1) AlexNet
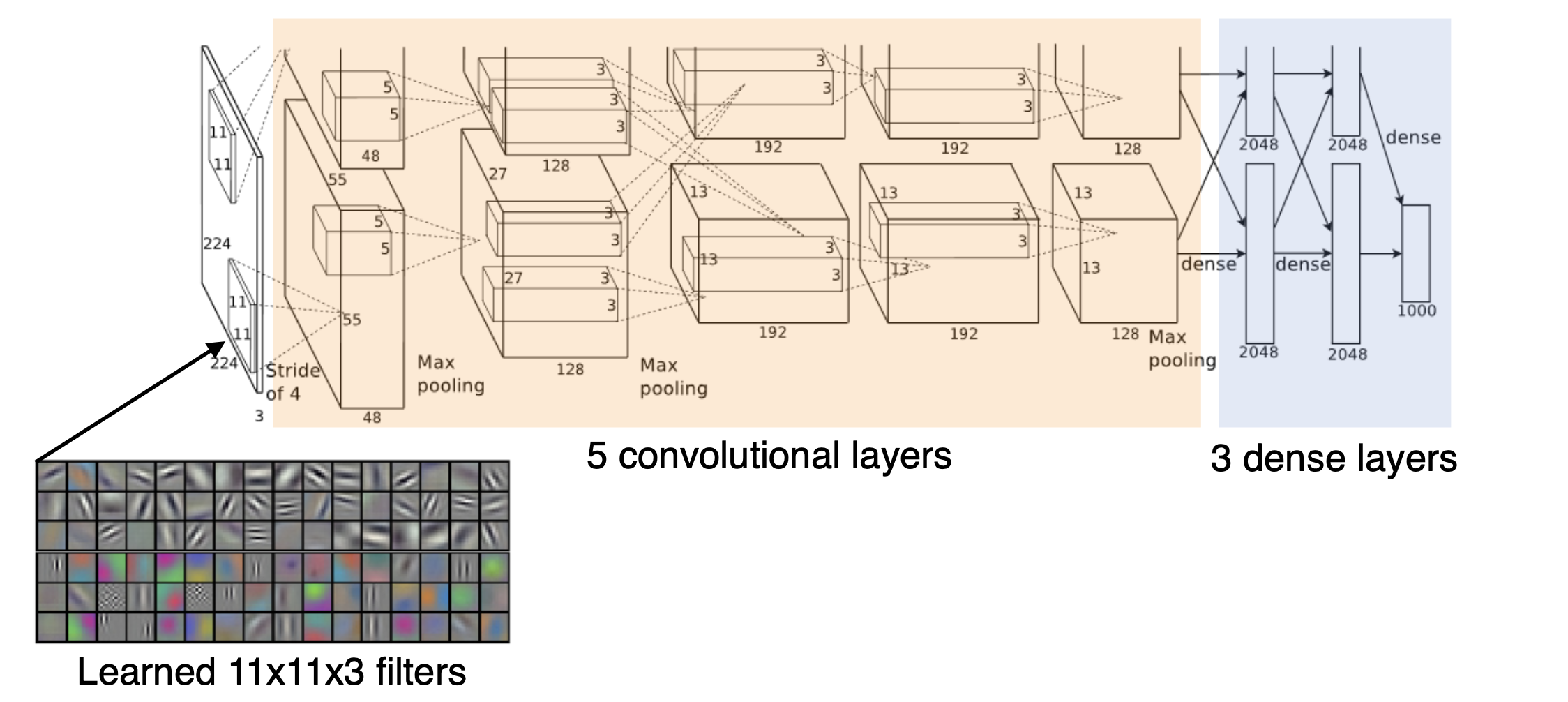
- 특징
- 총 8개 layer (요즘 모델들에 비하면 매우 light함)
- GPU 성능 제한 문제로 네트워크가 2개로 나누어져 있음.
- 파라미터가 11 * 11인 필터 사용. 이는 사실 좋은게 아님. 왜냐하면 필터 사이즈가 커지면 receptive field, 즉 하나의 커널이 볼 수 있는 이미지 레벨에서의 영역이 커지지만 상대적으로 그만큼 더 많은 파라미터를 필요로하기 때문이다.
- AlexNet의 성공 비결
- ReLU 사용
: vanishing gradient 문제를 해결함 + optimize가 용이함 + 결과적으로 generalization이 잘됨. - 2개의 GPU 사용
- Overlapping pooling
- Data augmentation
- Dropout
- ReLU 사용
지금 보면 당연한 것들이지만 당시에는 당연하지 않았다는 사실~
2) VGGNet
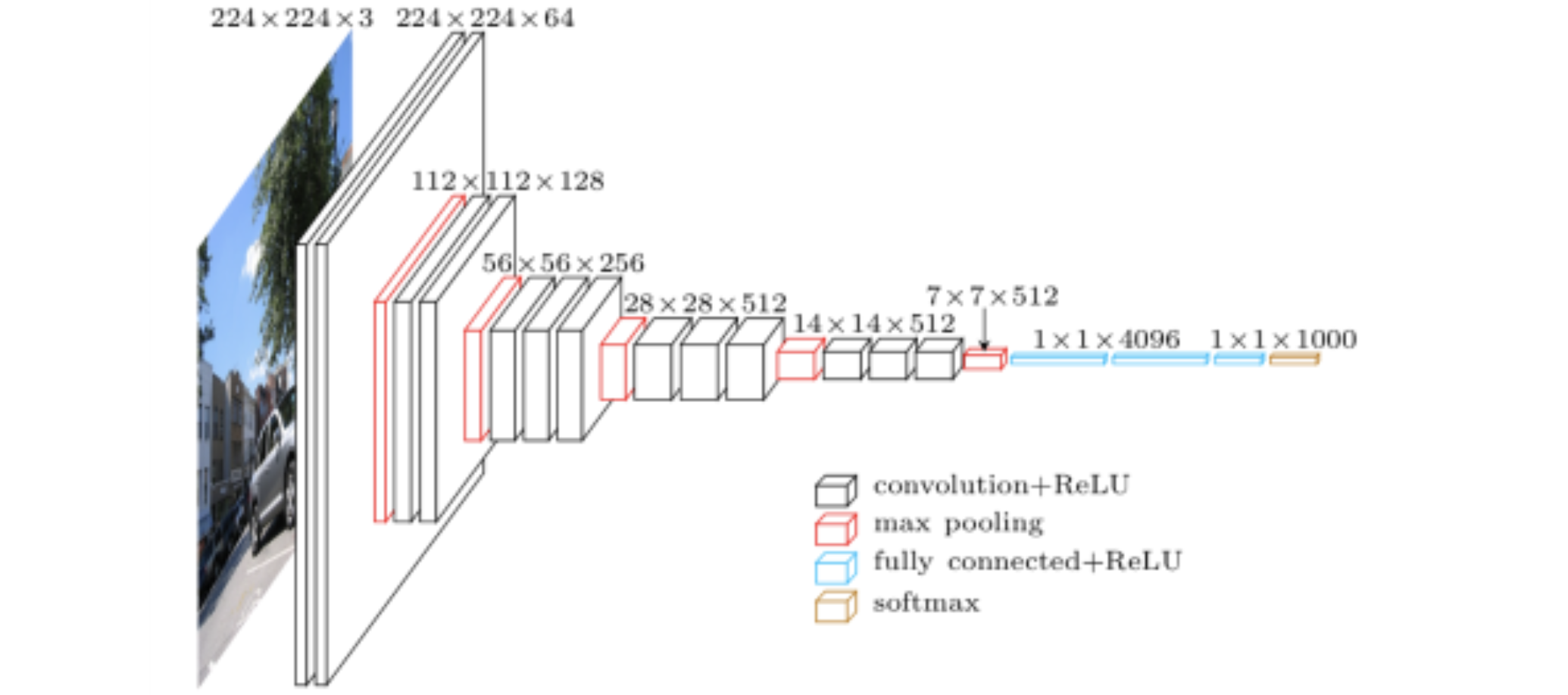
-
특징
- 3X3 convolution filter (with stride 1)을 사용하여 depth를 늘림
- Dropout (p=0.5)
- VGG16, VGG19가 있음 (여기서 숫자는 layer개수임)
-
VGGNet의 성공 비결: 3X3 convolution
필터 사이즈가 커지면 가지는 이점은Receptive field(=한 셀의 convolution feature map을 갖기 위해 고려하는 입력의 spatial demension)가커진다는 것이다. 즉, 딥러닝 모델이 입력 데이터의 더 넓은 영역을 한 번에 볼 수 있게 되는 것이다. 이것의 장점은 1) 단순한 로컬 패턴을 넘어서 더 복잡한 글로벌 패턴을 학습할 수 있고, 2) 모델이 노이즈나 작은 변화에 robust해지며, 3) 로컬 feature를 결합하여 더 풍부한 표현이 가능하다는 것이 있다.
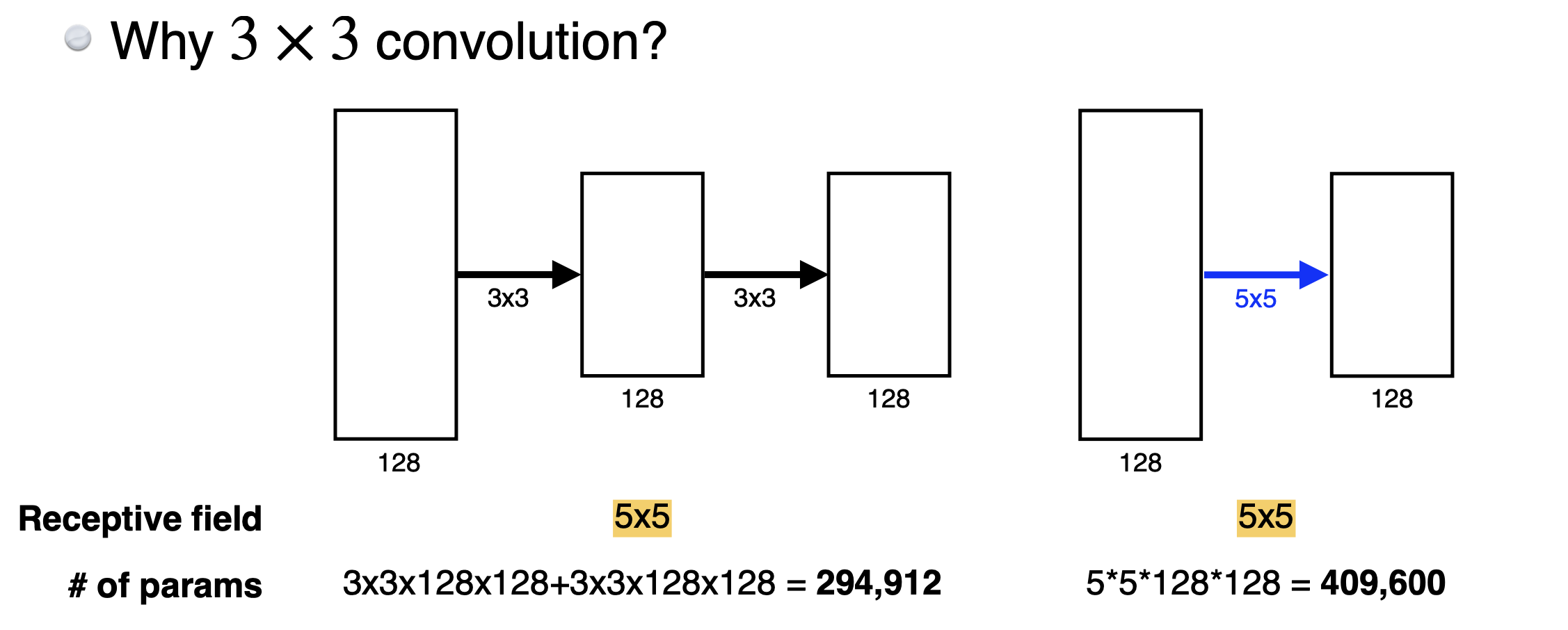
그런데 반대로 단점은 파라미터 수가 너무 커진다는 단점이 있다. 이 때 VGGNet은 receptive field는 유지하면서 파라미터 수를 줄일 수 있는 방법을 제시한 것이다.
구체적으로, 3x3 필터 2개를 사용하는 것과 5x5 필터 1개를 사용하는 것을 비교해보자. 파라미터 수는 아래 이미지와 같이 3x3 2개가 훨씬 적다는 것을 볼 수 있다. 그런데 receptive field는 둘이 동일하다. 왜냐하면 1) 3x3 필터 하나를 지나면 다음 레이어의 하나의 픽셀에 3개의 픽셀 정보가 합쳐지게 된다. 그리고 2) 두번째 레이어에서 (이전3개 픽셀 정보를 갖고 있는 셀 1개 + 주변(가로, 세로) 셀 2개) = 3개의 셀을 한번에 고려하여 다음 레이어로 넘어가게 된다. 따라서 총 3+(3-1)=5 의 수용영역이 되는 것이다.
3) GoogLeNet
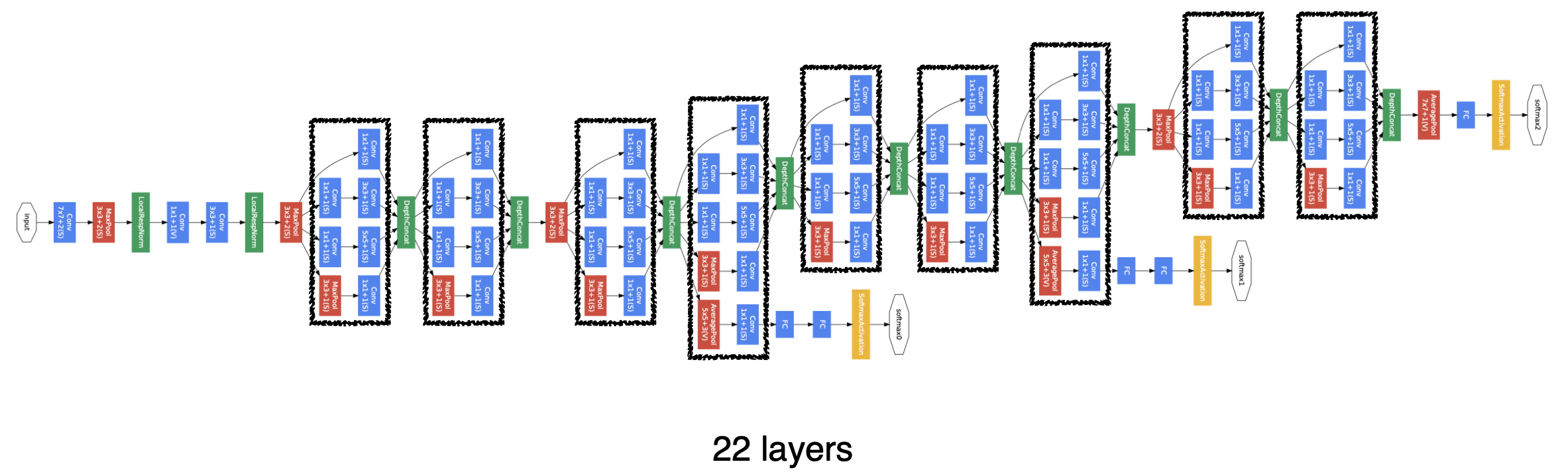
-
특징
- 비슷한 네트워크가 반복되는 구조이다. 이를 네트워크 안에 네트워크가 있다고 하여
Network-in-Network (NIN) 구조라고 부른다. Inception Blocks: 하나의 입력이 들어왔을 때 여러개로 퍼졌다가 다시 하나로 합쳐지는 형태
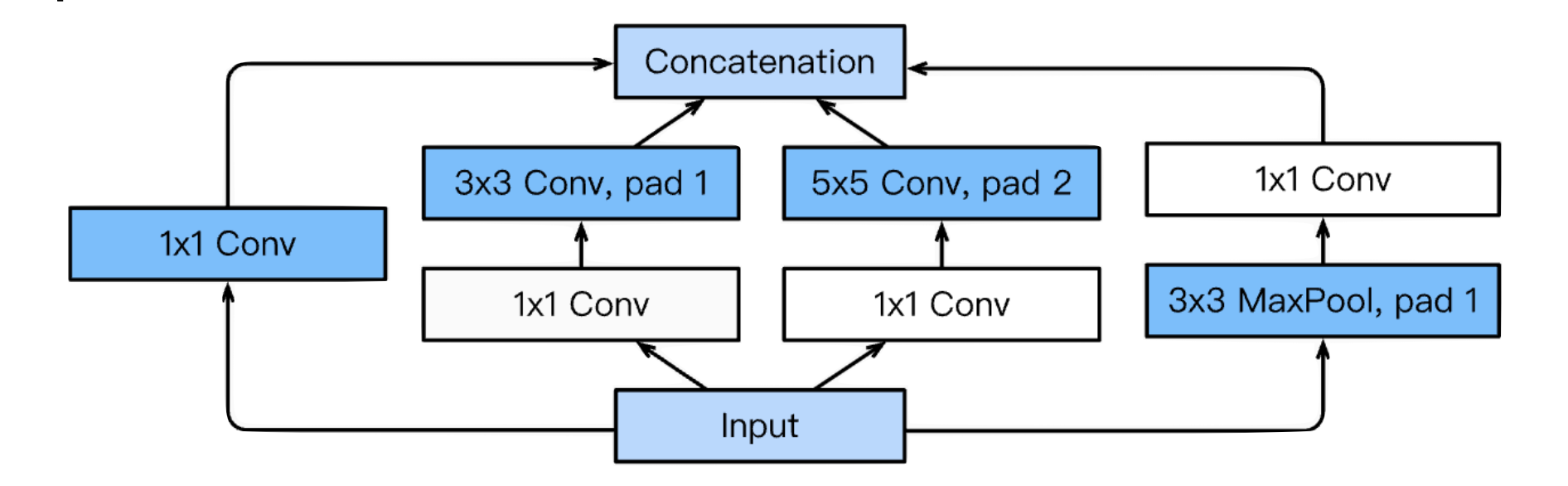
위 이미지 구조를 Inception block이라고 한다. 보면 3x3, 5x5 필터 전에 1x1 convolution layer가 들어가는데 이게 매우 중요한 특징이다.
- 비슷한 네트워크가 반복되는 구조이다. 이를 네트워크 안에 네트워크가 있다고 하여
-
GoogLeNet의 성공 비결: Inception Block
- Inception Block의
장점:파라미터 수를 줄인다!
(How?) 1x1 convolution이 channel 방향으로 dimension을 줄이는 효과가 있기 때문이다! (Channel-wise dimension reduction!)
이에 대한 구체적인 예시는 아래 이미지와 같다. 즉, 3x3 1개 사용하는 것보다 1x1 convolution으로 채널 수 줄이고, 3x3 convolution을 통해 채널 수를 원상복귀 시키는 방법이 receptive field는 동일하면서 parameter 수는 획기적으로 줄인 것을 볼 수 있다.
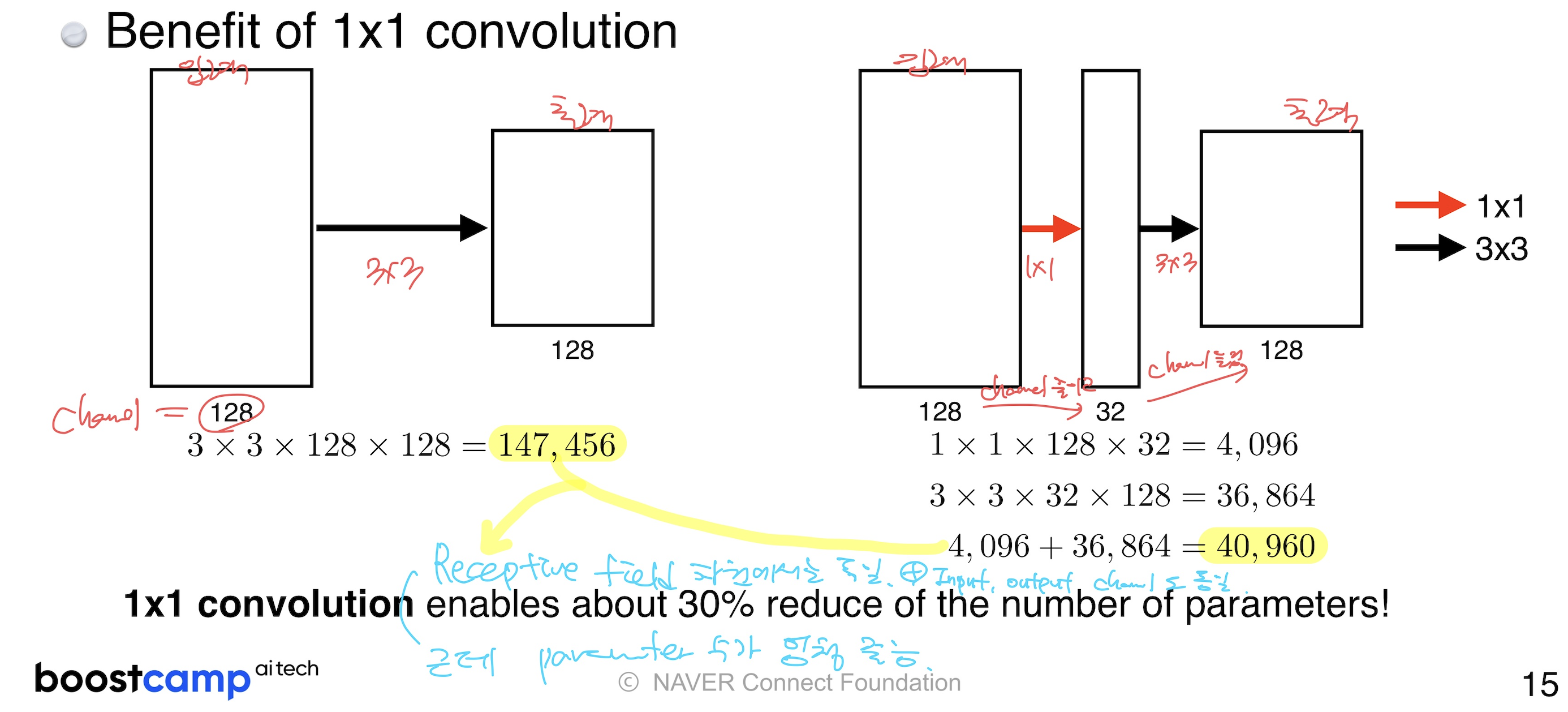
- Inception Block의
4) ResNet
-
기존 문제
파라미터 수가 많아지면 overfitting 문제가 쉽게 발생한다. 즉, train error는 작지만 test error는 큰 문제가 생기는 것이다. 그런데, overfitting과 유사해보이지만 overfitting은 아닌 문제가 발견되었다. 바로 그저 단순하게,네트워크가 깊어질수록 학습이 잘 안되는 현상이 발견되었다. 아래 그림에서 보다시피 train/test error 모두 줄어들기 때문에 overfitting은 아니다. 그런데 layer가 깊어질수록 에러가 줄어들어야하는데, 오히려 56-layer가 20-layer보다 에러가 큰 문제가 발생한 것이다.
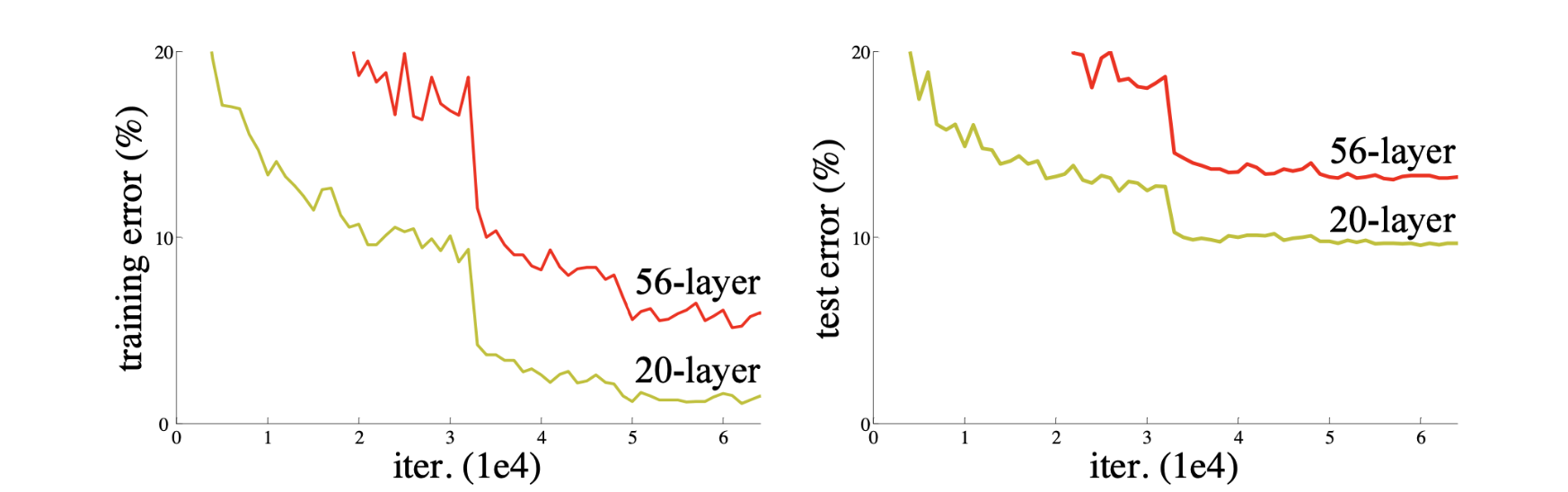
-
ResNet의 성공 비결: Residual Block
Residual block은3x3 convolution layer와Batch Normalization,ReLU함수,Skip Connection이 더해진 것이다.
그 중 생소할 것 같은 Skip Connection이 무엇인지 설명해보도록 하겠다.
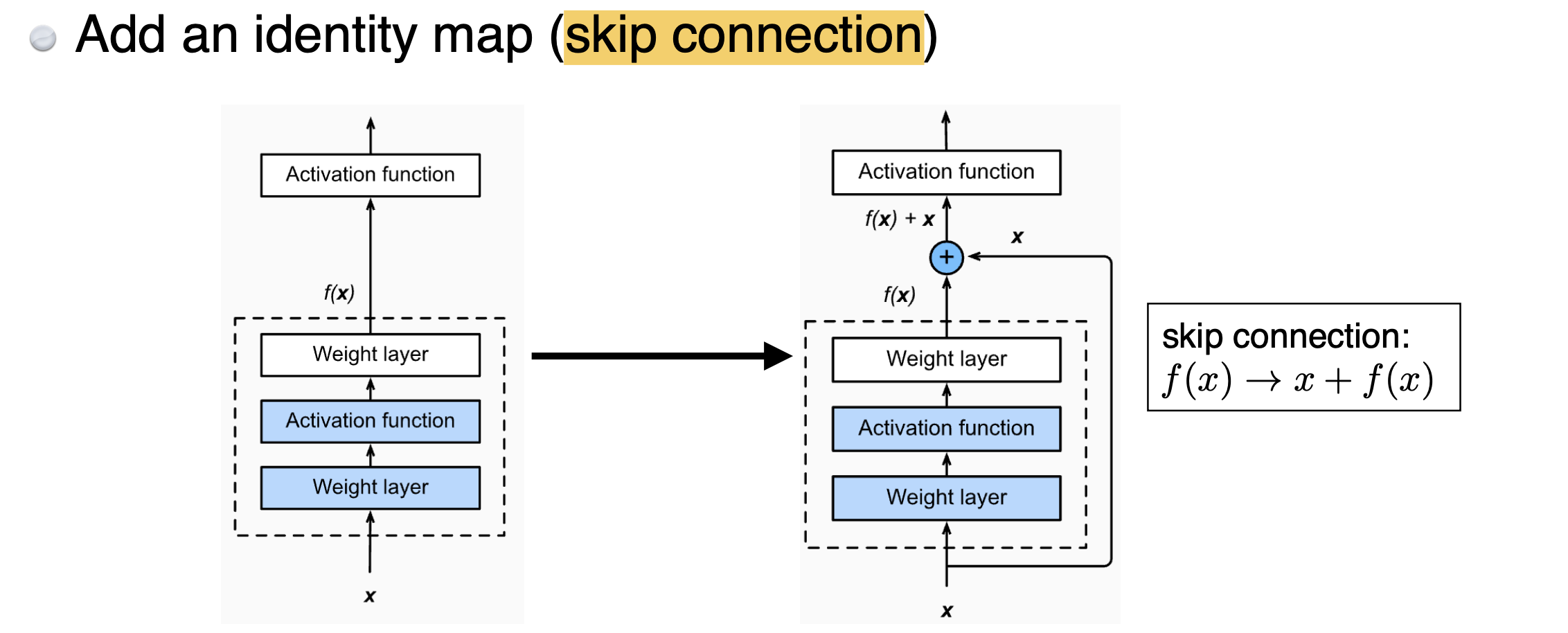
왼쪽이 기존 방식(plain layer)이고, 오른쪽이 residual block이다. 둘의 차이점은 단 한가지이다. residual block만 input인 를 출력값에 더해주는 것이다. 이를 통해 convolution layer가 학습하고자 하는 quantity는 residual이 되는 것이다.
기본적인 개념은 설명했는데, 이를 좀 더 high level에서 설명해보자.
residual block을 수식으로 설명하면 다음과 같다.
- input:
- output: H(x)
- convolution 연산 결과: F(x)
이 때 잔차 학습에서는 H(x)를 직접 학습하는 대신, F(x) = H(x) - x 를 학습한다. 즉, 작은 숫자만 추가적으로 학습하면 된다.
그런데, 이게 왜 깊은 레이어에서 효과적일까?
이에 대해 혁펜하임은 다음과 같이 설명한다. 
즉, 레이어가 깊을수록 한 레이어를 지날때마다 바뀌는 정도가 적을 것이다.
만약 3이 들어왔을 때 3.1을 output해야 한다고 하자. 기존의 plain layer에서는 3에서 3.1을 '만들어내야' 했다면, residual learning에서는 3과 3.1의 차이인 0.1만 만들어내면 되는 것이다. 왜냐하면 어차피 나중에 만들어낸 0.1에 x인 3을 더할 것이기 때문이다!
그렇다면 0.1 만드는게 왜 쉬울까?
어차피 시작할 때 (=신경망 가중치를 초기화할 때) 0에 가까운 작은 값에서 시작하기 때문이다.
layer가 깊어질수록 각 레이어에서의 변화량은 줄어들게 되기 때문에 잔차만 학습하는 residual block이 효율적인 것이다.
그 결과 plain layer에서는 레이어가 깊어질수록(18-layer에서 34-layer가 되니) 오히려 에러가 커졌으나, ResNet을 활용하니 18-layer보다 34-layer에서 더 에러가 작아졌다. 즉, ResNet을 통해 Network를 더 deep하게 쌓을 수 있는 가능성을 열어준 것이다. 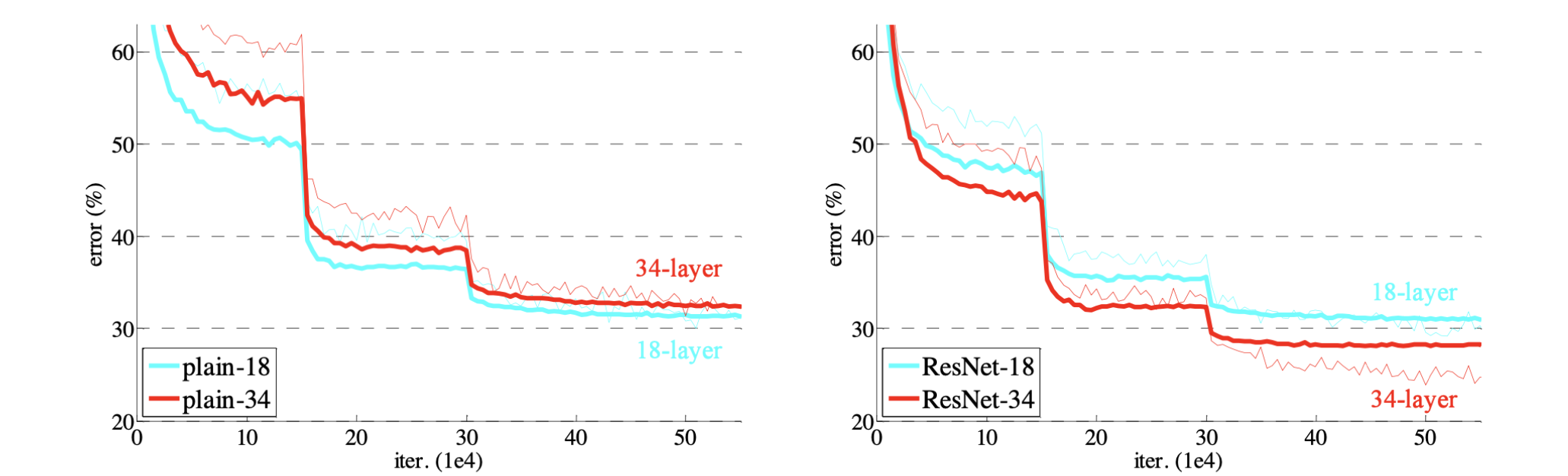
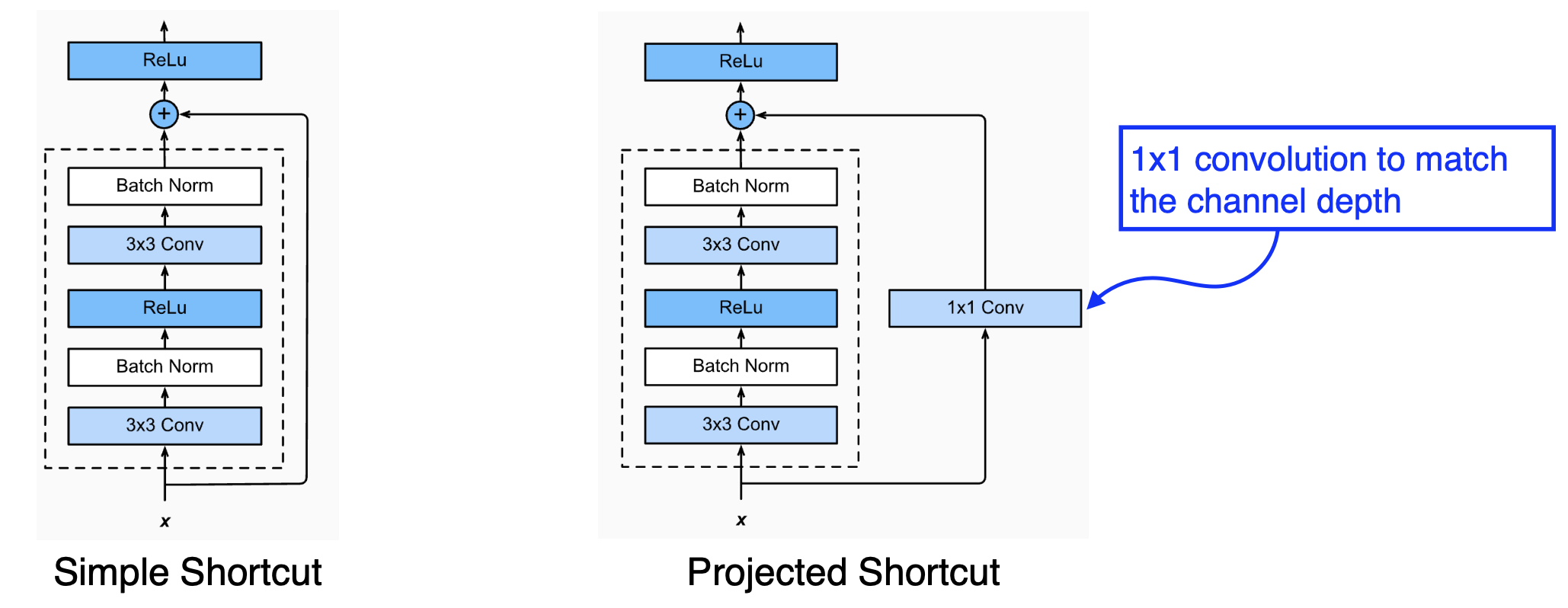
그런데, 만약 더해주어야 하는 x와 F(x)의 차원이 다르면 어떻게 할까?
1x1 convolution을 통해 channel depth를 맞춰주는 과정이 필요하다. 아래 그림에서 F(x)와 x의 차원이 같은 경우는 Simple Shortcut이고, 차원이 달라 맞추어줘야 하는 경우가 오른쪽의 Projected Shortcut이다. 그런데 주로 Simple Shortcut 방식으로 사용한다.
Batch Normalization
Residual block에는 batch norm을 수행하는 block이 있다. 기본적인 것은 3x3 convolution layer 다음에 오는 것인데, 그 순서에 대해서는 논란이 많다. 즉, 그 순서는 Interchangeable하다는 것이다.
Bottleneck Architecture
이는 GoogLeNet의 Inception Block과 같은 개념으로, 3x3 convolution layer 전에 1x1 convolution layer를 통해 channel을 줄이고, 3x3 conv 후에 다시 1x1 layer를 통해 원하는 channel수로 다시 맞추는 과정이다. 이를 통해 전체 차원은 유지하며 동시에 필요로하는 전체 파라미터 수는 줄인다는 효과가 있다.
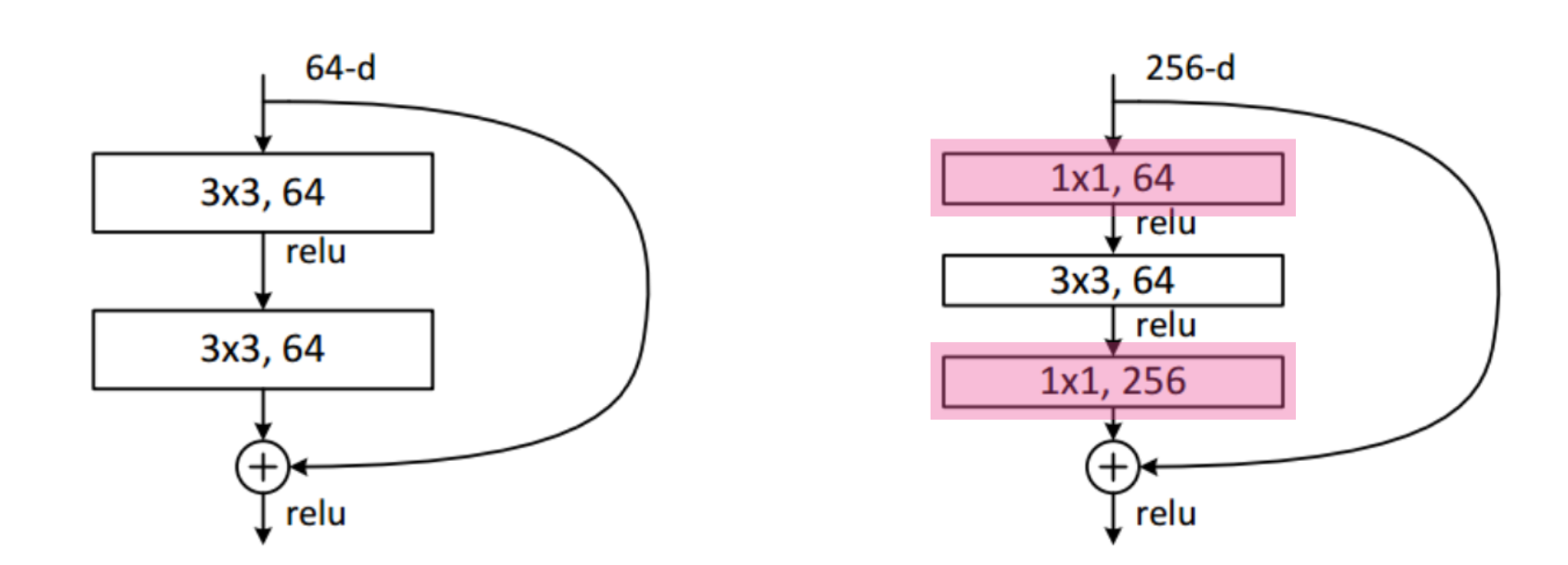
오른쪽이 bottleneck architecture이다.
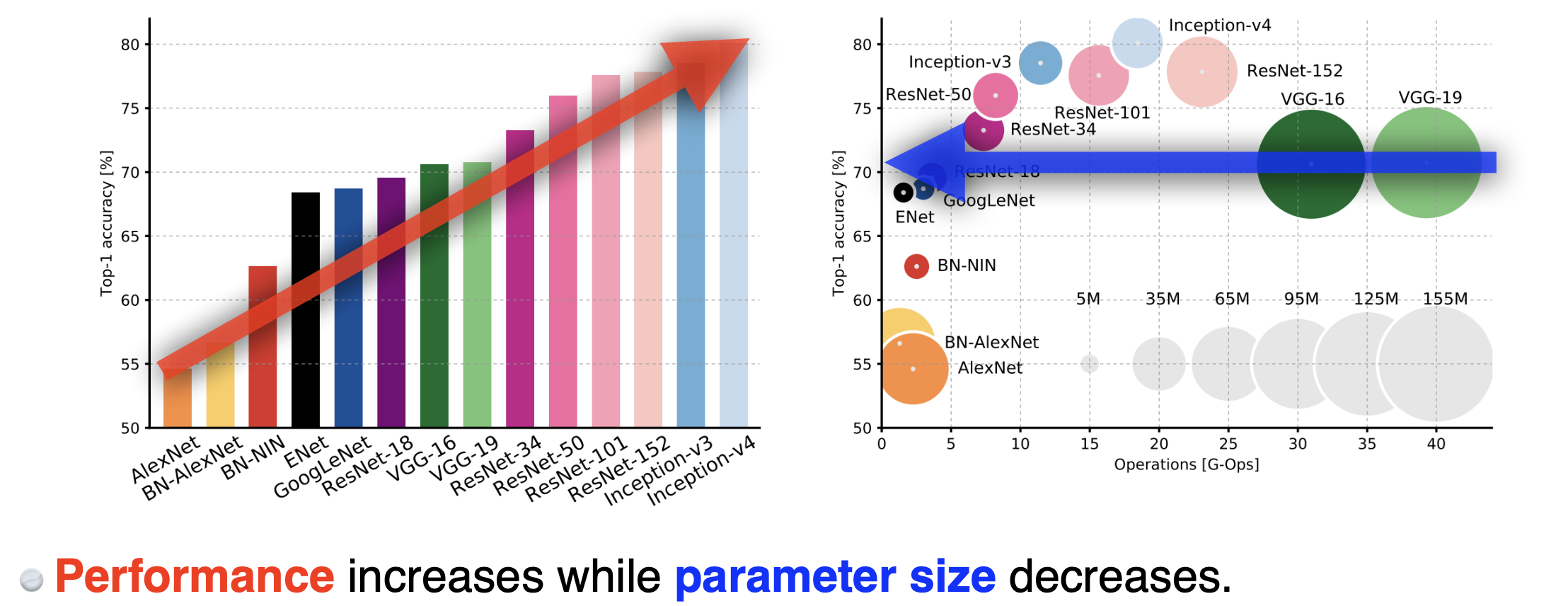
이를 통해 우리가 배운 모델을 한번에 살펴보면 전반적으로 파라미터 수는 줄어들고 성능은 높아지는 것을 볼 수 있다.
5) DenseNet
기본 개념은 다음과 같다. ResNet에서 두 값을 더하다보면 두 값이 섞이게 된다. 그러니 그렇게 하지 말고 그냥 두 값을 concat하자는 것이다.
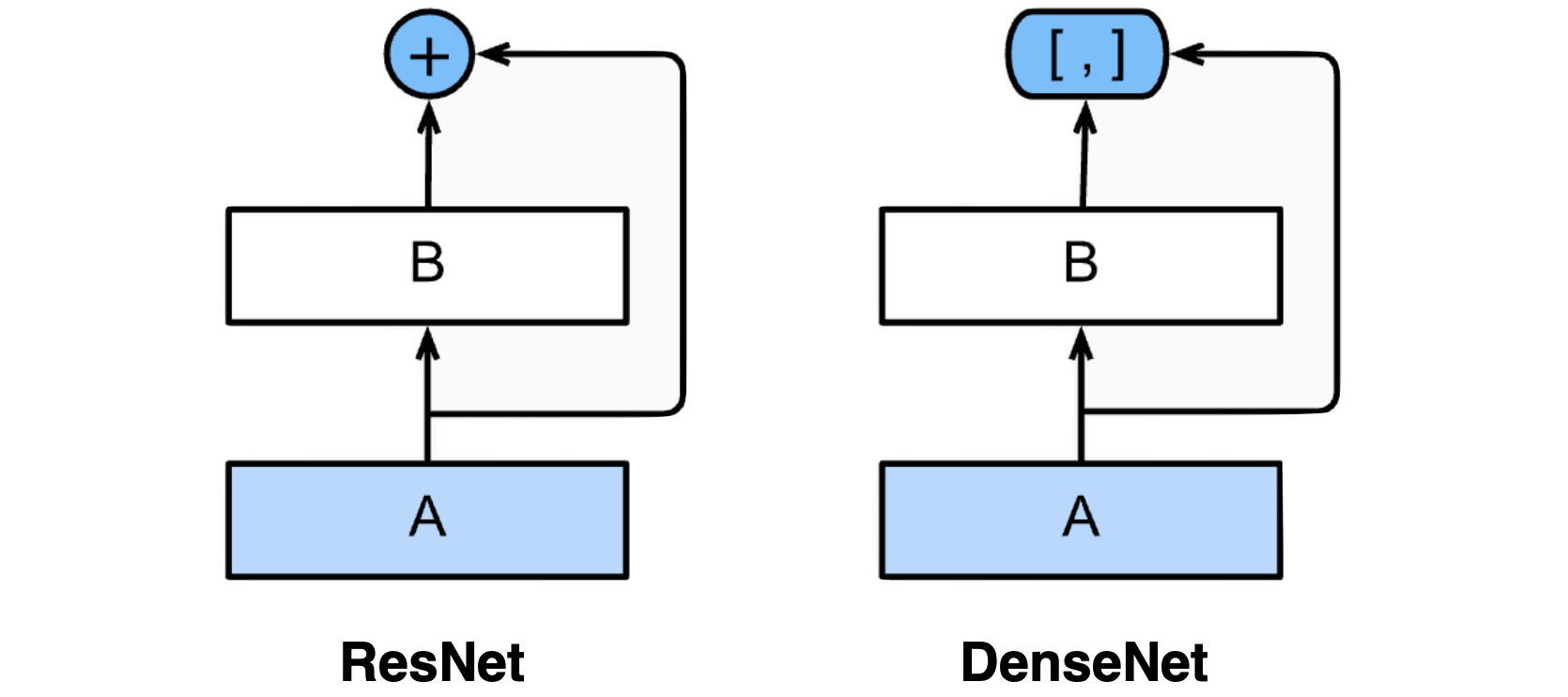
그런데, 모두 알겠다시피 이렇게 concat하다보면 channel이 계속 엄청 커진다는 문제가 있다. 그것도 2의 지수배로 커진다. 2개, 4개, 8개, 16개, ... 이런식으로 말이다.
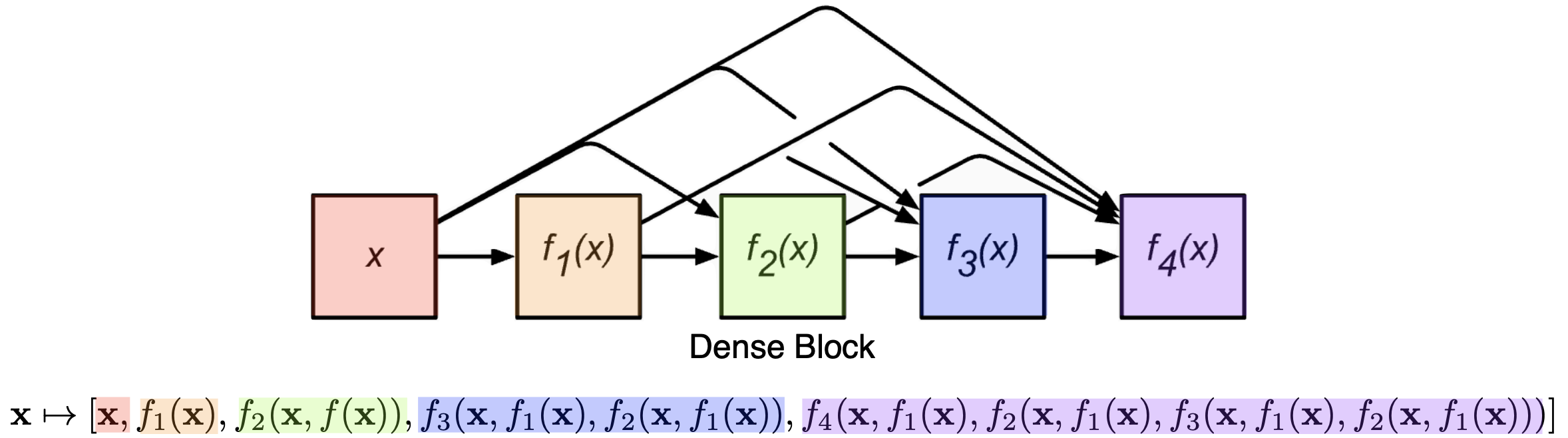
이렇게 채널이 커지면 필요로하는 파라미터 수도 매우 커진다. 따라서 중간중간 한번씩 channel을 1x1 convolution layer를 통해 줄여주는 과정이 필요하다. 이를 Transition block이라고 한다.

