.
즉, Batch Normalization을 적용하고자 하는 layer의 statistics를 정규화 하는 방법론이다.
방법
구체적으로, 만약 Neural Network의 각 layer가 1000개의 parameter를 가지는 hidden layer를 지니고 있다고 해보자. 그러면 1000개의 parameter 각 값에 대한 통계값이 평균 0, 분산 1이 되도록 만들어주는 것이다. 즉, 원래 값이 모두 100정도의 값을 가진다면 이를 모두 평균 0이 되도록 바꿔주는 것이다.
효과: Internal Covariate Shift
Internal Covariate Shift는 신경망 학습 과정에서 각 층의 입력 데이터 분포가 변화하는 현상을 의미한다. 이는 특히 딥러닝에서 각 층이 학습하는 동안 이전 층의 가중치가 변화함에 따라 입력 데이터의 분포가 변하게 되어 학습이 불안정해지고 수렴 속도가 느려지는 문제를 야기한다. 이것을 Batch normalization이 해결해준다는 의미인데, 이에 대해 논란이 많다고 한다. 암튼 이건 넘어가자
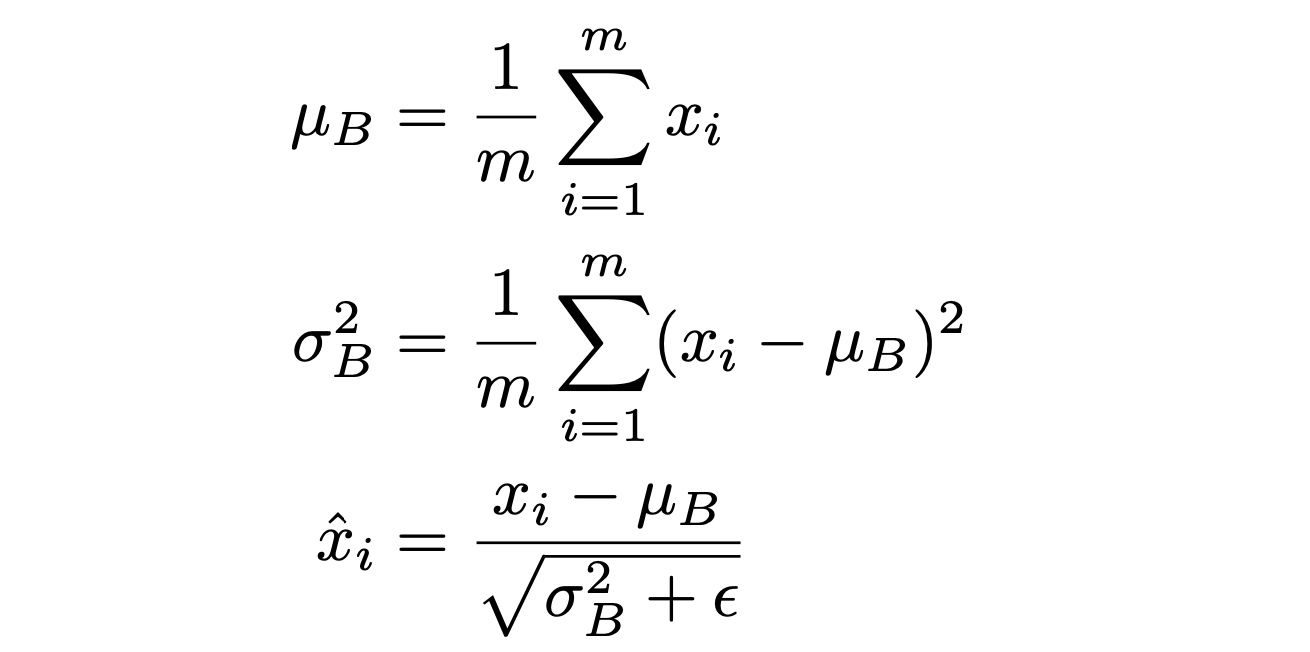
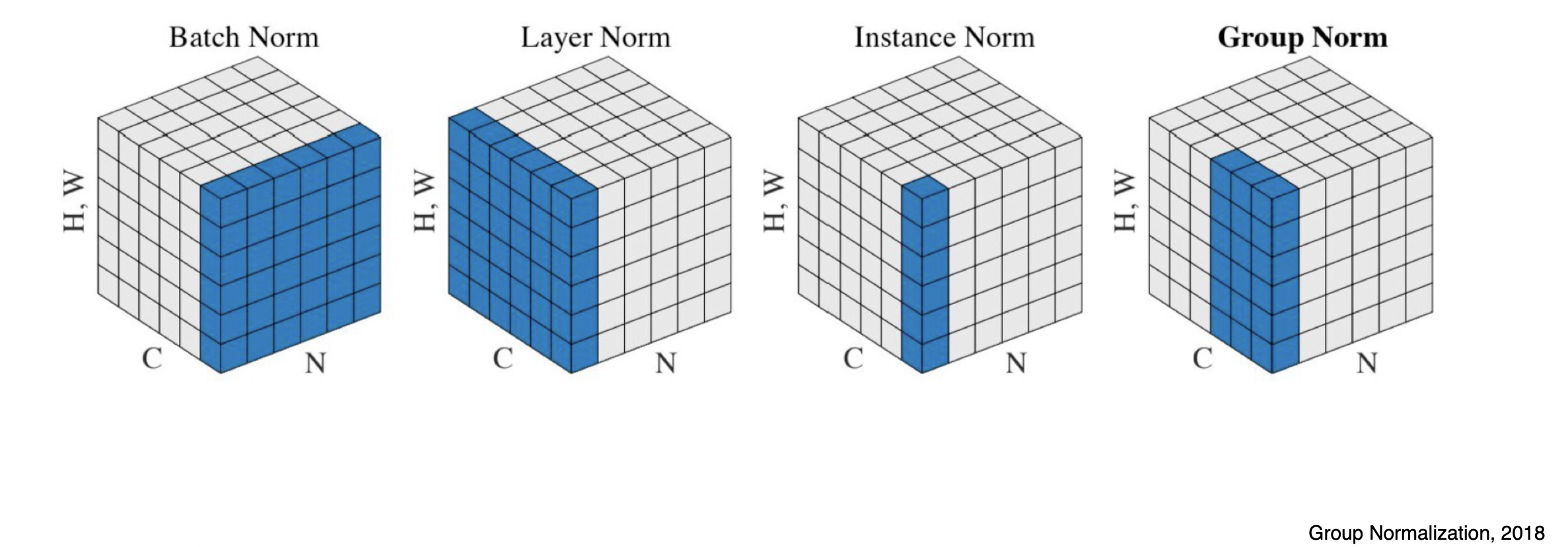
| Batch Norm | Layer Norm | Instance Norm | Group Norm | |
|---|---|---|---|---|
| 계산 범위 | 미니 배치 전체(layer 전체) 정규화 | 동일한 층의 뉴런간 정규화 | 이미지 한장별로 statistics 변경 | layer norm과 instance norm의 중간 |
| 사용 사례 | CNN | RNN, Transformer | GAN, 이미지 스타일 변환 | 이미지 분류 및 탐지,batch size가 극도로 작은 상황에는 배치의 평균과 분산이 전체 데이터셋을 대표하지 못하고, 구해지는 평균과 분산도 매 iteration마다 달라지는 상황에 사용 |
