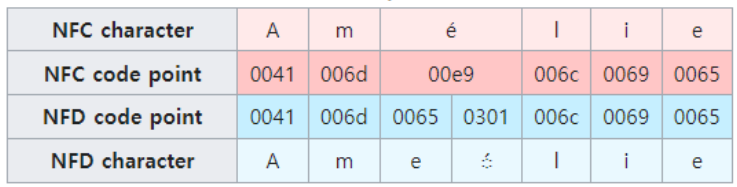
유니코드 정규화(Unicode Normalization)
ASCII (아스키 코드)
- 가장 처음 만들어진 인코딩
- 128개의 문자조합을 제공하는 7비트(1비트는 통신 에러 검출용) 부호
- 기술과 통신의 발달로 범국가적으로 정의할 인코딩의 필요성에 의해 도태됨.
ord('엄')50628Unicode(유니 코드)
- 각 나라별 언어를 모두 표현하기 위해 나온 코드 체계
- 사용 중인 운영체제, 프로그램, 언어에 영향을 받지 않음
- 문자마다 고유한 코드 값을 제공하는 새로운 개념의 코드
- 가장 많이 쓰이는 'UTF-8(가변 길이 인코딩)'
chr(50628)'엄'unicodedata
파이썬으로 텍스트 전처리를 하다가 정규식으로 한글 영어만 추출할 때, 가끔 데이터가 None이 되는 경우가 많이 발생한다.
그런 경우에는 대부분 같은 문자이지만 아스키 코드가 달라서 발생하는 문제들이다.
이런 이슈(오류)들을 피하기 위해서 유니코드 정규화(unicodedata.normalize)를 해야 한다.
import unicodedata
unicodedata.normalize('NFC', '안녕')'안녕'- NFC 이외에도 NFD, NFKC, NFKD 네가지 방식이 있다.
자세한 건 아래 링크 참조.
https://towardsdatascience.com/difference-between-nfd-nfc-nfkd-and-nfkc-explained-with-python-code-e2631f96ae6c
unicodedata.category(chr):
chr 문자에 할당된 일반 범주(general category)를 문자열로 반환.
Mn: Mark, no spacing(발음구별기호)LI: Letter, lower caseLu: Letter, upper case
unicodedata.category('c')'Ll'unicodedata.category('C')'Lu'