이 글은 권철민님의 강의와 MMDetection의 공식 Documentation및 논문을 참고하였습니다.
기본적으로 논문에 기반하여 공부한 후 코드 리뷰를 작성해 볼 예정입니다.
최선을 다해 자세하게 적었습니다. 궁금하신 점 및 피드백은 언제든 환영입니다.
Abstract
MMDetection은 2018년 COCO track detection 대회에서 우승한 MMDet팀에서 시작했습니다.
그 이후로 점진적으로 발전해가고 있으며, 현재는 가장 인기있는 detection toolbox로 성장했습니다.
MMDetection은 200개가 넘는 model에 대한 weights를 제공하며 training과 inference에 대한 코드도 제공합니다. 우리는 이런 MMDetection을 연구하며 benchmark도 진행 할 생각입니다.
MMDetection과 이 Benchmark가 커뮤니티를 성장시켰으면 좋겠습니다.
1. Introduction
ObjectDetection과 Instace-Segmentation은 컴퓨터 비전에서 기본적인 과제입니다.
이전 Classification에 비해 더 복잡한 구성을 가지고 있으며, 설정에 따라 상이한 결과가 나오기 마련입니다.
높은 퀄리티와 통일된 benchmark라는 목표를 위해 우리는 Pytorch기반 MMDetection을 만들었습니다.
MMDetection의 주요한 특징은 다음과 같습니다.
(1). Modular design
우리는 detection framework를 서로 다른 module로 분해했고, 사용자는 module을 이용해 object detection을 쉽게 커스터마이징 할 수 있습니다.
(2). Support of multiple frameworks out of box
MMDetection은 다양한 detection-frameworks를 지원합니다.
(3). High efficiency
모든 bbox, mask operation은 GPU기반에서 작동됩니다. 학습 속도는 다른 tool, framework에 비해 더 빠릅니다.
(4). State of the art
우리는 지속적으로 업데이트를 진행합니다.
2. Supported Frameworks
MMDetection은 아래와 같이 다양한 methods를 지원합니다.

MMDetection은 많은 methods를 지원함과 동시에 다른 codebases와 비교해 아래와 같은 Table을 제시합니다.
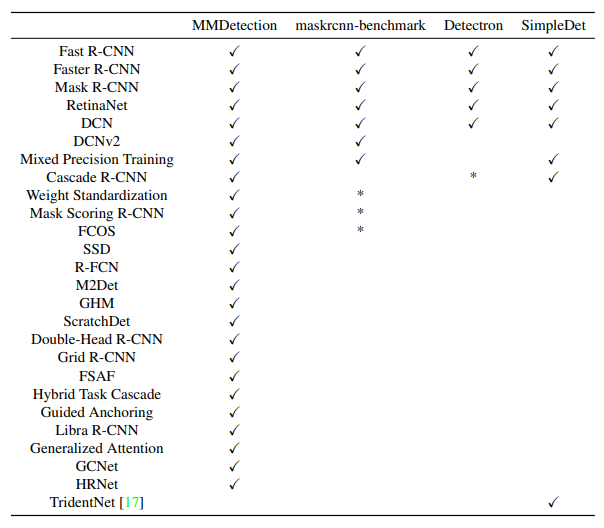
3. Architecture
✔ Model Representation
다양한 detector모델은 각 모델마다 다르지만, 공통적인 요소들이 있습니다.
(1). Backbone
ResNet-50과 같은 Backbone은 들어온 이미지에 대해 피처맵(feature map)을 추출해주는 역할을 합니다.
(2). Neck
Neck은 Backbone과 Head를 이어주는 역할을 합니다. Backbone에서 나온 피처맵을 다시 재가공해줍니다. 예를들어 FPN이 있습니다.
(3). DenseHead
DenseHead는 피처맵의 dense location에서 작동하는 부분입니다. 대표적으로 RPN-Head가 있습니다.
(4). RoIExtractor
RoIExtractor는 피처맵에서 RoI-wise features를 추출하는 부분입니다.(RoI정보를 추출하는 부분)
(5). RoIHead
RoI정보를 기반으로 Object의 classification과 regression을 진행하는 부분입니다.
이렇게 위의 주요 요소들을 재구성하고 새로 만듬으로써 single-stage-detection, two-stage-detection을 만들 수 있습니다.
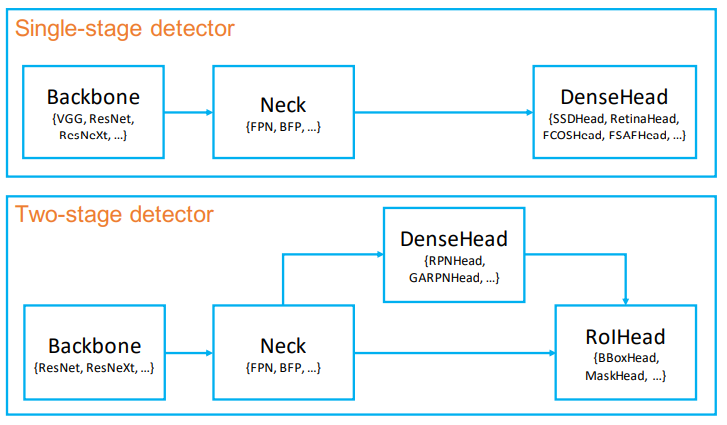
논문에서는 위 그림을 제시하면서 기본적인 model architecture를 제안했습니다.
Two-stage-detector를 보면 ①DenseHead와 RoIHead가 최종적으로 합쳐지는 것을 볼 수 있고, ②RoIExtractor가 명시되지 않은 것을 볼 수 있습니다.
추측하건데,
①. Object에 대한 Classification과 Regression은 RoIHead에서 진행되고, DenseHead에서는 RoIHead에서 필요한 location을 추출해주는 역할을 하는 것 같습니다.
②. RoIExtractor는 DenseHead에 포함되는 관계이거나 RoIHead에 포함되는 관계일 것 같습니다.
✔ Training Pipeline
우리는 유동적인 Training Pipeline을 hooking mechanism을 이용해 구성합니다.
이러한 Pipeline은 다른 컴퓨터비전 방식에서도 쓰이는 방식입니다.
많은 Training precess는 비슷한 형태로 작동합니다.
(논문에서 training, validation도 모두 비슷하게 작동한다고 합니다. 다만, validation은 선택적(optional)이라고 합니다.)
참고로 hooking mechanism은 특정 이벤트가 발생했을 때 설정해둔 함수가 자동으로 실행되도록 하는 것입니다.
논문에서는 hooking timepoint를 아래와 같이 10개로 정의했습니다.
"users may register any executable methods (hooks), including before run, before train epoch, after train epoch, before train iter, after train iter, before val epoch, after val epoch, before val iter, after val iter, after run."
이렇게 설정된 hook은 특정 시점에 우선적으로 발생됩니다.
전형적으로 MMDetection에서는 아래와 같이 pipeline이 작동한다고 합니다.
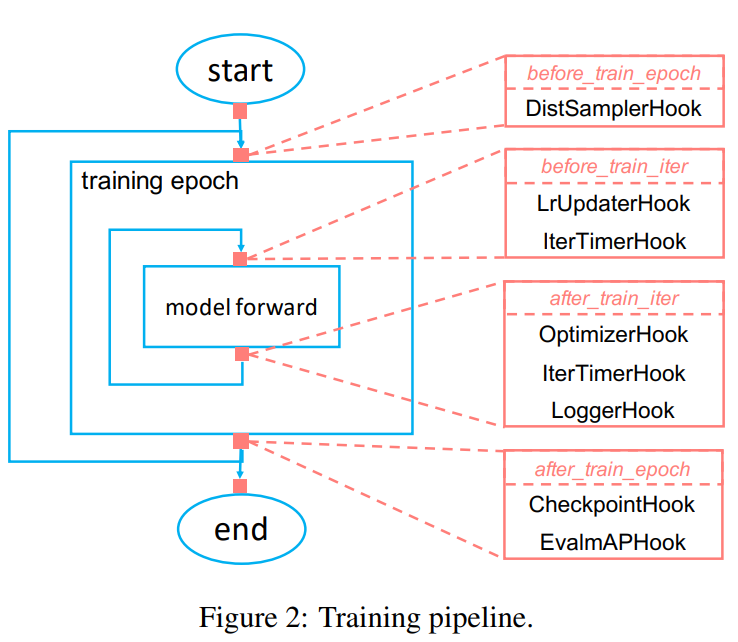
Validation Pipeline도 Training Pipeline과 같다고 합니다.
논문에서는 Validation 데이터는 test로 쓰기 때문에 따로 사용하진 않았다고 합니다.
4. Benchmarks
Benchmark란, 특정 소프트웨어나 하드웨어를 기준에 맞추어 성능을 평가하는 것을 의미합니다.
논문에서는 MMDetection의 성능을 평가하고자 Benchmarks라는 Session을 따로 만들었습니다.
✔ Experimental Setting
(1). Dataset
MMDetection을 벤치마크(Benchmark)하기 위해 Dataset은 MS COCO 2017을 적용합니다.
학습은 train dataset을 이용하며, 성능 평가는 val dataset을 이용하겠습니다.
(2). Implementation details
별다른 언급이 없으면 이미지는 1333X800 사이즈로 resize합니다.
학습과 추론을 위해서 V100 GPU를 이용했습니다. 학습을 위해서는 8 V100 GPU를, 추론을 위해서는 Single V100 GPU.(schdule은 detectron과 동일합니다.)
(3). Evaluation metrics
평가는 MS COCO방식을 그대로 따라갑니다. IoU threshold를 0.5-0.95로 올려가며 평균을 낸 값을 metric으로 이용합니다. 이를 mAP라고 합니다.
✔ Benchmarking Results
우리는 MMDetection을 성능, 속도, 메모리적인 부분에서 Detectron, maskrcnn-benchmark, SimpleDet과 비교합니다.
공정한 성능비교를 위해 위 Codebases와 같은 환경을 구성했습니다.
아래는 각각 MMDetection에서 모델별 성능/fps, GPU에 따른 fps 그리고 다른 tool에 비교했을 때 성능, 속도, 메모리 사용량입니다.
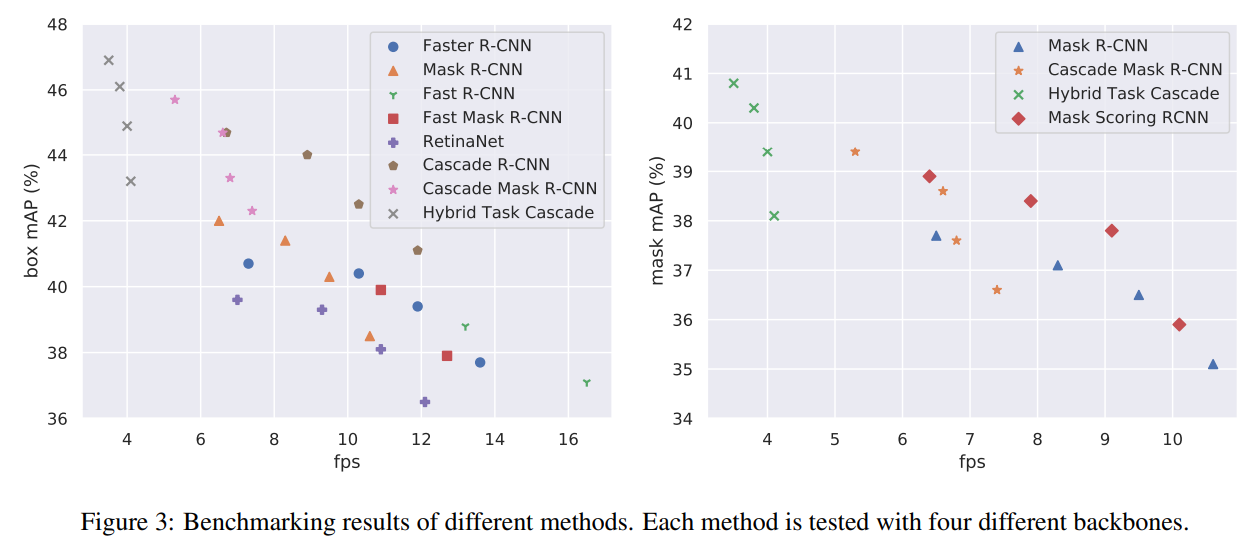
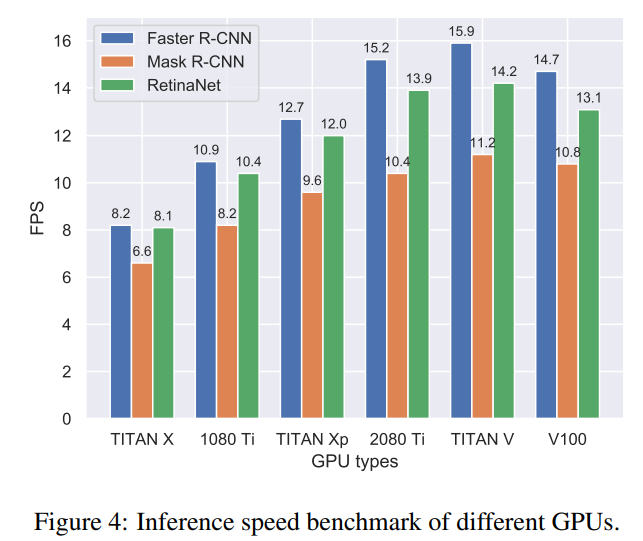
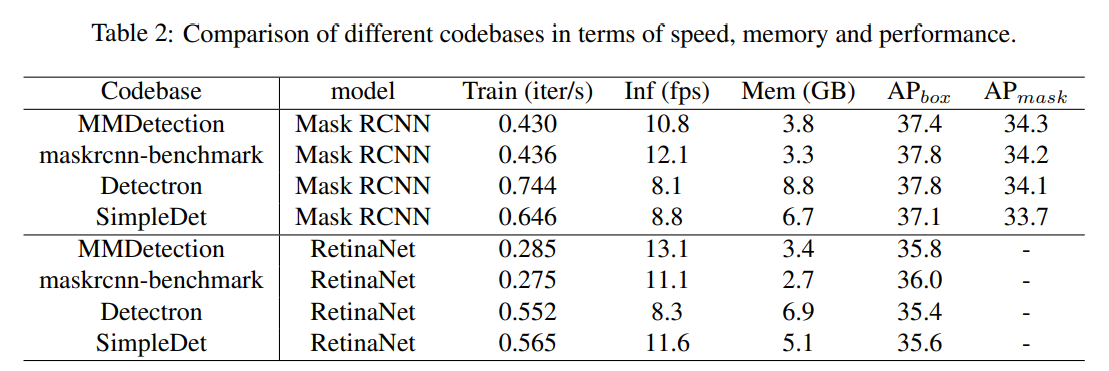
논문에서는 MMDetection이 훌륭한 Object Detection tool인지 보여줍니다.
본 장에서는 논문의 "5. Extensive Studies"를 다루지는 않았지만 관심이 있으시면 더 보시는 것도 괜찮을 것 같습니다.
논문에서 크게 얻어갈 것은 두 가지인 것 같습니다.
①. MMDetection에서 사용하는 Model Architecture를 알 수 있다.
②. MMDetection pipeline의 작동원리를 알 수 있다.
5. MMDetection Code
이제 이렇게 알아본 MMDetection을 활용해 볼 차례입니다.
우선, 활용된 버전은 2.xx버전임을 명시하겠습니다.
✅ Basic inference
우선, 모델이 이미 학습 되어있다고 생각하고 모델을 가져오고 추론하는 방법입니다.
✔ Architecture
pretrained된 모델을 활용하는 방법은 간단합니다.
아래는 MMDetection에서 pretrained된 모델을 가져와 추론하는 과정을 나타낸 것입니다.
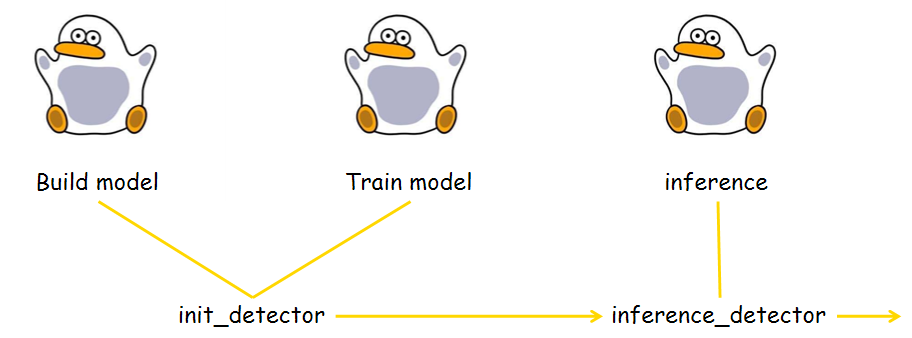
✔ init_detector
mmdet.apis 모듈의 init_detector와 inference_detector를 이용하면 mmdetection에서 pre-trained된 model을 가지고 와 추론까지 진행 할 수 있습니다.
from mmdet.apis import init_detector, inference_detector
model = init_detector(config_file, checkpoint_file, device='cuda:0')이때 init_detector에는 config_file과 checkpoint_file이 들어가게 됩니다.
당연히 사용하려는 모델에 맞게 config_file과 checkpoint_file을 가져와야합니다.
config_file은 기본적으로 mmdetection에 내장되어있고 checkpoint_file은 따로 다운을 받아줘야 합니다.
원하는 모델의 checkpoint file경로는 mmdetection 공식 깃허브에 나와있습니다.
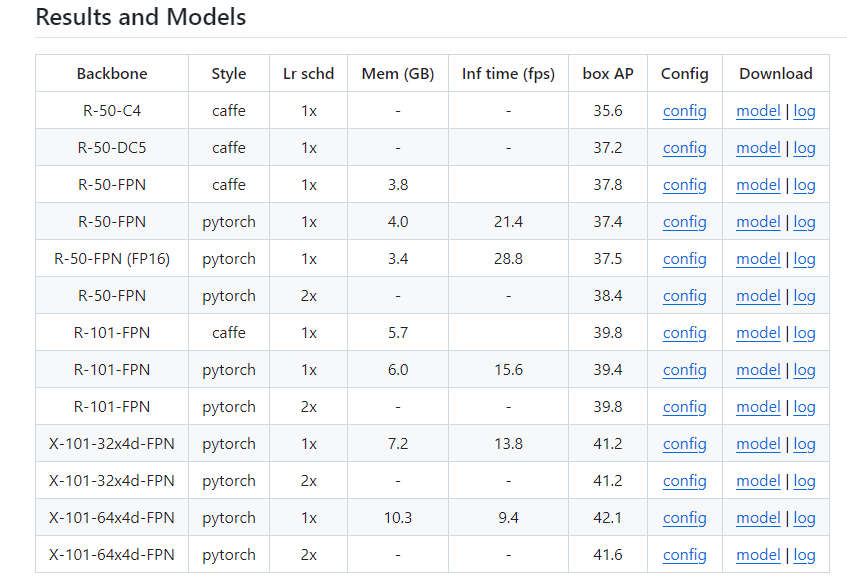
위는 faster-rcnn을 예시로 든 것입니다.
✔ inference_detector
이렇게 model을 만들어주면 inference_detector를 이용해 model을 넣어주고 image 경로를 넣어주면 result값이 반환됩니다. results는 리스트 형태로 반환되고, 학습된 데이터의 label 수 만큼의 길이를 가지며 각 리스트는 예측한 object의 수만큼의 길이를 가집니다.
그리고 results의 가장 안쪽 리스트는 inference_score, xmin, ymin, xmax, ymax로 길이가 5입니다.(빈 리스트 제외)
results = inference_detector(model, image_path)result 형태는 다음 형태와 같습니다.
[[
[inference_score, xmin, ymin, xmax, ymax],
[inference_score, xmin, ymin, xmax, ymax]
],
[
],
[
[inference_score, xmin, ymin, xmax, ymax],
[inference_score, xmin, ymin, xmax, ymax],
[inference_score, xmin, ymin, xmax, ymax],
[inference_score, xmin, ymin, xmax, ymax]
],
.
.
.
[]
]✔ show_result_pyplot
이렇게 추론된 데이터를 이미지에 한번에 나타내려면 show_result_pyplot을 이용하면 됩니다.
show_result_pyplot에는 학습된 model(여기서는 pre-trained-model), 추론한 image 경로, 모델이 예측한 results를 넣어주면 됩니다. 이때 show_result_pyplot의 threshold는 0.3으로 설정되어있으므로 inference_score가 0.3 이상인 값들만 이미지에 나타내줍니다. 따로 설정하고싶으면 score_thr를 설정해주면 됩니다.
from mmdet.apis import show_result_pyplot
show_result_pyplot(model, image_path, results)
✅ CustomDataset inference
앞에서 mmdetection에서 기본적으로 제공되는 API를 이용해 모델을 불러오고 추론하고, 결과를 이미지에 나타내는 방법까지 알아봤습니다.
이 방식은 누구나 간단하게 모델을 이용할 수 있다는 장점이 있지만, 자신이 원하는 데이터에 맞추어 원하는 카테고리를 모델이 예측하도록 하기는 어렵습니다.
따라서 이번에는 직접 CustomDataset을 만들어 원하는 카테고리에 모델을 학습시키는 방법을 알아보겠습니다.
✔ Architecture
저희가 원하는 카테고리를 학습시킬 때 앞선 방법처럼 간단하면 좋겠지만, 상대적으로 더 복잡할 수밖에 없습니다.
아래는 직접 CustomDataset을 만들어 원하는 카테고리에 모델을 학습시키는 architecture입니다.
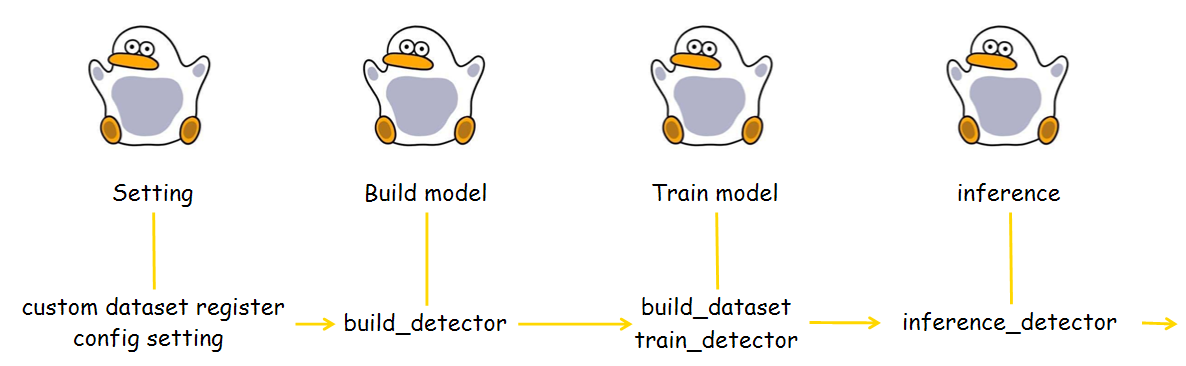
setting부분이 이번 장의 핵심입니다.
✔ Setting
모델을 구현하기에 앞서 custom dataset을 DATASET에 등록해줘야 합니다.
데이터셋을 MMDetection에서 원하는 format으로 바꿔주는 과정입니다.
MMDetection에서 데이터는 middle format이라고 가정합니다.

middle format은 리스트 안에 각 이미지에 대한 정보를 딕셔너리로 가진 형태입니다.
즉, 하나의 딕셔너리에 하나의 이미지 정보가 있습니다. 또한 하나의 딕셔너리에는 filename, width, height, ann이라는 정보가 있으며 ann이라는 딕셔너리는 bbox와 label에 대한 정보가 들어있습니다.
(ann에는 사용자가 모델에 학습시키고자 하는 label이 있는 경우 bboxes,labels에 저장이 되며 아닌 경우 ignore에 들어가게 됩니다.)
-
filename : 이미지가 들어있는 파일 이름입니다. 주의할 점은 경로가 아닌 파일 이름이라는 점입니다.
-
width / height : 이미지의 가로,세로 길이입니다.
-
bboxes : bbox 정보입니다. (n, 4) shape 형태를 띄며, 각각 xmin, ymin, xmax, ymax 정보를 가집니다.
-
labels : bbox 정보와 연결되는 label 정보입니다. (n,) shape 형태를 가집니다.
-
ignore : 무시되는 부분입니다.
middle format으로 변경하는 코드는 다음과 같습니다.
import copy
import os.path as osp
import cv2
import mmcv
import numpy as np
from mmdet.datasets.builder import DATASETS
from mmdet.datasets.custom import CustomDataset
# 반드시 아래 Decorator 설정 할것.@DATASETS.register_module() 설정 시 force=True를 입력하지 않으면 Dataset 재등록 불가.
@DATASETS.register_module(force=True)
class KittyTinyDataset(CustomDataset):
CLASSES = ('Car', 'Truck', 'Pedestrian', 'Cyclist')
##### self.data_root: /content/kitti_tiny/ self.ann_file: /content/kitti_tiny/train.txt self.img_prefix: /content/kitti_tiny/training/image_2
#### ann_file: /content/kitti_tiny/train.txt
# annotation에 대한 모든 파일명을 가지고 있는 텍스트 파일을 __init__(self, ann_file)로 입력 받고, 이 self.ann_file이 load_annotations()의 인자로 입력
def load_annotations(self, ann_file):
print('##### self.data_root:', self.data_root, 'self.ann_file:', self.ann_file, 'self.img_prefix:', self.img_prefix)
print('#### ann_file:', ann_file)
cat2label = {k:i for i, k in enumerate(self.CLASSES)}
image_list = mmcv.list_from_file(self.ann_file)
# 포맷 중립 데이터를 담을 list 객체
data_infos = []
for image_id in image_list:
filename = '{0:}/{1:}.jpeg'.format(self.img_prefix, image_id)
# 원본 이미지의 너비, 높이를 image를 직접 로드하여 구함.
image = cv2.imread(filename)
height, width = image.shape[:2]
# 개별 image의 annotation 정보 저장용 Dict 생성. key값 filename 에는 image의 파일명만 들어감(디렉토리는 제외)
data_info = {'filename': str(image_id) + '.jpeg',
'width': width, 'height': height}
# 개별 annotation이 있는 서브 디렉토리의 prefix 변환.
label_prefix = self.img_prefix.replace('image_2', 'label_2')
# 개별 annotation 파일을 1개 line 씩 읽어서 list 로드
lines = mmcv.list_from_file(osp.join(label_prefix, str(image_id)+'.txt'))
# 전체 lines를 개별 line별 공백 레벨로 parsing 하여 다시 list로 저장. content는 list의 list형태임.
# ann 정보는 numpy array로 저장되나 텍스트 처리나 데이터 가공이 list 가 편하므로 일차적으로 list로 변환 수행.
content = [line.strip().split(' ') for line in lines]
# 오브젝트의 클래스명은 bbox_names로 저장.
bbox_names = [x[0] for x in content]
# bbox 좌표를 저장
bboxes = [ [float(info) for info in x[4:8]] for x in content]
# 클래스명이 해당 사항이 없는 대상 Filtering out, 'DontCare'sms ignore로 별도 저장.
gt_bboxes = []
gt_labels = []
gt_bboxes_ignore = []
gt_labels_ignore = []
for bbox_name, bbox in zip(bbox_names, bboxes):
# 만약 bbox_name이 클래스명에 해당 되면, gt_bboxes와 gt_labels에 추가, 그렇지 않으면 gt_bboxes_ignore, gt_labels_ignore에 추가
if bbox_name in cat2label:
gt_bboxes.append(bbox)
# gt_labels에는 class id를 입력
gt_labels.append(cat2label[bbox_name])
else:
gt_bboxes_ignore.append(bbox)
gt_labels_ignore.append(-1)
# 개별 image별 annotation 정보를 가지는 Dict 생성. 해당 Dict의 value값은 모두 np.array임.
data_anno = {
'bboxes': np.array(gt_bboxes, dtype=np.float32).reshape(-1, 4),
'labels': np.array(gt_labels, dtype=np.int32),
'bboxes_ignore': np.array(gt_bboxes_ignore, dtype=np.float32).reshape(-1, 4),
'labels_ignore': np.array(gt_labels_ignore, dtype=np.int32)
}
# image에 대한 메타 정보를 가지는 data_info Dict에 'ann' key값으로 data_anno를 value로 저장.
data_info.update(ann=data_anno)
# 전체 annotation 파일들에 대한 정보를 가지는 data_infos에 data_info Dict를 추가
data_infos.append(data_info)
return data_infos코드의 주요 부분에 대해 설명하겠습니다.
@DATASETS.register_module(force=True) class KittyTinyDataset(CustomDataset):
위 코드를 통해 아래 custom dataset class를 모듈에 등록할 수 있게 됩니다.
'@'는 파이썬의 데코레이터 연산자이므로 필요한 내용은 찾아보시면 되겠습니다.
CustomDataset을 부모 클래스로 가져갔다는 것을 볼 수 있습니다. mmdet의 CustomDataset을 부모 클래스로 가져가면서 KittyTinyDataset은 ann_file, data_root, img_prefix를 입력받을 수 있게 됩니다.
-
ann_file : annotation 정보가 들어있는 파일의 경로입니다. VOC형태일 경우 meta file을 받습니다.
-
data_root : data경로의 근본적인 경로입니다. ex) /content/data
-
img_prefix : image가 저장되어있는 경로입니다. 최종적으로는 절대경로가 되지만 입력받을 때 img_prefix = data_root + img_prefix가 됩니다.
CLASSES = ('Car', 'Truck', 'Pedestrian', 'Cyclist')
사용자가 정의하는 label입니다.
꼭 CLASSES라는 변수 명으로 적어주어야 하며, 변동사항이 없으면 적어주지 않아도 괜찮습니다.
def load_annotations(self, ann_file):
나중에 dataset를 불러올 때 실질적으로 수행되는 메서드입니다.
데이터를 middle format으로 바꿔주는 역할을 하는 메서드입니다.
이후에 load_annotations의 내용은 사용자가 원하는 데이터에 의해 바뀌므로 설명하지 않겠습니다.
어느정도 파이썬(혹은 코딩)을 다룰줄 아는 분들이라면 함수 내용을 이해하는데 무리가 없을 것 같습니다.
Basic inference부분에서는 config파일을 가져와 그대로 init_detector에 넣었습니다.
여기서는 config파일을 그대로 가져오고 입맛대로 바꾸면 setting은 끝이납니다.
config객체를 가지고 오는 것은 mmcv의 Config.fromfile 메서드를 이용하면 됩니다.
from mmcv import Config
cfg = Config.fromfile(config_file)
print(cfg.pretty_text)config는 딕셔너리 형태이기 때문에 설정하는 방법은 간단합니다.
위에서 customdataset으로 KittyTinyDataset를 만들었다고 가정하고 cfg를 수정해보겠습니다.
from mmdet.apis import set_random_seed
# dataset에 대한 환경 파라미터 수정.
cfg.dataset_type = 'KittyTinyDataset'
cfg.data_root = '/content/kitti_tiny/'
# train, val, test dataset에 대한 type, data_root, ann_file, img_prefix 환경 파라미터 수정.
cfg.data.train.type = 'KittyTinyDataset'
cfg.data.train.data_root = '/content/kitti_tiny/'
cfg.data.train.ann_file = 'train.txt'
cfg.data.train.img_prefix = 'training/image_2'
cfg.data.val.type = 'KittyTinyDataset'
cfg.data.val.data_root = '/content/kitti_tiny/'
cfg.data.val.ann_file = 'val.txt'
cfg.data.val.img_prefix = 'training/image_2'
cfg.data.test.type = 'KittyTinyDataset'
cfg.data.test.data_root = '/content/kitti_tiny/'
cfg.data.test.ann_file = 'val.txt'
cfg.data.test.img_prefix = 'training/image_2'
# class의 갯수 수정.
cfg.model.roi_head.bbox_head.num_classes = 4
# pretrained 모델
cfg.load_from = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
# 학습 weight 파일로 로그를 저장하기 위한 디렉토리 설정.
cfg.work_dir = './tutorial_exps'
# 학습율 변경 환경 파라미터 설정.
cfg.optimizer.lr = 0.02 / 8
cfg.lr_config.warmup = None
cfg.log_config.interval = 10
# config 수행 시마다 policy값이 없어지는 bug로 인하여 설정.
cfg.lr_config.policy = 'step'
# Change the evaluation metric since we use customized dataset.
cfg.evaluation.metric = 'mAP'
# We can set the evaluation interval to reduce the evaluation times
cfg.evaluation.interval = 12
# We can set the checkpoint saving interval to reduce the storage cost
cfg.checkpoint_config.interval = 12
# Set seed thus the results are more reproducible
cfg.seed = 0
set_random_seed(0, deterministic=False)
cfg.gpu_ids = range(1)
# ConfigDict' object has no attribute 'device 오류 발생시 반드시 설정 필요. https://github.com/open-mmlab/mmdetection/issues/7901
cfg.device='cuda'
# We can initialize the logger for training and have a look
# at the final config used for training
print(f'Config:\n{cfg.pretty_text}')이제 config 변경 코드를 살펴보겠습니다.
cfg.dataset_type = 'KittyTinyDataset' cfg.data_root = '/content/kitti_tiny/'
dataset_type은 커스터마이징한 class 이름으로 지정해주셔야 합니다.
data_root는 앞 내용을 참고해주세요.
cfg.data.train.type = 'KittyTinyDataset' cfg.data.train.data_root = '/content/kitti_tiny/' cfg.data.train.ann_file = 'train.txt' cfg.data.train.img_prefix = 'training/image_2' cfg.data.val.type = 'KittyTinyDataset' cfg.data.val.data_root = '/content/kitti_tiny/' cfg.data.val.ann_file = 'val.txt' cfg.data.val.img_prefix = 'training/image_2' cfg.data.test.type = 'KittyTinyDataset' cfg.data.test.data_root = '/content/kitti_tiny/' cfg.data.test.ann_file = 'val.txt' cfg.data.test.img_prefix = 'training/image_2'
cfg data에 대한 정보입니다.
KittyTinyDataset같은 경우 VOC형태를 띄기 때문에 ann_file은 meta file로 설정됩니다.
# class의 갯수 수정. cfg.model.roi_head.bbox_head.num_classes = 4 # pretrained 모델 cfg.load_from = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
cfg model에 대한 정보입니다.
roi_head에서 num_classes에 설정한 label의 총 갯수를 정해주면 됩니다.
load_from에는 checkpoint file 경로를 넣어주면 됩니다.
# 학습 weight 파일로 로그를 저장하기 위한 디렉토리 설정. cfg.work_dir = './tutorial_exps' # 학습율 변경 환경 파라미터 설정. cfg.optimizer.lr = 0.02 / 8 cfg.lr_config.warmup = None cfg.log_config.interval = 10 # config 수행 시마다 policy값이 없어지는 bug로 인하여 설정. cfg.lr_config.policy = 'step' # Change the evaluation metric since we use customized dataset. cfg.evaluation.metric = 'mAP' # We can set the evaluation interval to reduce the evaluation times cfg.evaluation.interval = 12 # We can set the checkpoint saving interval to reduce the storage cost cfg.checkpoint_config.interval = 12 # Set seed thus the results are more reproducible cfg.seed = 0 set_random_seed(0, deterministic=False) cfg.gpu_ids = range(1) # ConfigDict' object has no attribute 'device 오류 발생시 반드시 설정 필요. https://github.com/open-mmlab/mmdetection/issues/7901 cfg.device='cuda'
나머지 부분은 파라미터 설정, metric 등 부수적인 설정입니다.
저도 이 부분에 대해서는 잘 모르지만 log_config.interval이 10인 경우 epoch를 10회 도는 것으로 알고 있고 그 아래의 interval 부분이 12인 것은 모델을 언제 저장할 지, 언제 평가할 지에 대한 부분입니다.
metric은 mAP를 적용한다는 뜻입니다.
warmup은 learning_rate를 적용하는 방식인 것으로 생각됩니다.(처음에 천천히 올라갈 것인지 설정)
✔ build_detector
앞에서 setting부분을 성공적으로 마쳤으면 model을 만드는 과정은 간단합니다.
mmdet의 build_detector API를 사용하면 detector가 만들어집니다.
인자로는 cfg.model이 들어갑니다.(model에 대한 config)
from mmdet.models import build_detector
model = build_detector(cfg.model, train_cfg=cfg.get('train_cfg'), test_cfg=cfg.get('test_cfg'))train_cfg와 test_cfg의 용도는 모델이 train/test 시에 필요로 하는 하이퍼 파라미터 정보를 입력해주는 용도입니다.
✔ build_dataset
dataset을 만드는 것도 앞에서 setting부분만 잘하면 간단합니다.
mmdet의 build_dataset API를 사용하면 됩니다. 주의할 점은 리스트로 감싸야 한다는 것입니다.
from mmdet.datasets import build_dataset
# 학습용 데이터 셋
datasets = [build_dataset(cfg.data.train)]모델을 학습하는 것이 목적이기 때문에 cfg의 train부분을 인자로 넣어주면 됩니다.
model.CLASSES = datasets[0].CLASSES그 후 model의 CLASSES 속성에 만들어진 datasets CLASSES 속성을 넣어줍니다.
(datasets의 CLASSES는 앞에서 KittyTinyDataset 클래스에서 설정한 CLASSES입니다.)
✔ train_detector
이제 앞에서 모델을 만들었고, custom dataset을 만들었으면 모델을 학습시킬 차례입니다.
train_detector API에 model, datasets, cfg를 넣어주면 됩니다.
cfg를 넣어주는 이유는 아마 config에 model이 학습하는 train config도 있기 때문입니다.
from mmdet.apis import train_detector
train_detector(model, datasets, cfg, distributed=False, validate=True)distributed 인자는 MMDetection 다큐멘터리를 찾아봤는데 정확히 어떤 작동을 의미하는지는 잘 모르겠습니다..
아래는 distributed가 작동하는 부분입니다.
이렇게 모델을 학습시키면 추론하는 과정은 inference_detector 부분과 완전히 동일합니다.
Reference
[개정판] 딥러닝 컴퓨터 비전 완벽 가이드
MMDetection github
MMDetection Paper
