오늘은 ResNet 논문을 리뷰하려고 합니다.
ResNet 모델은 마이크로소프트 팀이 개발한 모델로,
2015년 ImageNet Classification 대회에서 1등을 한 모델로 기존 모델보다 성능을 대폭 향상시켰습니다.
ResNet Paper
본 장에서는 논문 리뷰를 하지만, 논문 내용을 그대로 직역했다기 보다는 저의 개인적인 견해와 저의 지식을 통합하였습니다. 또한, 제목과 순서도 논문과는 다를 수 있습니다.
Abstract
모델 네트워크는 점점 더 깊어질수록 학습하기 어려워집니다.
논문에서는 "잔차(residual) 학습"을 이용해 모델의 네트워크가 더 깊어지고, 학습하기 용이하게 합니다.
이 논문을 통해 잔차 네트워크가 모델 최적화에 더 용이하며, 모델의 성능 향상에도 도움이 될 것이라는 증명을 합니다.
ResNet은 기존의 VGG 모델보다 더 깊지만, 모델의 심플성을 유지합니다.
ResNet 모델의 앙상블을 이용해서 ImageNet 대회에서 3.57% error로 1등을 하며 모델의 성능을 증명했습니다.

1. Introduction
Deep Convolutional Network는 이미지 분류의 돌파구를 만들었습니다.
Deep Convolutional Network는 자연적으로 low/mid/high 레벨의 피처를 만들었으며, 최근 연구에서 모델의 깊이에 대한 중요성이 대두되고 있습니다.
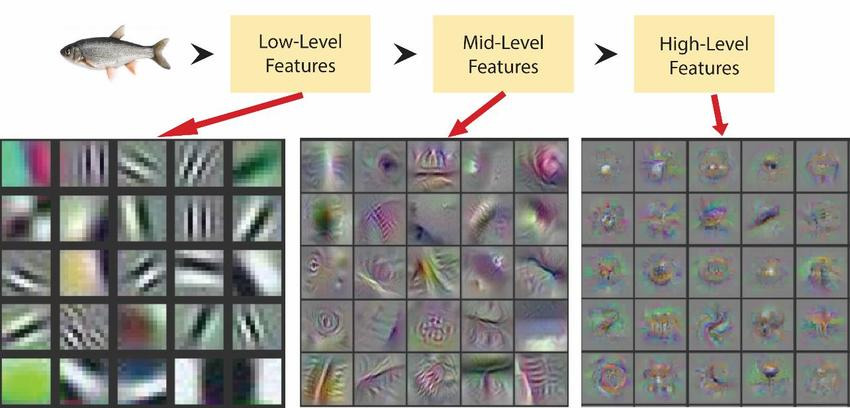
이렇게 '깊이'의 중요성을 추구하던 중 다음과 같은 의문이 제기되었습니다.
"더 많은 층을 쌓는 것처럼 쉽게 네트워크를 더 좋게 학습시킬 수 있는가?"
이 의문에 대한 답으로 미분 값 손실(Gradient Vanishing)이라는 답변이 나왔습니다.
이 문제는 10개 정도의 layer까지 SGD, Normalized initialization과 같은 방법을 사용했을 경우 문제가 없었다고 합니다.
하지만, 심층 신경망에서 모델의 성능이 포화상태에 다다르고 깊이가 깊어지면서, Degration문제가 발생하게 됩니다.
여기서 Degration이란, 모델의 성능이 낮아지는 현상을 의미하는데, Degration 문제가 발생하기 시작하면 모델의 성능이 급격하게 떨어진다고 합니다.
이는 예상과는 달리 오버피팅 문제가 아니었습니다.
왜냐하면 test_error가 증가함과 동시에 training error도 같이 증가했기 때문입니다.
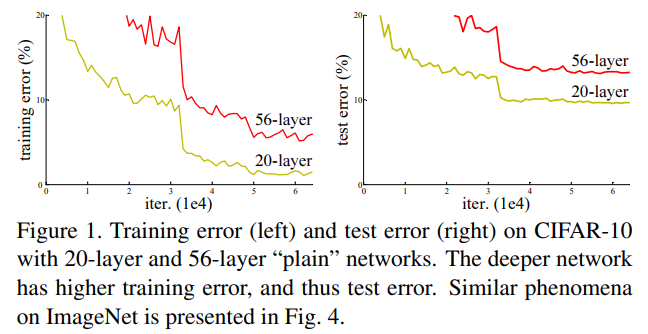
Degration 문제는 모델이 최적화 되는 방식은 다르다는 점을 시사합니다.
하지만, 논문에서는 이런 문제속에서도 모델을 최적화하는 방법이 있다고 가정합니다.
이를 위해서는 다음과 같은 조건이 필요합니다.
- 새롭게 추가되는 layer는 identity layer이여야 합니다.
- 기존 layer는 보다 얕은 모델에서 학습된 layer이여야 합니다.
이렇게 구성된 네트워크는 기존 모델보다 training error가 높아서는 안된다고 가정했습니다.
기존에는 x가 입력되면, H(x)를 찾는 것이 목표였지만, residual function은 입력 값과 출력 값의 잔차입니다. 즉, residual function H(x) - x은 F(x) = H(x) - x로 정의되며,
F(x)는 0으로 근접해야 하기 때문에 H(x) = x를 목표로 합니다.
이는 다시말해, H(x)를 x로 mapping하는 것이 학습의 목표가 됩니다.
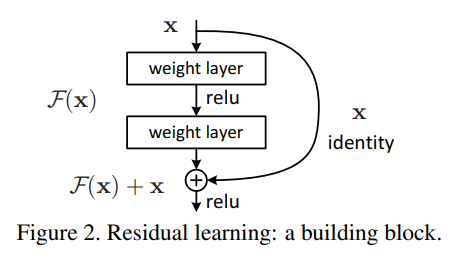
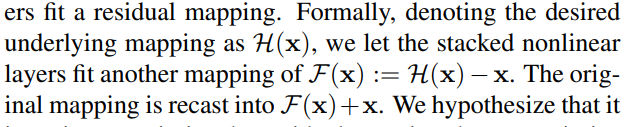
논문에서는 이렇게 residual function을 학습하는 것이 최적화에 더 쉽다고 말합니다.
왜냐하면, 기존의 방식이 H(x)라는 unreferenced mapping 방식이었다면(알려지지 않은 함수를 찾는 방식), 논문의 방식은 H(x) = x라는 목표 값이 사전에 지정되기 때문입니다.

결국 모델은 함수 H(x) = F(x) + x를 만들어야 하는데, 이는 기존의 H(x) = F(x)에서 입력 값 x가 추가된 것이므로 파라미터가 증가하지 않습니다. 논문에서는 이런 방법을 "Shortcut Connections"라고 명명했습니다.
Shortcut Connections는 한 개 혹은, 여러 개의 layer를 건너뛰는 작업입니다.
Shortcut Connections는 identity mapping을 수행하며, 이는 최종 output에 더해지게 됩니다.
이런 방식을 이용하면 파라미터 수는 증가하지 않고, 곱셈 연산 대신 덧셈 연산이 증가합니다.
이렇게 만들어진 ResNet은 이전 모델(논문에서는 Plain net이라고 부름)보다 최적화되기 쉽다는 것을 보였습니다.
또한, 성능도 이전 모델보다 뛰어남을 증명하였으며, 모델의 깊이를 대폭 늘리는데 성공하였습니다.

2. Deep Residual Learning
여기서는 Residual Learning과 Model Architecture에 대해 구체적으로 다룹니다.
✔ Residual Learning
만약 수많은 비선형 layer가 복잡한 함수 H(x)로 근사할 수 있다면, 동시에 residual function H(x) - x에 근접할 수 있음을 의미합니다.
따라서 논문에서는 H(x)에 접근하는 것보다 H(x) - x에 접근하는 것이 쉽다고 합니다.
F(x) = H(x) - x라고 한다면, 구하고자 하는 함수 H(x) = F(x) + x가 됩니다.

만약 추가되는 layer가 identity mapping으로 구성된다면, 기존 모델보다 training error가 높아져서는 안됩니다.
논문에서는 identity mapping이 최적화 될 가능성은 낮다고 합니다. 하지만, 이런 방식은 문제에 precondition을 추가함으로써 도움을 줍니다.
만약 최적화된 함수가 zero mapping이 아닌 identity mapping에 근접한다면 identity mapping을 학습하는 것이 새로운 function을 학습하는 것보다 쉽습니다.

zero mapping은 Convolutional layer에 곱해지는 값이 0인 상태에서 시작해 점진적으로 identity mapping으로 만드는 것을 의미하고, identity mapping은 identity 과정은 따로 학습하거나 추가되는 파라미터가 없이 Convolutional layer의 출력이 0에 가까워지도록 학습하는 것을 의미합니다.
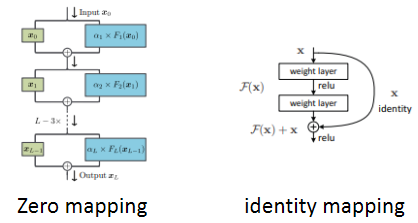
✔ Identity Mapping by Shorcuts
앞에서 Identity Mapping을 통해 얻는 함수는 F(x) + x라고 말했습니다.
이렇게 Identity Mapping을 하기 위해서 "Shorcuts" 방법을 사용하는데 이 방법을 이용하면 파라미터의 추가 없이, 연산 복잡량을 증가시키지 않습니다.
Shorcuts은 x를 skip-connections를 통해 블록의 output에 더해주는 방식입니다.
하지만, F(x)는 layer를 거치면서 차원이 달라질 수 있습니다.
논문에서는 x를 output 차원에 맞추기 위해 Ws를 x에 곱하여 차원을 맞출 수 있도록 했습니다.
이때, Ws는 차원을 맞출때만 사용합니다.

✔ Network Architectures
논문에서는 다양한 plain/residual networks를 테스트 했습니다.
Plain Network
ResNet은 VGG Network에서 영감을 받았습니다.
VGG는 3 X 3 Convolutional layer가 연속으로 결합된 모델 입니다.
이를 토대로 만들어진 ResNet Plain Network도 대부분 3 X 3 Convolutional layer가 결합됩니다.
이때, 다음과 같이 두 가지 규칙이 있습니다.
- output의 feature map이 변경되지 않으면, filter수도 변하지 않는다.
- 만약 output의 feature map의 크기가 절반이 된다면, filter수는 2배로 늘린다.
DownSampling할 때, stride를 2로 설정한 Convolutional layer를 이용합니다.
ResNet Network는 마지막에 GAP(Global Average Pooling)을 적용하며, 1000개의 unit으로 구성된 layer로 끝납니다.(activation='softmax')
이렇게 구성된 Plain 모델은 VGG보다 덜 복잡할 뿐더러 FLOPs와 필터 수가 더 적습니다.
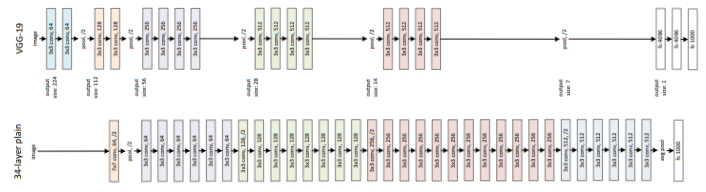
Residual Network
위에서 구성된 Plain Network에 Shortcut Connections를 추가한 것이 최종 ResNet 입니다.
output feature map의 차원이 달라졌을 경우, x에 다음과 같은 방법이 적용될 수 있습니다.
- 나머지 차원 부분을 0으로 채운다.
- projection shortcut을 적용한다.(1 X 1 convolutions)
이렇게 구성된 Shortcut Connections는 2개 블록마다 적용됩니다.

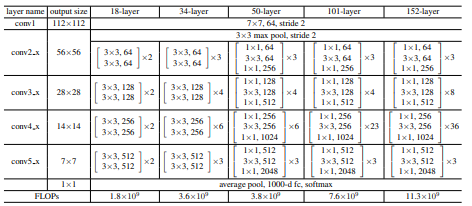
3. Conclusion
ResNet은 ImageNet Classification 대회에서 3.57% error로 1등을 하며 성능을 증명했습니다.
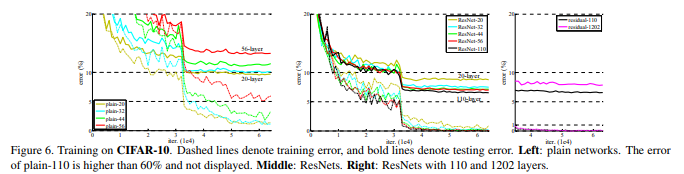
논문에서는 ImageNet 데이터 뿐만 아니라 CIFAR-10 데이터셋에 대해서 학습한 결과를 제시하며 기존 Plain 모델보다 Shortcut Connections를 적용한 모델의 성능이 얼마나 증가하는 지 보여줍니다.
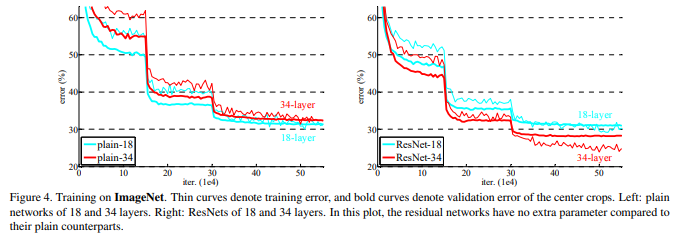
tensorflow 구현
아래는 직접 tensorflow로 ResNet34를 구현한 코드 입니다.
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, BatchNormalization, Activation, Add
from tensorflow.keras.layers import GlobalAveragePooling2D, Dense, Dropout
from tensorflow.keras.models import Model
# residual_block 함수
def residual_block(x, filters, strides=1, iter=2):
for i in range(iter):
if i == iter-1:
x = Conv2D(filters=filters, kernel_size=(3, 3), strides=strides, padding='same')(x)
x = BatchNormalization()(x)
else:
x = Conv2D(filters=filters, kernel_size=(3, 3), strides=strides, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
return x
input_tensor = Input(shape=(224, 224, 3))
# layer1
x = Conv2D(filters=64, kernel_size=(7, 7), strides=2, padding='same')(input_tensor)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
# layer2
x = Add()([residual_block(x, 64, iter=2), x])
x = Activation('relu')(x)
x = Add()([residual_block(x, 64, iter=2), x])
x = Activation('relu')(x)
x = Add()([residual_block(x, 64, iter=2), x])
x = Activation('relu')(x)
# layer3
prev = MaxPooling2D(pool_size=(2, 2), padding='same')(x)
prev = Conv2D(filters=128, kernel_size=(1, 1))(prev)
x = Conv2D(filters=128, kernel_size=(3, 3), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Add()([residual_block(x, 128, iter=1), prev])
x = Activation('relu')(x)
x = Add()([residual_block(x, 128, iter=2), x])
x = Activation('relu')(x)
x = Add()([residual_block(x, 128, iter=2), x])
x = Activation('relu')(x)
x = Add()([residual_block(x, 128, iter=2), x])
x = Activation('relu')(x)
# layer4
prev = MaxPooling2D(pool_size=(2, 2), padding='same')(x)
prev = Conv2D(filters=256, kernel_size=(1, 1))(prev)
x = Conv2D(filters=256, kernel_size=(3, 3), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Add()([residual_block(x, 256, iter=1), prev])
x = Activation('relu')(x)
x = Add()([residual_block(x, 256, iter=2), x])
x = Activation('relu')(x)
x = Add()([residual_block(x, 256, iter=2), x])
x = Activation('relu')(x)
x = Add()([residual_block(x, 256, iter=2), x])
x = Activation('relu')(x)
x = Add()([residual_block(x, 256, iter=2), x])
x = Activation('relu')(x)
x = Add()([residual_block(x, 256, iter=2), x])
x = Activation('relu')(x)
# layer5
prev = MaxPooling2D(pool_size=(2, 2), padding='same')(x)
prev = Conv2D(filters=512, kernel_size=(1, 1))(prev)
x = Conv2D(filters=512, kernel_size=(3, 3), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Add()([residual_block(x, 512, iter=1), prev])
x = Activation('relu')(x)
x = Add()([residual_block(x, 512, iter=2), x])
x = Activation('relu')(x)
x = Add()([residual_block(x, 512, iter=2), x])
x = Activation('relu')(x)
# fully-connected layer
x = GlobalAveragePooling2D()(x)
output = Dense(1000, activation='softmax')(x)
model = Model(inputs=input_tensor, outputs=output)Reference
