Semantic Segmentation
Semantic Segmentation은 이미지의 각 픽셀이 어디에 속하는지 classification하는 것이다.
이는 주로 자율주행에 많이 사용된다.
Semantic Segmentation의 대표적인 알고리즘은 Fully Convolutional Network이다.
1) Fully Convolutional Networks (FCN)
기존 네트워크의 문제점과 해결책
Fully Convolutional Networks에서는 기존의 분류 성능을 검증받은 네트워크(AlexNet, VGGNet 등)을 이용하려고 했다. 그런데, 이들을 그대로 이용하기에는 문제가 많았다.
1) Dense Layer로 인해 spatial information이 사라진다.
기존의 CNN은 마지막 layer즈음에서 데이터를 flatten하고 fully connected layer를 사용하게 된다. 이는 공간 정보를 없애기 때문에 semantic segmentation에는 적합하지 않다.
2) Fully connected layer를 사용한다면 고정된 크기의 input만을 받아야한다. 왜냐하면 fully connected layer는 (이전 레이어 데이터 x 다음 레이어 데이터) 만큼의 가중치 행렬을 필요로하기 때문이다. 그러니 이전 레이어에서 output된 데이터의 크기가 고정되어야하기 때문에 결국 input 데이터도 고정된 크기여야한다는 것이다. 그런데 이미지의 input size가 항상 고정되어야 한다면 너무 제약적이지 않는가!
따라서 FCL은 위 단점을 극복하고자 기존에 사용되던 fully connected layer를 모두 convolutional layer로 대체하자는 것이다. 즉, Dense Layer를 없애고 Convolutionalize하자는 것이다!
그렇게 해도 아래와 같이 output은 동일하게 만들 수 있다. 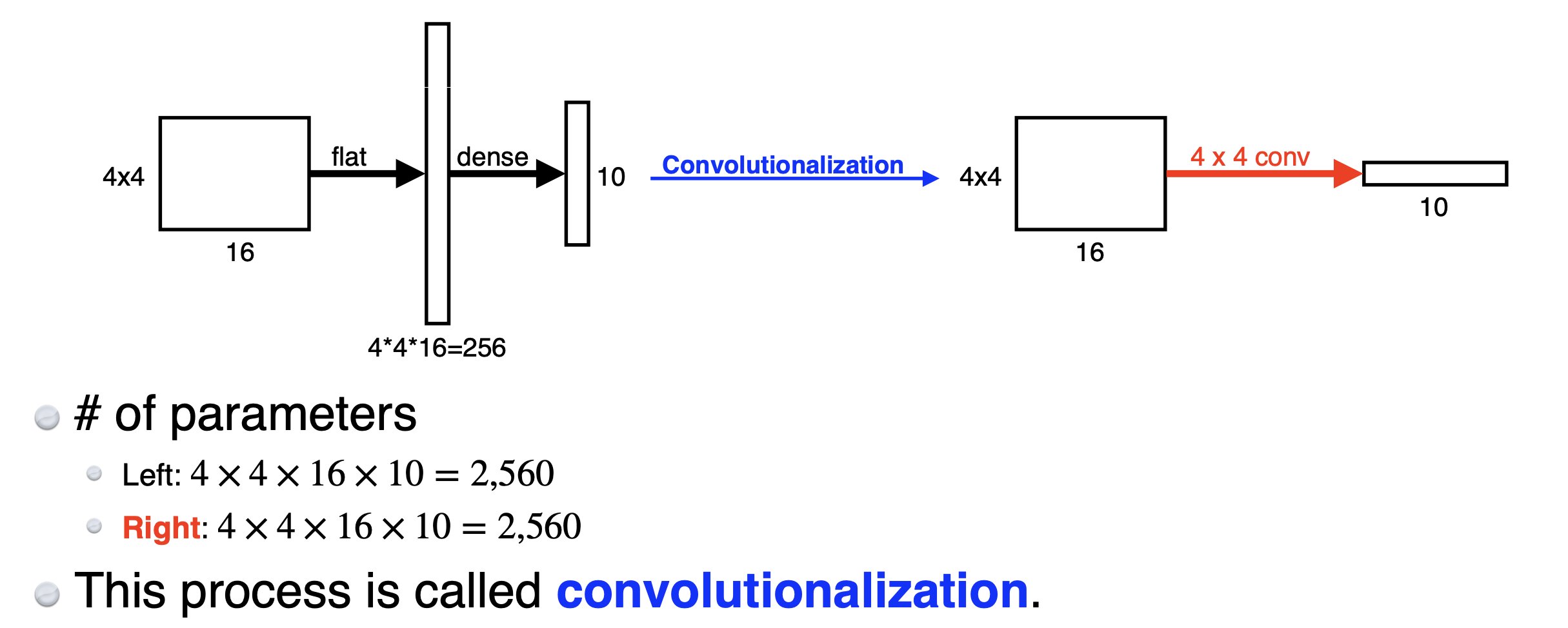
Convolution & Deconvolution
위와 같은 과정으로 convolutionalize하면 이제 모든 사이즈의 이미지 데이터를 input으로 받을 수 있게 되었다. 그런데 문제는 convolution을 통한 output dimension이 대부분 줄어든다는 것이다. 즉, subsampling으로 인해 resolution이 떨어진다는 것이다. 이대로 두면 안되지! 우리는 다시 원래대로 resolution을 늘려야 한다. 이를 deconvolution이라고 한다.
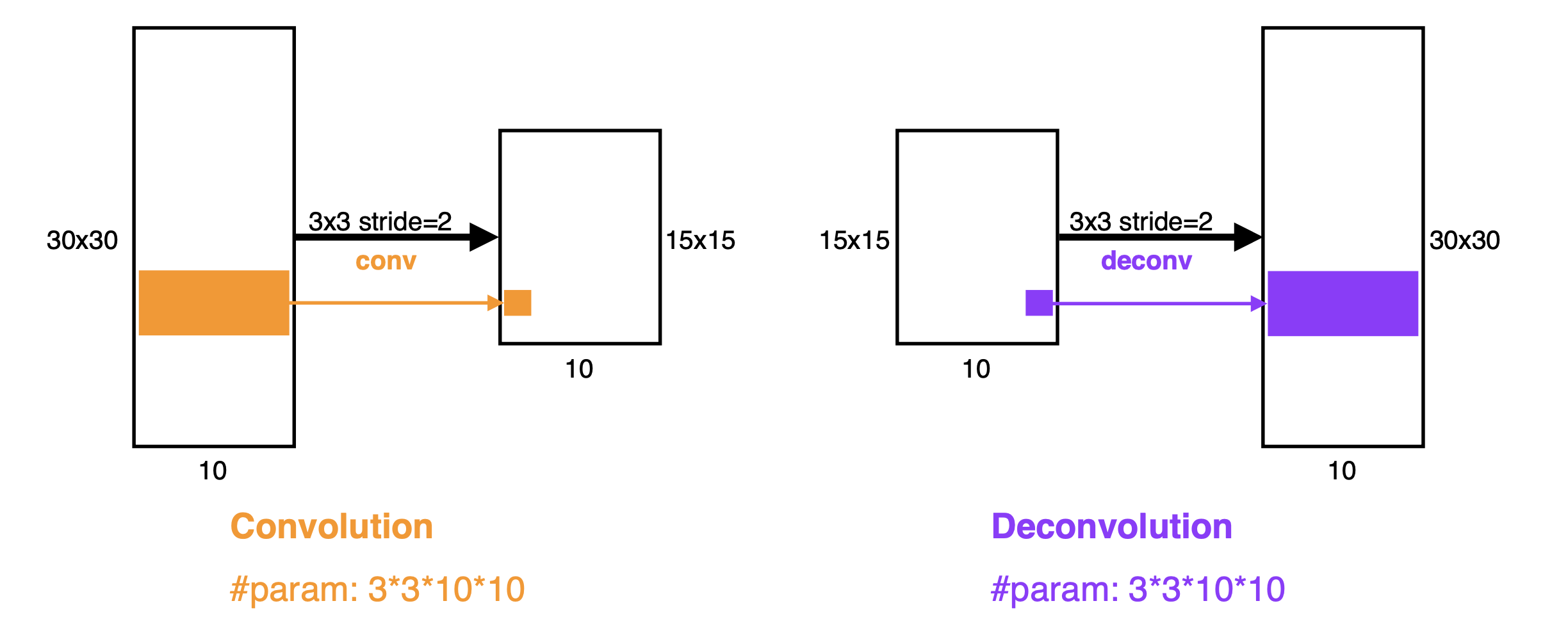
위 이미지의 왼쪽 주황색 부분은 convolution을 의미하며, spatial dimension이 약 절반가량 줄어들었다. 반면 오른쪽 보라색 부분은 deconvolution을 의미하며, spatial dimension을 키워준다. 엄밀히 convolution의 역연산은 아니지만 역이라고 생각하면 이해가 편한 뭐 그런 연산이다.
구체적으로 Deconvolution은 다양한 방법이 있겠지만 아래와 같이 2x2 이미지에 padding을 많이 주어 결과적으로는 원하는 5x5 이미지를 만드는 방식이다.
이 외에도 우리가 다루어야할 내용이 많다. Skip Architecture 등이 그것이다. 이에 대한 내용은 나중에 심화된 cv 수업에서 배워보도록 하자.
Detection
앞서 Semantic Segmentation에서 per pixel별로 label을 찾는게 아니라, 이는 bounding box를 찾는 문제이다. 이를 위한 알고리즘은 R-CNN, SPPNet, Fast R-CNN, YOLO 등이 있다. 이에 대해 이번 시간에 간략하게 high level로 설명하고자 한다.
1) R-CNN
- 개념
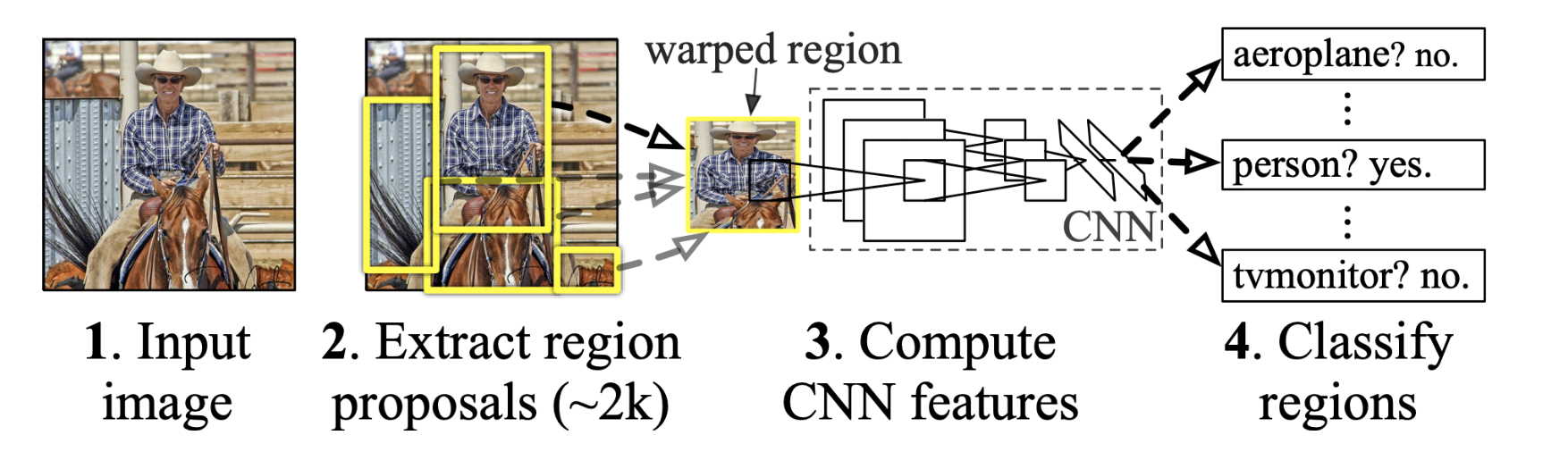
무작정 2천개의 가능한 영역을 추출하고 각 영역에 대해 CNN 돌려서 판단해보자!
- 알고리즘
(1) Input image를 받는다.
(2) Region Proposals: Selective Search를 통해 약 2,000개의 후보 영역 (region proposals)을 뽑아낸다.
(3) Feature Extraction: 각 후보 영역을 고정된 크기로 리사이즈한 후 CNN(해당 논문에서는 AlexNet을 사용한듯하다)을 사용하여 특징을 추출한다.
(4) Classification: 추출된 특징을 linear SVM을 사용하여 분류한다.
(5) Bounding Box Regression: bounding box 위치를 더 정확하게 조정한다.
- 한계
computational cost가 매우 높다.각 후보 영역(약 2천개의 이미지)에 대해 CNN을 개별적으로 통과시켜야 하기 때문이다. 즉, convolutional network를 2천번 돌려야하기 때문에 매우 느리다는 문제가 있다.
2) SPPNet
- 개념
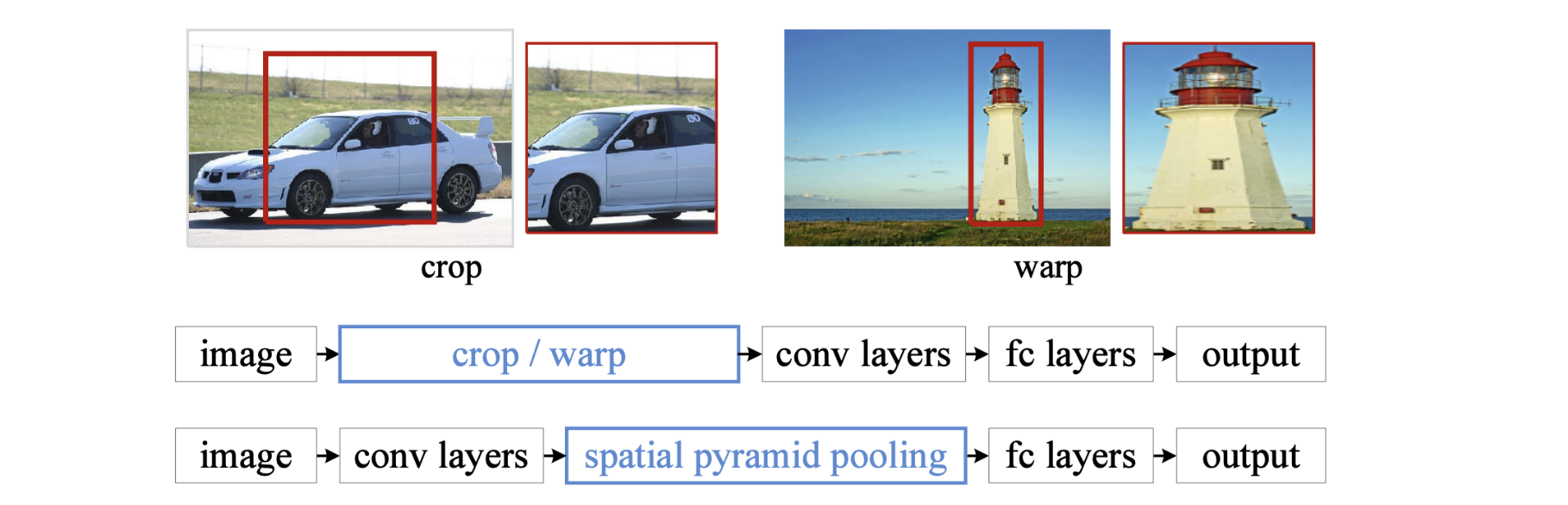
하나의 이미지 안에서는CNN을 1번만 돌리자!
이미지 전체에 대해 convolutional feature map을 뽑고 bounding box 위치에 해당하는 feature map의 tensor만 뜯어오자!
-
알고리즘
(1) Feature Extraction: 이미지를 CNN에 입력하여 이미지 전체의 특징맵을 한번만 계산한다.
(2) Spatial Pyramid Pooling: 후보 영역에 대해 SPP를 적용하여 고정된 크기의 특징 벡터 생성
(3) Classification and Regression: R-CNN과 유사하게 SVM을 사용하여 분류하고, bounding box를 적용한다. -
한계
R-CNN보다 훨씬 속도가 빠르지만 여전히 각각의 후보영역에 대해 하나하나 개별적으로 SVM을 통한 분류를 수행해야 한다.
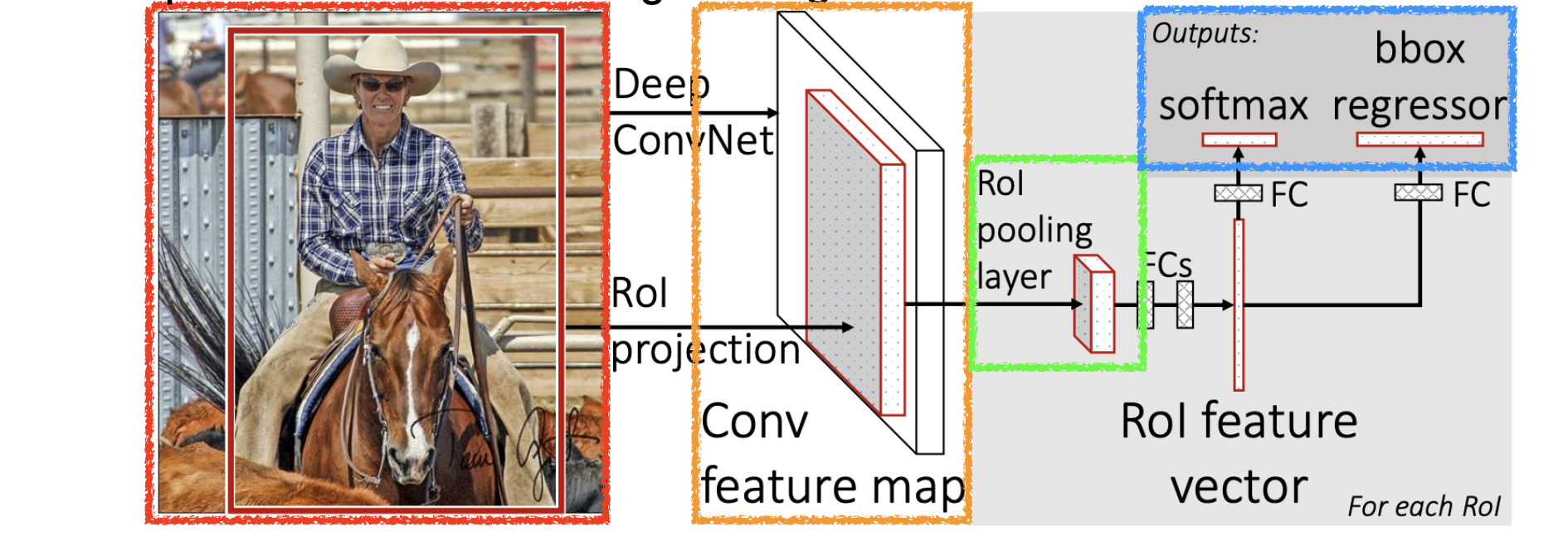
3) Fast R-CNN
- 개념
R-CNN과 SPPNet의 장점 결합! 한번에 클래스 분류와 bouding box regression(경계 상자 회귀)를 동시에 수행한다.
-
알고리즘
(1) Feature Extraction: 이미지를 CNN에 입력하여 이미지 전체의 특징 맵을 한 번만 계산한다.
(2) RoI Pooling: 후보 영역을 특징 맵에서 추출한 후, RoI Pooling(Region of Interest Pooling)을 적용하여 고정된 크기의 특징 벡터를 생성한다.
(3) Two outputs: Classification and Regression: 하나의 네트워크를 통해 분류와 경계 상자 회귀를 동시에 수행한다. -
한계
여전히 후보 영역을 생성하는 단계가 필요하다.
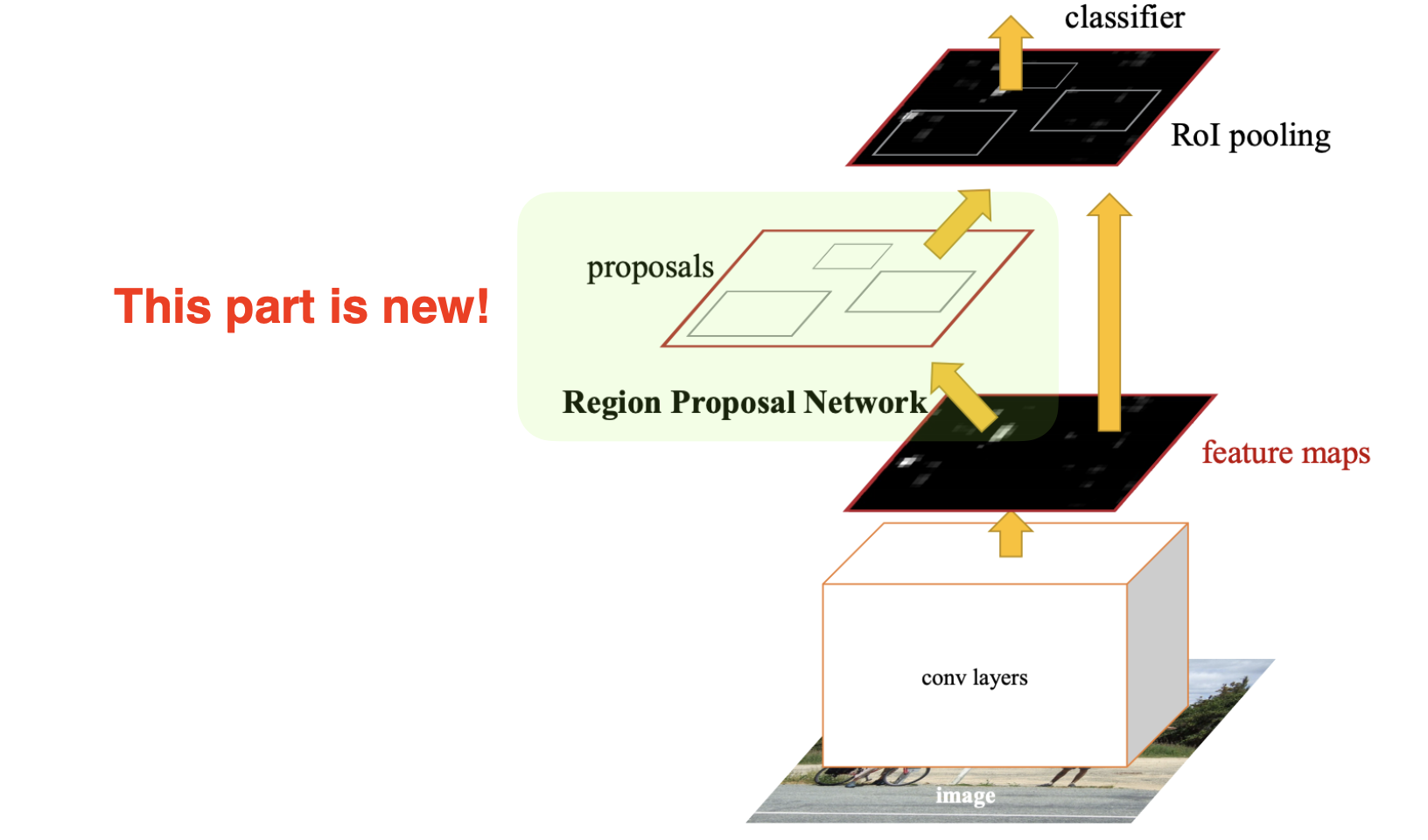
4) Faster R-CNN
- 개념
Candidate 뽑아내는 것도 Network로 학습하자! 즉, Bounding Box 뽑아내는 Region Proposal Network도 학습하자는 개념이다. 이를 통해 물체 탐지에서 사용되는 후보 영역 생성 과정을 CNN을 통해 자동화함으로써 속도와 정확도를 크게 향상시켰다.
Faster R-CNN = Region Proposal Network + Fast R-CNN
- 알고리즘
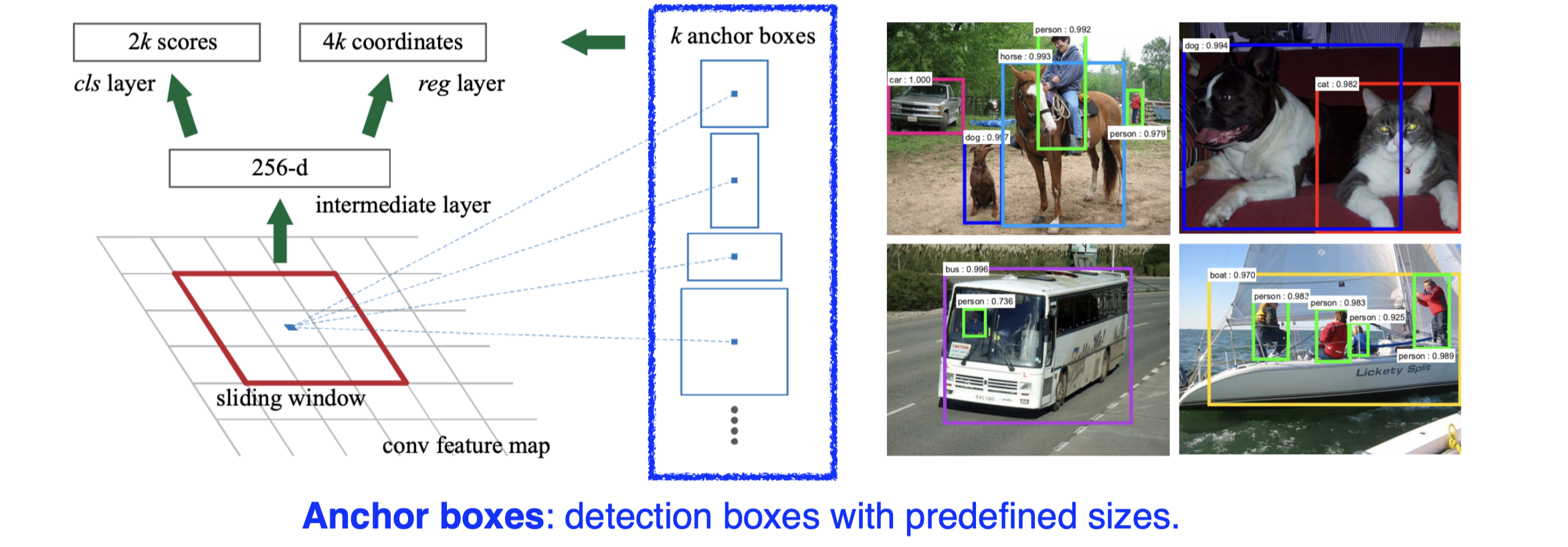
(1) Region Proposal Network (RPN): CNN 특징 맵을 사용하여 잠재적인 물체가 있을 법한 위치를 예측하는 네트워크- 특징 맵 생성: 입력 이미지를 CNN을 통해 특징 맵으로 변환한다.
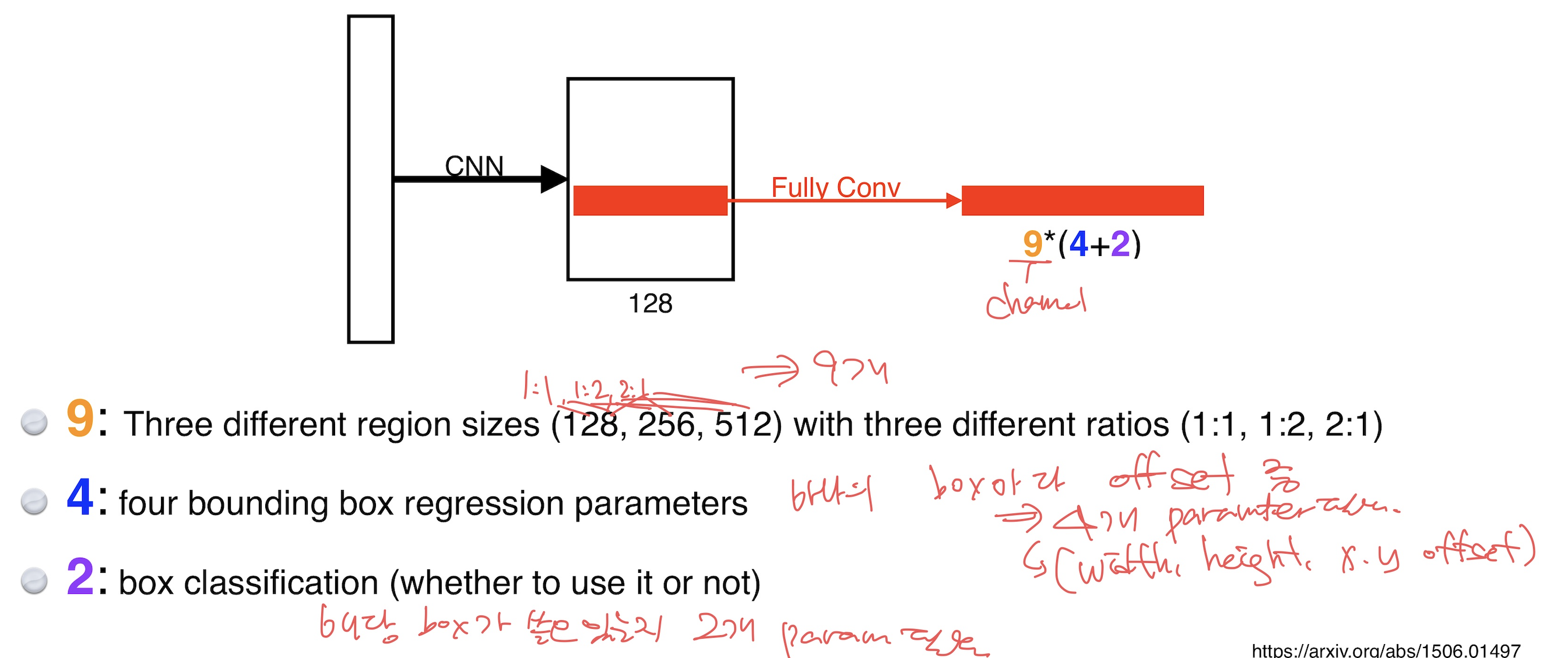
- 앵커 박스 (Anchor Boxes): 각 위치에서 여러 가지 크기와 비율을 가진 앵커 박스를 생성한다. (bounding box parameter에는 width, height, x offset, y offset 4개가 있다.)
- 객체 여부 판단: 각 앵커 박스에 대해 물체가 있는지 여부를 이진 분류한다.
- 경계 상자 조정: 각 앵커 박스에 대해 정확한 경계 상자 위치를 회귀를 통해 조정한다.
(2) Fast R-CNN Detector: RPN에서 생성된 후보 영역을 사용하여 클래스 분류와 경계 상자 회귀를 수행한다. (Fast R-CNN과 동일한 구조)
- 한계
여전히 네트워크 구조가 복잡하고 많은 계산을 필요로한다. (RPN과 Fast R-CNN Detector 두 단계 구조로 인해 계산 비용이 누적됨) 이로 인해 비디오 스트림과 같은 실시간 처리에 어려움이 있다.
5) YOLO v1
- 개념
매우 빠른 알고리즘이다. YOLO는 이미지를 그리드로 나누고,
- 알고리즘
- 한계
