Classification model의 y값은 '?' 값이다. 모델의 결과물을 binary한 결과값 y^로 제시하기 위해서 0과 1 사이의 일정한 기준값(Threshold)를 지정한다.
후술할 ROC를 이해하기 위해, 먼저 Confusion matrix (정오행렬 혹은 혼동행렬)를 먼저 살펴본다.
Confusion matrix
이진분류 모델에서 자주 활용되고 있다.
예측값과 실제값을 비교해서 각 영역에 해당하는 비율이 어느정도 되는지를 보기 위함이다.
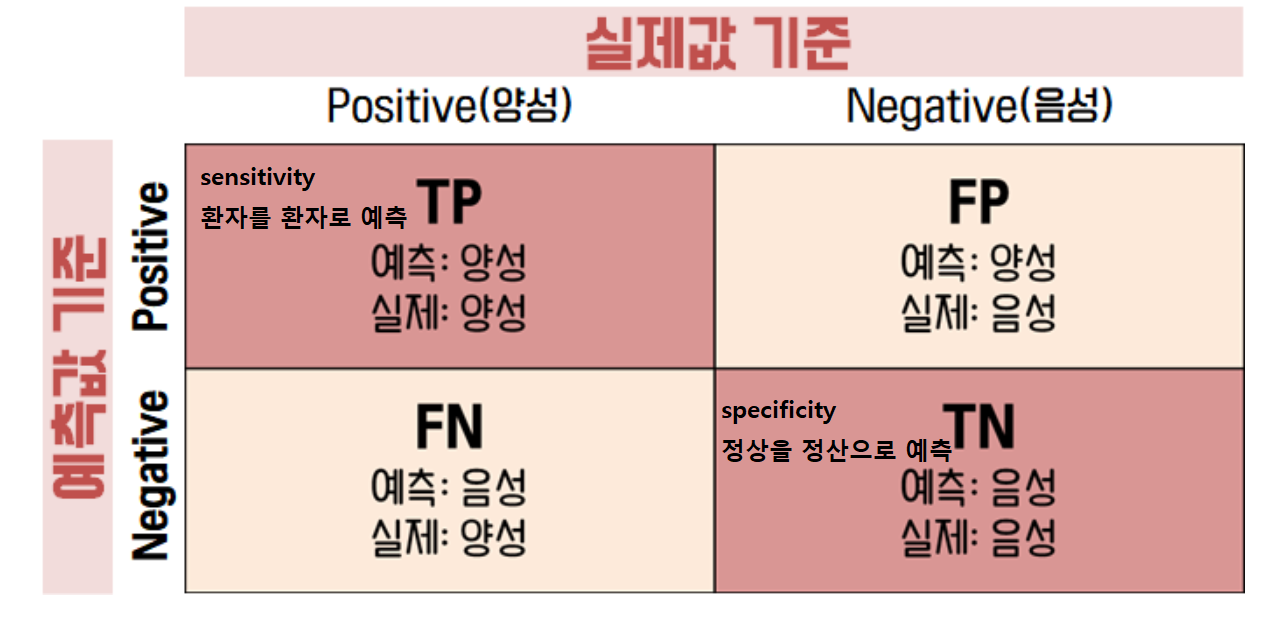
- True vs. False : 예측값이 실제 값인지에 대한 여부 (맞췄으면 True! 틀렸으면 False..)
- Positive vs. Negative : 예측했던 값 (양성/긍정/해당이면 Positive, 음성/부정/미해당이면 Negative)
ROC (Receiver Operating Characteristic)
ROC 곡선 그래프는 위에서 언급했던 것처럼 True Positive Rate를 Y축, False Positive Rate를 X축으로 하여 모델이 양성/긍정으로 예측했을 때 얼마나 잘 맞추고 있는지를 설명한 것이다.
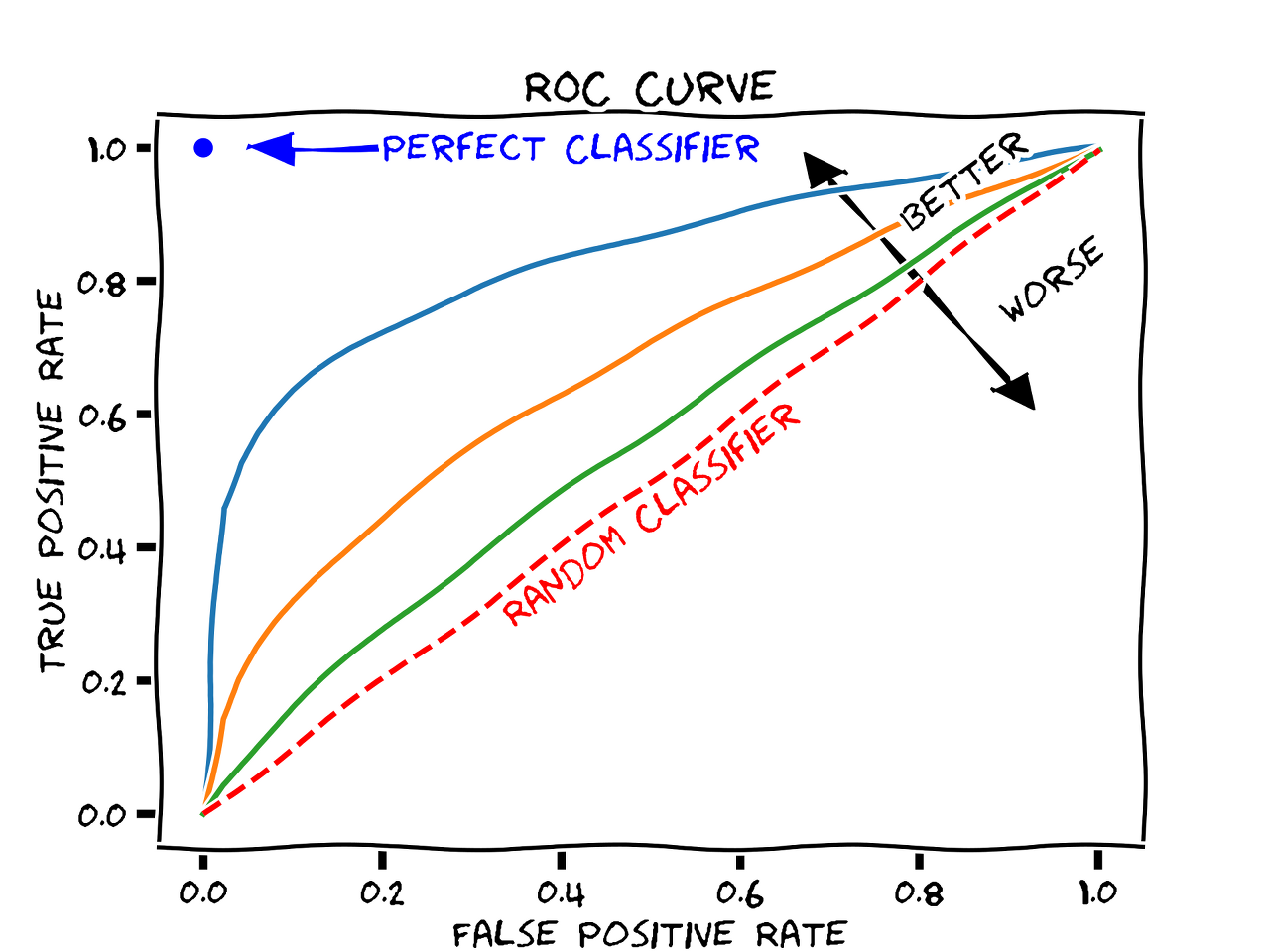
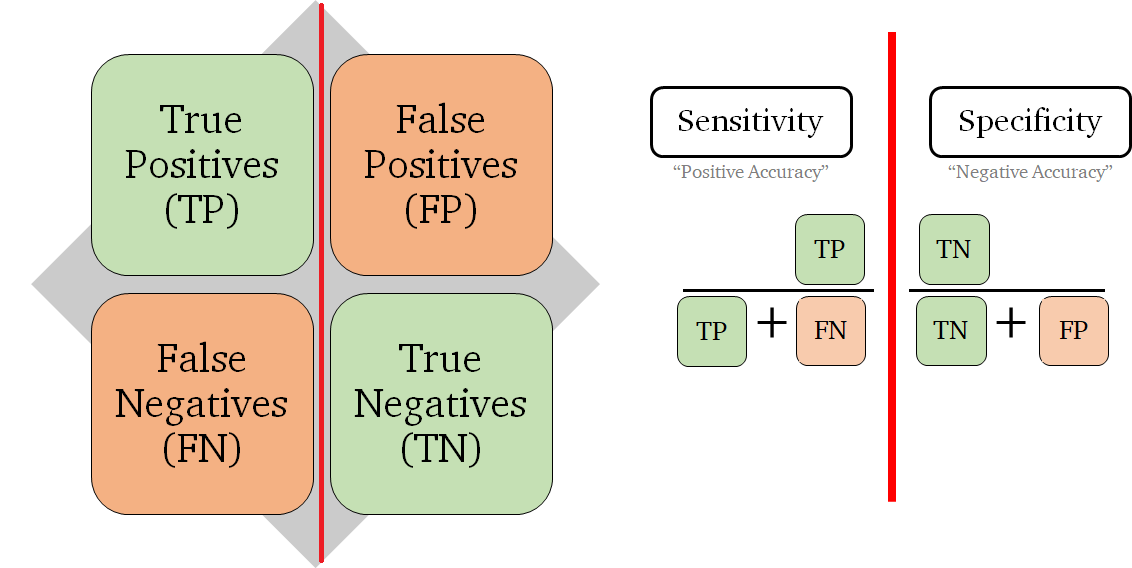
ROC를 이해하기 위해, 정밀도와 민감도를 알아야 한다.

정밀도(Precision)
i. 예측 Positive 중 실제도 Positive를 찾아낸 비율 = TP/(TP + NP)
ii. 출력결과가 정답을 얼마나 맞혔는지를 나타내는 지표.
iii. FP를 낮추는데 초점
iv. 미처 잡아내지 못한 개수가 많더라도 더 정확한 예측이 필요하다면 정밀도를 중시 = 실제 negative 음성인 데이터 예측을 positive 양성으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우
ex) negative인 일반 메일을 positive인 스팸메일로 분류했을 때 업무에 차질
민감도(Sensitivity)
민감도(Sensitivity) = 재현율(recall) = TPR(True Positive Rate)
ex) 레이블 처리(labelling)된 사진을 분석해 레이블 처리하지 않은 사진을 분류하는 작업을 재현(recall) 과정이라 한다.
i. 실제 Positive중 올바르게 Positive를 예측해 낸 비율 = TP/(TP + FN)
ii. 모형의 완전성을 평가하는 지표
iii. 출력결과가 실제 정답 중에서 얼마나 맞혔는지를 나타내는 지표.
iv. FN를 낮추는데 초점
v. 잘못 걸러내는 비율이 높더라도 참값을 놓치는 일이 없도록 하는 경우에 재현율을 중시 = 실제 positive 양성 데이터를 negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우
ex1) 암 판단 시 실제 positive인 암환자를 negative 음성으로 잘못 판단한 경우 생명 위험
ex2) 실제 금융거래 사기인 positive 건을 negative로 잘못 판단한 경우 회사 손실 큼
민감도(Sensitivity)와 특이도(Specificity) 관계
민감도(Sensitivity) : 실제 Positive중 올바르게 Positive를 예측해낸 비율
특이도(Specificity) : 실제 Negative 중 올바르게 Negative를 찾아낸 비율
민감도와 특이도는 상충하는 개념으로서, 'trade-off'의 관계에 있다.
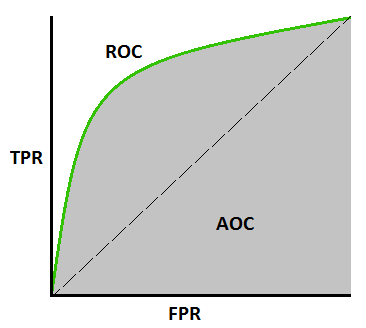
AUC (= AUROC)
AUC는 분류의 성능 지표로 사용되며, ROC 곡선 그래프의 아랫 부분의 빗금 친 영역을 말한다.
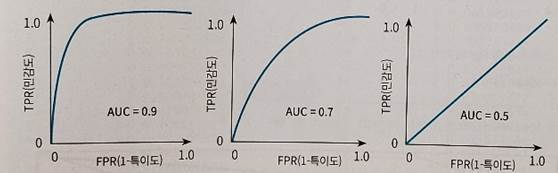
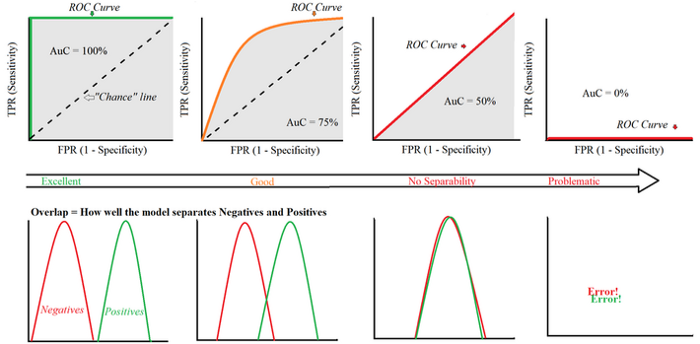
1에 가까울수록 모형의 성능이 우수하다고 할 수 있다.
0.5에 가까울수록 무작위로 예측하는 랜덤모델에 가까운 좋지 못한 모형이며,
AUC 수치가 커지려면 FPR이 작은 상태에서 얼마나 큰 TPR을 얻을 수 있느냐가 관건이다.
ref )
https://eva-codingnote.tistory.com/65
https://koreapy.tistory.com/897
