자료구조와 알고리즘
1.배열: 기초 자료 구조
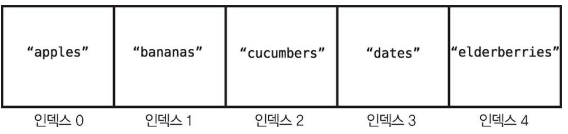
배열은 컴퓨터 과학에서 기초적인 자료구조 중 하나이다.배열은 단순히 데이터 원소들의 리스트다.배열의 크기는 배열의 데이터 원소가 얼마나 들어 있는지 알려준다.위 사진은 크기가 5인 문자열 배열이다.자료구조의 성능을 알려면 코드가 자료 구조와 일반적으로 어떻게 상호작용하
2.알고리즘이 필요한 이유
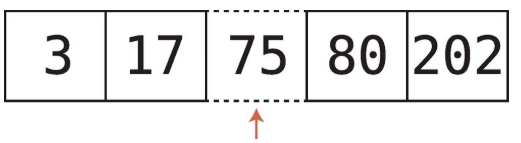
정렬된 배열은 "전형적인" 배열과 거의 같다. 유일한 차이는 값을 추가 할 때마다 배열의 값을 정렬된 상태로 유지한다.정렬된 배열은 값을 삽입하기 전에 먼저 검색을 수행해야한다. 그래야 데이터를 삽입해야 하는 위치를 정할 수 있다. 이게 전형적인 배열과 정렬된 배열의
3.빅 오 표기법
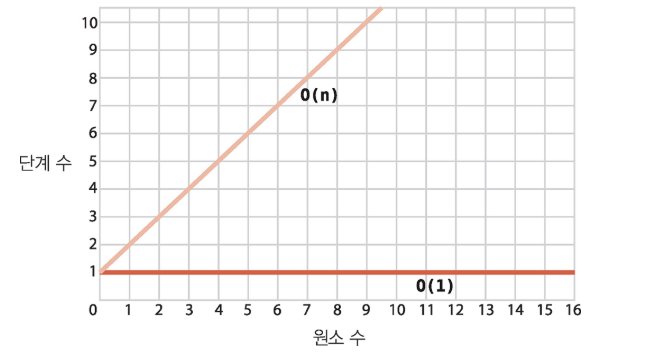
선형 검색의 최악의 경우 배열의 크기인 N 만큼 단계가 필요하다. 이를 빅 오로 표현하게 되면, O(N)이라고 표현 할 수 있다.빅 오 N = 차수 N = 오 N라고 발음 할 수 있다.선형 검색은 O(N)이라고 표현 한다. 그렇기에 O(N)인 알고리즘을 선형 시간을 갖
4.빅 오로 코드 속도 올리기

빅 오를 사용하여 내가 만든 알고리즘 세상에 존재하는 범용 알고리즘을 비교하여 코드 속도를 늘릴 수 있다.단순 정렬이라고 알려진 알고리즘의 분류 중 하나이다.버블 정렬은 주어진 배열의 값을 차례대로 비교하며 교환한다.그림과 같은 배열이 있다면 버블 정렬을 어떻게 동작할
5.빅 오를 사용하지 않는 코드 최적화
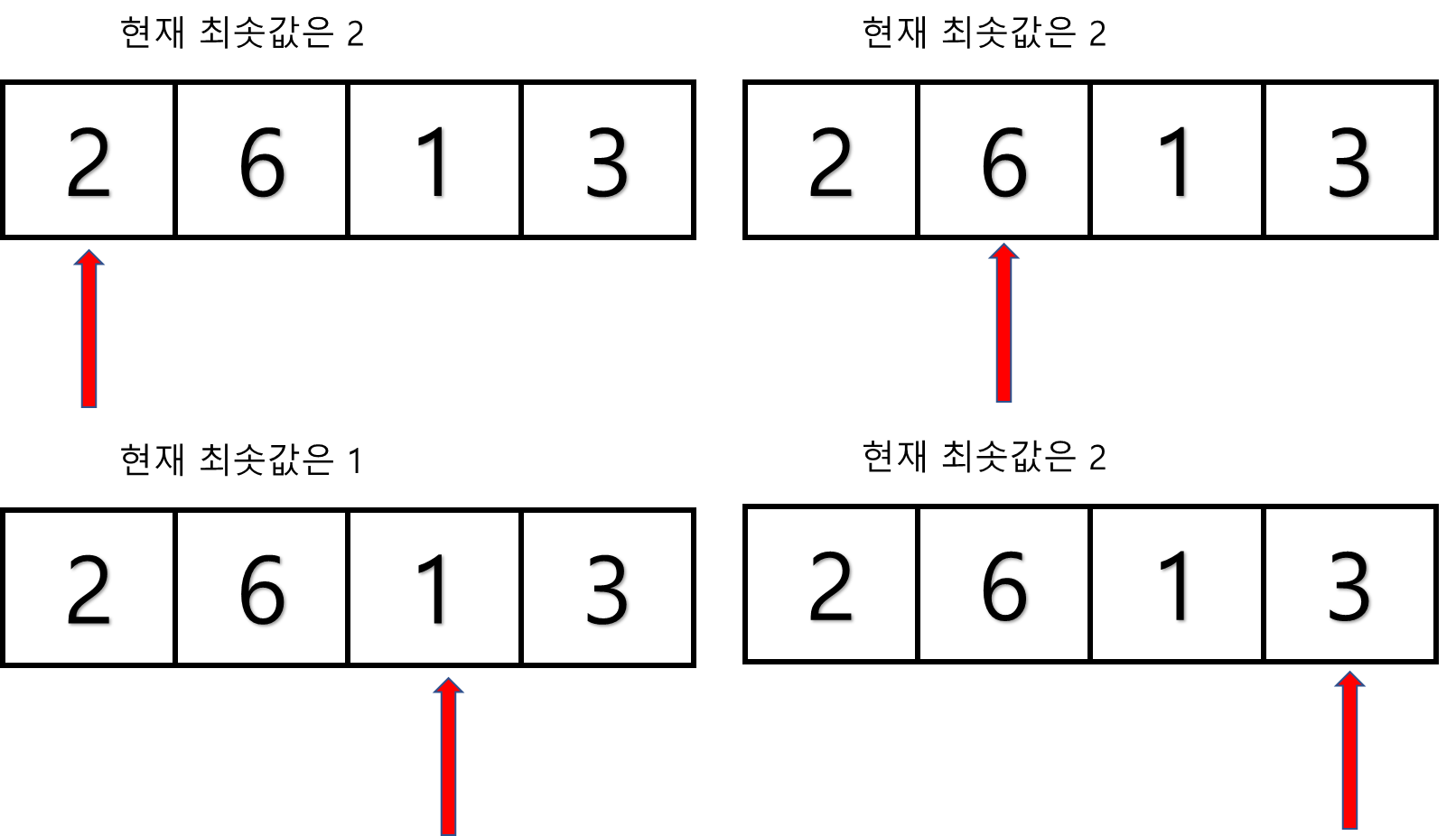
빅 오를 사용 했을 경우 선택 정렬과 버블 정렬 모두 O(n^2)이다. 하지만 이를 실직적으로 선택 정렬의 경우 n^2/2의 단계를 필요로 한다. 빅 오로 효율성이 같아 보이는 알고리즘을 구별해 내서 더 빠른 알고리즘을 고르는 법을 알아보자.선택 정렬(選擇整列, sel
6.긍정적인 시나리오 최적화
최악의 시나리오만을 확인 할 뿐만이 아니라 다른 시나리오도 고려해야 하는 이유를 설명하도록 하곘다.삽입 정렬은 자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 삽입함으로써 정렬을 완성하는 알고리즘이다.첫 번째 패스스루
7.일상 적인 코드 속 빅 오

여러 코드를 보고 빅 오를 판단 해보자.이 코드는 배열의 크기를 N으로 입력 받는다. 또한 반복문은 N번 만큼 동작한다. 반복문 내에서 짝 수 인지 확인하고, 짝수라면 sum에 더하고 짝수의 수를 카운트한다. 즉 반복문 밖에서 일어나는 3번의 단계와 반복문 내에서 일어
8.해시 테이블로 매우 빠른 룩업

배열이 정렬되어 있지 않다면 선형 검색, 정렬 되어 있다면 이진 검색을 수행 할 수있다. 하지만 이보다 더욱 빠르게 배열을 검색 할 수 있다. 바로 해시테이블을 사용하는 방법이다. 해시 테이블의 효율성은 O(1)이다.해시 테이블은 키,값 쌍으로 이루어진 리스트이다. 첫
9.스택과 큐로 간결한 코드 생성
스택과 큐는 배열과 배열과 큰 차이가 없다. 다만 제약을 갖는 배열일 뿐이다. 좀 더 구체적으로 설명하면 임시 데이터를 처리 할 수 있는 간결한 도구다. 운영 체제 아키텍쳐부터 출력 집과 데이터 순회에 이르기까지 스택과 큐를 임시 컨테이너로 사용해 뛰어난 알고리즘을 만
10.재귀를 사용한 재귀적 반복.
재귀는 함수가 자기 자신을 호출 할 때를 뜻하는 용어이다. 무한 재귀는 전혀 쓸모가 없지만, 올바르게 재귀를 사용한다면 강력한 도구가 될 수 있다.for문을 사용해서 카운트 다운하는 프로그램이 있다고 하자.위와 같은 프로그래밍을 재귀 함수를 사용하면 어떻게 구현 할 수
11.재귀적으로 작성하는 법
알고리즘 문제는 카테고리가 존재한다. 어떤 카테고리에 효과적인 기법을 터득하면 같은 카테고리에 속하는 문제를 해결 할 때 같은 기법을 적용 할수 있다.이 코드의 출력은 매번 다를 수 있으나, 코드의 본질은 숫자 출력 작업을 반복적으로 실행하는 것이다. 반복 실행 카테고
12.동적 프로그래밍
재귀로 많은 문제를 해결 할 수 있지만, 제대로 사용하지 않으면 O(2^N)같이 느린 효율성을 가진 프로그램이 만들어지는 문제가 있다. 이러한 문제를 해결하는 방법에 대해서 알아보자.다음과 같은 코드가 있다. 이 코드는 불필요한 재귀 일어나는 코드이다. 일반적으로 배열
13.속도를 높이는 재귀 알고리즘

재귀 알고리즘을 이용해서 속도를 높이는 알고리즘이 있다. 대표적인 예로 퀵 정렬을 말 할수 있다. 하지만 퀵정려를 알기전에 우선 분할에 대해서 이해하고 있어야 한다. 분할 >배열을 분할한다는 것은 배열로부터 임의의 수를 가져와(이후 수를 피벗이라 부름) 피벗보다 작은
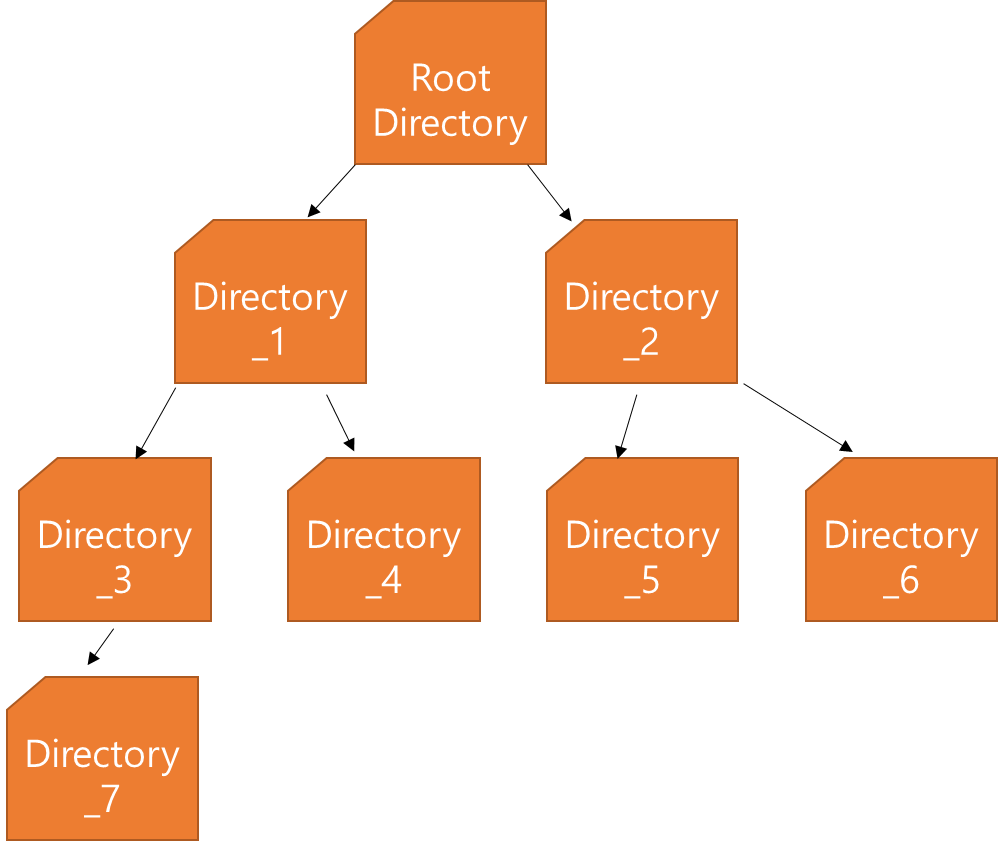
14.노드 기반 자료 구조
노드란 컴퓨터 메모리 곳곳에 흩어져 있는 데이터 조각이다. 노드 기반 자료 구조는 데이터를 조직하고 접근하는 새로운 방법을 제공하는데 성능상 큰 이점이 많다. 연결 리스트 > 배열의 경우 연속으로된 빈 셀 그룹에 데이터를 저장 할수 있도록 한다. 하지만 연결 리스트는
15.이진 탐색 트리로 속도 향상
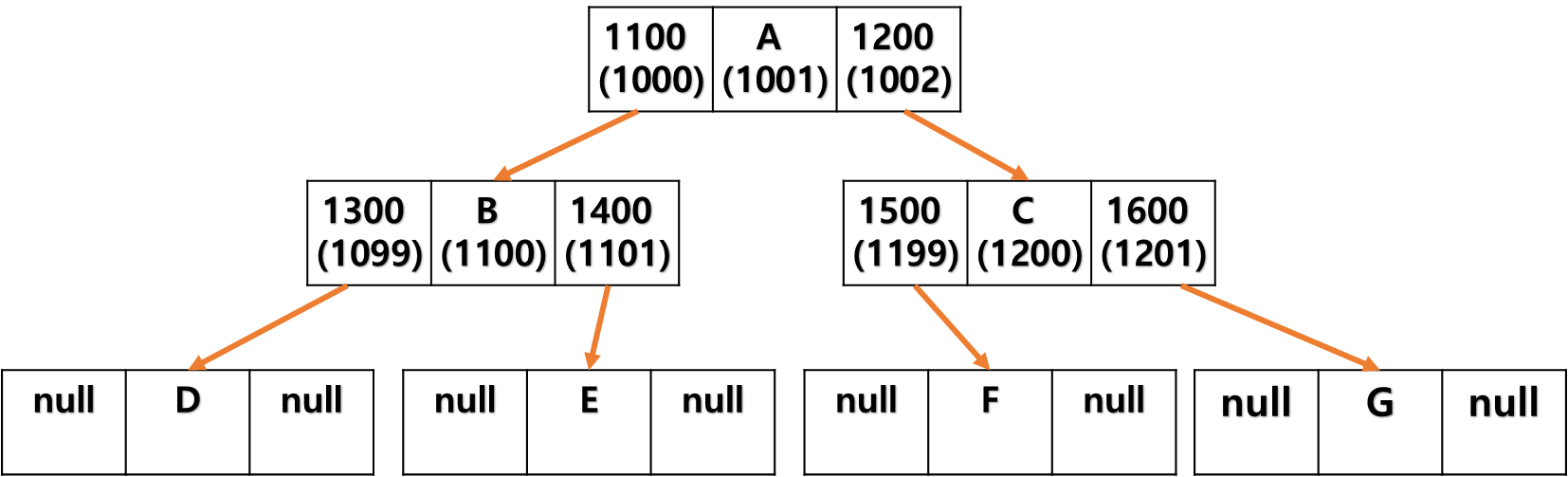
데이터를 특정 순서로 정리하려고 한다. 하지만 정렬 알고리즘은 아무리 빨라도 O(N logN)이다. 데이터를 자주 정렬해야 하면 데이터를 항상 정렬된 순서로 유지하는 편이 합리적이다.정렬된 배열은 읽기에 O(1), (이진) 검색에 O(logN)이 걸린다. 하지만 삽입과
16.힙으로 우선순위 유지하지
힙은 트리 자료 구조 중 하나로 데이터 세트에서 가장 큰 또는 가장 작은 데이터 원소를 계속 알아내야 할 때 특히 유용하다.힙의 기능을 제대로 파악하려면 우선순위 큐에 대해서 알고 있어야 한다.우선순위 큐는 삭제와 접근에 있어 전형적인 큐와 흡사하나 삽입에 있어 정렬된
17.트라이 해보는 것도 나쁘지 않다.
자동완성을 생각해보자. 자동완성이 될 단어는 사전에 저장되어있다. 그렇다면 내가 원하는 단어를 핸드폰에서 나한테 알려주기 위해 사전에 등록된 모든 단어를 확인해야 할 것이다.이러한 동작은 O(N) 시간 복잡도를 가진다. 그리고 배열에 단어가 알파벳 순으로 정렬되어 있다