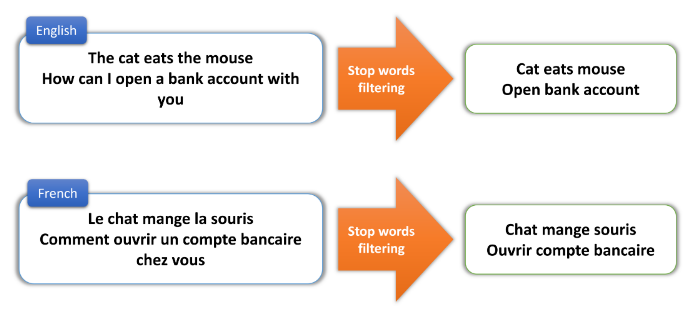
텍스트 전처리(Text Preprocessing)
Cleaning(정제)
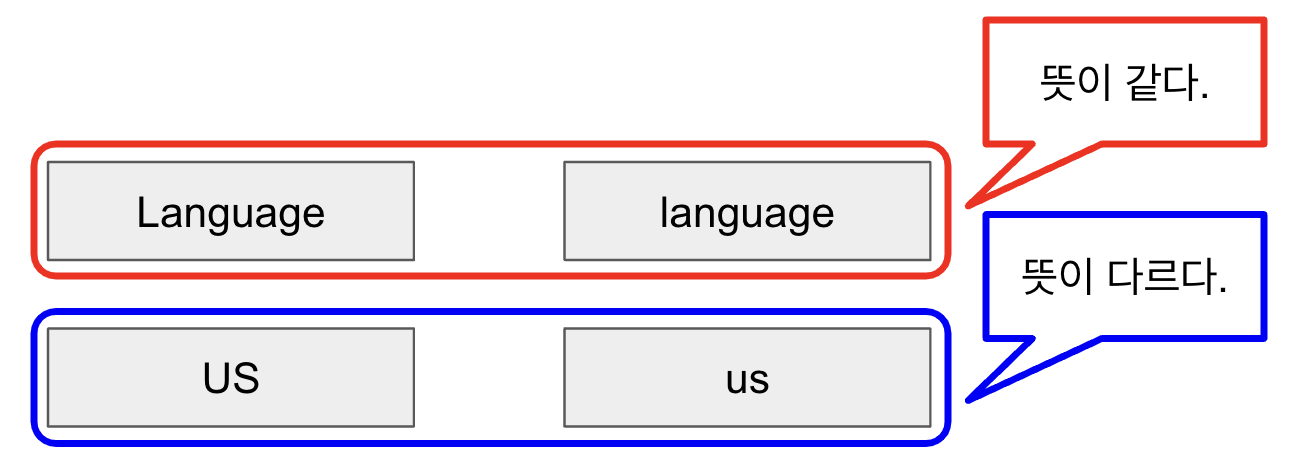
- 대문자 vs 소문자 처리
뜻이 같은 경우에는 대문자를 소문자로 변경하는 것이 맞지만,
다르다면 변경하지 말아야 한다.
- 출현 횟수가 적은 단어의 제거
- animals(동물) vs faunas(동물군)에서 와 같이 사용횟수가 적은 단어들을 제거.
- 다만, 이때도 출현 횟수가 적지만, 중요한 단어인 경우에는 제거 금지.
- 데이터 사용 목적에 맞추어 노이즈를 제거
- 관사, 대명사 등 의미를 부여할 수 없는 글자들을 제거.
Steamming (추출)
어간 추출
- 어간(Stem): 단어의 의미를 담은 핵심
- 접사(Affix): 단어에 추가 용법을 부여
- playing -> play(어간) + ing(접사)
- lectures -> lecture(어간) + s(접사)
- kindness -> kind(어간) + ness(접사)
표제어 추출
표제어(lemmatization)는 문장에서의 단어의 원형
- is, are -> be
- having -> have
어간 추출 vs 표제어 추출
- 표제어 추출은 단어의 품사 정보를 포함하고 있음
- 어간 추출은 품사 정보를 갖고 있지 않음
예시 1)
- having -> hav (어간 추출) / have (표제어 추출)
- is -> is (어간 추출) / be (표제어 추출)
예시 2)
- bear는 명사일 때는, '곰'이라는 뜻으로 사용하지만,
동사일 때는, '견디다'와 같이 다른 뜻으로 사용될 수 있음.- 이렇게 품사에 따라 뜻이 달라지는 단어들은 표제어 추출을 해야 함.
Stopword(불용어)
- 갖고 있는 데이터에서 유의미한 단어 토큰만을 선별하기 위해서는 큰 의미가 없는 단어 토큰을 제거하는 작업이 필요
- 여기서 큰 의미가 없다라는 것은 자주 등장하지만 분석을 하는 것에 있어서는 큰 도움이 되지 않는 단어들을 뜻함