데이터를 특정 순서로 정리하려고 한다.
하지만 정렬 알고리즘은 아무리 빨라도 O(N logN)이다. 데이터를 자주 정렬해야 하면 데이터를 항상 정렬된 순서로 유지하는 편이 합리적이다.
정렬된 배열은 읽기에 O(1), (이진) 검색에 O(logN)이 걸린다. 하지만 삽입과 삭제가 상대적으로 느리다. 평균 시나리오에서 N/2 단계, 즉 O(N)이 걸린다.
해시 테이블은 연산이 빠르지만 순서를 유지하지 못하므로 알파벳순으로 목록을 정렬하는 애플리케이션에는 적절치 않다.
트리
트리는 노드기반 자료구조이지만, 각 노드는 여러 노드의 링크를 가질 수 있다.
- 트리에 쓰이는 고유한 용어:
- 가장 상위 노드를 루트라고 부른다.
- A노드의 자식 노드는 B,C이며, B,C의 부모 노드는 A이다.
- 패밀리 트리에서는 노드에 자손과 조상이 있을 수 있다. 한 노드의 자손은 그 노드에서 생겨난 모든 노드이며, 한 노드의 조상은 노드를 생겨나게 한 모든 노드이다.
- 트리에는 레벨이 있다. 각 레벨은 트레이서 같은 줄이다.
- 트리의 프로퍼티는 균형 잡힌 정도를 말한다. 모든 노드에서 하위 트리의 노드 개수가 같으면 그 트리는 균형 트리다. 반면 불균형 트리는 하위 노드가 개수가 같지 않다.
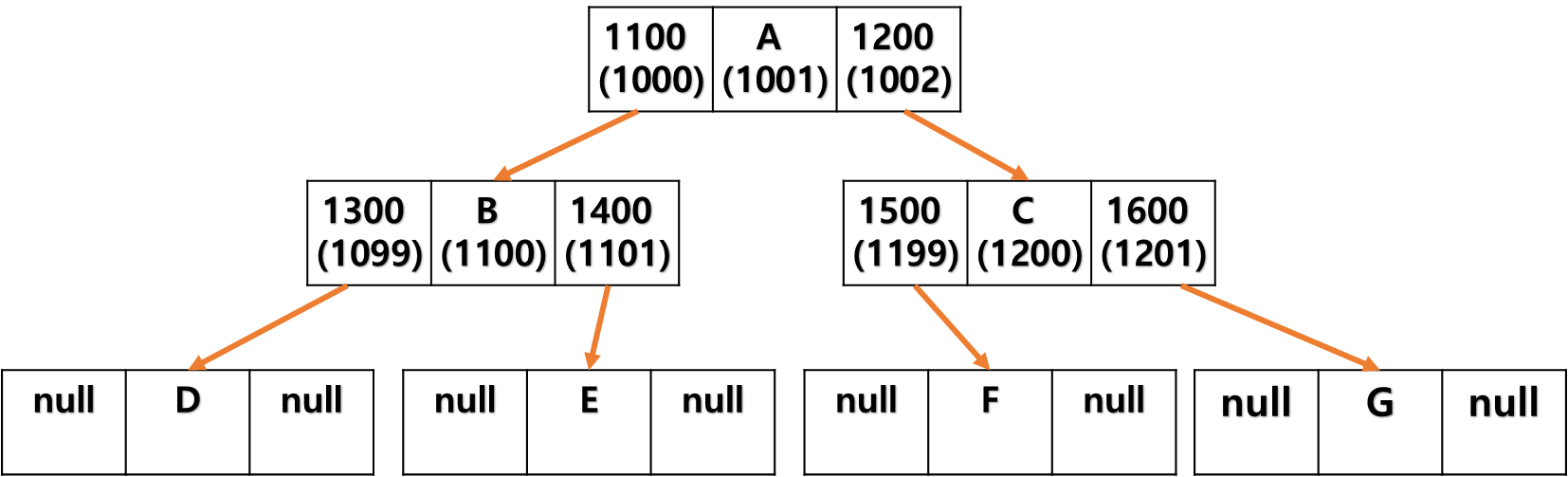
이진 탐색 트리
- 이진 탐색 트리는 각 노드의 자식 노드는 0,1,2 중 하나다.
- 각 노드의 자식은 최대 왼쪽에 하나, 오른쪽에 하나다.
- 한 노드의 왼쪽 자손은 그 노드보다 작은 값만 포함할수있다. 오른쪽은 큰 값만 포함할수 있다.
이진 탐색 트리는 각 노드에 자식이 최대 2개다. 이 때 자식 노드가 왼쪽에 2개, 혹은 오른쪽에 2개 존재 할 경우 이는 이진 탐색 트리가 아니다.
코드 구현: 이진 탐색 트리
public class chapter15 { public static void main(String[] args) { TreeNode<Integer> node1 = new TreeNode<>(25); TreeNode<Integer> node2 = new TreeNode<>(75); TreeNode<Integer> node3 = new TreeNode<>(50,node1,node2); } } class TreeNode<T>{ private T value; private TreeNode leftChild; private TreeNode rightChild; public TreeNode(T value){ this.value = value; } public TreeNode(T value, TreeNode leftChild, TreeNode rightChild){ this.value = value; this.leftChild = leftChild; this.rightChild = rightChild; } }
검색
이진 탐색 트리의 검색은 다음과 같이 동작한다.
- 노드를 현재 노드로 지정한다(알고리즘을 시작 할 때는 루트 노드가 첫 번째 현재노드다).
- 현재 노드의 값을 확인한다.
- 찾고 있는 값이면 좋다.
- 찾고 있는 값이 현재 노드보다 작으면 왼쪽 하위 트리를 검색한다.
- 찾고 있는 값이 현재 노드보다 크면 오른쪽 하위 트리를 검색한다.
- 찾고 있는 값을 찾았거나 트리 바닥에 닿을 때까지 위 단계를 반복한다.
루트 노드는 50, 왼쪽 노드는 25, 오른쪽 노드는 75라고 가정하자.
이 때 찾고 싶은 값이 36이라면, 왼쪽 노드는 36보다 작으므로, 오른쪽 노드를 탐색한다.
이와 같은 가정을 반복하여 검색을 진행한다.
이진 탐색 트리의 효율성
이진 탐색트리는 검색을 하는 과정에서 자식 노드 중 하나를 배제한다. 예로 오른쪽 노드를 선택했으면, 왼쪽 노드는 배제된다.
따라서 각 단계마다 남은 값 중 반을 제거하므로 이즈는 O(logN)이다.
log(N)레벨
이진 탐색트리의 데이터가 N개라면, row(줄)은 log(N)이다.
만약 모드 줄이 노드로 채워져 있다면, 가득 채운 새 레벨을 트리에 추가 할 때마다 트리의 노드 개수는 대략 두 배로 늘어난다.
즉 노드를 두배로 늘리면 레벨이 하나 늘어난다.
이진 탐색 트리 검색은 O(logN)인데 이는 정렬된 배열의 이진 검색과 효율성이 같다.
하지만 이진 탐색 트리는 삽입에 있어서 정렬된 배열보다 훨씬 뛰어나다.
코드 구현: 이진 탐색 트리
public static TreeNode search(Integer searchValue, TreeNode node){ // 기저 조건: 노드가 없거나, 찾고 있던 값이라면 if (node == null || node.value == searchValue){ return node; } // 찾고 있는 값이 현재 노드 값 보다 작으면 왼쪽 자식 노드를 탐색한다. if (searchValue <= (Integer) node.value) return search(searchValue, node.leftChild); // 찾고 있는 값이 현재 노브 보다 크면 오른쪽 자식 노드를 탐색한다. else return search(searchValue, node.rightChild); }
삽입
이진 탐색 트리의 삽입은 O(logN)이 걸린다.
모든 노드가 가득찬 레벨 4의 이진 탐색 트리가 있다고 가정하자. 이 때 우리는 어떠한 값을 넣게 되어도 레벨 + 1 단계 만에 삽입을 할 수있다.
그렇기에 이진 탐색 트리는 매우 효율적이다. 정렬된 배열은 검색 O(logN), 삽입 O(N) 거릴는 반면 이진 탐색 트리는 검색과 삽입 모두 O(logN)이다.
따라서 데이를 많이 변경할 애플리케이션에 매우 중요하다.
코드 구현: 이진 탐색 트리 삽입
public static<T> void insert(T value, TreeNode node){ // 삽입 값이 노드 값 보다 작을 경우 if ((Integer) value < (Integer) node.value) { // 노드의 왼쪽 자식노드가 null이라면 새로운 노드를 추가. if (node.leftChild == null) node.leftChild = new TreeNode(value); // 재귀를 반복 else insert(value, node.leftChild); } // 삽입 하려는 값이 노드 값보다 클 경우 else if ((Integer) value > (Integer) node.value) { // 오른쪽 자식 노드가 비었다면 새로운 노드를 삽입. if (node.rightChild == null) node.rightChild = new TreeNode(value); // 아니라면 재귀를 반복. else insert(value, node.rightChild); } return; }
삽입 순서
정렬된 데이터를 트리에 삽입하게 되면 불균형이 심하고 효율성이 낮은 트리가 된다.
예로 1,2,3,4,5 를 차례대로 삽입한다고 생각해보자.
모든 값이 부모 노드보다 크므로 계속 오른쪽 노드에만 새로운 값이 삽입될 것이다.
이 경우 시간 복잡도는 O(N)이다.
하지만 3,2,4,1,5 순서로 삽입하게 되면 균형 잡힌 트리가 된다. 즉 균형 잡힌 트리에 데이터를 삽입 할 경우만 O(logN)이다.
최악의 시나리오: O(N)
최선, 평균 시나리오: O(logN)
삭제
이진 탐색 트리에서 삭제는 매주 주의 깊게 실행해야 된다. 만약 부모 노드를 삭제 할 경우 하위 노드(자식 노드)가 모두 삭제 될 가능성이 있기 때문이다.
이진 탐색 트리에서 사겢는 다음과 같은 규칙을 가진다.
- 삭제할 노드에 자식이 없으면 그냥 삭제한다.
- 살제할 노드에 자식이 하나면 노드를 삭제하고 그 자식을 삭제된 노드가 있던 위치에 넣는다.
자식이 둘인 노드 삭제
자식이 하나 혹은 없을 때는 간단하게 쉽게 삭제 할 수 있었다. 하지만 만약 자식이 두개라면 어떻게 삭제해야 할까??
- 자식이 둘인 노드를 삭제할 때는 삭제된 노드를 후속자 노드로 대체한다. 후속자 노드란 삭제된 노드보다 큰 값 중 최솟값을 갖는 자식노드다.
예를 들어 부모 노드가 56, 자식 노드가 52,61이라면 이 때 56 삭제했다. 자식 노드인 52, 61 중 부모 노드인 56 보다 큰 값을 가지면 가장 낮은 수가 바로 후속자 노드이다.
후속자 노드 찾기
후속자 노드를 찾는방법은 다음과 같다.
- 삭제된 값의 오른쪽 자식을 방문해서 그 자식의 왼쪽 자식을 따라 계속해서 방문하며, 더 이상 없을 때까지 내려간다. 바닥 값이 후속자 노드다.
단 한번 오른쪽으로 방문 후 바닥에 있는 노드를 후속자 노드로 하는 이유가 뭘까??
우선 오른쪽 자식 노드는 부모 노드보다 큰 값을 가지고 있는 노드들이다. 이 때 계속 왼쪽으로 노드를 방문 할 경우 그 중 가장 작은 값을 찾을 수 있다.
오른쪽 자식이 있는 후속자 노드
후속자 노드를 찾았다. 그 후 후속자 노드와 부모 노드를 교체 한다고 가정하자.
이 때 후속자 노드에 오른쪽 자식 노드가 존재한다면 어떻게 해야 할까??
- 후속자 노드를 삭제된 노드가 있던 자리에 넣은 후, 후속자 노드의 오른쪽 자식을 후속자 노드의 원래 부모의 왼쪽 자식으로 넣는다.
61의 왼쪽 자식노드가 52, 52의 오른쪽 자식 노드가 55다. 52가 조상 노드의 후속자 노드라면,
52가 조상 노드와 교체 되고, 55는 61의 왼쪽 자식 노드가 된다.
완전한 삭제 알고리즘
- 삭제 할 노드가 없으면 그냥 삭제한다.
- 삭제할 노드에 자식이 하나면 노들르 삭제하고 자식을 삭제된 노드의 위치에 넣는다.
- 자식이 둘인 노드를 삭제할 때는 삭제된 노드를 후속자 노드로 대체한다. 후속자 노드란 삭제된 노드보다 크며, 최솟값을 갖는 자식 노드이다.
- 후속자 노드를 찾으려면 삭제된 값의 오른쪽 자식을 방문해서 그 자식의 왼쪽 자식을 따라 계속해서 방문하며 내려간다. 이 때 바닥 노드가 후속자 노드다.
- 만약 후속자 노드에 오른쪽 자식이 있으면 후속자 노드를 삭제된 노드가 있던 자리에 넣은 후, 오른쪽 자식을 후속자 노드의 원래 부모의 왼쪽 자식으로 넣는다.
코드 구현: 이진 탐색 트리 삭제
public static<T> TreeNode delete(T value, TreeNode node){ // 기저 조건: 노드가 바닥에 도달. 부모 노드에 자식이 없을 때. if(node == null) { return null; } // 삭제 하려는 값이 현재 노드보다 작거나 크면 현재 노드의 왼쪽 혹은 오른쪽 하위 트리에 대한 재귀 호출의 반환값을 // 각각 왼쪽 홋은 오른쪽 자식에 할당한다. else if ((Integer)value <(Integer)node.value){ node.leftChild = delete(value, node.leftChild); //현재 노드를 반환해서 현재 노드의 부모의 왼쪽 혹은 오른쪽 자식의 새로운 값으로 쓰이게 한다. return node; } else if ((Integer)value > (Integer)node.value){ node.rightChild = delete(value, node.rightChild); //현재 노드를 반환해서 현재 노드의 부모의 왼쪽 혹은 오른쪽 자식의 새로운 값으로 쓰이게 한다. return node; } // 현재 노드가 삭제하려는 노드라면 else if (value == node.value){ // 현재 노드에 왼쪽 자식이 없으면 오른쪽 자식을 그 부모의 새 하위 트리로 반환함으로써 현재 노드를 삭제. if (node.leftChild == null) return node.rightChild; //현재 노드에 오른쪽 자식이 없으면 null을 반환한다. else if ( node.rightChild == null) return node.leftChild; // 현재 노드에 자식이 둘이면 현재 노드의 값을 후속자 노드의 값으로 바꾸는 lift 함수를 호출하고 현재 노드를 삭제. else { node.rightChild = lift(node.rightChild, node); return node; } } return null; } public static TreeNode lift(TreeNode node,TreeNode nodeToDelete){ // 이 함수의 현재 노드에 왼쪽 자식이 있으면 왼쪽 하위 트리로 계속해서 내려가도록 함수를 재귀적으로 호출하여 후속 노드를 찾는다. if (node.leftChild != null) { node.leftChild = lift(node.leftChild,nodeToDelete); return node; } // 현재 노드에 왼쪽 자식이 없으면, 현재 노드가 후속자 노드이므로, 현재 노드의 값을 삭제하려는 노드의 새로운 값으로 할당한다. else { nodeToDelete.value = node.value; return node.rightChild; } }
이진 탐색 트리 삭제의 효율성
검색과 사입처럼 트리 삭제도 일반적으로 O(logN)이다. 삭제에는 검색 한번의 연결이 끊긴 자식을 처리하는 단계가 추가로 필요하기 때문이다. O(N)이 걸리는 정렬된 배열 삭제와 대조적이다.
이진 탐색 트리 다뤄보기
이진 탐색 트리는 정렬된 배열보다 삽입, 삭제가 훨씬 더 효율성이 높다. 따라서 데이터를 자수 수정할 경우 이진 탐색 트리가 효율적이다.
만약 책 제목 리스트를 관리하는 애플리케이션을 생성할 경우, 알파벳 순으로 출력할 수 있으면서 리스트를 계속 수정해야 할 수 있으면, 검색 기능을 지원하는 애플리케이션은 이진 탐색 트리가 효율적이다.
이진 탐색 트리 순회
이진 탐색 트리로 만들어진 책 제목 리스트를 알파벳 순으로 출력하고 싶다. 어떻게 해야 할까??
- 트리의 모든 노드를 순회할 수 있어야 한다.
- 트리를 알파벳 오름차순으로 순회할 수 있어야 한다. 이 때 중위 순회 방법을 수행한다.
재귀는 중위 순회를 수행하는 훌륭한 도구이다. traverse라는 재귀 함수는 다음과 같은 단계를 수행한다.
1. 노드의 왼쪽 자식에 함수를 재귀적으로 호출한다. 왼쪽 자식이 없는 노드에 닿을 때까지 다음과 같은 단계를 반복한다.
2. 노드를 방문한다.
3. 노드의 오른쪽 자식에 함수를 재귀적으로 호출한다. 오른쪽 자식이 없는 노드에 닿을 때까지 함수를 계속 호출한다.코드 구현: 중위 순회
public static TreeNode traverseAndPrint(TreeNode node){ if (node == null) return null; traverseAndPrint(node.leftChild); System.out.println(node.value); traverseAndPrint(node.rightChild); return null; }트리의 노드 N개를 모두 방문하므로 트리 순회는 O(N)이 걸린다.
결론
이진 탐색 트리는 노드 기반 자료구조다. 또한 빠른 검색, 삽입, 삭제를 제공한다.
