데이터베이스 시스템
- 정보: 데이터를 처리해서 사람이 이해하기에 정확한 형태로 의미 있게 만듦
- 데이터: 컴퓨터 disk와 같은 매체에 저장된 사실
데이터베이스
조직체의 응용 시스템들이 공유해서 사용하는 운영 데이터 (operational data)들이 구조적으로 통합된 모임
ex) 대학에서 데이터베이스에 학생들에 관하여 신상 정보, 수강 과목, 성적 등을 기록하고, 각 학과에 개설되어 있는 과목들에 관한 정보를 유지하고, 교수에 관하여 신상 정보, 담당 과목, 급여 정보를 유지한다.
ex) 항공기 예약 시스템에서는 여행사를 통해 항공기 좌석을 예약하면 모든 예약 정보가 데이터베이스에 기록된다.
-
데이터베이스 특징
- 데이터의 대규모 저장소로서, 여러 부서에 속하는 여러 사용자에 의해 동시에 사용됨
- 모든 데이터가 중복을 최소화하면서 통합됨
- 한 조직체의 운영 데이터 뿐만 아니라 그 데이터에 관한 설명 (데이터베이스 스키마 or 메타데이터)까지 포함.
- 프로그램과 데이터 간의 독립성 제공
- 효율적 접근 가능, 질의 가능 -
데이터베이스 스키마 [ 내포(intension) ] : 전체적인 데이터베이스 구조. 자주 변경X. 데이터베이스의 모든 가능한 상태 미리 정의
DEPARTMENT (DEPTNO, DEPTNAME, FLOOR)
EMPLOYEE (EMPNO, EMPNAME, TITLE, DNO, SALARY)-
데이터베이스 상태 [ 외연(extension) ]: 특정 시점의 데이터베이스 내용. 시간이 지남에 따라 계속 변화. => 데이터베이스 내용
DEPTNO DEPTNAME FLOOR 1 영업 8 2 기획 10 3 개발 9
데이터베이스 관리 시스템 (DBMS: Database Management System)
사용자가 새로운 데이터베이스를 생성하고, 데이터베이스의 구조를 명시할 수 있게 하고, 사용자가 데이터를 효율적으로 질의하고 수정할 수 있도록 한다.
시스템의 고장이나 권한이 없는 사용자로부터 데이터를 안전하게 보호하며, 동시에 여러 사용자가 데이터베이스를 접근하는 것을 제어하는 소프트웨어 패키지
데이터베이스 언어 한 개 이상 제공: SQL은 여러 DBMS에서 제공되는 사실상의 표준 데이터베이스 언어
- 시스템 요구사항
- 데이터 독립성: 응용 프로그램이 data의 상세한 내역과 data 저장으로부터 독립적
- 효율적인 데이터 접근: 방대한 data도 접근 용이. index 사용
- 데이터 동시 접근: 여러 사용자가 동시에 접근해도 각 사용자가 혼자 접근하는 것처럼 느끼도록 동시성 제어 필요
- 백업 & 회복: 데이터 손상 대비하여 백업 제공 필요
- 중복 ⬇ , 제어하며 일관성 유지: 데이터를 통합하여 여러 개의 데이터가 사본으로 존재하는 것 avoid
- 데이터 무결성: 데이터가 정확, 완전. 제약조건 지켜야 함.
- 데이터 보안: 권한 없는 접근으로부터 데이터베이스 보호
- 쉬운 질의어: 쉬운 구문으로 질의. 결과 바로 얻기.
- 다양한 사용자 인터페이스: sql -> query interface, 응용프로그램 개발 -> 프로그래밍 인터페이스, 초보 사용자 -> 메뉴 기반의 조회 인터페이스
파일 시스템 VS DBMS
파일 시스템을 사용한 데이터베이스 관리
- 파일의 기본 구성 요소: 순차적 레코드들 (레코드: 연관된 필드들의 모임)
파일 접근 방식이 응용 프로그램 내에 상세하게 표현 -> 데이터에 대한 응용 프로그램 의존도 ⬆
각각의 데이터를 각각의 파일에 대응
- 여러 응용프로그램이 각각의 employee 파일을 갖고 있다면 -> employee 파일 중복 & 불일치
⇒ 두 개의 응용프로그램이 하나의 employee 파일 사용- cell-phone 데이터 하나 추가 시, 레코드를 하나씩 읽어 cell-phone 필드를 추가한 레코드를 새로운 employee 파일에 기록하는 프로그램 작성 -> 기존 employee 파일을 사용하던 모든 응용 프로그램 찾아서 cell-phone 필드 추가
⇒ 데이터 종속성 ⬆ (파일 저장방식이나 접근 방법 변경 시, 연관된 모든 응용프로그램도 함께 수정되어야 함)
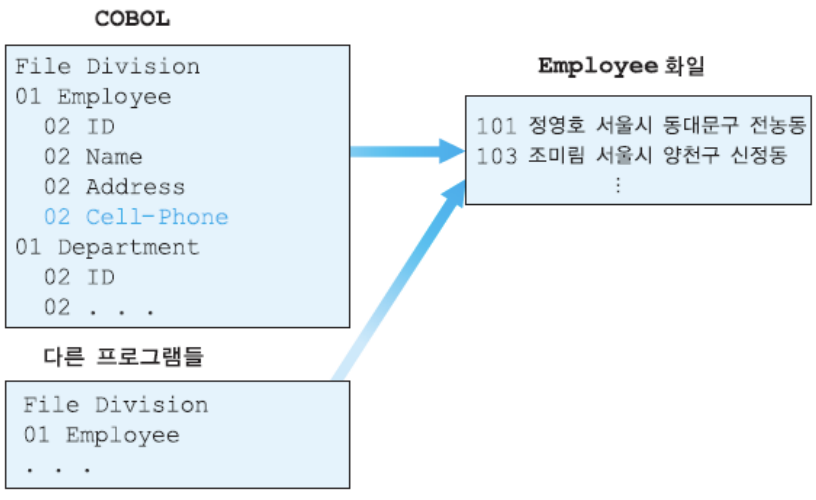
- 파일 시스템 단점
- 데이터가 많은 파일에 중복해서 저장됨
ex) 인사 관리용 employee 파일과 교육 관리용 enrollment 파일에DEPARTMENT레코드가 중복됨
: 한 쪽의 department만 변경 시, 데이터 불일치 발생 (중복 데이터 변경 제어 hard -> 중복된 데이터 간의 불일치)
⇒ 중복 제어 필요 (공간 낭비 방지)
- 다수 사용자들을 위한 동시성 제어 제공 X : 각각의 데이터에 다른 사람이 동시에 접근 / 수정 시, 동시성 제어 X
⇒ 데이터 불일치 발생
- 검색하려는 데이터를 쉽게 명시하는 질의어 제공 X
- 보안 조치 미흡: 파일 단위로마나 검색 / 갱신 / 시행 권한 부여 가능. 특정 레코드에 접근 제어 불가. 파일에 대한 사용자 구체적 명시 불가
- 회복 기능 X: 파일 작성 도중 시스템 다운 시, 데이터 일괄성 복구 어려움
- 프로그램 - 데이터 독립성 X 유지보수 비용 소요 ⬆ : 프로그램에 영향 주지 않으면서 데이터베이스 구조 변경 불가, 응용프로그램 수정 불가
⇒ 유지보수 비용 ⬆
- 파일을 검색하거나 갱신하는 절차가 상대적으로 복잡 => 프로그래머 생산성 ⬇
- 데이터 공유, 융통성 부족: 여러 프로그래밍 언어로 작성. 데이터 공유 제한
DBMS를 사용한 데이터베이스 관리
-
DBMS 특징
- 여러 사용자와 응용 프로그램들이 데이터베이스 공유
- 사용자의 질의를 빠르게 수행할 수 있는 인덱스 등의 접근 경로를 DBMS가 자동적으로 선택하여 수행
- 권한이 없는 사용자로부터 데이터베이스 보호
- 여러 사용자에 적합한 다양한 인터페이스 제공
- 데이터 간의 복잡한 관계 표현, 무결성 제약조건을 DBMS가 자동적으로 유지
- 프로그램에 영향을 주지 않으면서 데이터베이스 구조 변경 가능
⇒ 프로그램 - 데이터 독립성 -
DBMS 장점
- 중복성, 불일치 ⬇ : 모든 데이터를 하나의 데이터베이스에 통합
- 시스템 개발 유지 비용 ⬇ : 데이터베이스 구축 초기 비용은 ⬆, BUT 유지 비용 ⬇
- 표준화 시행 용이: 통합관리, 데이터 이름, 형식 등 표준화 용이
- 무결성 향상
- 다양한 유형의 고장으로부터 데이터베이스 회복 가능: 고장 이전의 일관된 데이터베이스 회복 가능
- 데이터베이스 공유 & 동시 접근 가능파일시스템 DBMS 데이터에 대한 물리적 접근만 조정 물리적 접근, 논리적 접근 조정 다수 사용자 동시 접근 X (동시성 제어 불가)
동시 접근 가능 데이터: 비구조적. 중복성 & 유지보수비용⬆ (데이터 종속성)
데이터: 구조적. 중복성 & 유지보수비용⬇ (데이터 독립성)
어떤 프로그램이 기록한 데이터는다른프로그램에서 읽을 수 X 접근 권한이 있는 모든 프로그램이 데이터 공유 미리 작성된 프로그램을 통해서만 데이터 접근 가능 질의어 사용하여 데이터에 대한 융통성 있는 접근 가능 각 응용 프로그램마다 파일 따로 데이터 통합 X
데이터 중복 배제, 통합 -
DBMS 선정 시 고려 사항
- 기술적 요인: DBMS에 사용되고 있는 데이터 모델, DBMS가 지원하는 사용자 인터페이스, 응용 개발 도구, 저장 구조, 성능, 접근 방법 등
- 경제적 요인: 소프트웨어/하드웨어 구입 비용, 유지보수 비용, 직원 교육 지원 -
DBMS 단점
- 추가적 하드웨어 구입 비용이 들고, DBMS 자체 구입 비용 expensive
- 직원들 교육 비용 소요 ⬆
- 비밀, 프라이버시 노출: 다수의 사용자가 데이터베이스 접근 가능. 노출 가능성 ⬆초기의 투자 비용이 너무 클 때
오버헤드가 너무 클 때
응용 단순 & 잘 정의, 변경되지 않을 것으로 예상될 때
엄격한 실시간 처리 요구사항이 있을 때
데이터에 대한 다수 사용자의 접근 필요하지 않을 때
⇒ DBMS를 사용하지 않는 것이 바람직
DBMS 발전 과정
-
데이터 모델 (프레임워크)
데이터베이스 구조를 기술하는데 사용되는 개념들의 집합인 구조(데이터 타입과 관계), 구조 위에서 동작하는 연산자들, 무결성 제약조건
사용자들에게 내부 저장 방식의 세세한 방식은 숨기면서 데이터에 대한 직관적인 뷰를 제공하는 동시에 데이터들 간의 사상 제공
- 고수준 또는 개념적 데이터 모델 (conceptual data model)
: 사람이 인식하는 것과 유사하게 데이터베이스의 전체적인 논리적 구조 명시.
시스템 인식과는 거리가 멂. 현실세계의 개념적 표현. 사용자가 이해할 수 있는 모델.
ex) 엔티티-관계 데이터 모델, 객체지향 데이터 모델 - 표현(구현) 데이터 모델 (representation/implementation data model)
: 최종 사용자가 이해하는 개념. 컴퓨터 내에서 데이터가 조직되는 방식과 멀리 떨어져 있지는 X
ex) 계층 데이터 모델, 네트워크 데이터 모델, 관계 데이터 모델 - 저수준 또는 물리적 데이터 모델 (physical data model)
: 데이터베이스에 데이터가 어떻게 저장되는지를 기술
시스템이 인식하는 것과 가까운 모델
ex) ISAM(색인순차접근방식): 자료를 파일로 저장할 때 순서대로 저장 / 색인을 두어 순서에 관계 없이 처리, VSAM(가상기억접근방식): 가상기억 환경에서 접근 / 순차 접근. 기억장치에 있는 데이터 read or record
- 고수준 또는 개념적 데이터 모델 (conceptual data model)
계층 DBMS
트리 구조를 기반으로 하는 계층 데이터 모델을 사용한 DBMS
IBM사의 IMS: 1960s 후반에 등장한 최초의 계층 DBMS
트리 구조: 위->아래. 각 엔티티는 하나의 부모만 가짐. 한 부모는 여러 자식을 가질 수 있음.
계층 데이터 모델: 네트워크 데이터 모델의 특별한 사례 (link 사용 유사 / tree 형태 차이)
- 장점
- 어떤 유형의 응용에 대해서는 빠른 속도와 높은 효율성 제공 - 단점
- 어떻게 데이터에 접근하는가를 미리 응용 프로그램에 정의해야 함
- 데이터베이스가 생성될 때 각각의 관계를 명시적으로 정의해야 함
- 레코드들이 link로 연결. 레코드 구조 변경 어려움
네트워크 DBMS
그래프를 기반으로 하는 네트워크 데이터 모델 사용
IDS: 1060s 초에 Charles Bachman이 하니웰 사에서 개발한 최초의 네트워크 DBMS
그래프: 레코드 => 노드, 레코드들 사이의 관계 => 간선
- 단점
- 레코드들이 link로 연결. 레코드 구조 변경 어려움
- 응용프로그램 수정 어려움 -> 데이터 독립성 매우 제한적
- 파일 검색 / 갱신 절차 상대적 복잡: 절차적으로 한 번의 한 개의 데이터만 검색 가능
- 검색하려는 데이터를 쉽게 명시하는 질의어 제공 X
=> 새로운 우수한 데이터 모델들의 개발로 더이상 사용 X
관계 DBMS
실세계 객체를 테이블 형태의 릴레이션, 애트리뷰트, 무결성 제약 조건을 표현하는 관계 데이터 모델 사용
1970s에 E.F.Codd가 IBM 연구소에서 관계 데이터 모델 제안
System R: 미국 IBM 연구소에서 진행. db2로 상용화. 프로젝트 진행 과정에서 SQL 고안 (관계 데이터 모델 기반. 사실상 dbms 표준 언어)
Ingres: 캘리포니아 버클리대에서 진행. 상용 ingres. postgres로 발전. ibm 최종 합병
- 장점
- 모델이 간단하여 이해하기 쉬움
- 사용자는 자신이 원하는 것(what)만 명시. 데이터 위치, 접근 방식은 DBMS가 결정
=> 과거 모델들에 비해 기술 크게 확장. 성능 향상.
ex) 오라클, MS SQL Server, Sybase, DB2, Informix
객체지향 DBMS
객체 단위로 저장한 연관 데이터들 사이 관계를 객체 식별자로 표현하는 객체지향 데이터 모델 사용
1980s 후반 객체지향 프로그래밍 패러다임 기반 객체지향 데이터 모델 등장
객체지향: 클래스, 상속, 추상화, 캡슐화 + 데이터베이스 개념 통합하여 저장 구조에 도입
구조적 측면: 계층형, 네트워크 모델과 유사.
- 장점
- 데이터와 프로그램 그룹화, 복잡한 객체 이해 용이, 유지/변경 용이
ex) ONTOS, OpenODB, GemStone, ObjectStore, Versant, O2
객체관계 DBMS
관계 DBMS에 객체 지향 개념을 통합한 객체관계 데이터 모델 사용
1990s 후반
새로운 데이터 타입과 데이터베이스 연산 추가 가능
- 장점
- 관계, 객체지향 DBMS 단점 해결 - 단점
- DBMS 복잡도 증가
ex) 오라클, Informix, Universal Server
DBMS 언어
데이터 정의어 (DDL: Data Definition Language)
: 데이터 정의어를 사용하여 데이터베이스 스키마 정의
데이터 정의어로 명시된 문장 입력 시, DBMS는 사용자가 정의한 스키마에 대한 명세를 시스템 카탈로그 또는 데이터 사전에 저장
CREATE TABLE데이터 모델에서 지원하는 데이터 구조 생성
ALTER TABLE데이터 구조의 변경
DROP TABLE데이터 구조의 삭제
CREATE INDEX데이터 접근을 위해 특정 애트리뷰트 위에 인덱스 정의
데이터 조작어 (DML: Data Manipulation Language)
: 데이터 조작어를 사용하여 데이터베이스 내의 원하는 데이터를 검색, 수정, 삽입, 삭제
- 절차적 언어: 어떤 데이터가 필요하고, 어떻게 데이터를 찾을 것인지 명시
- 비절차적 언어: 어떤 데이터를 원하는지만 명시
ex) SQL
오라클 : 비절차적언어(SQL) + 절차적요소 => PL/SQL (조건문, 반복문 사용하여 필요한 데이터, 데이터 접근 방법 명시)
단말기에서 대화식으로 입력되어 수행 or C, COBOL 등 고급 프로그래밍 언어로 작성된 프로그램에 내포되어 사용
SELECTUPDATEDELETEINSERT
내장함수:SUMCOUNTAVG
데이터 제어어 (DCL: Data Control Language)
: 데이터 제어어를 사용하여 데이터베이스 트랜잭션을 명시하고 권한 부여 / 취소
데이터 보안, 무결성 회복, 병행 수행 제어 => 관리자가 주로 사용
GRANT SELECT, INSERT ON EMPLOYEE TO LEE;
REVOKE INSERT ON EMPLOYEE FROM LEE;
DBMS 사용자
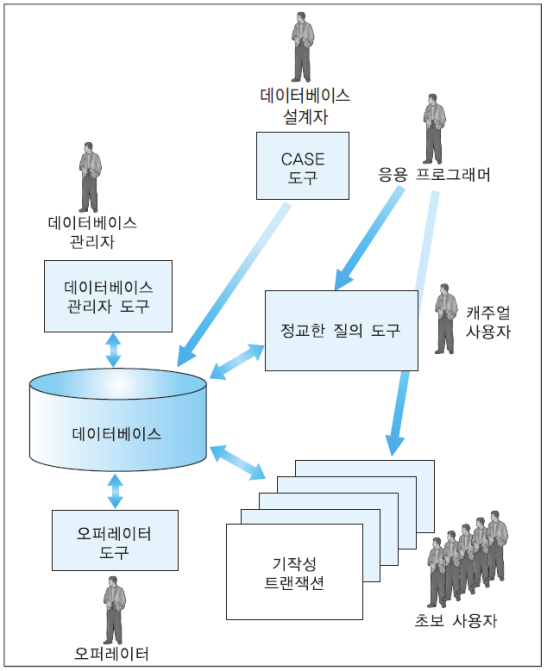
데이터베이스 관리자 (DBA: Database Administrator)
: 조직의 여러 부분의 상이한 요구를 만족시키기 위해 일관성 있는 데이터베이스 스키마를 생성하고 유지하는 사람(팀)
- 데이터베이스 관리자의 역할
- 데이터베이스 스키마의 생성 / 변경
- 무결성 제약조건 명시
- 사용자 권한 허용 / 취소, 사용자 역할 관리
- 저장구조와 접근 방법(물리적 스키마) 정의: 데이터가 어떻게 저장되고, 어떤 인덱스를 유지할 것인가 결정. DBMS 성능 모니터링. 미흡 시, 저장 구조 변경
- 백업과 회복
- 표준화 시행: 데이터 개념, 구조 표준화
응용 프로그래머
: 데이터베이스 위에서 특정 응용(ex. 고객 관리, 인사 관리, 재고 관리 등)이나 인터페이스를 구현하는 사람
고급 프로그래밍 언어 C, Covol 등으로 개발 + 데이터베이스 접근 부분은 내포된 데이터 조작어 사용
- 기작성 트랜잭션 (canned transaction): 응용 프로그래머들이 작성한 프로그램. 최종 사용자들이 반복해서 수행.
ex) 재고관리 프로그램: 매일 아침 재고 통계 보여줄 때, 프로그래머가 이 통계에 대한 보고서 생성해서 사용자들이 조회할 수 있도록 함
최종 사용자 (end user)
: 질의 / 갱신하거나 보고서를 생성하기 위해 데이터베이스를 사용하는 사람
- 캐주얼 사용자: 데이터베이스 질의어를 사용하여 매번 다른 정보를 찾음 (데이터베이스 지식 O)
- 초보 사용자: 기작성 트랜잭션을 주로 반복 수행
데이터베이스 설계자 (database designer)
: ERWin 등의 CASE 도구를 이용하여 데이터베이스 설계를 담당하는 사람
데이터베이스 일관성 유지 위해 정규화 수행
- 정규화: 데이터베이스 설계 시, 보다 좋은 설계를 위해 중복/갱신이상/삭제이상 등의 문제 발생하지 않도록 관계 데이터베이스 스키마를 기반으로 relation에 수학적 이론 적용
오퍼레이터
: DBMS가 운영되고 있는 컴퓨터 시스템과 전산실을 관리하는 사람
ANSI/SPARC 아키텍처와 데이터 독립성
ANSI/SPARC Architecture
현재의 대부분의 상용 DBMS 구현에서 사용되는 일반적 아키텍처 (1978)
-
외부 단계(external level): 각 사용자의 뷰
- 여러 부류의 사용자를 위해 동일한 개념 단계로부터 다수의 서로 다른 뷰 제공 가능
- 최종 사용자와 응용 프로그래머들은 데이터베이스의 일부분에만 관심 가짐
ex) 대학교 데이터베이스
교수: 강의정보스키마, 학생: 수강정보스키마, 직원: 예산정보스키마, 사서: 도서정보스키마 -
개념 단계(conceptual level): 사용자 공동체의 뷰
- 조직체의 정보 모델. 물리적 구현 고려 X, 조직체 전체에 관한 스키마
- 저장된 데이터, 데이터 간의 관계, 무결성 제약조건 명시 기술
- 데이터베이스마다 한 개의 개념 스키마만 존재 -
내부 단계(internal level): 물리적 또는 저장 뷰
- 실제 물리적 데이터 구조에 관한 스키마
- 저장된 데이터, 저장 방식 기술
- 인덱스, 해싱 등과 같은 접근 경로, 데이트 압축 등 기술
- 개념 스키마에는 영향을 미치지 않으면서 성능을 향상시키기 위해 내부 스키마를 변경하는 것이 바람직
- 내부 단계 >> (아래) 물리적 단계 : 실제 장치의 물리적 저장 방식이나 구조 명시. DBMS 지시에 따라 운영체제가 관리.
- 효율성을 가장 중요하게 고려스키마 간의 사상
- 외부 / 개념 사상 (external/conceptual mapping)
: 외부 단계의 뷰를 사용해서 입력된 사용자의 질의를 개념 단계의 스키마를 사용한 질의로 변환
- 개념 / 내부 사상 (conceptual/internal mapping)
: 위 단계에서의 질의를 다시 내부 단계의 스키마로 변환하여 디스크의 데이터베이스 접근
데이터 독립성
- 논리적 데이터 독립성
: 개념 스키마의 변화로부터 외부 스키마가 영향 받지 X.
응용 프로그램 재작성 없이 개념 스키마 변화 가능 - 물리적 데이터 독립성
: 내부 스키마의 변화가 개념적 스키마에 영향 미치지 X, 외부 스키마 / 응용 프로그램에 영향 미치지 X
성능 향상을 위해 파일 저장 구조 변경, 인덱스 생성/삭제 시, 응용 프로그램들이 신경 쓸 필요 없게 처리
데이터베이스 시스템 아키텍처
- 데이터 정의어 컴파일러 (DDL Compiler) 모듈
: 데이터 정의어 사용하여 테이블 생성 요청 -> 데이터베이스에 파일 형태로 테이블 만듦 -> 테이블에 대한 명세를 시스템 카탈로그에 저장- 질의 처리기 (Query Processor) 모듈
: 데이터 조작어 수행하는 최적의 방법 찾음. 기계어 코드로 번역- 런타임 데이터베이스 관리기 (Run-time Database Manager) 모듈
: 디스크에 저장된 데이터베이스 접근- 트랜잭션 관리 (Transaction Management) 모듈
: 동시성 제어 (concurrency control) 모듈, 회복 (recovery) 모듈
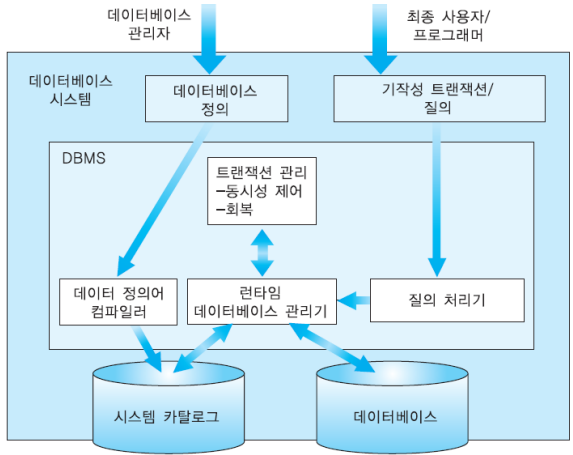
- 데이터베이스 API (Application Program Interface)
: 데이터베이스 접근을 간단하게 하기 위해 호출 가능한 라이브러리 함수 집합. 제품마다 고유한 데이터베이스 API 존재. 서로 호환 불가.
- ODBC (Open Database Connectivity): 응용 프로그램들 간에 사용. ODBC 지원 DBMS 간에는 서로 상대방의 데이터베이스 접근 가능. 사용자는 ODBC SW와 접근하려는 각 데이터베이스에 대한 별도의 드라이버가 필요하다.
- JDBC: 자바를 위한 드라이버. 자바가 운영되는 모든 프로그램에서 제공
중앙 집중식 데이터베이스 시스템 (Centralized database system)
: 데이터베이스 시스템이 하나의 컴퓨터 시스템에서 운영. 중앙컴퓨터에 저장된 데이터베이스를 여러 단말에서 접근 가능
분산 데이터베이스 시스템 (Distributed database system)
: 네트워크로 연결된 여러 사이트에 데이터베이스 자체가 분산되어 있으며, 데이터베이스 시스템도 여러 컴퓨터 시스템에서 운영. 사용자는 다른 사이트에 저장된 데이터베이스도 접근 가능
사용자에게는 데이터베이스가 분산되지 않은 것처럼 느끼게 하지만 각 컴퓨터마다 분산 DBMS 운영.
=> 사용자: local 데이터베이스, 원격 데이터베이스 모두 접근 가능
클라이언트 - 서버 데이터베이스 시스템 (Client - Server database system)
: PC 또는 워크스테이션처럼 자체 컴퓨팅 능력을 가진 클라이언트를 통해 데이터베이스 서버 접근. 데이터베이스가 하나의 데이터베이스 서버에 저장. 데이터베이스 시스템의 기능이 서버와 클라이언트에 분산.
- 클라이언트: 사용자 인터페이스 관리. 응용 수행
- 서버: 데이터베이스 저장. DBMS 운영. 여러 클라이언트에서 온 질의 최적화. 권한 검사. 동시성 제어. 회복. 데이터베이스 무결성 유지. 데이터베이스 접근 관리.
(+) : 데이터베이스를 보다 넓은 지역에서 접근 가능. 다양한 컴퓨터 시스템 사용 가능.
(-) : 보안 다소 취약
