아래 내용은 다음 자료들을 재구성한 내용이다.
내용에 들어가기에 앞서, 이 페이지에는 여러 이미지가 나온다. 여기에서의 이미지는 필자가 만든 이미지가 아니라 모두 앞에 첨부한 링크의 영상에서 가져온 것이다. 구체적으로 하얀 배경의 이미지는 추가로 링크를 달지 않았으면, https://www.youtube.com/watch?v=AA621UofTUA 에서 가져온 내용이며, 검정 배경의 이미지는 https://www.youtube.com/watch?v=eMlx5fFNoYc 에서 가져온 이미지이다. 하나하나 이미지 아래에 링크를 첨부하였는데, 가독성이 너무 떨어져서 이렇게 앞단에 미리 밝혀둠에 양해를 구한다. velog 캡션 쉽게 가능하게 해주세요
왜 Transformer가 필요한가?
Transformer는 RNN/LSTM이 시퀀스 데이터를 순차적으로 처리하기 때문에 발생하는 여러 문제를 해결하기 위해 등장하였다. 구체적으로, 문장을 구사할 때 우리는 몇개 단어를 빼고 이야기할 수도 있고, 순서를 바꿔서 말할 수도 있는 상황에 보다 robust한 모델이 필요했다. 나아가 RNN/LSTM은 순서대로 hidden state를 넘기는 방식이었기 때문에 문장 길이가 길어짐에 따라 gradient vanishing 문제로 저 문장 앞쪽에 있는 정보는 지금 위치에 반영이 잘 안되는 등의 문제가 발생했던 것이다.
즉, 시퀀스 데이터를 순차적으로 처리하기 때문에 병렬 처리에 한계가 있었으며, 긴 문맥을 처리하는 데에 어려움이 있던 것이다. 이를 해결하기 위해 Transformer 모델이 등장하였다.
Transformer 개념
트랜스포머 모델의 가장 핵심 개념은 Attention Mechanism을 사용한다는 것이다. attention mechhanism은 입력 시퀀스의 모든 단어가 서로를 참고할 수 있게 하여, 특정 단어를 설명/이해 하기 위해 중요한 다른 단어를 동시에 참고하고, 해당 단어에 더 많은 가중치를 부여하는 방법이다. 즉, 어텐션 메커니즘을 통해 입력 시퀀스의 모든 단어 간의 관계를 고려할 수 있어, 병렬 처리와 긴 문맥 처리에서 우수한 성능을 발휘하게 된 것이다.
Transformer는 기존의 RNN/CNN을 전혀 사용하지 않고, Attention과 Fully Connected Layer를 사용하였다는 특성이 있다.
트랜스포머 모델은 크게 인코더(Encoder)와 디코더(Decoder)로 이루어져 있다. 이에 대해 자세한 내용은 하단에서 구체적으로 설명하겠다.
Transformer vs Seq2Seq
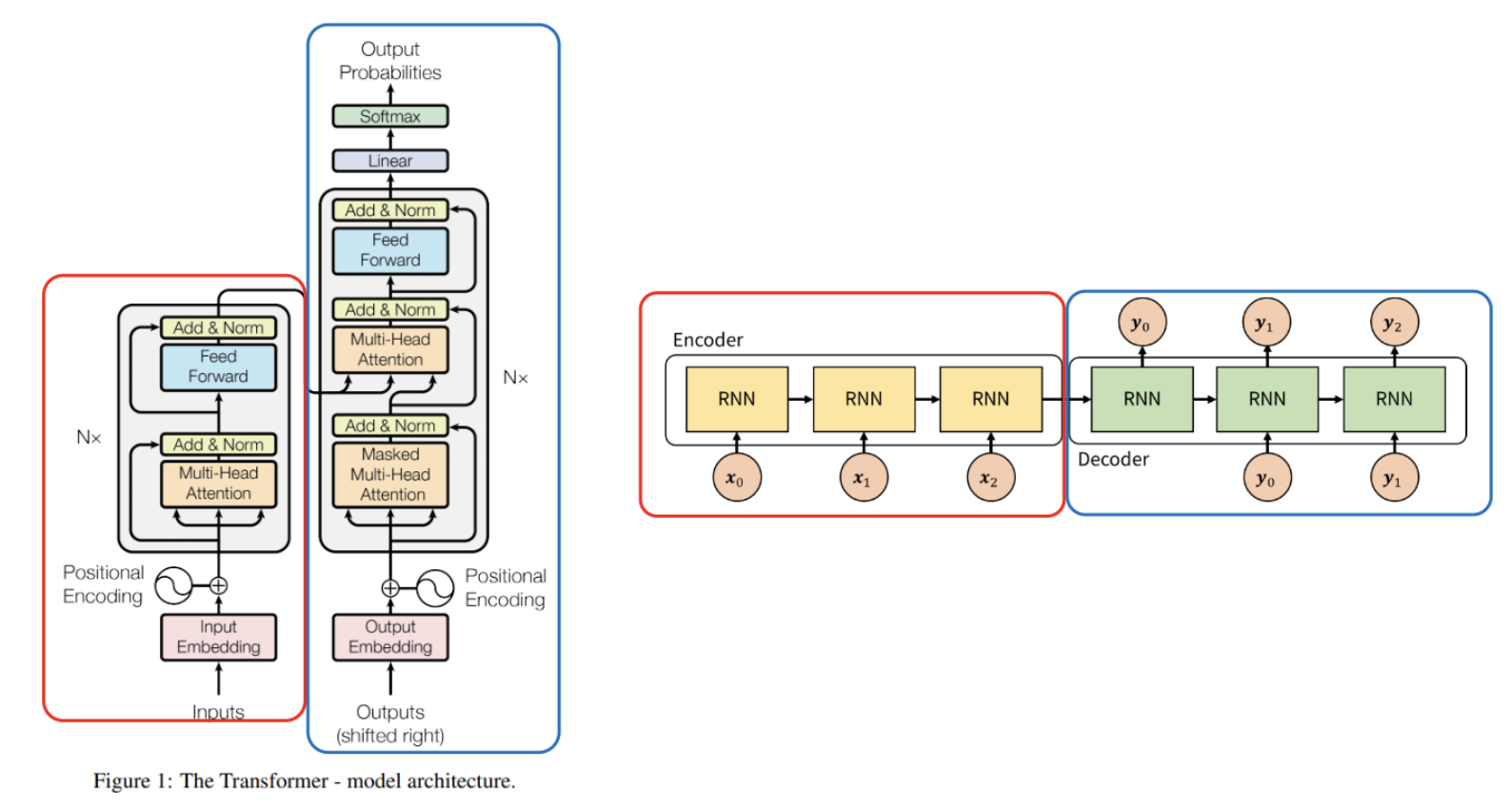
[이미지 출처] https://gaussian37.github.io/dl-concept-transformer/
트랜스포머에 대해 깊이 들어가기 전에 transformer와 Seq2Seq의 공통점과 차이점에 대해 살펴보도록 하자.
우선, 두 모델 모두 Encoder(빨간색)과 Decoder(파란색)으로 이루어져 있다는 공통점이 있다. 그러나 차이점은 다음과 같다.
Seq2Seq 모델은 Encoder에서 Decoder로 정보를 전달할 때 가운데 화살표인 context vector에 encoder 정보를 고정된 크기로 저장하여 Decoder로 전달한다. 즉, 고정된 크기의 Context vector에 소스 문장의 정보를 압축하여 전달하는 것이다. 그런데 문제는 입력 데이터의 길이가 길 수도 있고, 짧을 수도 있는 등 다양한 변수가 있는데, 이를 무조건적으로 고정된 크기의 context vector에 저장하는 것은 병목현상의 원인이 될 수 있다는 문제가 있다. 나아가 긴 시퀀스의 입력에게는 information loss 문제가 발생하게 된다.
이를 해결하기 위해 Seq2Seq with attention 모델도 등장하여 디코더가 인코더의 모든 출력을 참고할 수 있도록 하는 방법도 개발되었다. 그러나 결론적으로, Seq2Seq와 Transformer의 가장 큰 차이점은 Seq2Seq는 Encoder가 모든 단어에 대해 context vector를 만든 후에 decoder연산이 시작된다면, transformer는 encoder와 decoder 연산이 동시에 진행된다는 차이가 있다.
Transformer Architecture
1) Input Embedding
맨 처음 들어오는 입력은 one-hot encoding 방식으로 들어오게 된다. 즉, 특정 언어에서 존재할 수 있는 단어의 개수의 차원(한국어 단어 전체)을 지니며, 그 안에서 해당 단어만 1을 가지고 나머지는 0인 엄청나게 큰 차원의 벡터로 encoding되어 input으로 들어오게 된다. 그런데 이렇게 차원이 많으면 데이터 처리하기 정말 너무 힘들 것이다. 따라서 임베딩 과정을 거쳐서 보다 적은 차원의 continuous 값으로 표현하게 된다.
임베딩 결과의 행은 입력되는 단어의 개수로, 열은 embedding 차원으로 구성된다. 이 때 embedding 차원은 모델 아키텍쳐를 만드는 사람이 임의로 설정해줄 수 있는데, 원본 논문에서는 512정도의 값으로 설정했다고 한다. 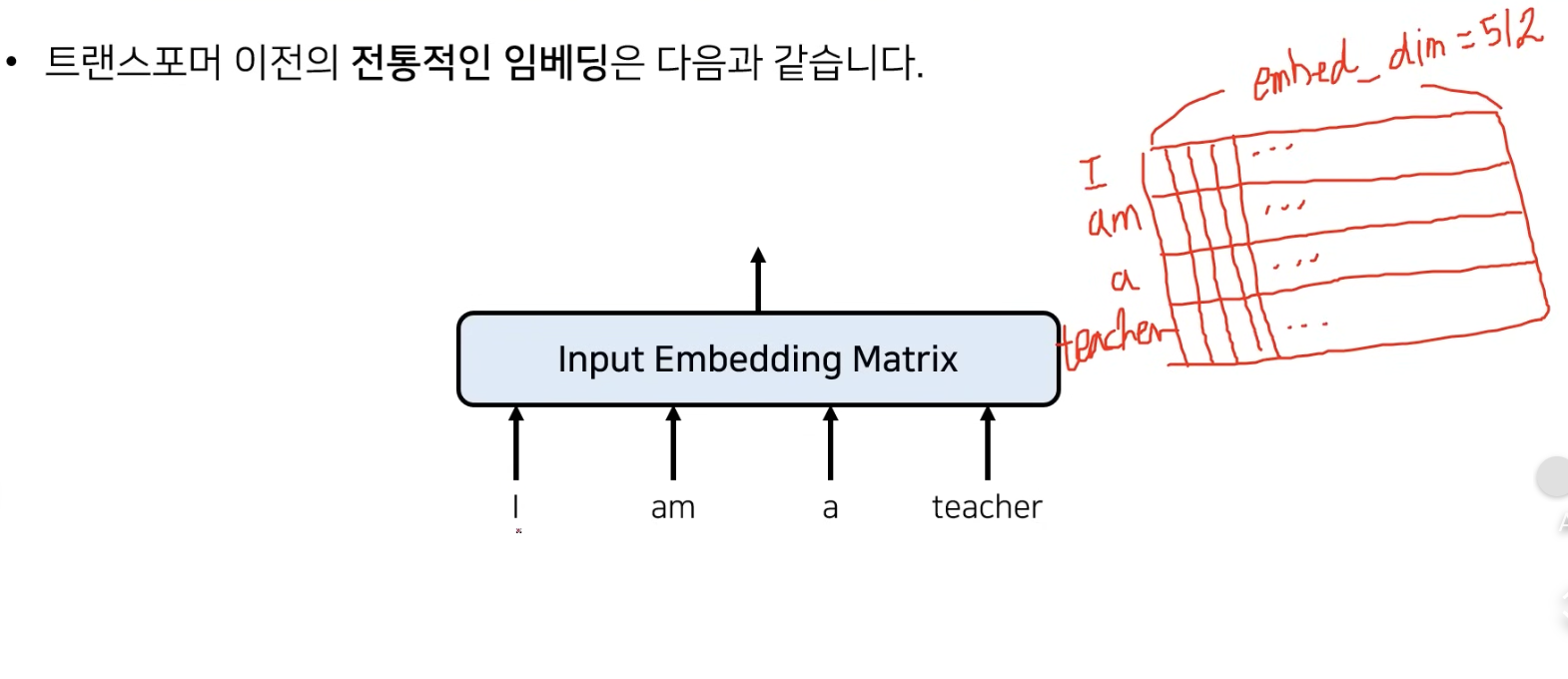
(참고) 참고로 각 단어를 토큰이라고 부르는데, 사실 '하나의 토큰 = 하나의 단어'가 아니다. 실제로는 아래 이미지의 The Truth 부분처럼 단어 level이 아닌,,, 우리에게는 낯선 방식으로 각 토큰이 구성되어 있다. 그런데 그냥 우리의 이해를 용이하게 하기 위해 토큰 = 단어 라고 생각하고 진행하겠다.

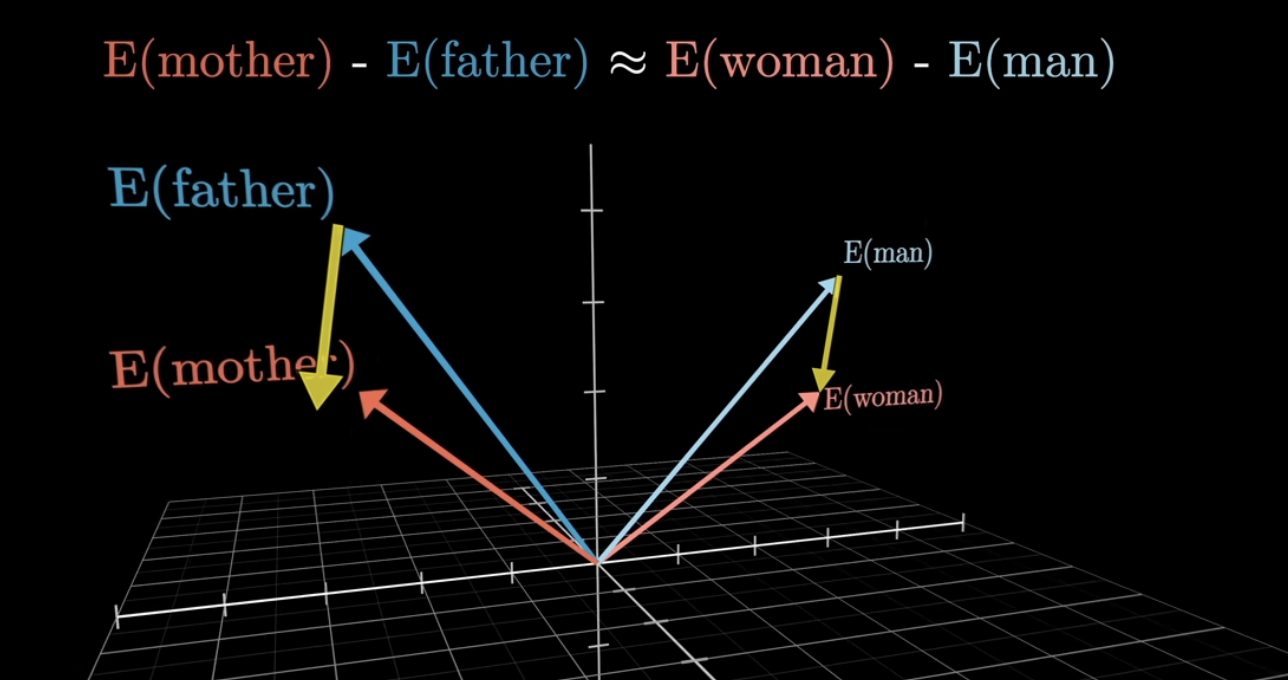
(참고) 추가적으로, 유사한 방향성을 가지는 두 embedding vector는 서로 유사한 의미를 지니고 있음을 의미한다.
2) Positional Encoding
우리가 병렬적으로 데이터를 입력하기 때문에 앞의 과정만으로는 I am a teacher 라는 단어를 encoding하였을 때, teacher가 I 뒤에 나오는지 앞에 나오는지 알 방법이 없다. 따라서 우리는 추가적으로 입력 데이터의 위치 정보를 더해주게 된다. 이를 Positional Encoding이라고 한다.
구체적으로, input embedding matrix와 같은 차원을 가지며, 위치에 대한 정보를 가지고 있는 positional encoding을 input embedding matrix와 element-wise로 더해줌으로써 각 단어의 위치 정보를 추가적으로 제공한다.
아래 첫번째 이미지는 과정을 설명하고 있으며 두번째 이미지는 positional encoding값을 더해준 결과의 예시이다. 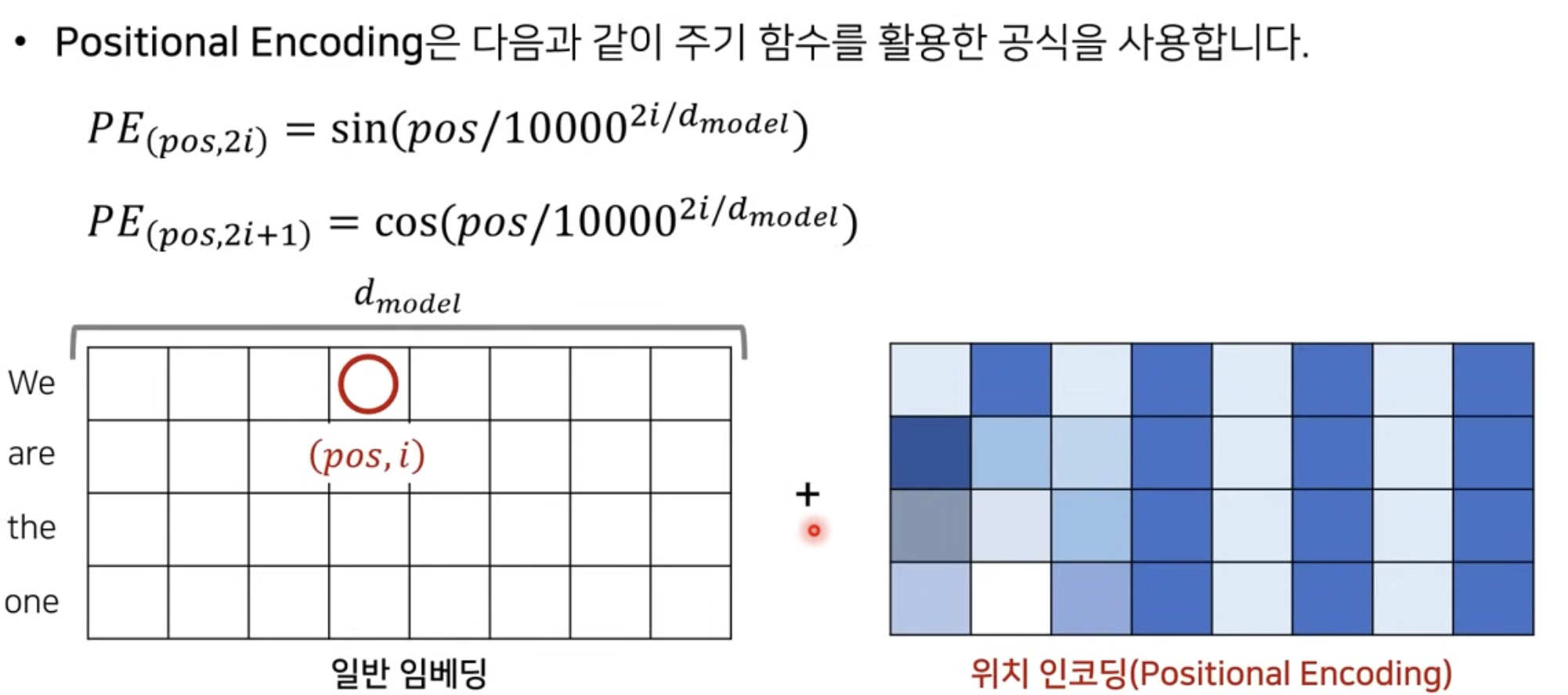
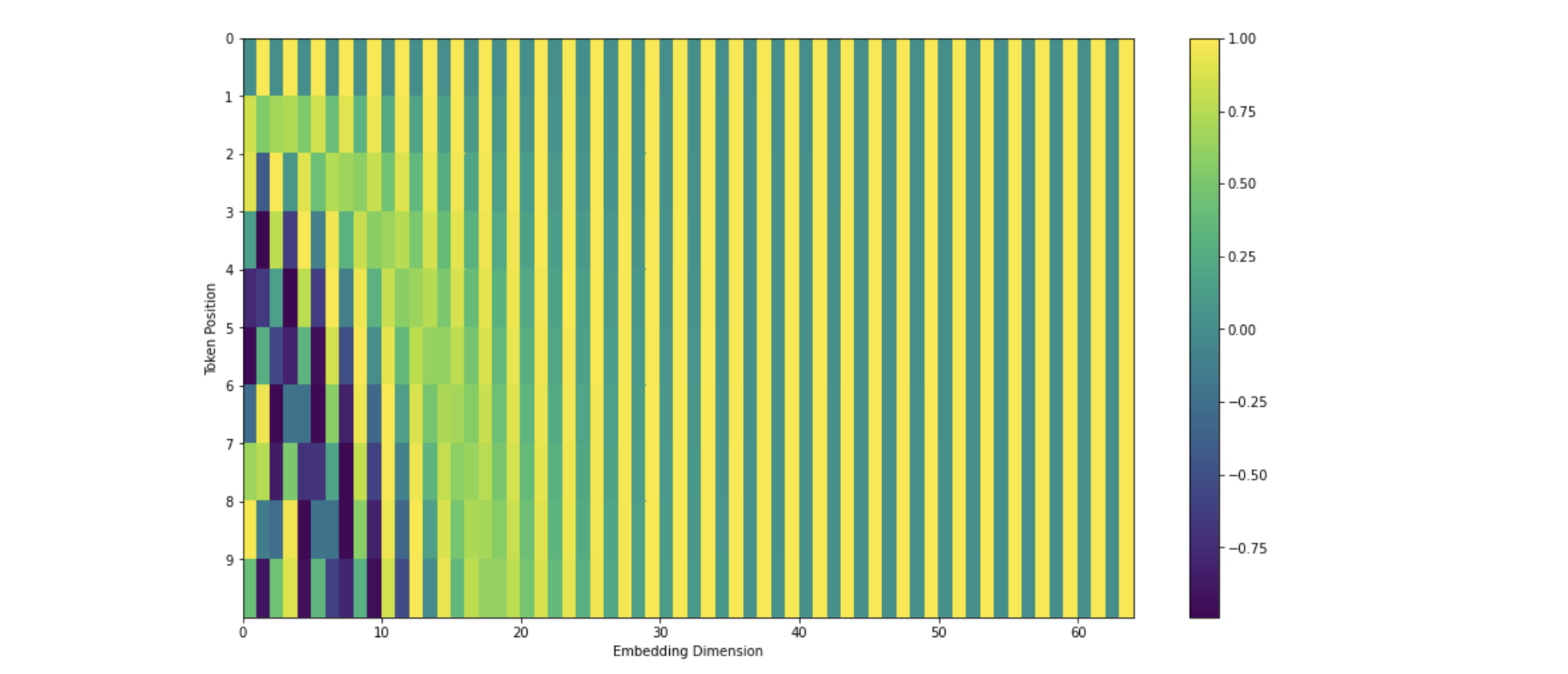
그 후, embedding + position 정보를 담은 값을 multi-head attention에 입력하게 된다. 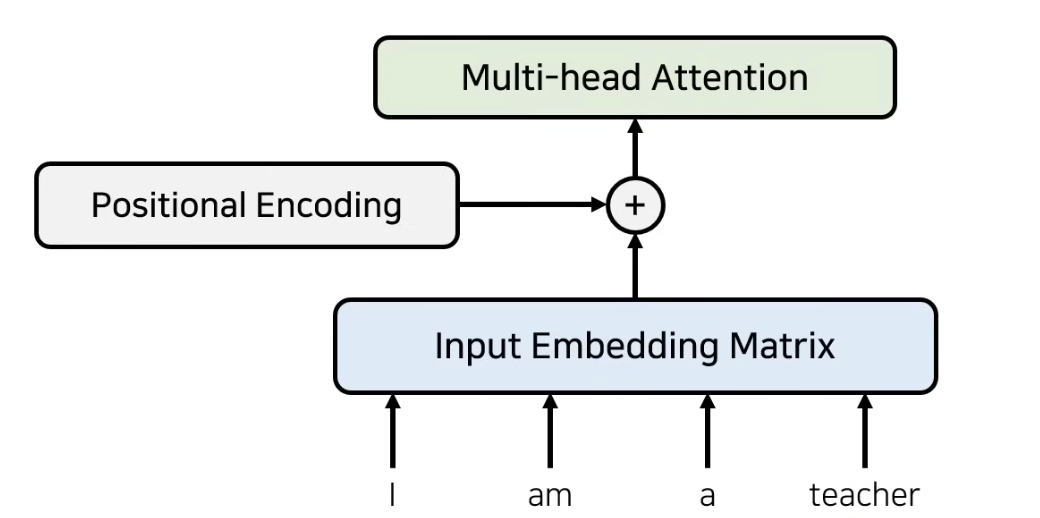
3) Self-Attention
Encoder파트에서 수행되는 attention은 self-attention이라고 하여, 각 단어가 서로에게 어떤 연관성을 가지고 있는지 문맥에 대한 정보를 파악하기 위한 목적으로 활용된다.
예를 들어, tower라는 단어만 보면 여러 의미(에펠타워, 롯데타워, 두바이의 높은 타워...등..)로 해석될 수 있다. 따라서 tower라는 단어 하나만 가지고 임베딩하는 것보다 주변 맥락을 함께 고려하면 tower의 의미를 더 정확하게 알 수 있다는 것이다. 만약 tower 앞에 Eiffel이라는 단어가 있었다면? 즉, 주변 context까지 한번에 고려했을 때 비로소 tower의 의미를 더욱 명확하게 임베딩할 수 있다는 것이다.
그런데 그 과정이 어떻게 이루어진다는 것인가? 자... 긴 여정이 될 것이다. 그렇지만 구체적인 예를 들어서 최대한 쉽게 설명해보겠다. 이 내용은 https://www.youtube.com/watch?v=eMlx5fFNoYc 이 유튜브에서 정말 잘 설명해주고 있어 해당 내용을 바탕으로 설명하고자 한다. 이번 섹션에 나오는 검정 바탕의 이미지도 이 유튜브에서 가지고 왔는데, velog의 출처 첨부 시스템의 난해함으로 앞에서 미리 밝혀두고 아래에는 별도로 표시하지 않았음을 양해 부탁한다.. 자 그럼 이제 시작한다!
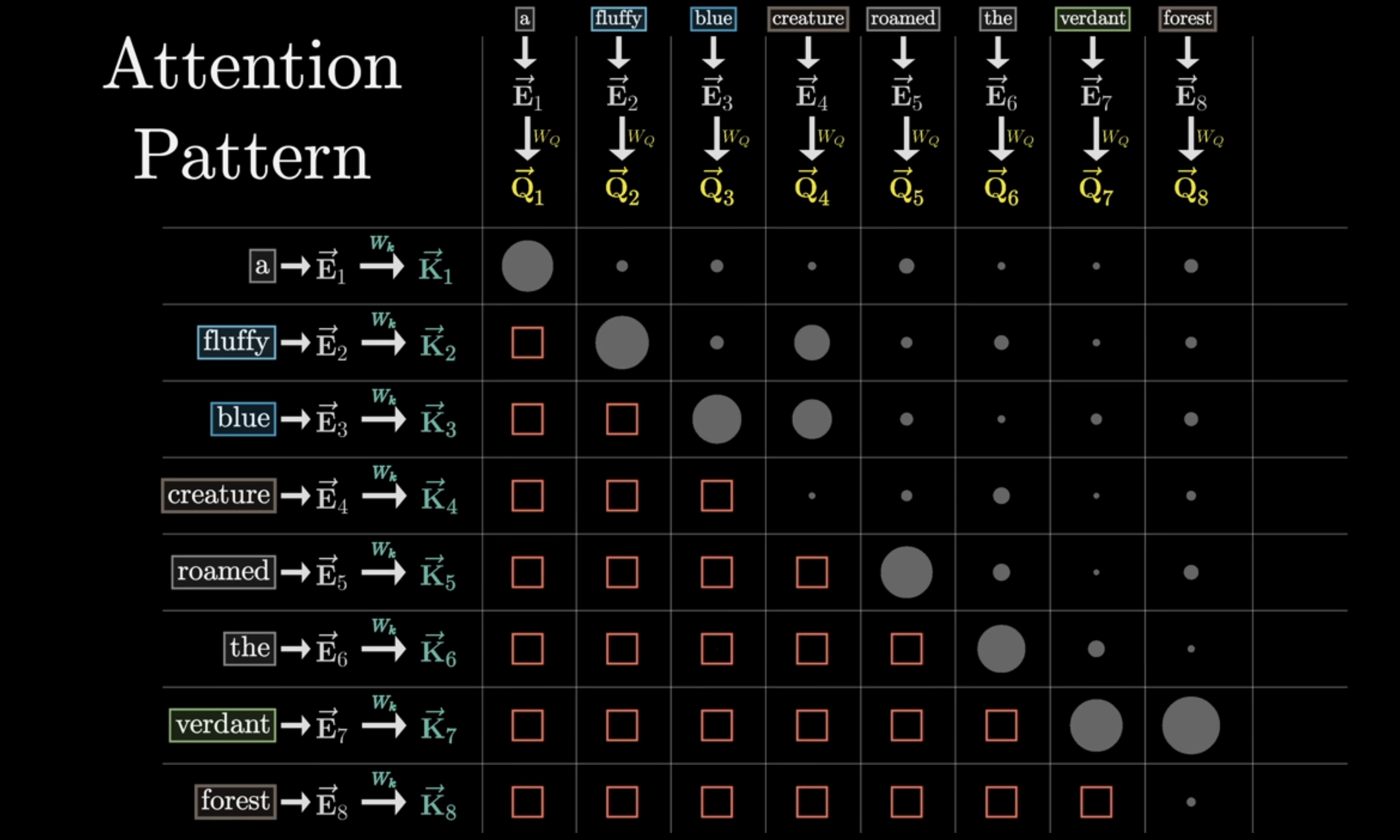
아래 그림에서 처음 단어 하나하나만 가지고 임베딩 했을 때에는 위에 첨부된 이미지를 상상하게 된다 (e.g., creature = 그냥 어떤 생명체). 그런데 Self-attention 과정을 통해 아래와 같이 보다 문맥의 의미를 모두 담고 있는 단어로 임베딩하게 되면 최종적으로 creature라는 단어를 '파란색의 복실복실한 털을 가지고 있는 생명체'로 구체화할 수 있게 된다. 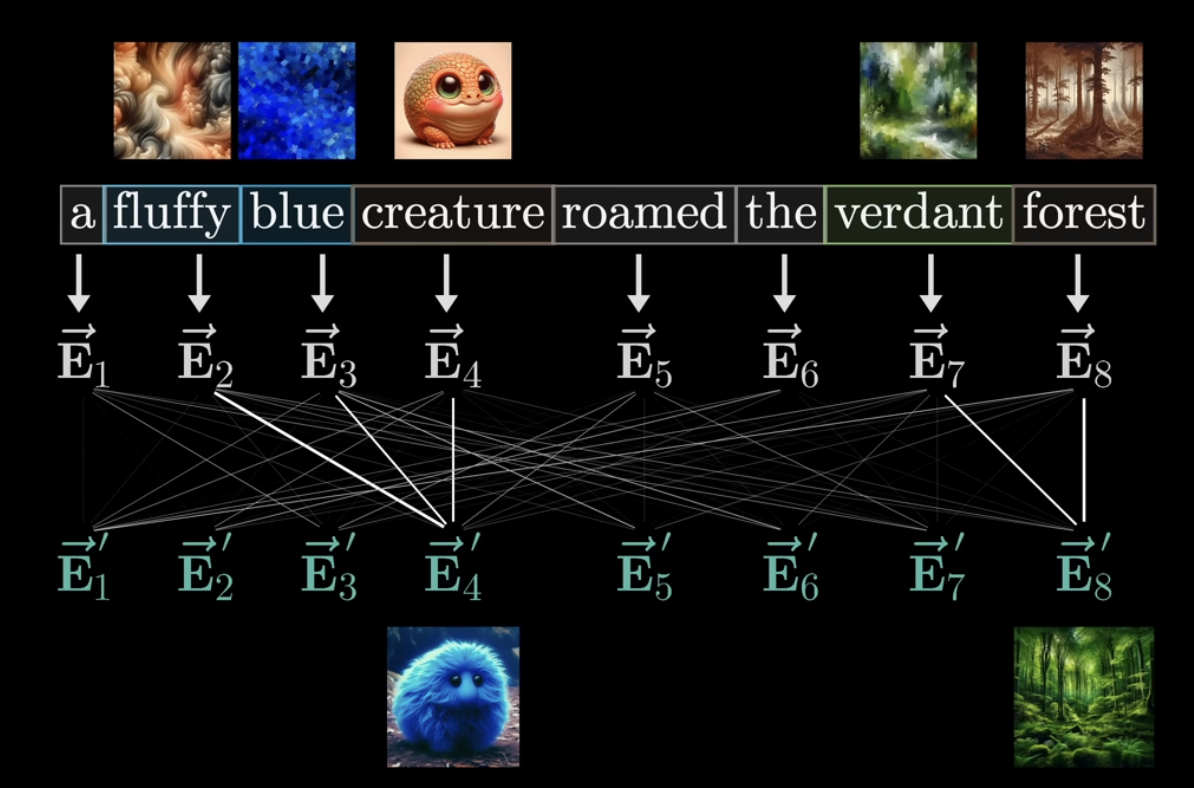
그 과정을 각 단어 관점에서 생각해보자. creature 단어가 물어본다. 나를 설명해줄 형용사 어디 없나? 있나? 이런 질문을 수학적으로 표현하면 Query vector가 되는 것이다. 이런 Query를 만드는 과정도 임베딩 벡터에 Weight를 곱한 형태로 표현된다. 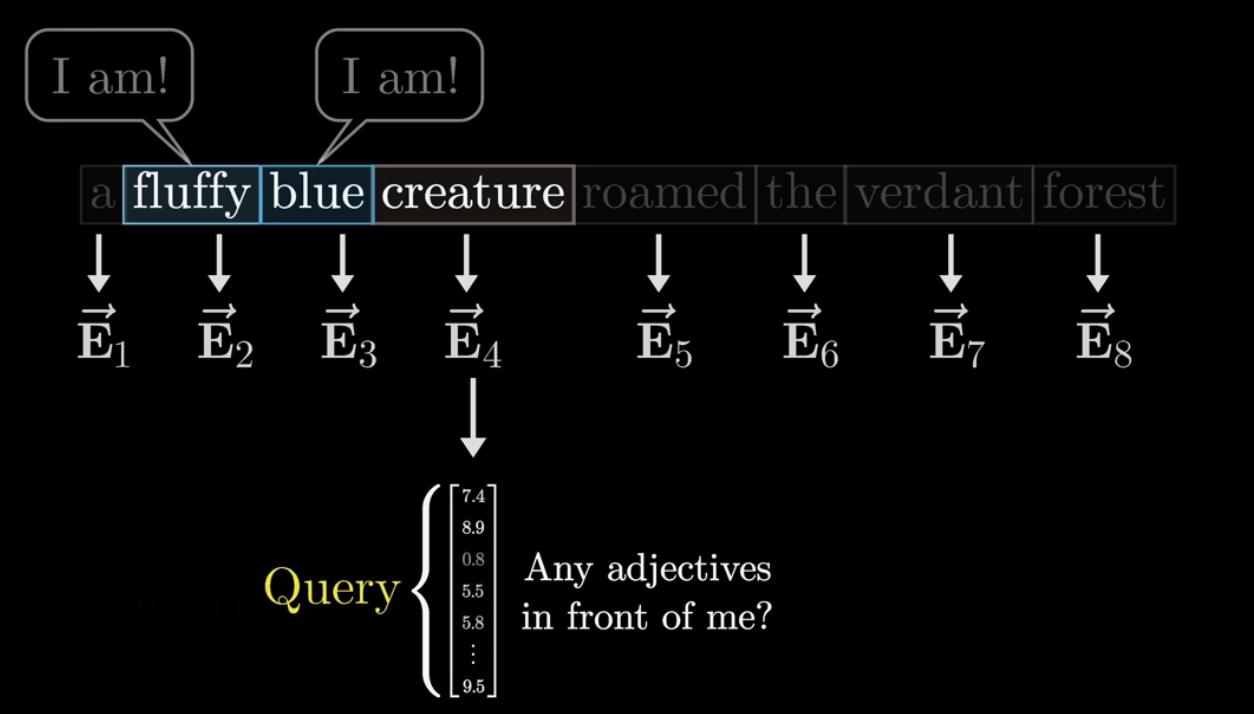
그 다음 형성되는 Key vector는 Query vector의 답변!이라고 생각하면 된다. 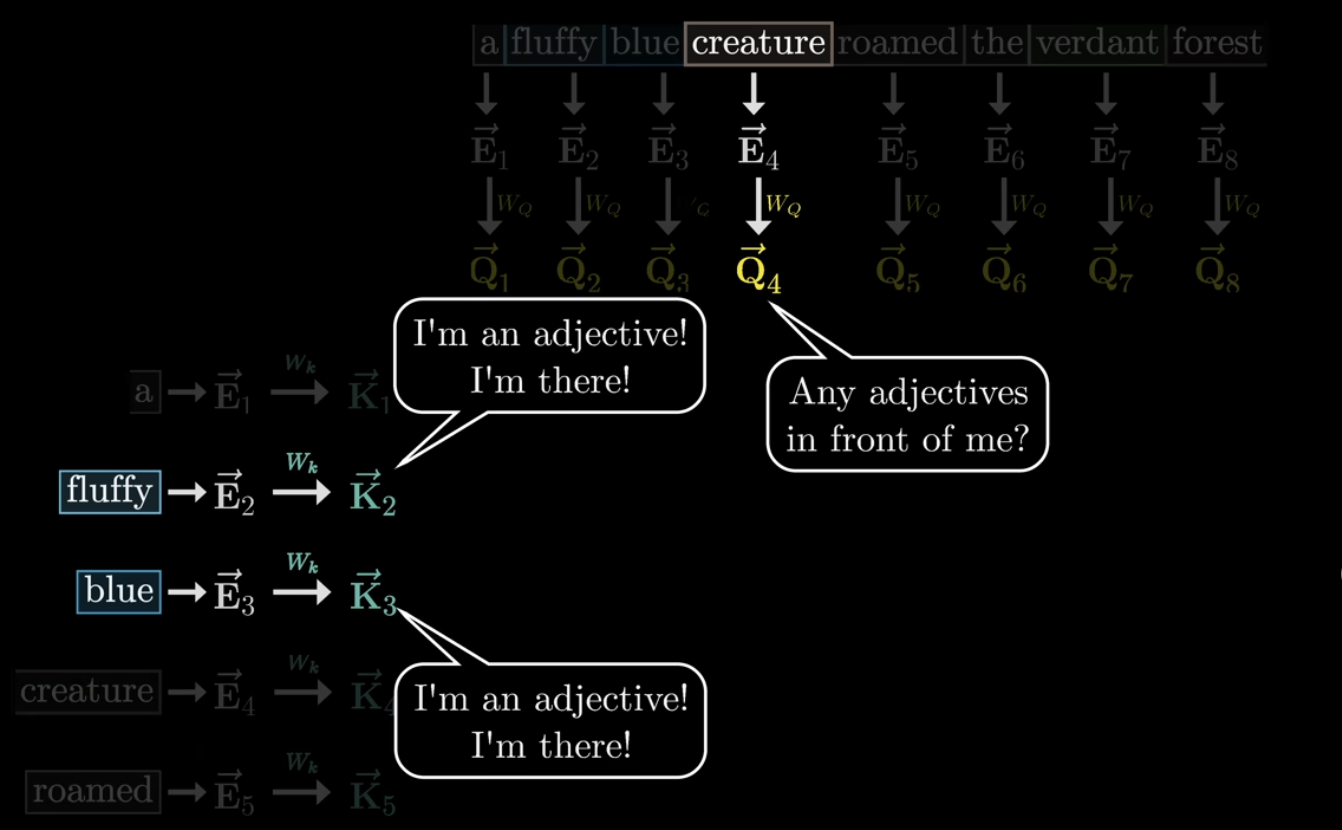
각 Query와 Key가 얼마나 잘 일치하는지/얼마나 유사한지를 측정하기 위해 모든 query와 key에 대해 내적을 수행하게 된다. 여기서 보면 fluffy와 blue가 creature와 내적을 수행했을 때 높은 값(=큰 원으로 표현되었다)을 지니고 있다는 것을 확인할 수 있다. 즉, fluffy와 blue가 creature라는 단어를 설명하기 위한 중요한 단어라는 것이다! 
그런데 이렇게 내적한 값들이 굉장히 랜덤한 숫자로 이루어져 있을 것이다. 그런데 우리가 원하는건 랜덤한 숫자가 아닌, 0에서 1 사이의 확률값으로 표현되어 어떤 단어가 얼마나 중요한지 확률적으로 알 수 있길 바란다. 따라서 softmax 를 씌워 값들을 normalize해준다. 이를 통해 한 단어가 다른 단어에 얼마나 연관이 있는지, 얼만큼 attention해야하는지 확률로서 알게 되는 것이다. 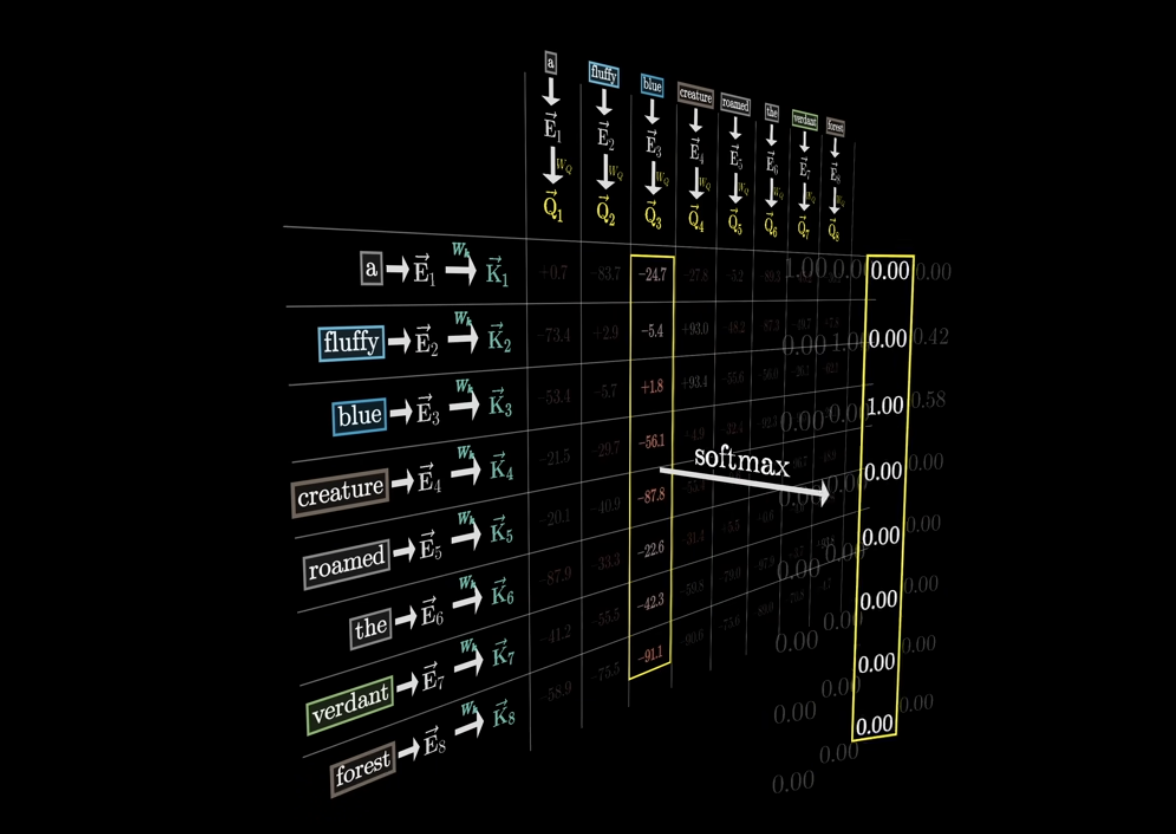
이렇게 하여 완성된 matrix를 우리는 attention pattern이라고 부른다.
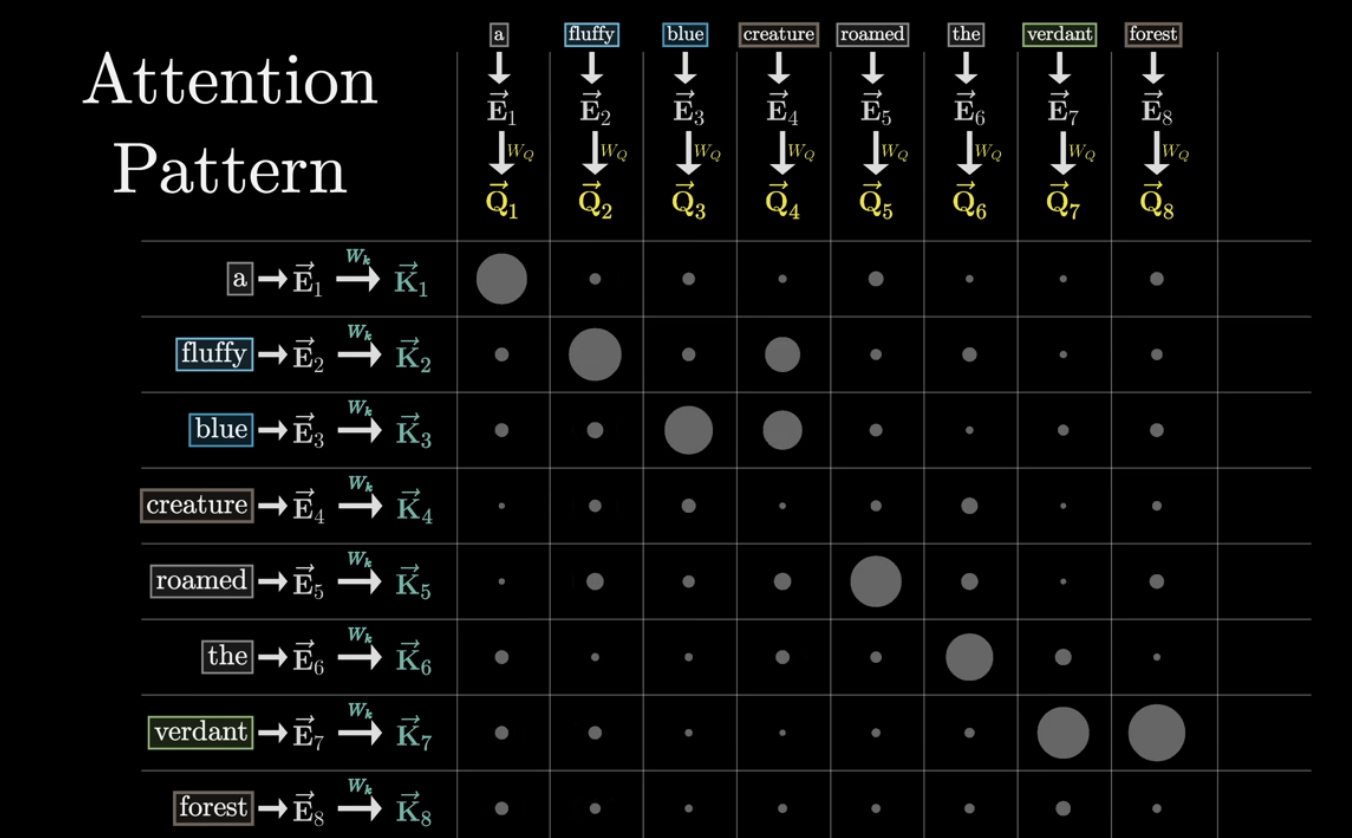
자 이제 이 단어(e.g., creature)가 다른 단어와 얼마나 연관이 있는지 알았으니, 이제는 진짜 그 단어에 대한 임베딩 값을 update할 때가 왔다! 즉, 기존의 creature라는 단어에 fluffy + blue 정보를 활용해서 creature 벡터를 fluffy blue creature 모양으로 바꿔주는 것이다. 아래 그림처럼 말이다. 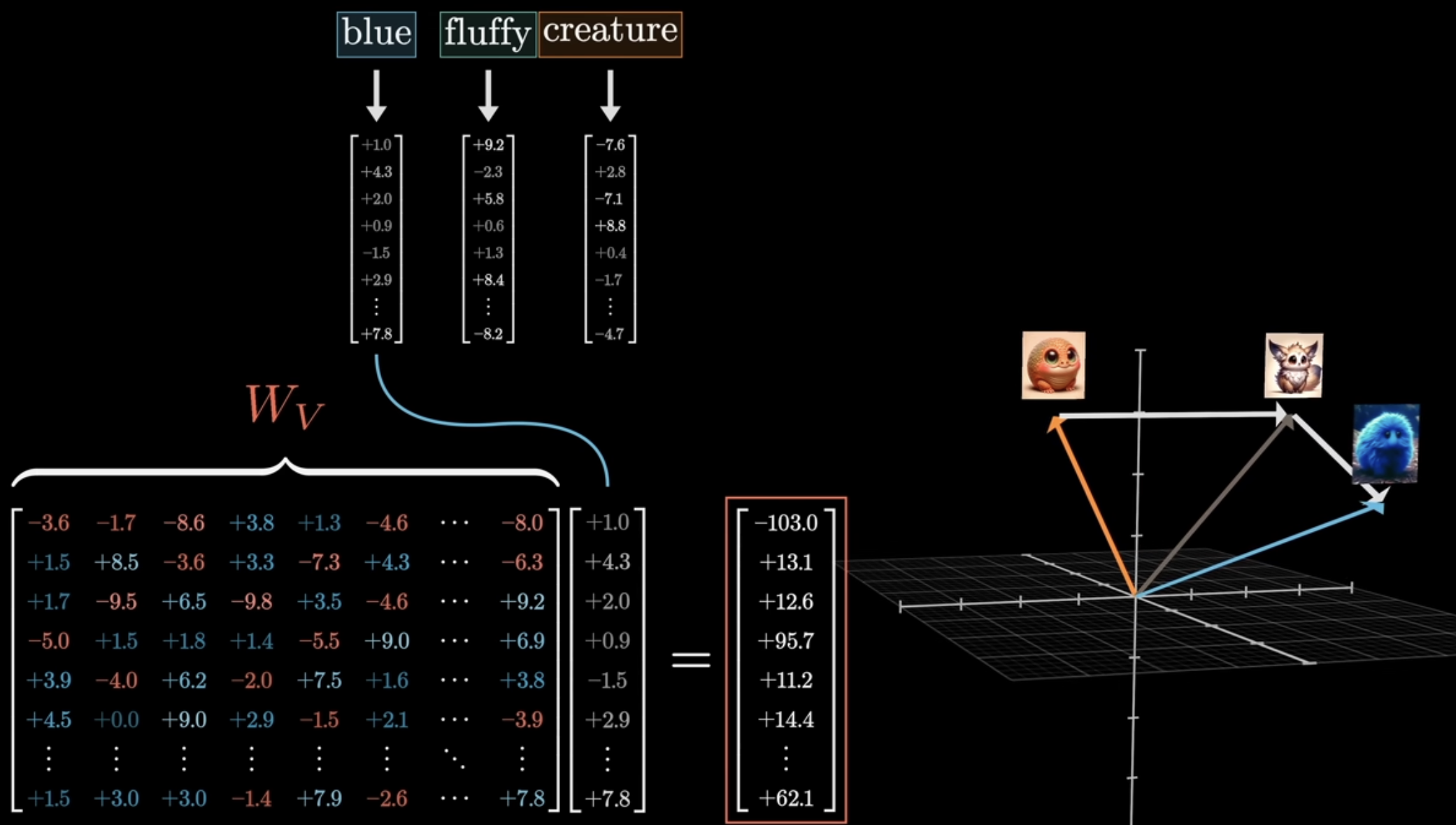
이에 대한 구체적인 과정은 다음과 같다. 앞에서 나온 softmax 결과에(e.g., creature는 fluffy와 42% 관련 있고, blue는 58% 관련 있다는 정보를 담고 있는 벡터) value vector를 곱하게 된다. 
그 후 원래의 임베딩 벡터에 value vector에 대한 weighted sum을 해주면 (softmax값 * value값들을 모두 더해주면()) 최종적으로 우리가 원하는 creature에 대한 명확한 의미를 지닌 벡터가 나오게 되는 것이다. 
이 한 과정이 Single head of Attention이다. 
그런데 attention block에 들어가는 것은 multi-headed attention이다. single head of attention이 병렬적으로 들어가는 것인데, 구체적으로 gpt-3에는 96개의 attention head가 들어간다고 한다. 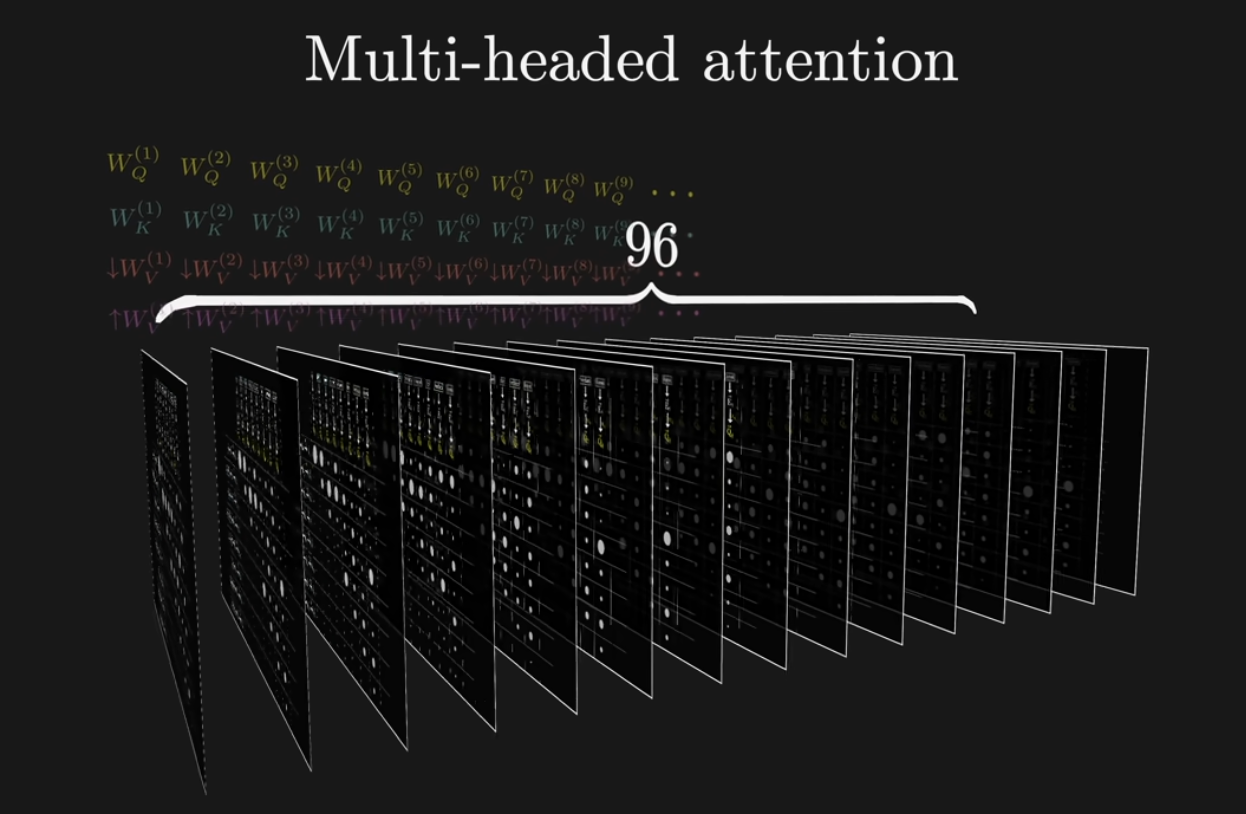
즉, original embedding에 value의 weighted sum 결과()를 96번 반복하여 생성된 값을 모두 더해주어 New embedding으로 update해주게 된다. 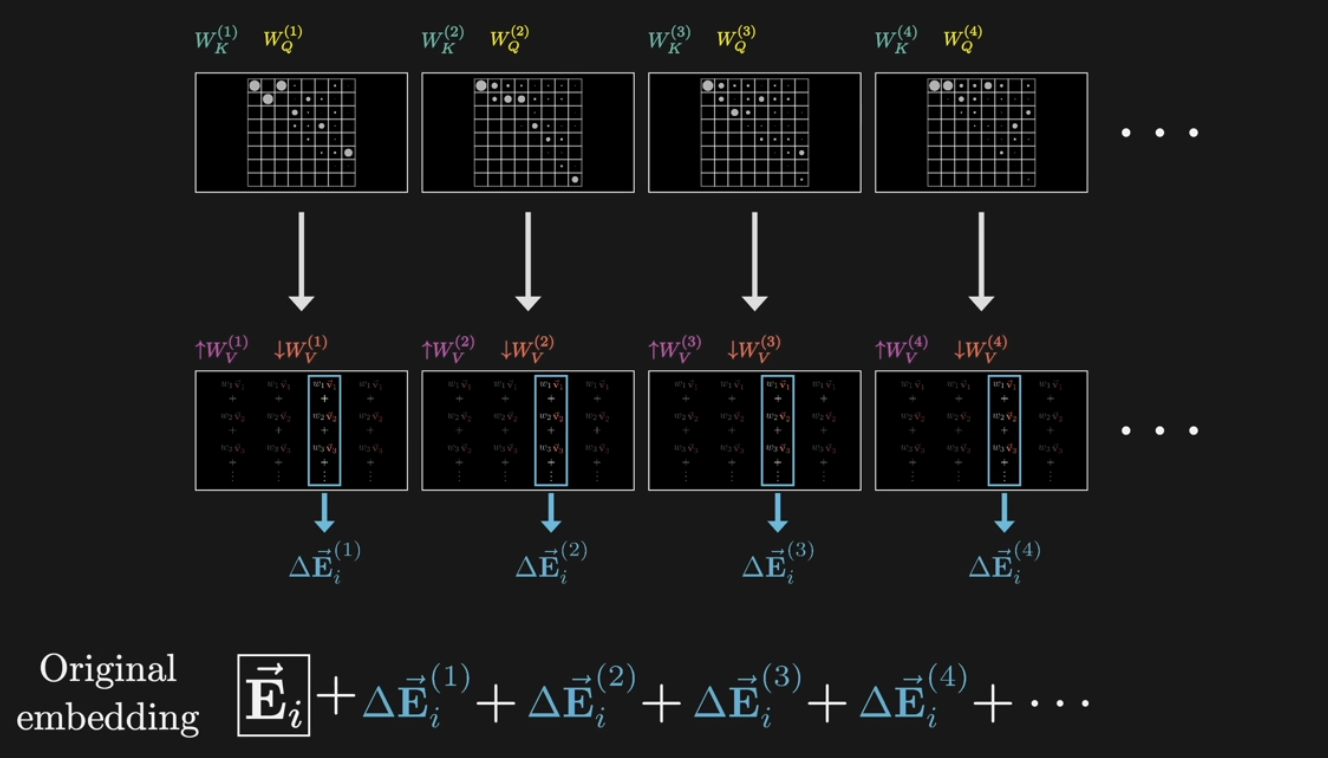
자, 그리고 나서 이러한 multi-head attention block에 feed forward (multilayer perceptron)을 N번 반복 수행하게 된다. 즉, 네트워크를 지날수록 보다 더 미묘한 의미까지 인코딩하게 된다. 정서, 어조, 어떤 과학적 진실과 관련이 있는 것인지 등을 말이다. 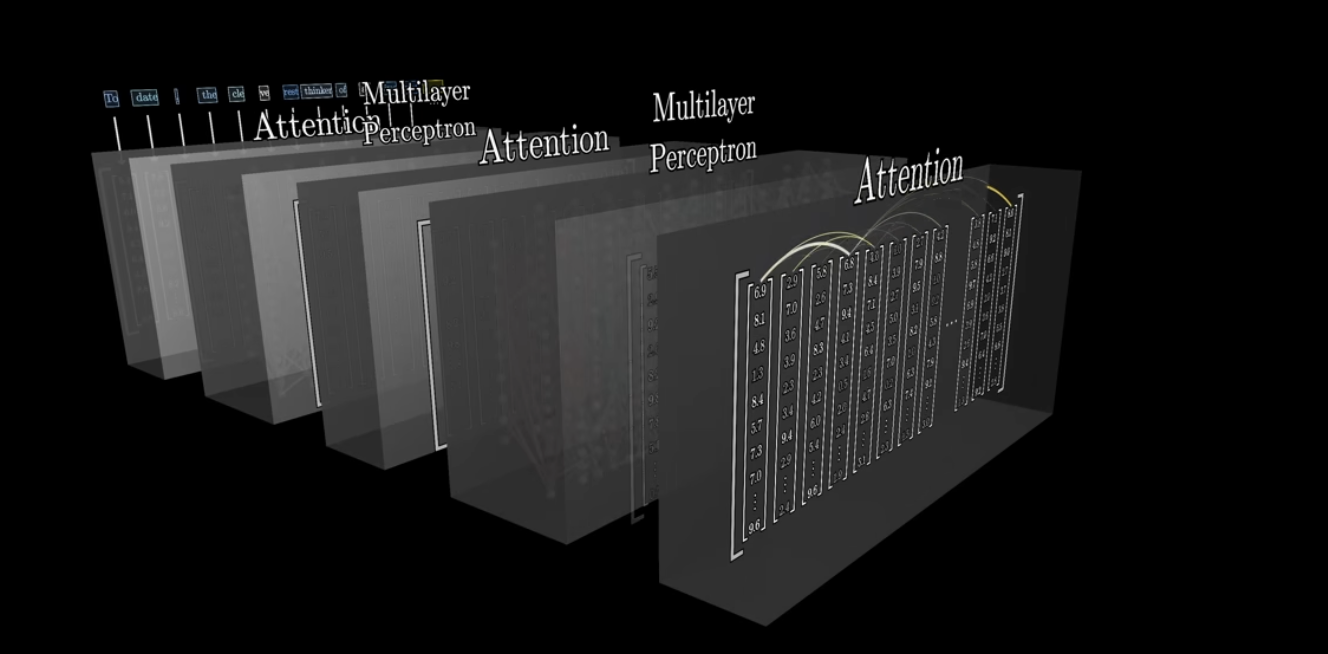
이를 종합한 이미지를 Transformer 논문에 사용된 figure로 표현하자면 아래와 같다. 여기서 이야기 하지 않은 것은 attention block에 ResNet처럼 성능 향상을 위해 Residual Learning을 사용한다는 것이다. 이를 통해 잔여된 부분만 학습하도록 하여 보다 수월한 학습이 가능하게 된 것이다. 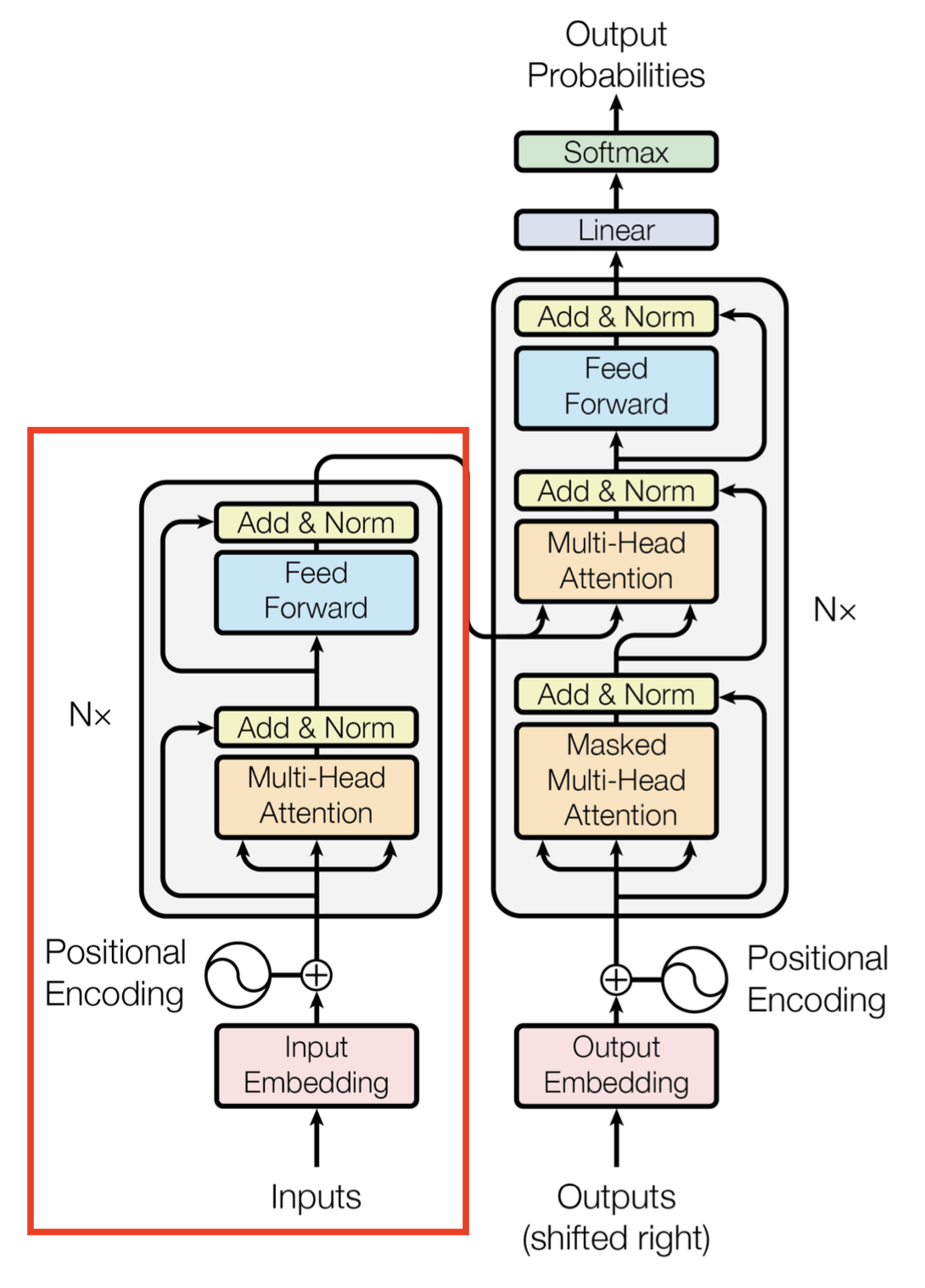
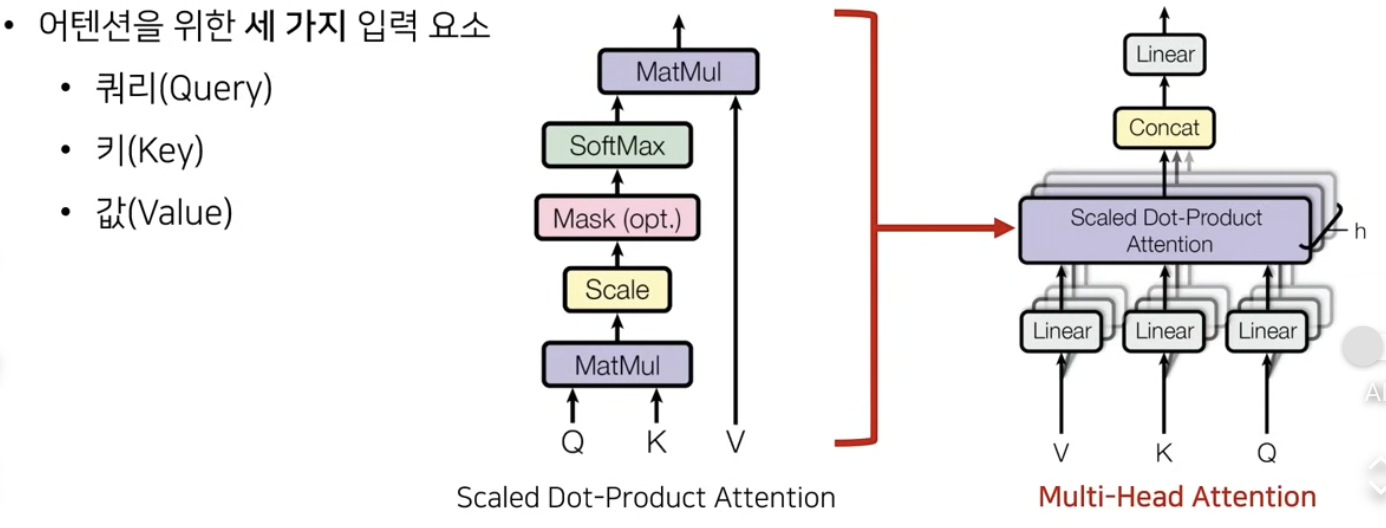
이걸 식으로 나타내면 다음과 같다. 여기서 아마 앞에서 이야기하지 않은 가 나오게 된다. 얘는 그냥 단순히 scaling factor로 softmax 함수를 살펴보면 0 근처에서는 gradient가 높게 형성되지만 양끝에서는 기울기가 0에 가까워진다. 따라서 gradient vanishing 문제를 해결하기 위해 추가한 scaling factor인 것이다. 
4) Decoder
앞서 이야기한 대로, 모델 입력값은 여러 encoder layer를 지나게 된다. 그리고 가장 마지막 encoder layer에서 나오는 출력값이 decoder에 들어가게 된다. 이렇게 하는 이유는 decoder파트에서 매번 출력할 때마다 입력소스 문장 중에서 어떤 단어에 가장 많은 초점을 두어야하는지를 알려주기 위함이다.
decoder도 여러 Layer로 이루어져 있다. 다시 말해, encoder의 마지막 layer의 출력값이 각 decoder layer의 입력값이 된다. (encoder의 각 레이어마다의 값을 decoder의 입력으로 받는 방법론도 존재하지만 기본 트랜스포머의 아키텍쳐는 encoder의 마지막 layer 출력값을 매번 decoder의 입력값으로 넣어주는게 디폴트이다.) 그리고 decoder의 가장 마지막 Layer에서 나오는 출력값이 바로 우리가 번역을 수행한 결과의 출력 단어가 된다. 참고로, 일반적으로 encoder와 decoder의 레이어 개수는 동일하게 맞춰주는 경우가 많다. 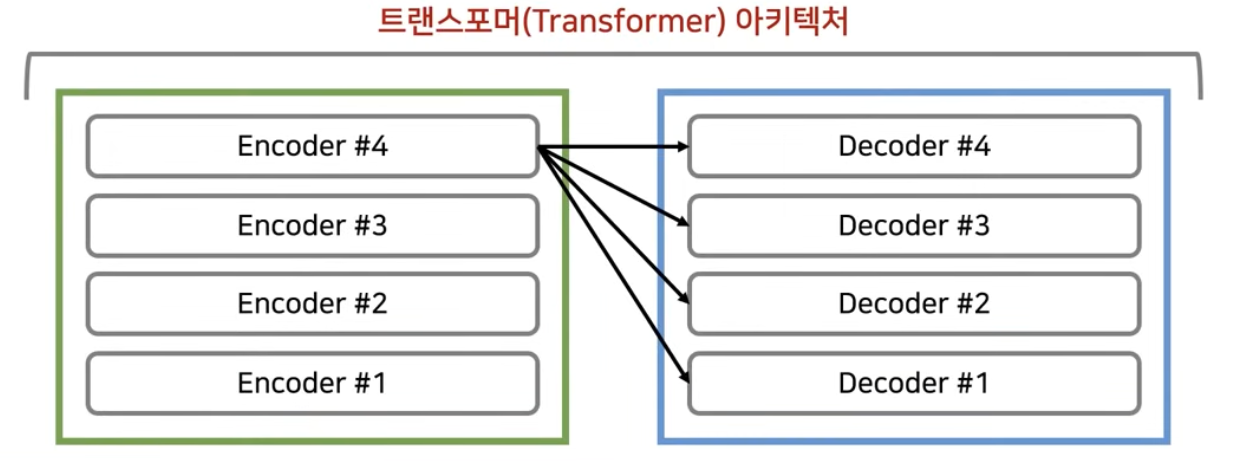
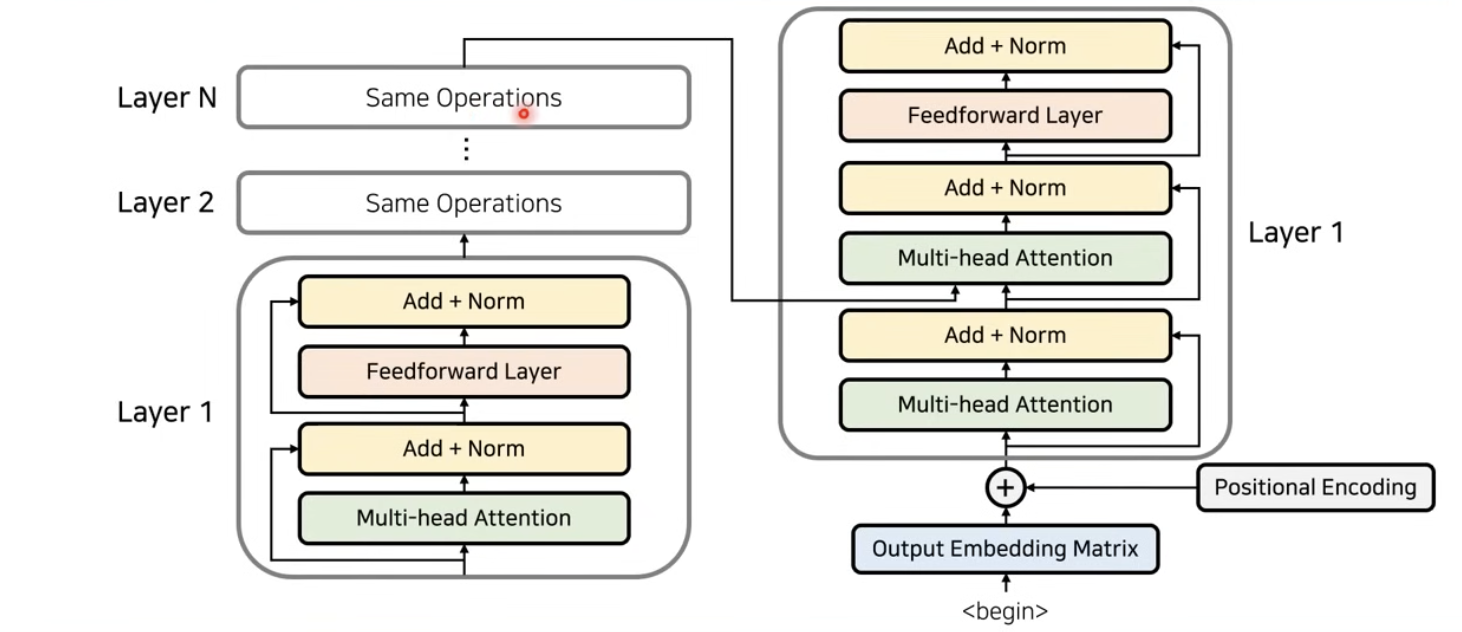
decoder또한 앞 단어의 정보를 받고, 각 단어의 상대적인 위치 정보를 알기 위해 positional encoding을 수행한다.
하나의 decoder layer에서는 두개의 attention block이 사용된다. 첫번째 attention block에서는 self attention으로, encoder에서의 역할과 동일하다. 즉, 출력 문장에서의 각 단어가 서로가 서로에게 어떤 가중치를 가지는지를 구하도록 만들어서 출력되고 있는 문장에 대한 전반적인 표현을 학습하게 된다. 이는 auto-regressive 방식을 사용하기 때문에 가능하다.
이어서 두번째 attention block에서는 encoder의 정보를 decoder가 attention하게 한다. 즉, 각 출력 단어가 소스문장(입력문장)에서의 어떤 단어와 연관성이 있는지 구해주게 된다. 따라서 두번째 attention block은 encoder-decoder attention이라고 부른다.
예를들어, 입력 문장이 I am a teacher이고, 출력값은 나는 선생님이다라고 하자. 이 때 encoder-decoder attention은 선생님이라는 번역/출력은 영어에서 어떤 단어와 가장 높은 연관성을 가지는지를 구하는 것이다. 이 때 decoder도 입력 demension과 출력 demension을 같도록 하여 layer 중첩이 가능하도록 한다.
Masked Decoder Self-Attention
앞에서 decoder단에서의 첫번째 attention block은 encoder와 동일한 역할을 한다고 하였다. 90% 맞는 말이지만 사실 조금 다른 형태를 지닌다. Masked라는 단어가 붙은 것처럼 일부 영역을 mask하기 때문이다. 즉, 아래 이미지처럼 일부 영역을 mask하는 것이다.
mask하는 방법은 softmax를 취하기 전에 일부 영역을 -Inf로 값을 바꿔준다. 그렇게되면 softmax를 적용한 이후에 해당 값들은 0이 되고 나머지 값/각 column은 normalize되게 된다. 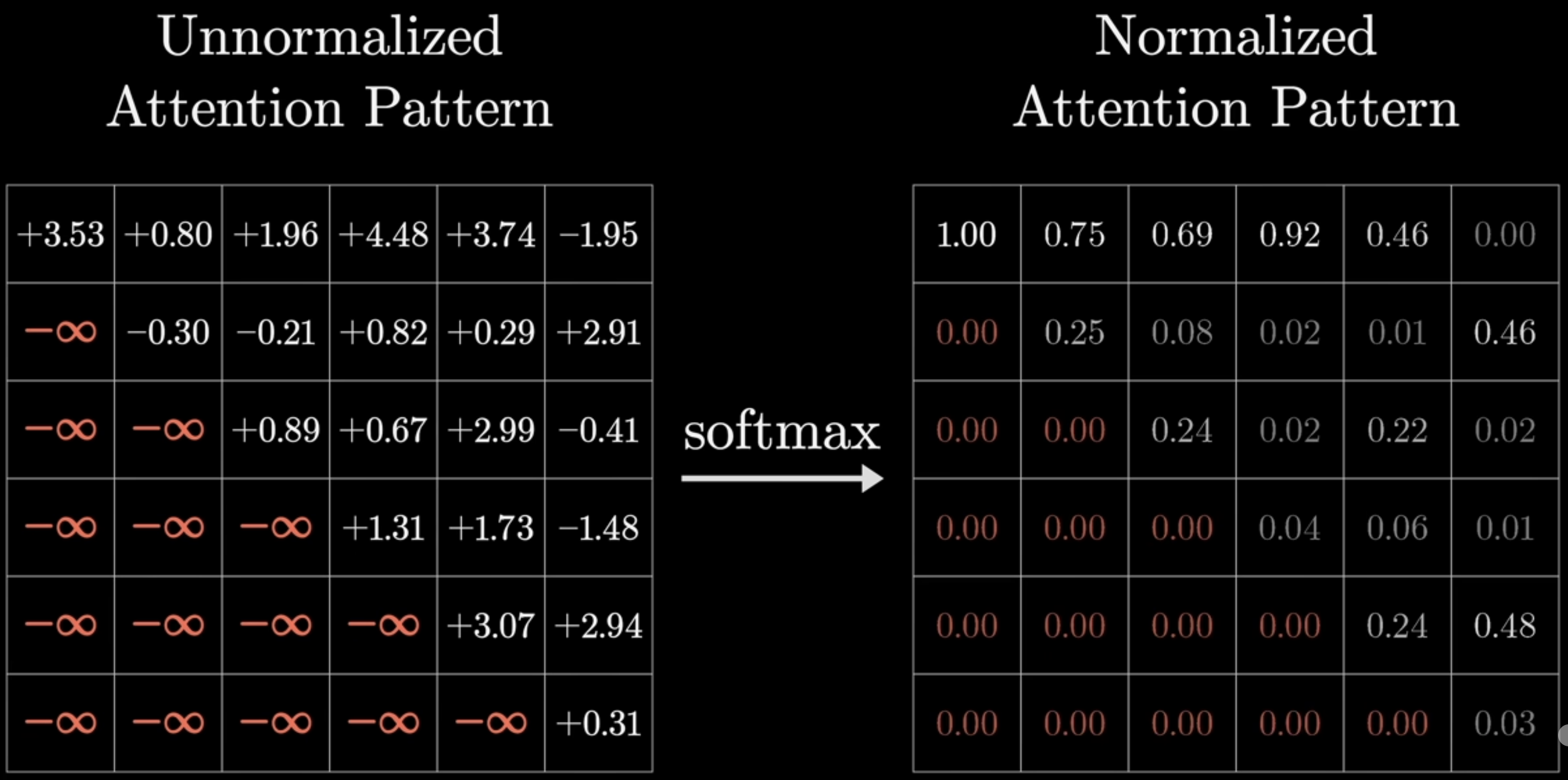
그렇다면 왜 이걸 사용하는 것인가? 모델 학습 단계에서 출력 단어가 다른 모든 출력단어를 참고하는 것이 아니라 앞쪽에 위치한 단어만 참고하도록 하는 것이다. 예를들어, '나는 축구를 했다'라는 단어를 출력함에 있어서 '축구를' 이라는 단어를 출력할 시기라고 해보자. 그 때 뒤쪽에 '했다' 라는 단어가 나온다는걸 미리 알고 있다면 일종의 cheating이지 않겠는가.(미리 알 수 있는 이유는 이 모델 자체가 병렬적으로 한번에 모든 문장을 처리하는 알고리즘을 따르고 있기 때문이다.) 그렇게 되면 모델이 정상적으로 학습이 안되기 때문에 학습 시에 치팅 없이 제대로 학습하도록 하기 위해 다음과 masked decoder self-attention이 사용되는 것이다.
Encoder-Decoder attention
두번째 attention block은 encoder-decoder attention이다. 이 때 각 출력 단어를 만들기 위해 encoder에서의 어떤 단어를 참고하면 좋은지를 파악하기 위해 encoder의 출력값을 사용하게 된다. 구체적으로, 각 단어를 출력하기 위해 어떤 단어를 참고해야 해? 라고 묻는 것이기 때문에 decoder의 출력 단어가 query가 되고, 그에 대한 답인 key와 value는 encoder파트의 출력값의 key와 value가 되는 것이다.
(참고)Encoder와 Decoder
RNN을 사용할 때에는 입력단어 개수만큼 인코더 레이어를 거쳐 매번 hidden state를 만들었다면, 트랜스포머에서는 입력 단어가 한번에 encoder를 거치고 병렬적으로 출력값을 구해낸다. 따라서 RNN을 사용했을 때와 비교하여 일반적으로 계산복잡도가 더 낮다.
출력값을 내보낼때에는 decoder아키텍쳐를 여러번 사용해서 eos(end of sequence였나?)가 나올때까지 반복한다.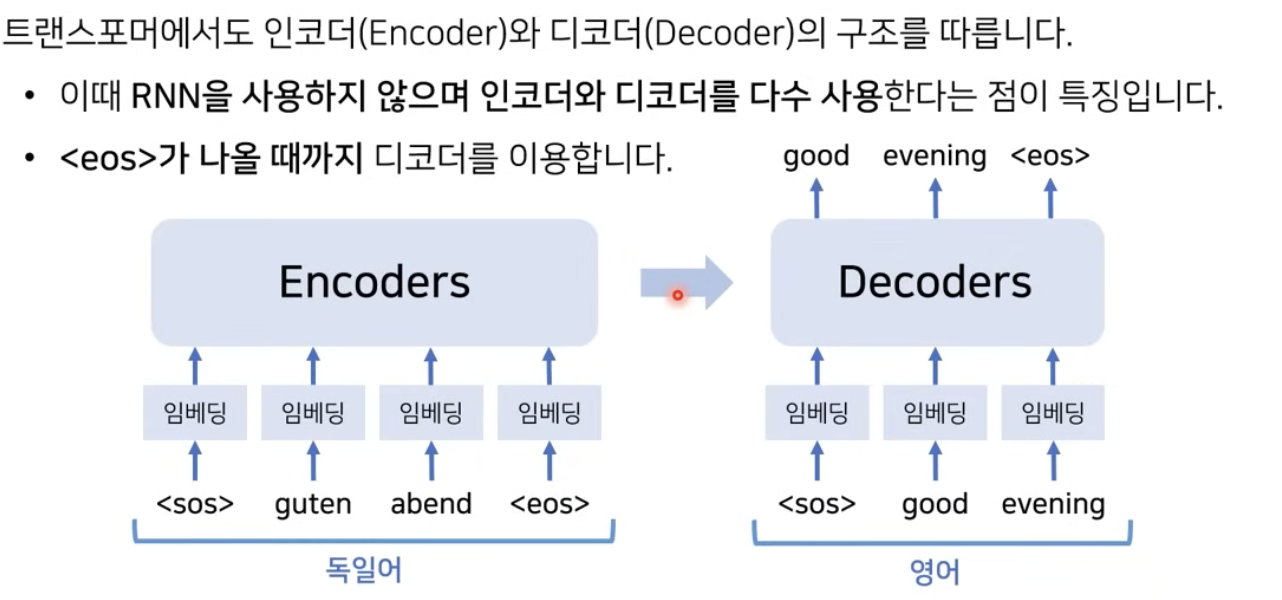

정말 좋은 글이네요. 항상 잘 보고 있습니다~