텍스트 전처리(Text Preprocessing)

Tokenization(토큰화)
- 주어진 문장에서 "의미 부여"가 가능한 단위를 찾는다.
- 토큰화는 형태소 분석기를 이용하여 진행된다.
다만, 각 형태소 분석기마다 토큰화를 하는 방식이 다르기 때문에,
사용하는 데이터(또는 목젝어)에 맞는 형태소 분석기를 찾아서 사용해야 한다.
Token(토큰)
우리는 각 문자가 무엇을 나타내는지 , 그리고 모든 문자가 어떻게 모여 문장의 단어를 형성하는지 이해한다.
그러나 컴퓨터 자체로는 그러한 이해가 없으며, 신경망은 훈련 중에 의미를 학습해야 한다.
따라서 텍스트를 표현할 때 다양한 접근 방식을 사용할 수 있다.
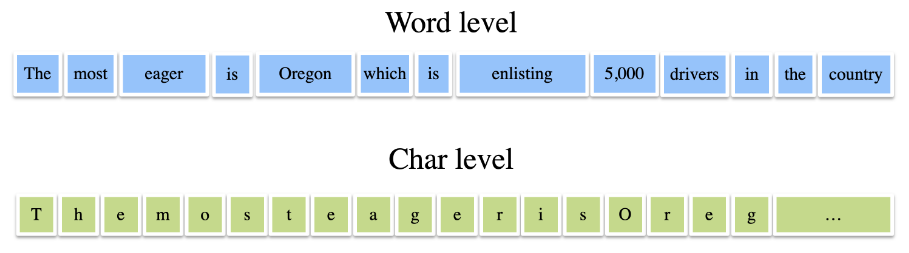
- 문자(글자) 수준 표현(Character-level representation)
예) "토끼 안녕"은 "토", "끼", "안", "녕"으로 구분할 수 있다.
- 단어 수준 표현(Word-level representation)
예) "토끼 안녕"은 "토끼", "안녕"으로 구분할 수 있다.
이러한 접근 방식을 통합하기 위해 일반적으로 텍스트의 원자 조각을 토큰이라고 한다.
이렇게 텍스트를 일련의 토큰으로 변환하는 프로세스를 토큰화라고 한다.
다음으로 각 토큰을 신경망에 공급할 수 있는 숫자에 할당해야 한다.
이를 벡터화라고 하며, 일반적으로 토큰 어휘를 구축하여 수행된다.
이런 벡터화의 과정을 Word Embedding이라고 한다.
※ 정리
토큰화로, 전처리된 자연어들에 고유 토큰을 부여하는 작업을 한 뒤,
벡터화를 통해, 컴퓨터의 연산을 위한 torch 형식으로 인코딩을 진행. (Embedding)
