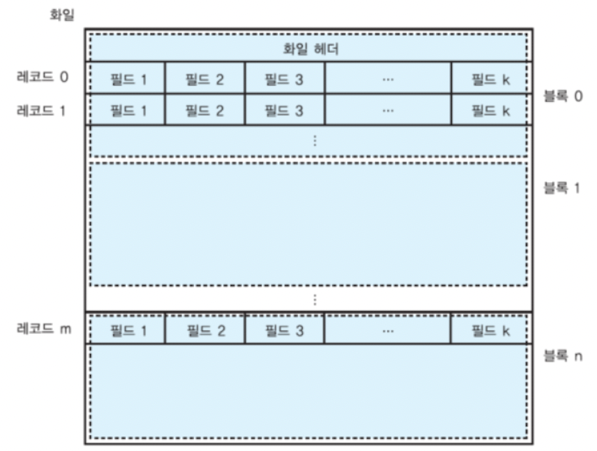
물리적 데이터베이스 설계
: 논리적인 설계의 데이터 구조를 보조 기억 장치 상의 화일(물리적인 데이터 모델)로 사상
예상 빈도를 포함하여 데이터베이스 질의와 트랜잭션 분석
데이터에 대한 효율적 접근 제공 위해 저장 구조, 접근 방법들을 다룸 -> 조인 연산 속도 향상
DBMS 종류 고려하여 진행
질의를 효율적으로 지원하기 위해 인덱스 구조 적절히 사용
- 인덱스 너무 많을 시, 데이터베이스 갱신에 시간 많이 걸림
- 인덱스 너무 적을 시, 검색 연산 효율적으로 적용되지 않음
보조 기억 장치
보조 기억 장치
: 사용자가 원하는 데이터 검색 위해 DBMS는 디스크 상의 데이터베이스로부터 사용자가 원하는 데이터를 포함하고 있는 블록을 읽어서 주기억 장치로 가져옴
데이터 변경 시, 디스크에 블록 다시 기록
블록 크기: 512bytes~ 운영체제에 따라 다름. 일반적으로 4096bytes
- 디스크: 데이터베이스를 장기간 보관하는 주된 보조 기억 장치
주기억장치: RAM. 빠르지만 용량 작음
디스크: 직접 접근
테이프: 순차 접근만 가능. 느림. 백업용으로만 사용
자기 디스크
- 디스크: 자기 물질로 만들어진 여러 개의 판으로 이루어짐
각 면마다 디스크 헤드가 있음 - 각 판: 트랙과 섹터로 구분
정보 -> 디스크 표면 상의 동심원(트랙)을 따라 저장 - 실린더: 여러 개의 디스크 면 중에서 같은 지름을 갖는 트랙들
- 블록: 한 개 이상의 섹터들로 이루어짐
- 탐구 시간(Seek time): 디스크에서 임의의 블록을 읽어오거나 기록하는데 걸리는 시간
=> 회전 지연 시간(Rotational delay) + 전송 시간(Transfer time, 블록을 주기억장치로 전송하는 데 걸리는 시간)디스크 접속 소요 시간을 줄이기 위해서?
=> 평균 회전지연시간 감소, 블록 전송 횟수 감소
버퍼 관리와 운영 체제
모든 데이터를 주기억장치에 올릴 수 없기 때문에 한정된 버퍼 공간에 어떤 블록들을 주기억장치에 유지할 것인가
- 디스크 입출력: 속도 가장 느린 작업. 입출력 횟수 줄이기 => DBMS 성능 향상
가능하면 많은 블록들을 주기억 장치에 유지 or 자주 참조되는 블록들을 주기억 장치에 유지 => 블록 전송 횟수 감소 - 버퍼: 디스크 블록 저장하는데 사용되는 주기억 장치 공간
- 버퍼 관리자: 운영 체제의 구성요소. 주기억 장치 내에서 버퍼 공간 할당, 관리.
- LRU 알고리즘: 버퍼 내에서 가장 오래 전에 참조된 블록을 디스크에 내보내고 지금 필요한 블록 읽어오기
=> 버퍼에 최근에 접근된 블록 유지.
디스크 상에서 화일의 레코드 배치
릴레이션의 애트리뷰트: 고정 길이 or 가변 길이의 필드
연관된 필드들 => 고정 길이 or 가변 길이의 레코드
한 릴레이션을 구성하는 레코드들의 모임 => 화일 (블록들의 모임)
한 화일에 속하는 블록들이 반드시 인접해 있을 필요 X
인접한 블록들을 읽는 경우: 탐구 시간과 회전 지연 시간 X. 입출력 속도 Fast.
-
BLOB(Binary Large Object): 이미지, 동영상 등 대규모 크기의 데이터 저장
8TB ~ 128TB
(블록 크기: 일반적으로 레코드보다 훨씬 big. IF 레코드 길이 > 블록 크기: 한 레코드 여러 블록에 저장해야 함) -
채우기 인수: 각 블록에 레코드를 채우는 공간의 비율
나중에 레코드 삽입될 때, 기존의 레코드들을 이동하는 가능성을 줄이기 위해서 빈 공간을 남겨두기. -
고정 길이 레코드
: 레코드 i를 접근하기 위해 n*(i-1)+1 위치에서 레코드 읽기 (n: 바이트)
* 가변 길이: 위치 파악 어려움. 레코드 끝 나타내는 특별 문자 사용.
* 고정 길이: 레코드 배치, 관리 단순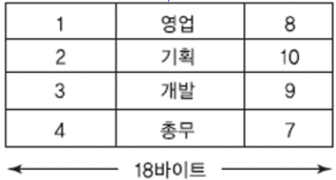
18*(3-1)+1 = 37byte부터 읽으면 세 번째 레코드 읽을 수 있음.
2번 레코드 삭제 시, 4번 레코드를 2번 자리로 옮겨서 빈 자리를 채우면 한 개의 레코드만 이동해도 재배치 가능. -
화일 내의 클러스터링 (Intra-File Clustering)
: 한 화일 내에서 함께 검색될 가능성이 높은 레코드들을 디스크 상에서 물리적으로 가까운 곳에 모아두는 것 -
화일 간의 클러스터링 (Inter-File Clustering)
: 논리적으로 연관되어 함께 검색될 가능성이 높은 두 개 이상의 화일에 속한 레코드들을 디스크 상에서 물리적으로 가까운 곳에 저장하는 것
화일 조직
: 화일 내의 데이터를 보조기억장치인 디스크에서 블록과 레코드들로 배치
히프 화일 (Heap File)
: 레코드들이 삽입된 순서대로 화일에 저장
- 삽입: 새로 삽입되는 레코드는 화일의 가장 끝에 첨부
- 검색: 원하는 레코드를 찾기 위해서는 모든 레코드들을 순차적 접근
- 삭제: 원하는 레코드를 찾은 후에 그 레코드 삭제, 삭제된 레코드가 차지하던 공간 재사용 X
(공간 재사용 시, 레코드 삽입 시에 끝 대신에 중간에서 자리를 찾아야하기 때문에 시간 증가)
* 공간 재사용하지 않고 끝에 계속 새로 넣기 때문에 화일 크기 증가 => 주기적 재조직 필요 (릴레이션 쭉 적재할 때 사용)
- 성능
- 효율적: 질의에서 모든 레코드 참조, 접근 순서 중요 X
SELECT *
FROM EMPLOYEE;- 비효율적: 특정 레코드 검색
// 히프 화일에 b개의 블록이 있을 때
// 원하는 블록을 찾기 위해 평균적으로 b/2개의 블록을 읽어야 함
SELECT TITLE
FROM EMPLOYEE
WHERE EMPNO = 1365;// 몇 개의 레코드들 검색.
// 조건에 맞는 레코드 이미 한 개 이상 검색했더라도
// 화일의 마지막 블록까지 읽어서 원하는 레코드 존재하는가 확인해야 함
// b개의 블록 모두 읽어야 함
SELECT EMPNAME, TITLE
FROM EMPLOYEE
WHERE DNO = 2;// 급여의 범위를 만족하는 레코드들 모두 검색
// EMPLOYEE 릴레이션의 모든 레코드들을 접근해야 함
SELECT EMPNAME, TITLE
FROM EMPLOYEE
WHERE SALARY >= 3000000 AND SALARY <= 4000000;
- 레코드: 10,000,000개, 레코드 길이: 200byte
- 블록 크기: 4096byte
- 블록킹 인수: 4096/200 = 20 (한 블록에 포함되는 레코드 수)
- 한 블록 읽는 데 걸리는 시간: 10ms
- 블록 수: 10,000,000 / 20 = 500,000개
- 특정 레코드를 찾기 위해 읽어야 하는 디스크 블록 수: 500,000 / 2 = 250,000개
- 총 걸리는 시간: 250,000 * 10ms = 2,500,000ms = 2500s (약 42m)
효율적: 삽입
비효율적: 삭제, 탐색, 순서대로 검색, 특정 레코드 검색
순차 화일 (Sequential File)
: 레코드들이 하나 이상의 필드 값에 따라 순서대로 저장된 화일 (탐색 키값의 순서에 따라 저장)
*탐색 키(Search Key): 순차 화일을 정렬하는데 사용되는 필드
- 삽입: 삽입 레코드 순서 고려해야하기 때문에 시간 많이 소요
- 삭제: 삭제된 레코드가 사용하던 공간을 빈 공간으로 남기기 때문에 히프 화일과 마찬가지로 주기적 재조직 필요
* 레코드 순차적 접근 응용에 적합. 화일의 레코드들이 정렬된 필드를 사용해서 특정 레코드 검색 효율적
- 성능
- 효율적: EMPLOYEE 화일이 EMPNO의 순서대로 저장되어 있을 때 이진 탐색 이용
SELECT TITLE
FROM EMPLOYEE
WHERE EMPNO = 1365;- 비효율적: SALARY는 저장 순서와 무관. 화일 전체 탐색.
SELECT EMPNAME, TITLE
FROM EMPLOYEE
WHERE SALARY >= 3000000 AND SALARY <= 4000000;
- 레코드: 10,000,000개, 레코드 길이: 200byte
- 블록 크기: 4096byte
- 블록킹 인수: 4096/200 = 20 (한 블록에 포함되는 레코드 수)
- 한 블록 읽는 데 걸리는 시간: 10ms
이진 탐색
- 블록 수: 10,000,000 / 2 = 500,000개
- 특정 레코드 찾기 위해 읽어야 하는 디스크 블록 수: = 19개
- 총 걸리는 시간: 19 * 10ms = 190ms
효율적: 탐색 키 기반 탐색
비효율적: 삽입, 삭제, 탐색 키가 아닌 필드를 사용하여 탐색
단일 단계 인덱스
인덱스된 순차 화일: 인덱스를 통해서 임의의 레코드를 접근할 수 있는 화일
- 엔트리: <탐색 키, 레코드에 대한 포인터>, 탐색 키 값의 오름차순으로 정렬
탐색 키 값의 인덱스를 찾아, 인덱스의 포인터로 찾음 - 인덱스: 데이터 화일과는 별도의 화일에 저장. 데이터 화일보다 훨씬 작은 크기. 하나의 화일에 여러 개 인덱스 정의 가능
- 탐색 키: 인덱스가 정의된 필드. 탐색 키 값은 후보 키처럼 각 튜플마다 반드시 고유하지는 X. 키 구성 애트리뷰트뿐만 아니라 어떤 애트리뷰트도 탐색 키로 사용 가능.
- 인덱스 엔트리: 탐색 키 값의 오름차순으로 저장. 이진 탐색 가능. (데이터파일이 큰 경우 인덱스 사용이 유리)
기본 인덱스 (Primary Index)
: 탐색 키가 데이터 화일의 기본 키인 인덱스
기본 키의 값에 따라 정렬된 데이터 화일에 대해 정의됨
- 희소 인덱스로 유지 가능. (데이터 레코드마다 모두 포함되는 게 아니라 각 블록마다 하나의 탐색키가 인덱스에 포함)
- 각 릴레이션마다 최대 한 개의 기본 인덱스 가질 수 있음
- 레코드: 10,000,000개, 레코드 길이: 200byte
- 블록 크기: 4096byte
- 블록킹 인수: 4096/200 = 20 (한 블록에 포함되는 레코드 수)
- 한 블록 읽는 데 걸리는 시간: 10ms
- 블록 포인터: 4byte, 키 필드 길이: 20byte
- 블록 수: 10,000,000 / 20 = 500,000개
데이터 화일의 각 블록마다 하나의 인덱스 엔트리가 인덱스에 들어 있음 (인덱스 엔트리 개수 = 데이터 블록 개수)
- 인덱스 엔트리 길이: 24byte
- 인덱스 블록킹 인수: 4096/24 = 170 (인덱스 블록 당 170개의 인덱스 엔트리 들어감)
- 인덱스 크기: 500,000/170 = 2942블록
- 인덱스로 하나의 레코드를 찾는데 필요한 블록 접근 횟수: (인덱스 블록 접근 횟수) + 1(데이터 블록 접근 횟수) = 13
- 총 걸리는 시간: 13*10ms = 130ms
클러스터링 인덱스 (Clustering Index)
: 탐색 키 값에 따라 정렬된 데이터 화일에 대해 정의됨
각각의 상이한 키 값마다 하나의 인덱스 엔트리가 인덱스에 포함
범위 질의에 유용
- 범위의 시작 값에 해당하는 인덱스 엔트리 먼저 찾고, 범위에 속하는 인덱스 엔트리 따라가면서 레코드 검색 시, 디스크에서 읽어오는 블록 수 최소화
- 레코드: 10,000,000개, 레코드 길이: 200byte
- 블록 크기: 4096byte
- 블록킹 인수: 4096/200 = 20 (한 블록에 포함되는 레코드 수)
- 한 블록 읽는 데 걸리는 시간: 10ms
- 블록 포인터: 4byte, 키 필드 길이: 20byte
- 블록 수: 10,000,000 / 20 = 500,000개
데이터 화일의 각 블록마다 하나의 인덱스 엔트리가 인덱스에 들어 있음 (인덱스 엔트리 개수 = 데이터 블록 개수)- 서로 상이한 탐색 키 값들의 수: 800,000
- 인덱스 엔트리 길이: 24byte
- 인덱스 블록킹 인수: 4096/24 = 170
- 인덱스 크기: 800,000/170 = 4706블록
- 인덱스로 하나의 레코드를 찾는데 필요한 블록 접근 횟수: + 1 = 14
- 총 걸리는 시간: 14 * 10ms = 140ms
보조 인덱스 (Secondary Index)
: 탐색 키 값에 따라 정렬되지 않은 데이터 화일에 대해 정의
- 한 화일: 한 가지 필드들의 조합에 대해서만 정렬
- 보조 인덱스 => 밀집 인덱스. 같은 수의 레코드들을 접근할 때 보조 인덱스 사용 시, 기본 인덱스보다 디스크 접근 횟수 증가
- 레코드: 10,000,000개, 레코드 길이: 200byte
- 블록 크기: 4096byte
- 블록킹 인수: 4096/200 = 20 (한 블록에 포함되는 레코드 수)
- 한 블록 읽는 데 걸리는 시간: 10ms
- 블록 포인터: 4byte, 키 필드 길이: 20byte
- 블록 수: 10,000,000 / 20 = 500,000개
데이터 화일의 각 블록마다 하나의 인덱스 엔트리가 인덱스에 들어 있음 (인덱스 엔트리 개수 = 데이터 블록 개수)
- 인덱스 엔트리 길이: 24byte
- 인덱스 블록킹 인수: 4096/24 = 170
- 인덱스 블록 수: 10,000,000/170 = 58,824블록
- 인덱스로 하나의 레코드를 찾는데 필요한 블록 접근 횟수: + 1 = 17
- 총 걸리는 시간: 17 * 10ms = 170ms
희소 인덱스 VS 밀집 인덱스
| 희소 인덱스 | 밀집 인덱스 |
|---|---|
| 블록마다 한 개의 엔트리 | 레코드마다 한 개의 엔트리 |
| 엔트리 수 ⬇️ | 엔트리 수 ⬆️ |
| 디스크 접근 수 1만큼 ⬇️ | |
| 갱신, 질의에 대해 효율적 | 인덱스 정의된 애트리뷰트만 검색(ex. COUNT) 시, 인덱스만 접근해서 질의 수행 가능 => 효율적 |
| 한 화일에 한 개 | 한 화일에 여러 개 |
클러스터링 인덱스 VS 보조 인덱스
| 클러스터링 인덱스 | 보조 인덱스 |
|---|---|
| 희소 인덱스 | 밀집 인덱스 |
| 범위 질의에 효율적 | 일부 질의에 대해 화일 접근 필요 없이 처리 가능 |
*클러스터링 인덱스: 채우기 인수에 낮은 값 지정해서 추가 삽입되는 레코드 대비하는 게 바람직
다단계 인덱스
: 인덱스 엔트리 탐색 시간 단축 위해, 단일 단계 인덱스를 디스크 상의 하나의 순서 화일로 간주, 단일 단계 인덱스에 대해 다시 인덱스 정의.
가장 상위 단계의 모든 인덱스 엔트리들이 한 블록에 들어갈 수 있을 때까지 위 과정 반복.
- 마스터 인덱스: 가장 상위 단계 인덱스
한 블록으로 이루어짐 => 주기억 장치에 상주 - B+-트리 사용
- 레코드: 10,000,000개, 레코드 길이: 200byte
- 블록 크기: 4096byte
- 블록킹 인수: 4096/200 = 20 (한 블록에 포함되는 레코드 수)
- 한 블록 읽는 데 걸리는 시간: 10ms
- 블록 포인터: 4byte, 키 필드 길이: 20byte
- 블록 수: 10,000,000 / 20 = 500,000개
데이터 화일의 각 블록마다 하나의 인덱스 엔트리가 인덱스에 들어 있음 (인덱스 엔트리 개수 = 데이터 블록 개수)
- 인덱스 엔트리 길이: 24byte
- 인덱스 블록킹 인수: 4096/24 = 170
- 1단계 인덱스 블록 수: 500,000/170 = 2942블록
- 2단계 인덱스 블록 수: 2942/170 = 18블록
- 3단계 인덱스 블록 수: 18/170 = 1블록 => 주기억장치 상주 가능
- 2단계 인덱스 한 블록, 1단계 인덱스 한 블록, 데이터 화일 한 블록: 3
- 총 걸리는 시간: 3 * 10ms =30ms
- SQL 인덱스 정의문
- CREATE TABLE에서 PRIMARY KEY절로 명시한 애트리뷰트에 대해 자동으로 기본 인덱스 생성
- CREATE TABLE에서 UNIQUE로 명시한 애트리뷰트에 대해 자동으로 보조 인덱스 생성
- 인덱스 생성문:CREATE INDEX EMPDNO_IDX ON EMPLOYEE(DNO);
- 다수의 애트리뷰트 사용한 인덱스 정의
: 한 릴레이션에 속하는 두 개 이상의 애트리뷰트들의 조합에 대하여 하나의 인덱스 정의 가능
CREATE INDEX EmpIndex ON EMPLOYEE (DNO, SALARY);
// 활용 가능
SELECT *
FROM EMPLOYEE
WHERE DNO = 3 AND SALARY = 4000000;// 활용 가능
SELECT *
FROM EMPLOYEE
WHERE DNO >= 2 AND DNO <= 3 AND SALARY >= 3000000 AND SALARY <= 4000000;// 활용 가능
SELECT *
FROM EMPLOYEE
WHERE DNO = 2; // 또는 DNO에 대한 범위 질의// **활용 불가능**
SELECT *
FROM EMPLOYEE
WHERE SALARY >= 3000000 AND SALARY <= 4000000; // 또는 SALARY에 대한 동등 조건- 인덱스 장단점
(+): 검색 속도 향상. 소수 레코드 수정, 삭제 연산 속도 향상. 릴레이션 매우 크고, 질의에서 릴레이션의 튜플들 중에 일부를 검색하고, WHERE절이 잘 표현되었을 때 성능 good
(-): 인덱스 저장 공간 추가로 필요. 삽입, 삭제, 수정 연산 속도 저하.
인덱스 선정 지침과 데이터베이스 튜닝
: 가장 중요한 질의, 수행 빈도 & 가장 중요한 갱신, 수행 빈도에 대한 성능 고려하여 인덱스 선정
- 인덱스 결정 지침
- 기본 키: 클러스터링 인덱스 정의 후보
- 외래 키: 인덱스 정의 후보 (조인 연산에 도움)
- 한 애트리뷰트에 들어있는 상이한 값들의 개수 ~= 전체 레코드 수, 그 애트리뷰트가 동등 조건에 사용 시, 비클러스터링 인덱스 생성
- 튜플이 많이 들어있는 릴레이션에서 대부분의 질의가 검색하는 튜플이 2~4% 미만인 경우에는 인덱스 생성
- 자주 갱신되는 애트리뷰트에는 인덱스 정의 X
- 자주 갱신되는 릴레이션에는 인덱스 정의 X
- 후보 키: 기본 키의 특성을 가짐. 인덱스 생성 후보
- 인덱스는 화일의 레코드들 충분히 분할 가능
- 정수형 애트리뷰트에 인덱스 생성
- VARCHAR, 날짜형, 실수형 애트리뷰트 인덱스 생성 X
- 작은 화일에는 인덱스 생성 X
- 대량 데이터 삽입 시, 모든 인덱스 제거 후, 데이터 삽입 완료 후, 인덱스 다시 생성
- 인덱스가 사용되지 않는 경우
- DBMS의 질의 최적화 모듈이 릴레이션의 크기가 작아서 인덱스가 도움이 되지 않는다고 판단
- 인덱스가 정의된 애트리뷰트에 산술 연산자 사용
SELECT *
FROM EMPLOYEE
WHERE SALARY * 12 > 40000000;- DBMS가 제공하는 내장 함수가 집단 함수 대신 사용
SELECT *
FROM EMPLOYEE
WHERE SUBSTR(EMPNAME, 1, 1) = '김';- 널값에 대해 인덱스 사용 X
SELECT *
FROM EMPLOYEE
WHERE MANAGER IS NULL;- 질의 튜닝을 위한 지침
- DISTINCT절 사용 최소화
- GROUP BY, HAVING절 사용 최소화
- 임시 릴레이션 사용 피하기
- SELECT * 대신에 SELECT절에 애트리뷰트 이름 구체적 명시
