스테이블 디퓨전 기초 과정 (1) - UI 구조 해석
1. 시작하며
스테이블 디퓨전에 대한 관심이 커지면서 서적을 구매하고 사내 개인 과외를 신청했다. 프롬프트에 대한 이해와 정리가 필요할 것 같아 시판 서적과 개인 과외 교본을 사용하여 그 내용을 정리한다. 본 블로그의 내용은 모두 개인 학습을 위한 필기 및 정리용이며 저작권은 모두 서적의 저자와 교본 작성자에게 있다.
2. 스테이블 디퓨전 사용하기
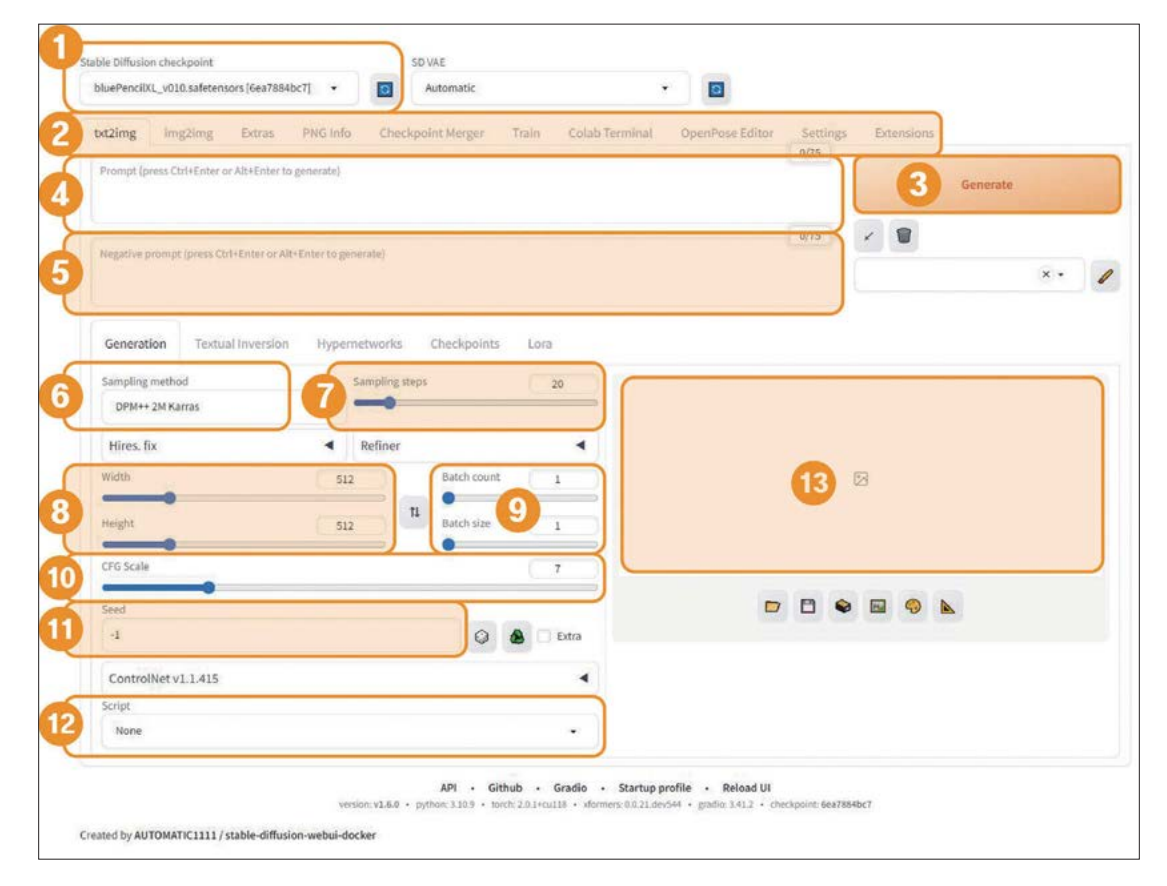
1. Checkpoint
그림 스타일이 학습돼 있는 모델을 선택할 수 있는 창입니다.
2. 탭
txt2mg, img2img를 주로 사용합니다.

3. Generate
버튼을 클릭하면 이미지를 생성하기 시작합니다.

4. 프롬프트
이미지가 입력한 문자에 근거해 생성됩니다. 생성형 이미지 인공지능 툴에서 가장 중요한 역할을 합니다. 프롬프트는 항상 여러 이미지를 생성해 보면서 테스트해 보세요 나에게 맞는 키워드 수집은 필수!

추천 프롬프트
masterpiece, best quality, intricate details, photorealistic,
(원하는 값 입력)...
5. 부정 프롬프트
생성되면 안 되는 이미지들을 입력한 문자에 근거해 제어합니다.

추천 프롬프트
EasyNegative, (worst quality, low quality:1.3), (text:1.8),(logo:1.8), (nsfw), low resolution, deformed, blurred, bad anatomy, disfigured, badly drawn face, mutation, mutated, extra limb, missing limb, blurred, floating limbs, detached limbs, blurred, watermark, bad proportion, cropped image
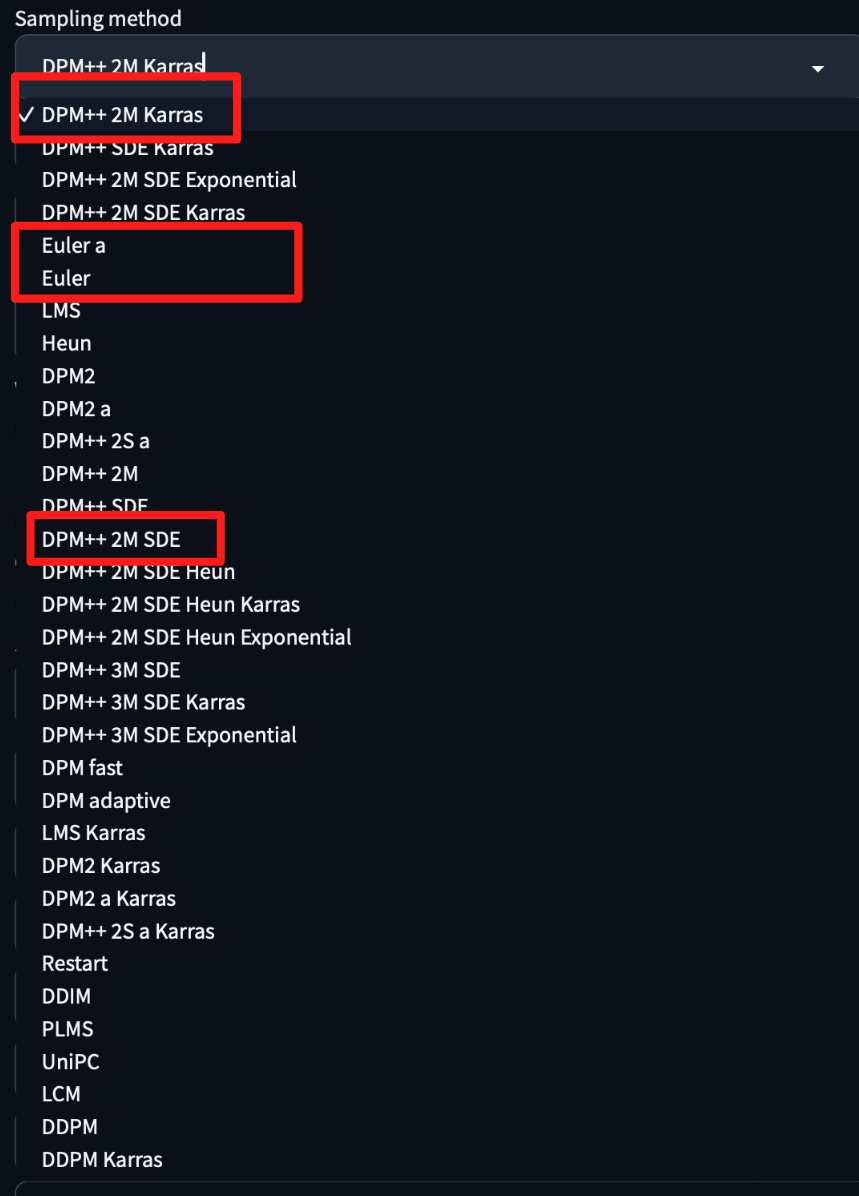
6. Sampling method
개념설명
| 서수 | 내용 |
|---|---|
| 1 | 어떤 과정을 통해 이미지를 생성할지 정하는 방법입니다. |
| 2 | 샘플러를 사용해 노이즈를 제거하는 작업 과정 단계를 줄여 속도를 높이는 역할을 합니다. |
| 3 | a가 붙은 샘플러는 무작위 이미지 생성률이 높아지고 a가 붙지 않은 샘플러는 좀 더 정교한 이미지를 생성할 수 있습니다. |
| 4 | a가 붙지 않은 샘플러는 좀 더 정교한 이미지를 생성할 수 있습니다. |

Sampling Method 방식에는 Euler a, DPM2 a 처럼 a가 붙어있는 샘플러가 있습니다. a는 조상 샘플러 (Ancestral Sampler)에서 따온 것으로 이러한 샘플러는 샘플링 단계에서 노이즈를 제거하고 일정 수준의 노이즈를 첨가하는 식으로 샘플링 됩니다.
따라서 샘플링 단계를 거치면서 하나의 이미지로 수렴해가는 Euler와는 다르게 Euler a는 각 샘플링 단계에서 보여지는 이미지가 달라질 수 있습니다.
안정적인 이미지 생성을 원하시면 a가 없는 샘플러를 선택하세요.
자주쓰이는 Sampling method
| 서수 | 내용 |
|---|---|
| 5 | 일반적으로 많이 사용되는 샘플링 방법으로는 Euler a, DPM++2M Karras, DPM++ SDE Karras 등이 있습니다. |
| 6 | EuIer a, Euler가 주로 사용되지만, 원하는 분위기 작업 방식에 따라 선택을 달리할 수 있습니다. |
| 7 | 주로 DPM++ SDE Karras에 Sampling step 30으로 설정하여 사용하고 있습니다. |
tip) 많은 샘플링 방법들이 있습니다. 일반적으로 아래 경우를 참조하여 사용하면 됩니다.
- 좋은 품질을 얻고 싶을 경우: DPM ++Karras, DPM ++2M Karras
- 속도를 중시할 경우: Euler, DPM fast
comment) AI 그림, 사진 오픈카톡방 조언
euler는 단순 수치적인 원시적 연산이고 euler a는 Ancerstal을 추가한거라 함수의 기울기를 반영한 샘플러에요. 그래서 euler보다 이미지가 더 자연스러운게 장점임니다. 반면 euler는 기초적인 연산이라 속도가 빠른게 장점이에요. 물론 유의미한 속도 차이를 보이는 정도는 아니라서 대부분 euler a가 더 좋습니다.
karras는 지수 방정식을 사용한 샘플러를 의미해요. 따라서 상대적으로 낮은 샘플링 횟수(스텝)으로 더 나은 결과물이 나옵니다. 기존엔 단순히 미분을 통해 노이즈를 제거했었는데, 지수 방정식을 도입함으로써 스탭별로 노이즈의 양과 분포를 유동적으로 조절할 수 있게끔 바꾸고 그 결과로 초기 단계에서 더 많은 노이즈를 억제 할 수 있게 된거에요. 계산이 추가된거라 속도가 느려지긴 하지만 효율적인 노이즈 제거 방식이라서 karras 선택이 가능하다면 저는 개인적으로 하시는걸 추천드려요
비슷한걸로 Exponential도 있는데 이거는 karras보다 정확도는 더 낮고 속도가 더 빠르다고 생각하시면 돼요. Exponential은 dpm 2m sde karrs처럼 karrs 자리에 붙을거에요 karrs가 많이 쓰이지 솔직히 그리 많이 쓰이는것 같진 않습니당
그 외에도 2m은 그냥 단순히 모드 두개 사용했다는 뜻이고 배경이랑 피사체 분할을 잘 하고 속도가 빠르다는 장점이 있습니당
sde는 확률을 넣은 미분 방정식 샘플러로 미분을 넣어서 보존률을 높힌 샘플러에요 보존률이 높아서 디테일이 좋은 대신 계산량이 많아서 효율이 좋지 못한게 단점입니당
DPM은 deformable part model을 줄인거였나 그랬을텐데 그냥 검출방식 여러개 섞은거라 범용성이 좋아서 여러군데에 폭 넓게 쓰여요 dpm으로 시작하는 샘플러가 많은 이유입니당 다르게 말하자면 이미지의 유동성이 좋다? 높다?
사실 dpm 파생들이 워낙 좋아서 그냥 웬만한 상황은 다 dpm++ 2m sde karrs gpu나 dpm++ 2m sde karrs 쓰는게 가장 좋을거에요
7.Sampling steps
개념설명
| 서수 | 내용 |
|---|---|
| 1 | 몇 단계를 실행해 이미지를 생성할것인지를 정하는 부분입니다 |
| 2 | step 수를 설정한 만큼 단계를 거쳐 노이즈를 제거합니다. |
| 3 | 따라서 step수가 적을수록 노이즈가 많고 샘플링 단계가 증가함에 따라 품질이 향상되지만, 단계 수를 늘이면 시간이 오래 걸립니다. |
| 4 | step수가 20~30을 넘어가게 되면 큰 차이가 발생하지 않으니 20~30 사이로 원하는 값을 설정해서 사용하면 됩니다. |
| 5 | 기본값은 20부터 최대 150까지 설정할 수 있습니다. |
일반적으로 EuIer 샘플러를 사용한 20단계는 고품질의 선명한 이미지에 도달하기에 충분합니다.
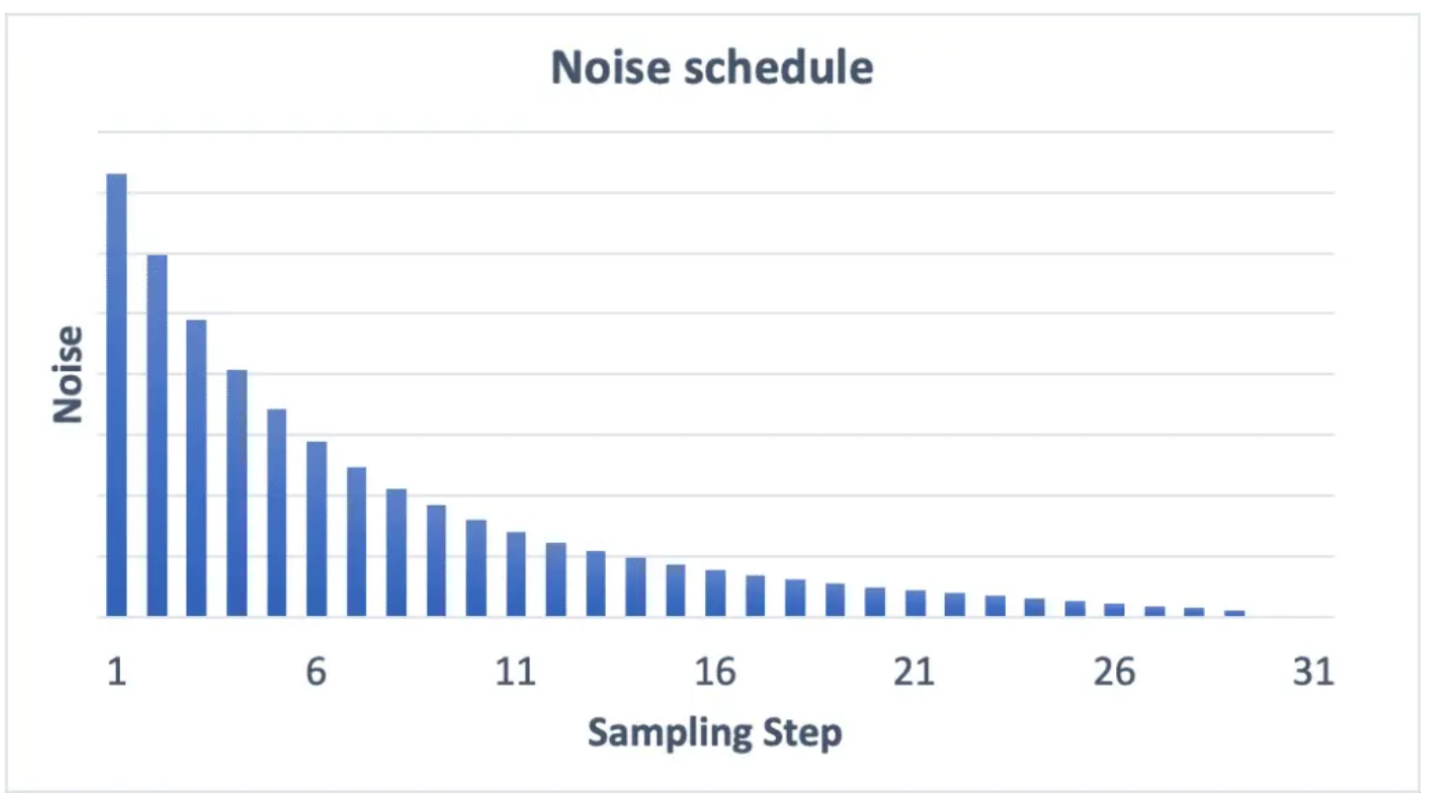
Noise schedule
Noise schedule 은 샘플링 단계에서 제거해야 할 노이즈입니다. 낮은 값에서 많은 노이즈를 제거하고 값이 높아질수록 0에 가까워집니다. sampling수 는 20~30 정도로 설정하면 됩니다.
8. Width와 Height
이미지의 폭을 조절합니다. 기본은 512Ⅹ512로 설정돼 있습니다. 이 값을 크게 하면 이미지의 퀄리티는 좋아지지만, 시간이 많이 걸리므로 생성한 후 마음에 드는 이미지를 선택해 업스케일하는 방법을 주로 사용합니다. 스테이블 디퓨전은 512 x 512 이미지로 훈련되기 때문에 세로 또는 가로 크기로 설정하면 예기치 않은 문제가 발생할 수 있습니다. 되도록 항상 정사각형을 유지하는 것이 좋습니다(권장 사항 이미지의 크기를 512 x512로 설정합니다)
9. Batch count, size
Batch count
| 서수 | 내용 |
|---|---|
| 1 | 배치 카운트(Batch count)는 한 번에 생성되는 이미지 수이며 생성할 이미지의 총 수를 설정합니다. |
| 2 | 한 이미지가 생성된 후 다음 이미지를 생성하는 방식으로 처리됩니다. |
| 3 | 프롬프트를 변경할 때마다 2~4개의 이미지를 생성해 검색 속도를 높일 수 있습니다. |
| 4 | 세부적인 변경을 할 때마다 4개의 이미지를 생성해 최대한 사용할 수 있는 이미지를 찾아내는 것이 중요합니다 |
| 5 | 처음부터 많은 이미지를 만들면 생성 속도가 무척 느려질 수 있으므로 처음에는 적당한 수의 이미지를 생성하는 것이 좋습니다. |
배치카운트는 1부터 설정할 수는 있지만 한 번에 원하는 이미지를 판단하기 어려우므로, 아래 방법을 취합니다.
배치카운트를 이용하여 여러 장을 생성하도록 설정한 후 생성해 보면서 원하는 이미지에 가까운 결과가 나온 후에 숫자를 늘여 이미지를 생성한 후 가장 근접한 이미지를 선택하는 것이 타율이 높아집니다
Batch size
| 서수 | 내용 |
|---|---|
| 1 | 배치 사이즈(Batch size)는 이미지를 동시에 생성하는 옵션입니다. |
| 2 | 한번의 모델에서 동시에 처리되는 이미지의 수를 설정합니다. |
| 3 | Batch size를 크게 설정하면 많은 컴퓨팅 리소스를 사용하지만, 처리 속도가 빠릅니다. |
| 4 | VRAM 사용량이 늘어나게 되므로 사이즈(size)를 늘이는 것보다는 카운트(count)를 늘리는 것이 좋습니다. |
Batch count:2, Batch size:2 로 설정하면 4(2*2)장의 이미지를 생성하게 됩니다.
10. CFG Scale
클래시파이어 프리 가이던스 스케일(Classifier Free Guidar℃e scale)은 모델이 프롬프트를 어느정도 존중해야 하는지를 제어하기 위한 매개변수입니다. 값이 클수록 비슷하게 고정된 이미지들이 생성되고 값이 적으면 랜덤 이미지가 생성됩니다. 기본급은 제며 예상되는 이미지를 원할 경우 10 이상으로 설정하면 깔끔한 결괏값을 얻을 수 있습니다.

1 - 대부분의 프롬프트를 무시합니다.
3 - 더 창의적이 됩니다.
7 - 신속성을 따르는 것과 자유를 지키는 것 사이의 균형이 좋습니다.
15 - 메시지를 더 표시합니다.
30 - 안내 메시지를 철저히 따릅니다.
2~6 : 창조성 높음. 프롬프트를 따리지 않을 가능성 높음
7-10 : 대부분의 경우 추천함. 창조성과 준수성간에 균형이 잡혀있음
10-15 : 프롬프트가 정말 좋고 정확하다고 확신할 때 사용
16-20 : 프롬프트가 정말 좋지 않는 한 추천하지 않음
11. Seed

| 서수 | 내용 |
|---|---|
| 1 | seed는 이미지 생성 과정에서 무작위성을 제어합니다. 기본값은 -1이고 seed값이 랜덤으로 설정됩니다. |
| 2 | seed는 생성되는 난수의 초기값을 의미합니다. |
| 3 | -로 설정하는 것은 매번 임의의 이미지를 사용하는 것을 의미합니다.새로운 이미지를 생성하고 싶을 때 유용합니다. |
| 4 | 랜덤 시드는 초기화 노이즈 패턴과 최종 이미지를 결정합니다. |
| 5 | 프롬프트, 설정, 시드 값이 같으면 똑같은 이미지가 나옵니다. |
| 6 | 고정하면 뉴제너레이션(newgeneration)에서 동일한 이미지가 생성됩니다. |
| 7 | [재활용]버튼을 누르면 바로 앞에서 생성된 이미지의 시드 값이 입력돼 같은 구도에서 프롬프트만 변경할 때 사용합니다. |
동일한 seed 값을 사용하면, 모델이 완전한 동일한 이미지를 다시 생성할 수 있습니다.
(프롬프트나 이미지 해상도 모델 등 다른 조건이 동일해야 동일한 seed값을 가졌을 때 동일한 이미지를 생성할 수 있습니다.)
다른 seed 값을 사용하면, 같은 텍스트 프롬프트와 설정을 사용해도 불구하고 다른 이미지를 생성할 수 있습니다.
질문: 시드값을 -1이 아닌 음수나 양수의 정수를 사용하면 어떻게 되나요? 소수점 시드도 쓸 수 있나요?
질문: 시드값을 내가 이미 생성한 그림의 시드값은 어떻게 볼 수 있나요?
질문: 이미지 생성 후에도 시드값 설정을 통해 이미지의 상세한 내용을 수정할 수 있나요?
12. Script
여러 가지 조합해 보고 싶을 때 사용하는 옵션이지만 VRAM 사용량이 늘어나 속도가 많이 느려집니다.


로라를 비교할때는 옵션이 없기 때문에 프롬프트를 선택해서 로라 값을 점차적으로 늘려줍니다.

VAE의 스크립트

STEP의 스크립트

로라와 체크포인트를 동시에 비교해보는 법
13. 이미지 업스케일 (Hires.fix)
stable diffusion에서 이미지를 생성할 때 기본 사이즈는 512*512 입니다.
만약 이미지의 해상도를 1024x1024로 늘리고 싶을 경우, 이미지의 생성에서 1024x1024로 생성하는 것이 아닌, Hires.fix를 이용하여 이미지를 업스케일 하는 것이 이미지가 조금 더 안정적으로 나옵니다.
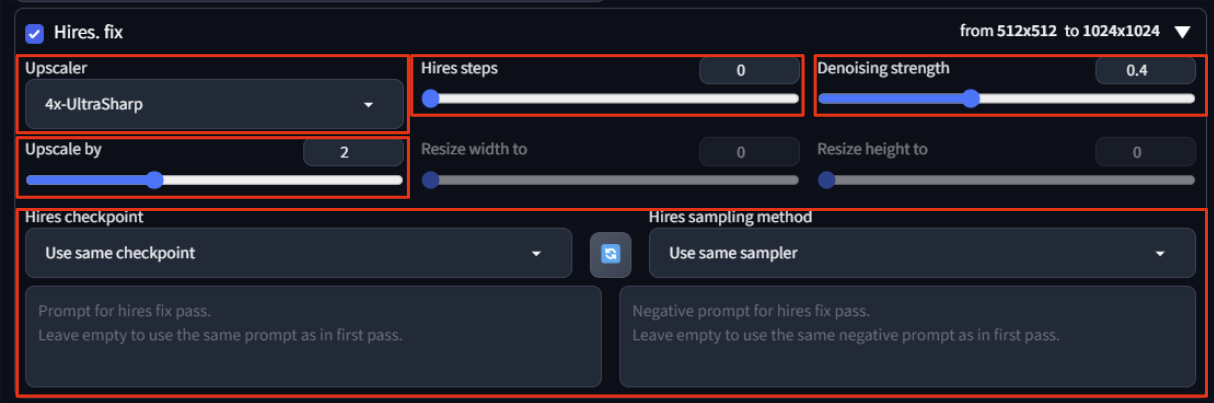
| 제목 | 내용 |
|---|---|
| Upscaler | 이미지를 어떤 방식으로 업스케일 할 건지를 선택합니다. 주로 R-ERGAN이나 4x-Ultrasharp를 사용하시면 됩니다. |
| Hires steps | sampling step과 유사합니다. 업스케일 과정을 거칠 때 몇 번의 단계를 거쳐 진행할지 결정합니다. 0으로 설정하면 앞에서 설정했던 Sampling step과 동일한 값으로 설정됩니다. |
| Denoising stength | Hire.fix과정을 거칠 때, 얼마나 노이즈를 추가할 것인지 정합니다. 값이 1에 가까워질수록 원본 이미지와 달라집니다. 어려우면 그냥 기본 설정값 그대로 두고 사용하시면 됩니다. |
| Upscale by | 몇 배 업스케일 할지 정합니다. 2로 설정할 경우 512x512에서 2배가 된 1024x1024 사이즈로 생성됩니다. |
| Hires checkpoint | 업스케일을 진행할 때, 처음 이미지를 생성할 때 사용한 checkpoint와 다른 모델을 골라서 사용할 수 있습니다. 원하지 않을 시 선택하지 않아도 됩니다. |
| Hires sampling method | 업스케일을 진행할 때, 처음 이미지를 생성할 때 사용한 sampling method와 다른 방식을 골라서 사용할 수 있습니다. 원하지 않을 시 선택하지 않아도 됩니다. |
사이즈 키울때 클릭
울트라 샤프는 실사쪽에서 사용
애니메이션은 anime 기본파일 사용

비율대로 늘리고 싶을때 사용
tip: 원래 사이즈는 512x512 등 작게 만들어서 계속 생성하고
마음에 드는 이미지가 나올때 시드값과 프롬프트, 이미지 사이즈를 동일하게 둔 뒤
업스케일드 바이에서 비율변경해서 크기 변경!

업스케일 할 때
- 이전과 많이 변화해도 될 때 : 0.7
- 이전과 비슷하길 바랄때 : 0.4
14. Adetailer
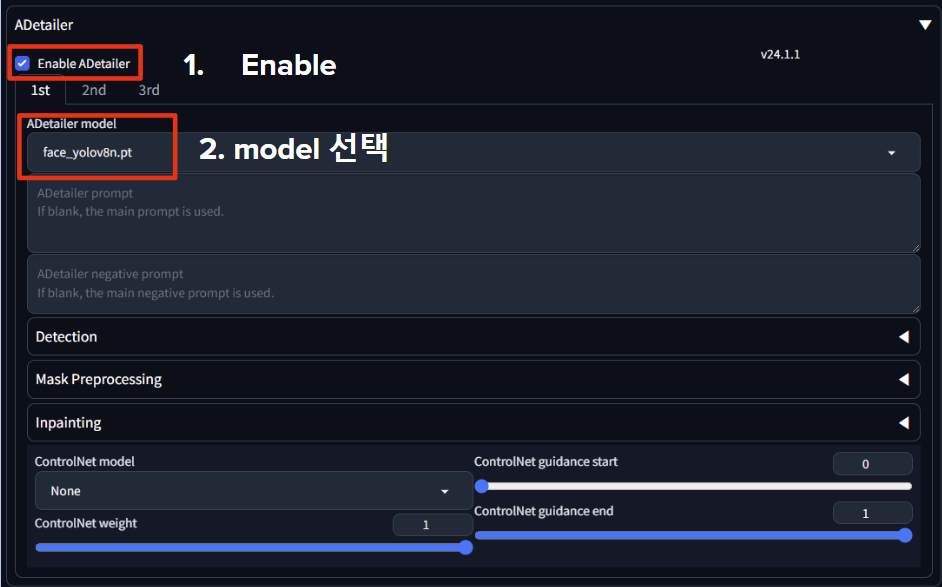
ADetailer model:
face_xx: 얼굴 감지 및 다시 그리기
hand_xx: 손 감지 및 다시 그리기
person_xx: 사람 전체를 감지하고 다시 그리기
mdeiapipe_face_xx: 얼굴 감지 및 다시 그리기
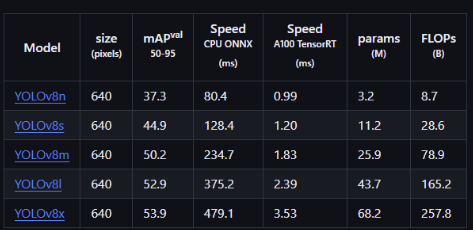
https://github.com/ultralytics/ultralytics
tmi.yolov모델을 보면 _n, _s모델이 있습니다.
1. s모델은 small
2. n모델은 nano
n 모델은 s모델보다 더 작고 빠른 모델입니다. s모델보다는 정확성이 조금 떨어집니다. )
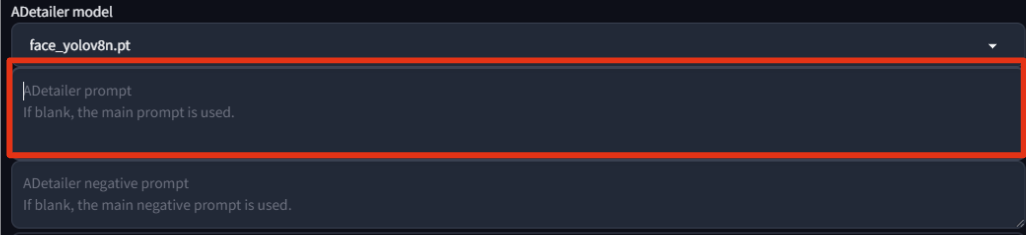
adetailer 내에 프롬프트를 작성하여 프롬프트에 맞게 다시 그려지는 부분을 수정할 수 있습니다.


Detection model confidence threshold: adetailer가 적용되면서 얼굴을 감지할 때 마스킹 영역에 숫자가 표시됩니다.
이 숫자는 신뢰도를 뜻하며, confidence threshold는 최소 신뢰도를 뜻합니다.
마스킹 영역이 최소 신뢰도 이상인 경우에만 adetailer가 적용됩니다.
confidence threshold를 0.9로 설정한다면
왼쪽의 이미지는 adetailer가 작용하겠지만
오른쪽의 이미지는 adetailer가 작용하지 않을 것입니다.

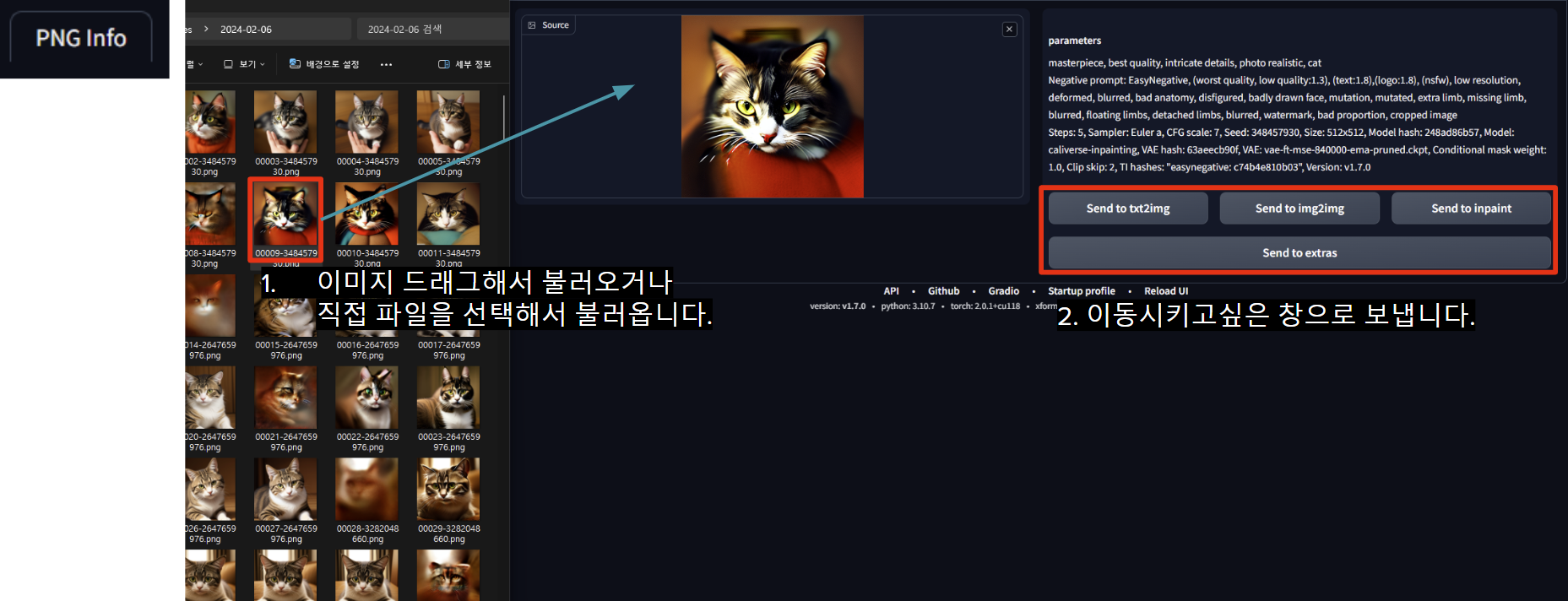
15. 기존 이미지의 생성 정보를 가져오는 법
이전에 생성한 이미지를 어떤 설정값으로 생성하였는지 알고 싶을 때 이미지의 생성 정보를 불러올 수 있습니다. 이때 생성 값을 불러올 이미지는 스테이블 디퓨전으로 생성된 원본 이미지만 생성값을 불러올 수 있습니다. 기본적으로 stable diffusion 에서 생성된 이미지는 stable-diffusion-webui\outputs 폴더에 저장됩니다.
방법1.
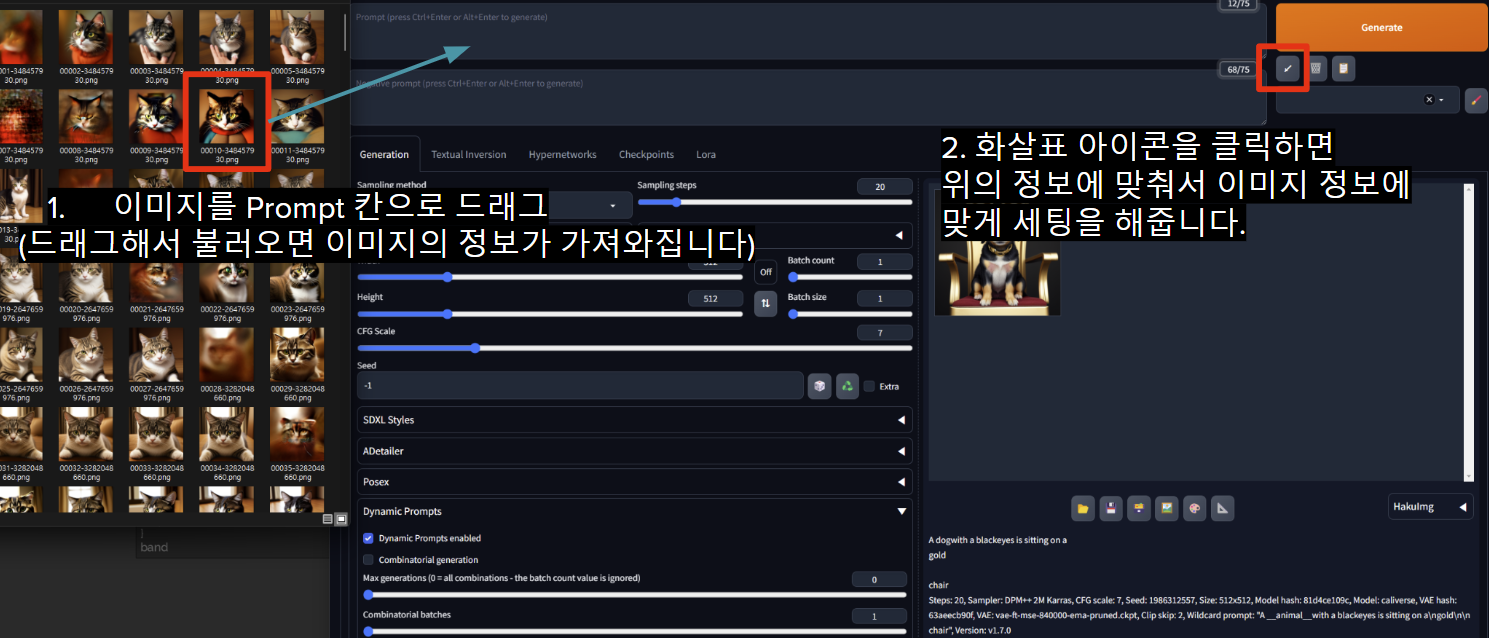
방법2.상단의 PNG Info 이용