관계 데이터 모델
데이터 모델을 만든 목적?
=> 사용자에게 내부 저장 방식의 세세한 사항은 숨기면서 데이터에 대한 직관적인 뷰 제공
- 표현 데이터 모델: 최종 사용자가 이해하는 개념. 컴퓨터 내에서 데이터가 처리되는 방식과 멀리 떨어져 있지 않은 중간 단계의 모델.
ex) 관계 데이터 모델
관계 데이터 모델
: 실세계 객체를 테이블 형태의 릴레이션, 애트리뷰트, 무결성 제약 조건을 표현
- 장점
- 테이블(릴레이션) 단순한 구조. (중첩 복잡 구조 X) 사용자 - 프로그래머 간의 소통, 상호작용 원활
- 집합 위주의 데이터 처리. 프로그래머가 데이터를 레코드 단위로 처리하는 어려움 없게
- 표준 데이터베이스 응용에 좋은 성능
- 데이터베이스 관리 분야에서 튼튼한 이론적 근거 제공. (집합, 논리 분야 용어 사용)
- 관계 데이터베이스 설계, 효율적 질의 처리
- 특징
- 동일한 구조(릴레이션)의 관점에서 논리적 데이터 구성
- 질의어를 통한 데이터 접근 제공
- 응용 프로그램들은 데이터베이스 내의 레코드들의 순서와 무관하게 작성
- 사용자는 원하는 데이터만 명시, 데이터 찾을 방법 명시 필요 X
- 논리적 연관(키와 연산자, 제약조건 정의) 데이터 연결 위해 link, pointer 사용 X
1970년. IBM 연구소.
관계 DBMS: 최초 System R. 가장 널리 사용되는 DBMS
- 관계 dbms 제품
- 다수 사용자용: 오라클, ms sql server, db2(sql/ds), informix, sybase
- 개인용: msft/access
- 자바 기반: instanceDB, simple text
관계 데이터 모델 용어
- 릴레이션(relation): 2차원 테이블
- 투플(tuple): 릴레이션 행 (레코드). row
- 애트리뷰트(attribute): 릴레이션 열. column. 서로 다른 이름 가져야 함
- 도메인(domain)
- 한 애트리뷰트에 나타날 수 있는 값들의 집합
- 원자값: 논리적으로 더 분해될 수 없는 값
- 프로그래밍 언어의 데이터 타입과 유사
- 동일한 도메인이 여러 애트리뷰트에서 사용될 수 X
- 복합 애트리뷰트 X, 다치 애트리뷰트 X
CREATE DOMAIN EMPNAME CHAR(10)
CREATE DOMAIN EMPNO INTEGER
CREATE DOMAIN DNO INTEGER- 차수(degree) >= 1
- 한 릴레이션에 들어있는 애트리뷰트들의 수- 자주 바뀌지 X. 열들의 수는 자주 변하지 않고 유지됨.
- 카디날리티(cardinality) >= 0
- 릴레이션의 튜플 수
- 시간이 지남에 따라 계속 변함. 튜플 수는 변화. 쉽게 삽입, 삭제 가능 - 널값 (null value)
- 알려지지 않음 / 적용할 수 없음
ex) 사원 릴레이션에 새로운 사원에 관한 튜플 입력. 신입 사원의 DNO(부서번호)가 결정되지 않았을 수 있음
- 숫자 도메인의 0이나 문자열 도메인의 공백 문자(열)과 다름 (오라클은 널과 빈 문자열이 모두 같이 널로 처리)
- DBMS마다 널값을 나타내기 위해 서로 다른 기호 사용
릴레이션 스키마: 내포(intension)
: 릴레이션의 이름, 애트리뷰트들의 집합
릴레이션을 위한 framework
표기법: 릴레이션이름(애트리뷰트1, 애트리뷰트2, ..., 애트리뷰트N)
EMPLOYEE (EMPNO, EMPNAME, TITLE, DNO, SALARY)
EMPNO에 밑줄을 그어 기본키 표현
- 관계 데이터베이스 스키마: 하나 이상의 릴레이션 스키마들로 이루어짐
릴레이션 인스턴스: 외연(extension)
: 릴레이션의 어느 시점에 들어 있는 튜플들의 집합
시간의 흐름에 따라 계속 변함. 일반적으로 현재의 인스턴스만 저장됨
- 관계 데이터베이스 인스턴스: 릴레이션 인스턴스들의 모임으로 구성
릴레이션
튜플들의 집합
- 각 릴레이션은 오직 하나의 레코드 타입만 포함
- 한 애트리뷰트 내의 값들은 모두 같은 유형
- 애트리뷰트들의 순서는 중요하지 않음 (상용DBMS에서는 순서를 갖는 경우도 O)
- 튜플의 유일성: 동일한 튜플이 두 개 이상 존재 X. => 키가 존재
- 애트리뷰트의 원자성: 한 튜플의 각 애트리뷰트는 원자값을 가짐. (의미적으로 더 쪼개서 사용할 수 있는 값이나 여러 값들의 집합 X)
- 각 애트리뷰트의 이름은 한 릴레이션 내에서만 고유
- 튜플의 무순서성: 튜플들의 순서 중요 X
릴레이션의 키
슈퍼 키 (Super key)
한 릴레이션 내의 특정 튜플을 고유하게 식별하는 하나의 애트리뷰트 또는 애트리뷰트들의 집합
튜플들을 고유하게 식별하는데 꼭 필요하지 않은 애트리뷰트 포함 가능
ex) 카드회사 고객 릴레이션: (신용카드번호, 주소) / (주민등록번호, 이름) / (주민등록번호)
후보 키 (Candidate key)
각 튜플을 고유하게 식별하는 최소한의 애트리뷰트들의 모임
ex) (신용카드번호): 후보 키 // (신용카드번호, 주소): 후보 키 X
모든 릴레이션에는 최소한 한 개 이상의 후보 키 있음
- 복합 키 (Composite key): 두 개 이상의 애트리뷰트로 이루어진 후보 키
ex) 수강 릴레이션에서 (학번, 과목번호): 학번/과목번호 혼자서 각 튜플 식별 X => 학번, 과목번호 결합하여 후보 키
후보 키: 이메일 (이름 X: 고유하지 않음)
한 애트리뷰트 또는 애트리뷰트들의 모임이 후보 키라는 것을 입증하기 위해 릴레이션의 한 인스턴스를 사용해서는 안 됨
=> 어떤 릴레이션의 인스턴스만을 살펴보고, 동일한 값을 갖지 않는다고 해서 후보키라고 판단해서는 안 됨
실세계에서 애트리뷰트의 의미를 이해하고 중복된 값이 나타날 수 있다는 점을 고려해야함
기본 키 (Primary key)
한 릴레이션에 후보 키가 두 개 이상 존재할 경우, 설계자 또는 데이터베이스 관리자가 이들 중에서 하나를 기본 키로 선정
ex) 카드회사 고객 릴레이션에서 후보키: (신용카드번호), (주민등록번호)
=> 기본 키: 둘 중 하나 선택
자연스러운 기본 키를 찾을 수 없는 경우에는 레코드 번호와 같이 인위적인 키 애트리뷰트를 릴레이션에 추가
- 자연스러운 기본 키 고려사항
- 애트리뷰트가 항상 고유한 값을 가짐
- 널값을 갖지 않음
- 값이 변경될 가능성이 낮아야 함
- 가능하면 작은 정수값이나 짧은 문자열을 갖는 애트리뷰트로 선정
- 복합 기본 키는 피하는 것이 좋음
대체 키 (Alternate key)
기본 키가 아닌 후보 키
ex) 카드회사 고객 릴레이션에서 (신용카드번호) 기본키로 선정 시, 대체 키: (주민등록번호)
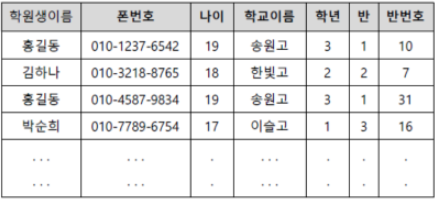
애트리뷰트: 학원생이름, 폰번호, 나이, 학교이름, 학년, 반, 반번호
- 슈퍼키
{폰번호} => 유일성(O), 최소성(O)
{학원생이름, 폰번호}, {학원생이름, 학교이름, 학년, 반, 반번호}, {학교이름, 학년, 반, 반번호, 폰번호} => 유일성(O), 최소성(X)- 후보키
{폰번호}, {학교이름, 학년, 반, 반번호} => 유일성(O), 최소성(O)
{학원생이름}, {학원생이름, 폰번호}, {학원생이름, 학교이름, 학년, 반}, {반번호, 학년, 반}- 기본키
{폰번호} => 유일성(O), 최소성(O)- 대체키
{학교이름, 학년, 반, 반번호} => 유일성(O), 최소성(O)
기본키랑 대체키는 임의로 선정.
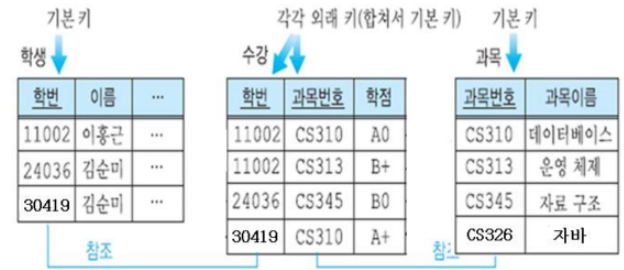
외래 키 (Foreign key)
어떤 릴레이션의 기본 키를 참조하는 애트리뷰트
릴레이션들 간의 관계를 나타내기 위해 사용
의미적 연관성이 있음에도 다른 릴레이션으로 분리된 튜플 사이의 연결고리
참조되는 릴레이션의 기본 키와 동일한 도메인을 가져야 함
자신이 속한 릴레이션의 기본 키의 구성요소가 되거나 되지 않을 수 있음
-
다른 릴레이션의 기본 키를 참조
외래키 이름: 대응되는 기본 키와 다른 이름을 가질 수 O.
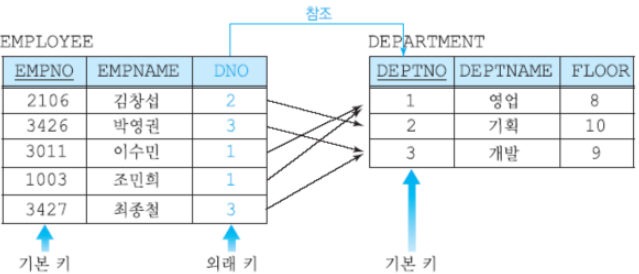
외래키DNO는 DEPARTMENT 릴레이션의 기본 키DEPTNO를 참조 -
자체 릴레이션의 기본 키를 참조
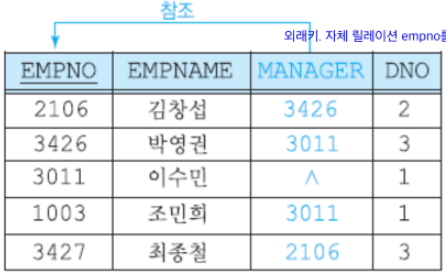
외래키MANAGER는 자체 릴레이션의EMPNO를 참조 -
기본 키의 구성요소
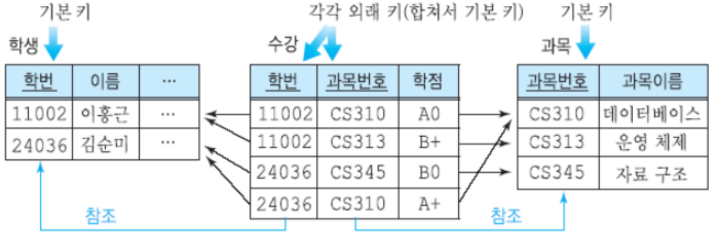
수강 릴레이션의 외래키학번은 학생 릴레이션의 기본키학번을 참조
수강 릴레이션의 외래키과목번호는 과목 릴레이션의 기본키과목번호를 참조
=> 수강 릴레이션의 기본키:학번 + 과목번호
무결성 제약조건
데이터 무결성 (Data Integrity): 데이터의 정확성 / 유효성
일관된 데이터베이스의 상태(데이터베이스 스키마, 특정 시점의 데이터베이스 내용)를 정의하는 규칙들을 묵시적 / 명시적으로 정의
데이터베이스가 갱신될 때 DBMS가 자동적으로 일관성 조건 검사. 응용 프로그램들이 검사할 필요 X
- 무결성 구현방식
- DBMS 이용X, 개별 응용 프로그램의 코드 안에 제약 조건 검사 코드 추가
=> 구현 부담, 비효율적, 향후 유지 어려움 - DBMS 안에 설정. 공통 제약사항을 DBMS 무결성 제약조건으로 명시
=> 별도 구현X, 한 번만 명시해오 OK, 부담 적음, 효율적, data 입력/수정/삭제 시 제약조건 자동 검사 & 적용
ex) 수강 릴레이션에 등록하려면 학생이 학생 릴레이션에 존재해야함을 명시
- 목적: 권한을 가지는 사용자로부터 데이터베이스의 정확성을 지키는 것. 사용자에 의한 데이터베이스 갱신이 데이터베이스의 일관성을 깨지 않도록 보장
ex) 어떤 학생이 수강신청 -> 수강 relation에 등록, 그러나 학생 relation에 없음
학생이 대학 자퇴, 학생 relation에는 없음, 그러나 수강 relation에 있음
=> 이러한 상황 방지 위해 데이터베이스 무결성 제약조건 존재
도메인 제약조건 (Domain Constraint)
- 각 애트리뷰트 값이 반드시 원자값
- 애트리뷰트 값의 디폴트 값 / NOT NULL 지정
- 데이터 형식을 통해 값들의 유형 제한, CHECK 제약 조건을 통해 값들의 범위 제한
TITLE CHAR(10) DEFAULT '사원', SALARY NUMBER CHECK (SALARY < 6000000)
키 제약조건 (Key Constraint)
- 키 애트리뷰트에 중복된 값 존재 X
기본키, UNIQUE 명시한 애트리뷰트 => 중복 불가
EMPNAME CHAR(10) UNIQUE
엔티티 무결성 제약조건 (Entity Integrity Constraint)
- 릴레이션의 기본 키를 구성하는 애트리뷰트는 NOT NULL
- 기본 키: 튜플 고유 식별, 효율적으로 빠르게 접근하는 데 사용 => 두 개 이상의 튜플이 동일한 기본키 값을 가질 수 없음
- 대체 키 적용 X
- 릴레이션 생성 데이터 정의문에서 어떤 애트리뷰트가 릴레이션의 기본 키 구성요소인지 DBMS에서 알려줌
EMPNO NUMBER NOT NULL, PRIMARY KEY(EMPNO)
참조 무결성 제약조건 (Referential Integrity Constraint)
- 두 릴레이션의 연관된 튜플들 사이의 일관성 유지
- 관계 데이터베이스: 릴레이션으로만 구성. 릴레이션 사이의 관계들: 다른 릴레이션의 기본 키 참조 => 외래 키
- 참조 무결성 제약조건 만족 기준 (R2의 외래 키가 R1의 기본 키를 참조)
- 외래 키의 값은 R1의 어떤 튜플의 기본 키 값과 같다
- 외래 키가 자신을 포함하고 있는 릴레이션의 기본 키를 구성하고 있지 않으면 널값을 가짐
연결: 외래키가 기본키 참조
위의 학생, 수강, 과목 릴레이션 예시에서 참조 무결성 제약조건?
: 수강 릴레이션의 학번이 학생 릴레이션의 학번 값들 중에서 와야함.
수강 릴레이션의 과목번호가 과목 릴레이션의 과목번호 값들 중에서 와야함
FOREIGN KEY
무결성 제약조건 유지
데이터베이스 갱신 연산 시, 데이터베이스가 무결성 제약조건들을 만족해야 한다.
외래 키 갱신, 참조 기본 키 갱신 => 참조 무결성 제약조건 유지
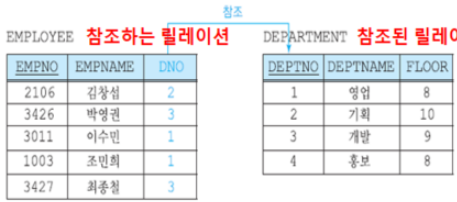
삽입
- 참조되는 릴레이션(DEPARTMENT): 새로운 튜플 삽입 => 참조 무결성 제약조건 위배 X
새로 삽입되는 튜플의 기본 키 애트리뷰트 값에 따라서는 도메인 제약조건, 키 제약조건, 엔티티 무결성 제약조건 위배 가능 - 참조하는 릴레이션(EMPLOYEE): 새로운 튜플 삽입 => 다른 제약조건 + 참조 무결성 제약조건 위배 가능
- 참조되는 릴레이션의 기본 키 값에 없는 값을 참조하는 릴레이션에 삽입 시 => 참조 무결성 제약조건 위배
ex) EMPLOYEE 릴레이션에 (4325, 오혜원, 6) 삽입 => 참조 무결성 제약조건 위배
DEPARTMENT 릴레이션에 (2, 총무, 9) => 키 제약조건 위배. DEPTNO UNIQUE
(NULL, 총무, 9) => 엔티티 제약조건 위배. (5,2,9) => 도메인 제약조건 위배 (부서 이름에 숫자)
삭제
- 참조하는 릴레이션(EMPLOYEE): 튜플 삭제 시, 모든 제약조건 위배 X
- 참조되는 릴레이션(DEPARTMENT): 튜플 삭제 시, 참조 무결성 제약조건 위배 가능
ex) DEPARTMENT 릴레이션에서 (4,홍보,8)을 삭제 => 참조 무결성 제약조건 위배 X
(3,개발,9) 삭제 => 참조 무결성 제약조건 위배 (DEPTNO3을 참조하는 EMPLOYEE 릴레이션의DNO가 존재) - 참조 무결성 제약조건 만족시키기 위해 DBMS가 제공하는 옵션
- 제한(restricted): 위배를 야기한 연산 거절
ex) DEPARTMENT 릴레이션에서 (3,개발,9) 삭제 거절 - 연쇄(cascade): 참조되는 릴레이션에서 튜플 삭제, 참조하는 릴레이션에서 이 튜플을 참조하는 튜플들도 함께 삭제
ex) DEPARTMENT 릴레이션에서 (3,개발,9) 삭제 -> EMPLOYEE 릴레이션에서 (3426,박영권,3), (3427,최종철,3)도 함께 삭제 - 널값(nullify): 참조되는 릴레이션에서 튜플 삭제 -> 참조하는 릴레이션에서 이 튜플을 참조하는 튜플들의 외래 키에 널값 삽입
ex) DEPARTMENT 릴레이션에서 (3,개발,9) 삭제 -> EMPLOYEE 릴레이션에서 (3426,박영권,NULL), (3427,최종철,NULL) 널값 삽입 - 디폴트값: 널값을 넣는 대신 디폴트 값 삽입
- 제한(restricted): 위배를 야기한 연산 거절
수정
- 수정하는 애트리뷰트가 기본 키인지 외래 키인지 검사 -> 기본 키도 외래 키도 아니면 참조 무결성 제약조건 위배 X
- 기본 키나 외래 키 수정: 하나의 튜플을 삭제하고 새로운 튜플을 그 자리에 삽입하는 것과 유사
=> 삽입/삭제의 제한, 연쇄, 널값, 디폴트값 규칙 적용
1. 학생 릴레이션에서 '24036' 튜플 삭제 ❌ 제한, 연쇄 (기본키: null, default X)
2. 학생 릴레이션에서 '30419' 튜플 삭제 ❌ 제한, 연쇄 (기본키: null, default X)
3. 학생 릴레이션에서 '11002'를 '13452'로 수정 ❌ 제한, 연쇄 (기본키: null, default X)
4. 학생 릴레이션에서 새로운 '42531' 튜플 삽입 ⭕
5. 수강 릴레이션에서 새로운 튜플 (30419, CS366, A0) 삽입 ❌ (CS366: 참조되는 릴레이션의 기본키에 X)
6. 수강 릴레이션에서 새로운 튜플 (24036, CS313, B+) 삽입 ⭕
7. 수강 릴레이션에서 새로운 튜플 (32517, CS313, B0) 삽입 ❌ (32517: 참조되는 릴레이션의 기본키에 X)
8. 과목 릴레이션에서 'CS326' 튜플 삭제 ⭕
9. 과목 릴레이션에서 'CS313' 튜플 삭제 ❌ 제한, 연쇄 (기본키: null, default X)
10. 과목 릴레이션에서 'CS345'를 'CS321'로 수정 ❌ 제한, 연쇄 (기본키: null, default X)