머신러닝 클리닉
1.#1 머신러닝의 정의와 목적

머신러닝이란, 데이터(Data)를 사용하여, 기계가 스스로 학습하게 하는 방법을 말한다.유명 머신러닝 연구자인 Tom Mitchell이 제안한 공식적인 정의는 다음과 같다.Tom Mitchell (1988) : A computer program is said to le
2.#2 Train-Vaildation-Test

머신러닝에서는 일반적으로 전체 데이터를 training set과 test set으로 나누는 과정을 거친다.학습에 사용되는 데이터 : Traininghyper-parameter tuning에 사용되는 데이터 : Validation최종 성능 확인에 사용하는 데이터 : Te
3.#3 머신러닝의 Task
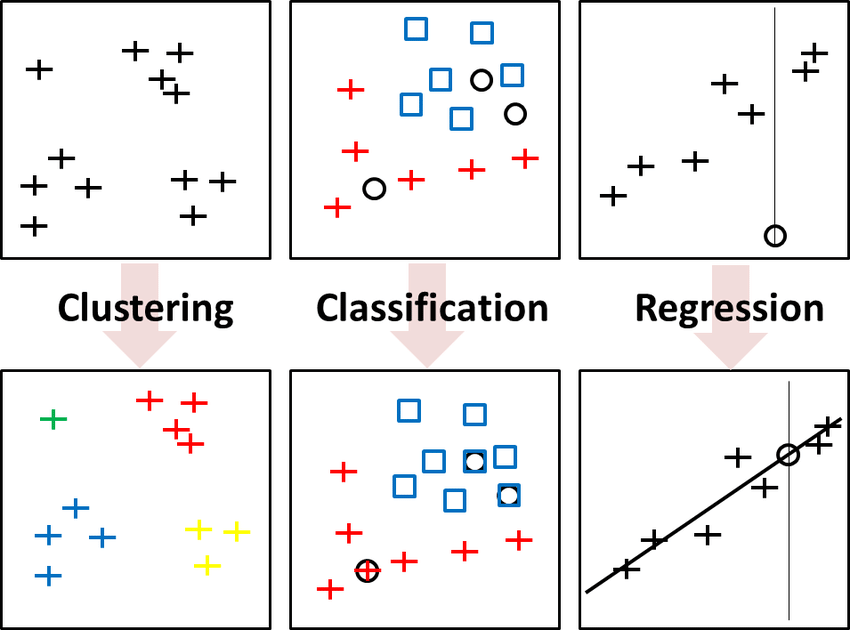
기계학습(ML)의 대표적인 3가지 Task 인 Classification(분류)과 Clustering(군집), 그리고 Regression(회귀)에 대해 알아보고자 한다. Classification (분류)지도학습(Supervised learning)의 일종. 기존의 데
4.#4 머신러닝의 구분
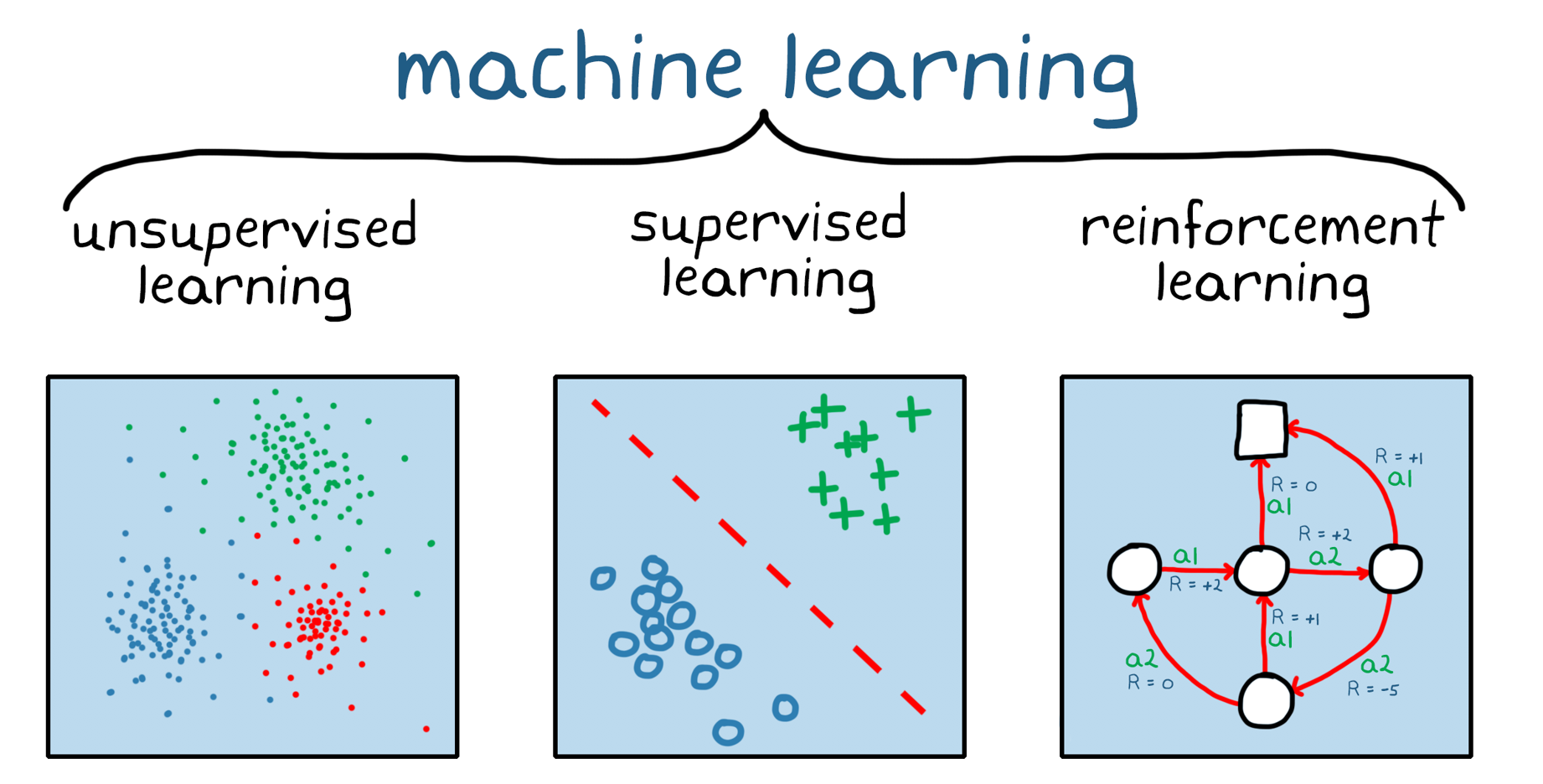
머신러닝 방법을 구분하는 방법에는 총 3가지가 있다.지도학습 지도 학습은 정답이 있는 데이터를 활용해 데이터를 학습시키는 방식.X(입력) → Y(label) 처럼 입력값을 통해 정답을 학습한다.대표적으로 Classification 과 Regression 이 있다.('h
5.#5 Linear ?
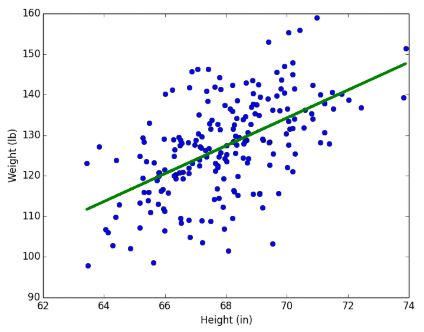
'Linear'라는 단어의 사전적 의미는 다음과 같다.X와 Y의 관계를 함수로 나타냈을 때, 선형으로 표현이 가능한 모델을 Linear Model이라고 한다.중학교 수학 시간에 가장 기본적으로 배웠던 '일차함수' 내용과 일맥상통한다.직선의 방정식Y = aX + bY =
6. #6 수식의 이해 : Simple
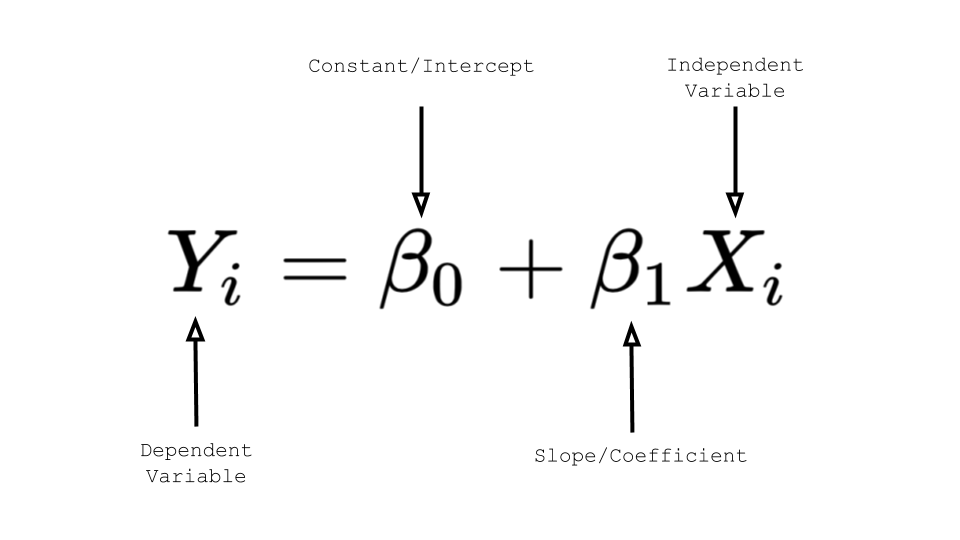
$$y = Wx + b$$ 종속 변수 y에 대한 독립 변수 x가 1개면 단순 선형 회귀라고 한다.W는 가중치, b를 편향(bias)라고 한다. (직선의 방정식에서의 기울기와 절편)가중치(W)는 데이터의 예측값에 얼마나 영향을 미칠 건지에 대한 파라미터이다.
7.#7 수식의 이해 : Multiple

$$y = W_1x_1 + W_2x_2 + ... + W_nx_n + b$$y : 종속 변수W : 가중치 x : 독립 변수b : 편향 이 다중 선형회귀를 잘 활용한 데이터 예제가 바로 '주택 가격'이다.우리가 부동산의 가격을 알아보고자 할 때, 여러가지의 고려 사항을
8.#8 선형회귀의 Task

Linear Regression 으로 해결할 수 있는 문제의 예시 보스턴 주택 가격 예측 기업의 프로모션 효용성 예측 대여자전거 이용률 예측 -
9.#9 Non-Linear ?
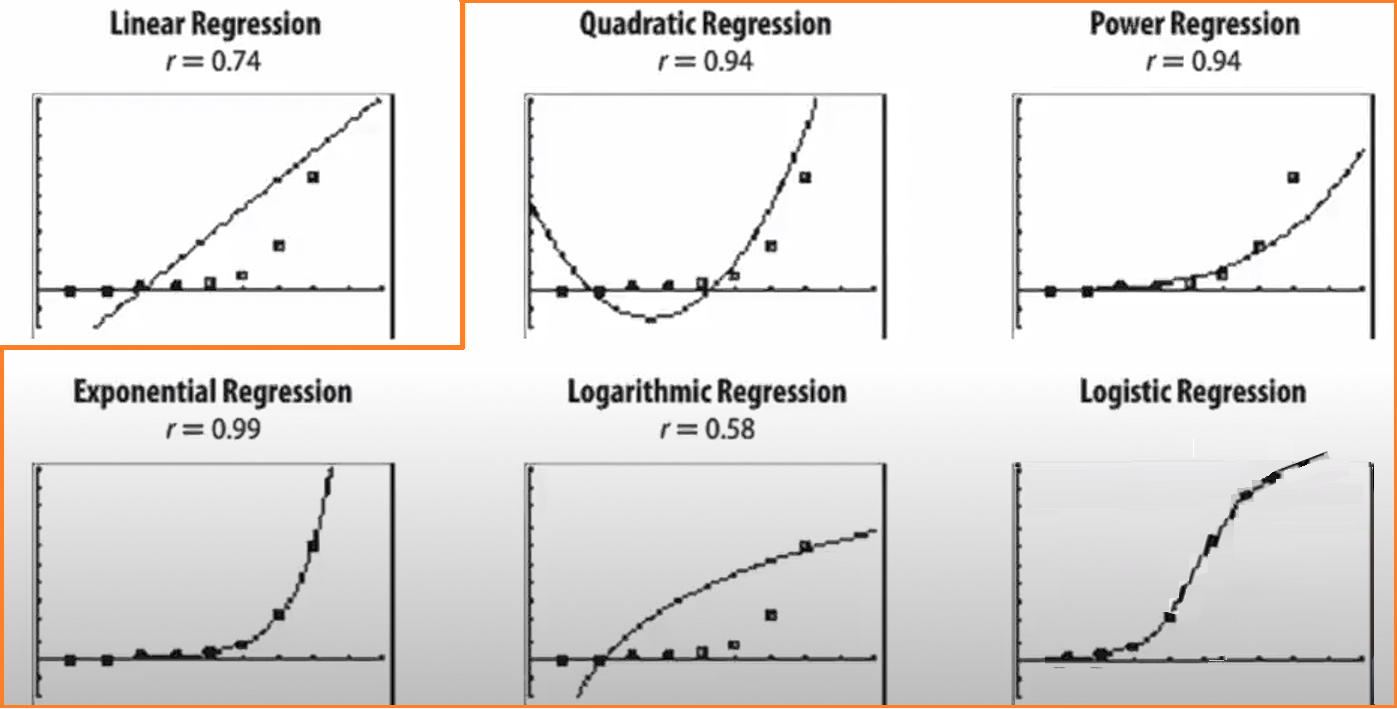
'Non-Linear'는 앞에서 이야기 했던 선형의 것과 달리, '선형이 아닌, 비선형의'라는 것을 의미한다.다시 말해, 비선형 모델이란 "데이터를 어떻게 변형하더라도 파라미터를 선형 결합식으로 표현할 수 없는 모델"이라고 말할 수 있다.$$y=f(X,β)+ϵ$$X와
10. #10 Binary & Multinomial
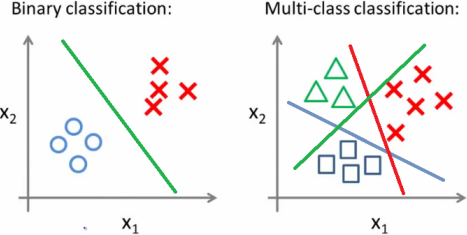
Classification Task의 종류에는 두 가지가 있습니다. 바로 이항분류와 다항분류입니다.두 가지 Classification에 각각 어떤 Task 예시가 있는지, 차이점은 무엇인지 적어주세요. 또한 현실에서는 둘 중에 어떤 분류가 더 많이 쓰이는 것 같은지 자
11.#11 ROC & AUROC
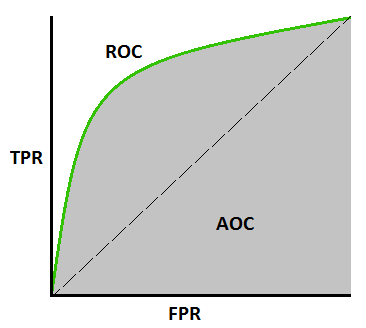
Classification model의 y값은 '?' 값이다. 모델의 결과물을 binary한 결과값 y^로 제시하기 위해서 0과 1 사이의 일정한 기준값(Threshold)를 지정한다.ROC, AUROC는 분류모델의 평가지표입니다. 이 분류지표는 어떤 원리로 작동하는
12.#12 Logistic Regression
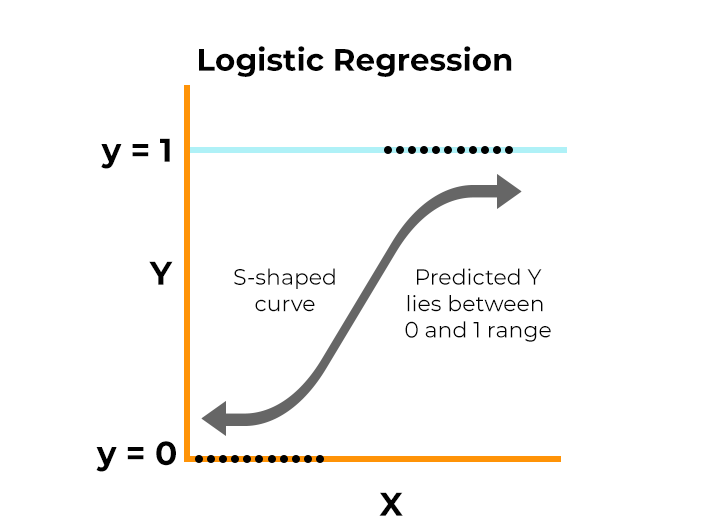
로지스틱 회귀는 선형 회귀 방식을 분류에 적용한 알고리즘사건이 일어나고(1) 일어나지 않고(0)를 예측하는 것이 로지스틱 회귀 모델의 목표<예시>화재가 발생했을 때, 산소가 X만큼 부족해지면 '사망한다 or 사망하지 않는다.'교통사고가 발생했을 때, 충격량이 X일
13.#13 Softmax Function
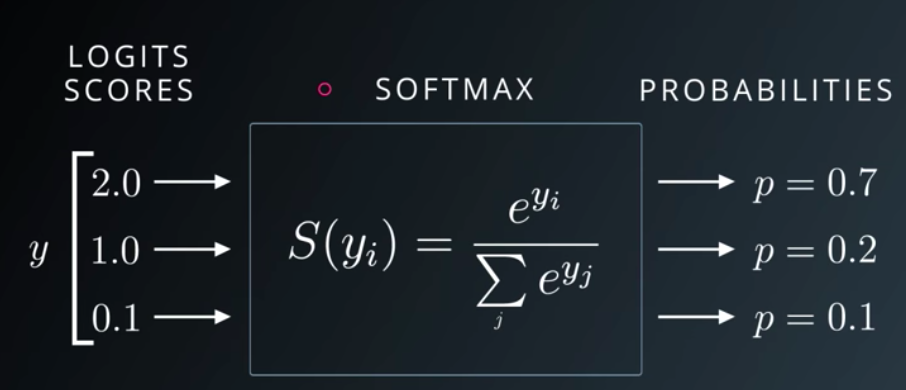
아래의 그림처럼 class가 여러 개 있을 때 예측하는 Multinomial Classification 중,행렬 계산을 통해 각 클래스 별로 분류를 진행한다.계산을 통해 나온 결과값을 Softmax Function 를 거쳐, 아래의 그림처럼 0과 1 사이의 확률 값으로
14.#14 Cross Entropy
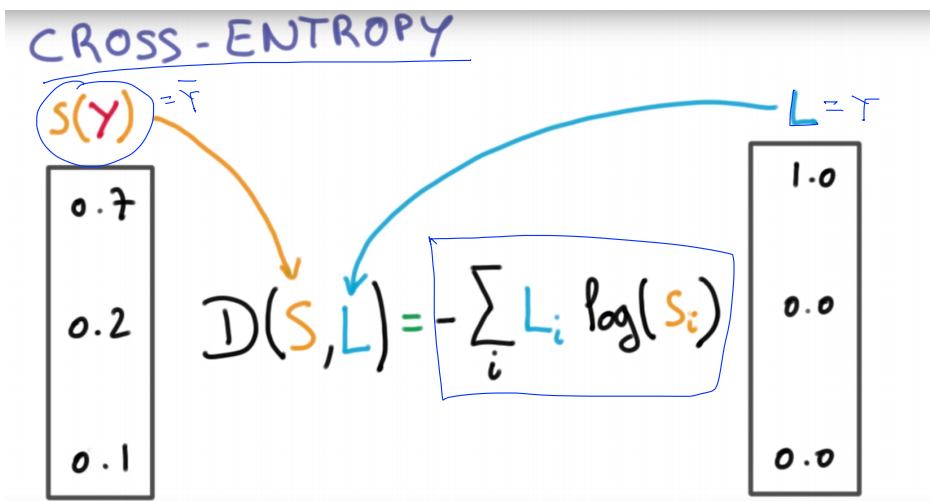
앞에서 살펴봐왔던 Classification 이라는 지도학습을 통해, 모델이 예측한 클래스가 라벨링 되었다면, 이를 기반으로 모델이 잘 예측했는 지에 대해 Cost Function (Loss 함수)을 정의해 평가를 해준다.Cost function = (sotmax가 예
15.#15 Generalization, Normalization, Standardization
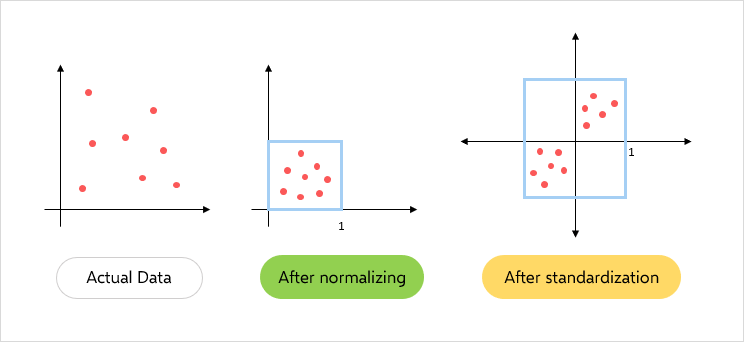
데이터 스케일링(Feature Scaling)이란 데이터 전처리 과정의 하나이며, 굉장히 중요한 과정.서로 각기 다른 변수들의 범위 혹은 분포를 일정한 수준으로 같게 만드는 작업.이를 통해 각 변수들이 동일한 조건(혹은 범위)을 가지게 되어, 이 변수들에 대한 상대 비
16.#16 Regularization :: L1 & L2 수식의 이해
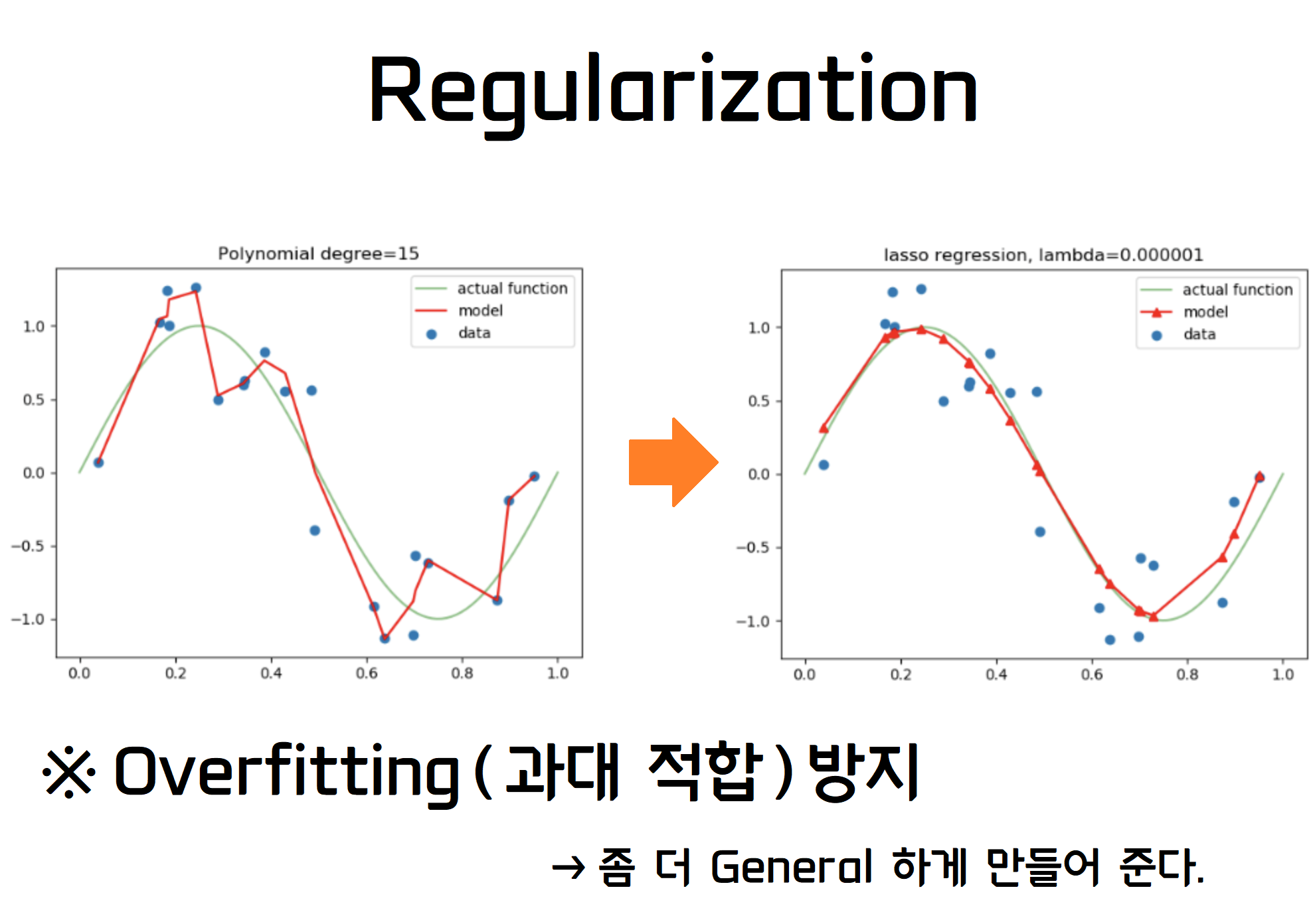
Regularization에 대한 L1, L2에 대한 이해
17.#17 SVM 개론
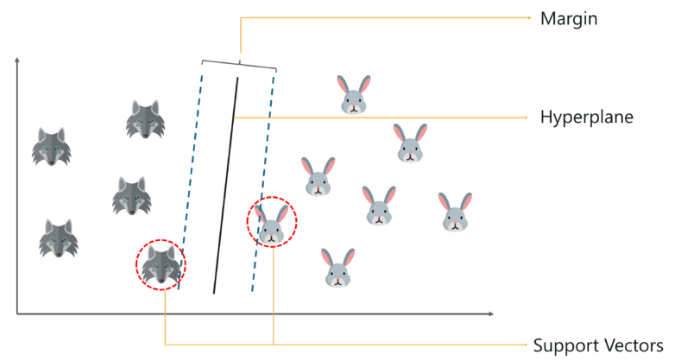
결정 경계(Decision Boundary), 즉 분류를 위한 기준 선을 정의하는 모델. 분류되지 않은 새로운 점이 나타나면 경계의 어느 쪽에 속하는지 확인해서 분류 과제를 수행할 수 있게 된다.분류에 사용되는 지도학습 머신러닝 모델.1) 마진을 극대화하는 최적의 Hy
18.#18 SVM & Feature Scaling
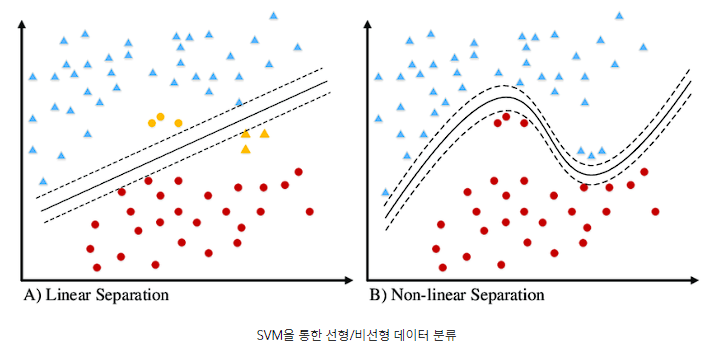
SVM은 입력 데이터 Feature 스케일링(scaling)이 매우 중요합니다. 그 이유에 무엇인지 서술하고, 이에 더해 SVM 커널 함수가 어떤 역할을 하는지 적어주세요. 구글링 키워드 : 선형SVM, 비선형 SVM, SVM 커널 함수 Feature Scaling
19.#19 Ensemble
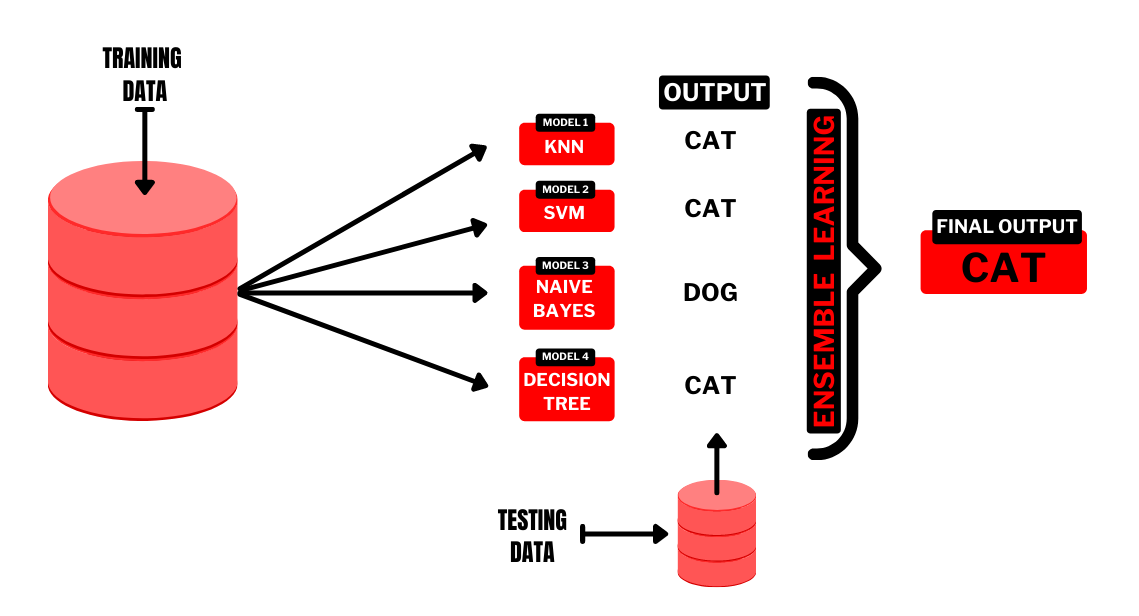
Ensemble 에 대한 이해
20.#20 Gradient Boost
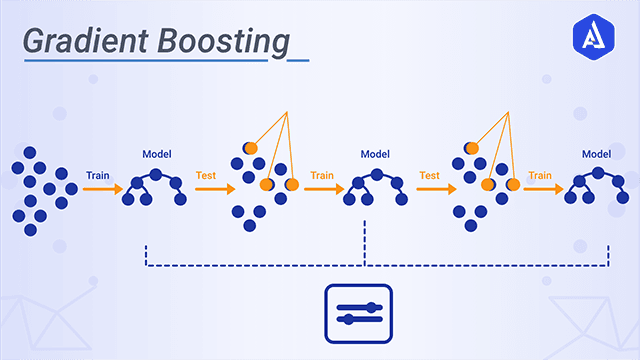
여러 개의 약한 학습기(weak learner)를 순차적으로 학습/예측하며 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식.실제 값들의 평균과 실제 값의 차이residual에 fitting해서 다음 모델을 순차적으로 만들어 나가는 것→ n
21.#21 Boosting
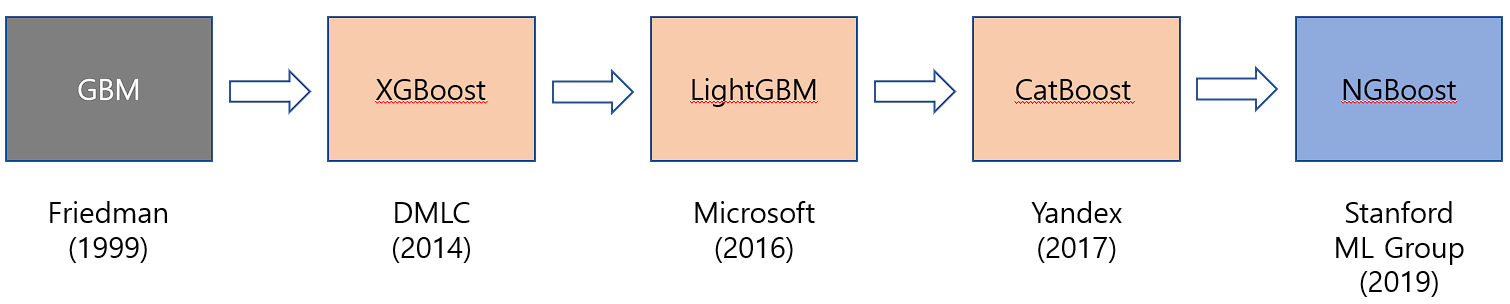
실제로 캐글에서는 XGboost라는 라이브러리를 사용한 대회 참여나 다양한 시도들이 이루어지고 있습니다. 자매품으로는 Catboost나 조금 더 가벼운 앙상블 모델인 LightGBM이 있습니다. Kaggle의 마음에 드는 대회에 들어가, XGboost 혹은 Catbo
22.#22 차원의 저주
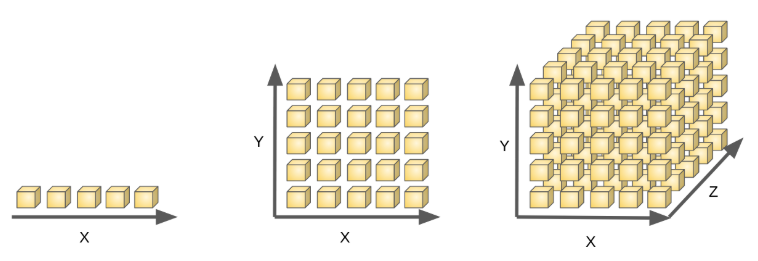
고차원 공간에 있는 데이터를 분석할 때 발생하는 여러 가지 현상.차원 = 변수의 수 = 축의 개수 → 차원이 늘어난다 = 변수(Feature)의 수가 많아진다 = 축의 개수가 많아진다 = 데이터의 공간이 커진다 = 이를 채우기 위한 데이터 건수도 증가 차원이 커짐에
23.#23 PCA & LDA
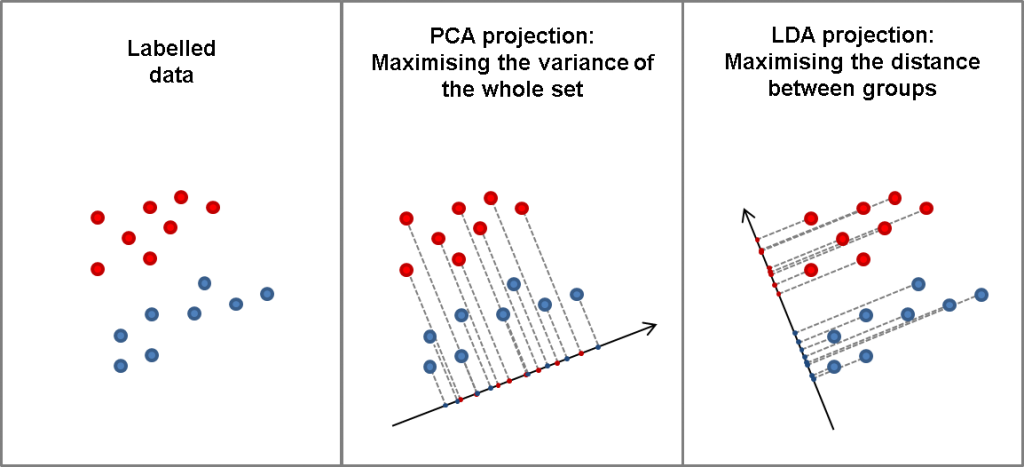
데이터셋에 대해 이야기 할 때, 차원이란 feature와 동의어입니다. 차원 축소의 기법인 PCA 와 LDA에 대해 공부하고, 두 방식의 공통점과 차이점에 대해 서술하세요. 구글링 키워드 : 머신러닝 PCA, 머신러닝 LDA, 주성분 분석, 선형 판별 분석 PCA
24.#24 SVD
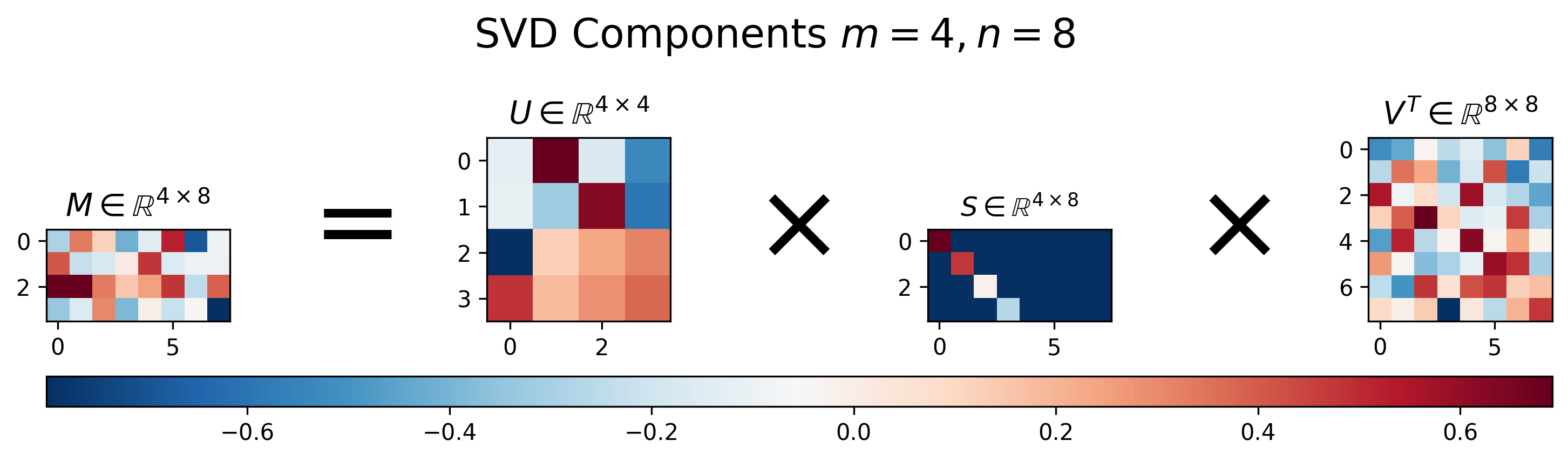
앞에서 살펴봤던 LDA는 이전 LSA의 단점을 개선하고 보완하여 나온 알고리즘이다.그렇다면, LSA는 무엇인지 앞서 간단하게 설명하고자 한다.잠재 의미 분석(LSA), 이는 Topic Modeling 과정에서 쓰이는 기법이다.기본적으로 단어의 빈도 수를 이용한 수치화
25.#25 PCA vs SVD
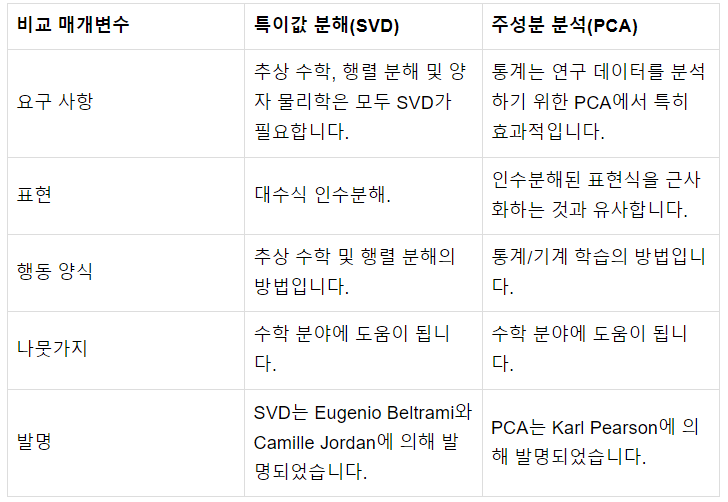
SVD를 이용한 차원 축소는 데이터를 개별적으로 압축하지만, PCA는 데이터를 집합적으로 압축한다. SVD는 수학적 알고리즘, PCA는 통계 기법 SVD는 데이터 기반 푸리에 변환 일반화인 반면, PCA를 사용하면 데이터를 기반으로 하는 계층적 좌표 시스템을 사용하
26.#26 Optimization
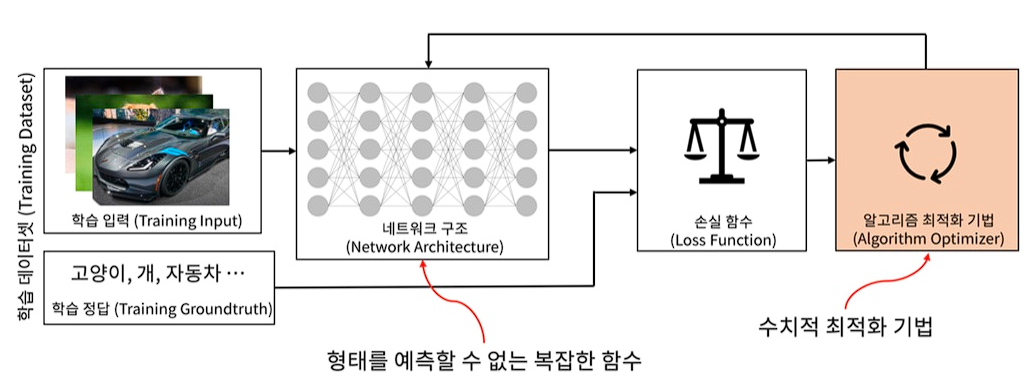
경사하강법이란 ML의 optimization 방법 중 하나입니다. optimization이 무엇인지 개념을 설명할 수 없다면 우선 이 개념부터 정리한 후 아래 미션을 진행하세요. Gradient Descent Algorithm는 비용 함수(Cost Function)의
27.#27 Gradient Descent (경사 하강법)
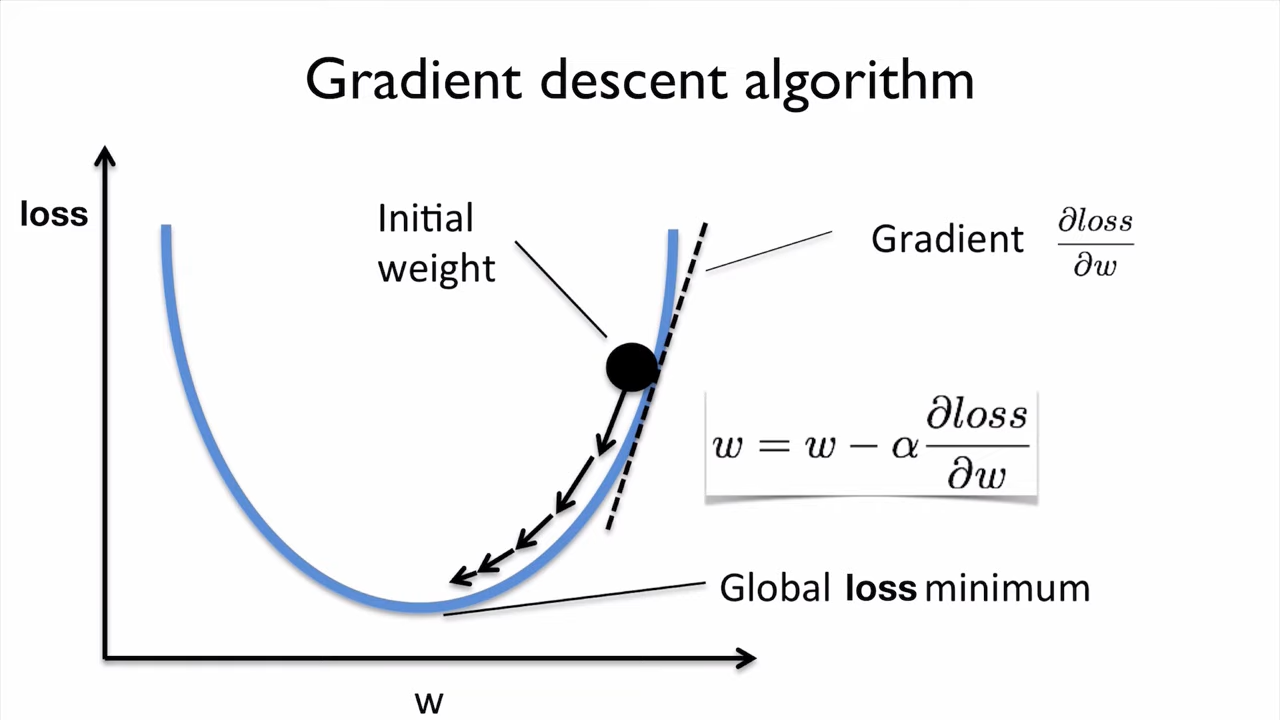
함수 값이 낮아지는 방향으로 이동하며 최솟값을 탐색하는 방식→ 아무 것도 보이지 않는 산에서 낮아지는 방향으로 이동하여 한 발자국 씩 산을 내려가는 방법.기울기가 양수: x가 커질수록 값이 커짐기울기가 음수: x가 커질수록 값이 작아짐기울기 부호의 반대로 움직여야 최솟
28.#28 Learning Rate (학습률)
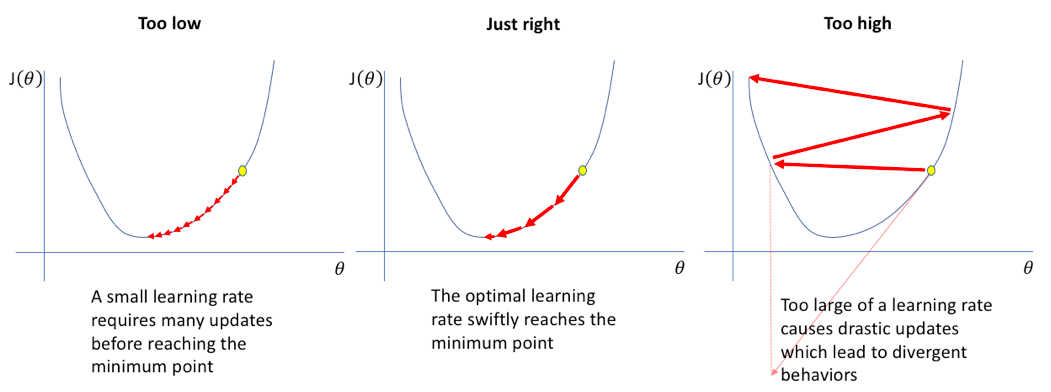
현재 네트워크의 weight에서 내가 가진 데이터를 다 넣어주면 전체 에러(Cost Function)가 계산된다.미분을 하면 에러를 줄이는 방향을 알 수 있다.그 방향으로 정해진 스텝량(learning rate)을 곱해서 weight을 이동시킨다.계속 반복해서 학습.G
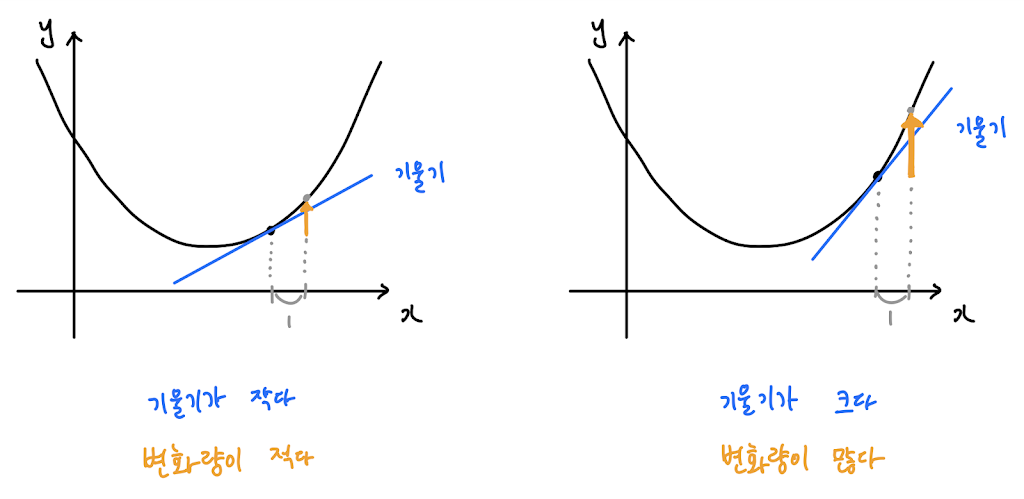
29.#29 Derivative Term
경사 하강 알고리즘의 수렴 조건(종료 조건)이 무엇일까요? 이 물음에 답할 수 있나요? 경사 하강 알고리즘은 갱신 직전 값과 갱신 값이 같을 때 종료됩니다. (종료하는 것이 좋습니다 - early stopping) [ 미적분적 개념을 참조하자면, 함수는 극점에서의 기