오늘은 2014 ImageNet Classification 대회에서 1등을 차지한 GoogLeNet 논문을 리뷰하려고 합니다.
매우 복잡한 아키텍처를 가지고 있는 모델로, 같은 대회에서 좋은 성과를 낸 VGG와는 다른 결을 가진 모델입니다.
GoogLeNet Paper
본 장에서는 논문 리뷰를 하지만, 논문 내용을 그대로 직역했다기 보다는 저의 개인적인 견해와 저의 지식을 통합하였습니다. 또한, 제목과 순서도 논문과는 다를 수 있습니다.
Abstract
GoogLeNet은 기존과는 다르게 "Inception"이라고 명명한 네트워크로 구성됩니다.
Inception 네트워크는 컴퓨팅 자원의 유용성을 증가시켰습니다.
(다시 말해, 연산량을 대폭 감소시켰습니다.)
이렇게 증가한 유용성을 통해 네트워크의 층과 넓이를 증가시킬 수 있었습니다.
이렇게 만들어진 GoogLeNet은 22개의 deep network로 구성되어 있으며, classification과 detection에서 좋은 성능을 내는 모델입니다.
1. Introduction
지난 3년동안 convolution network은 드라마틱한 변화를 겪었습니다.
높은 성능을 보유한 하드웨어, 더 방대해진 데이터셋, 더 커진 모델뿐만 아니라 새로운 아이디어들, 알고리즘 등이 네트워크에 영향을 미쳐왔습니다.
앞서, Inception 네트워크를 통해 컴퓨팅 연산을 줄였다고 말했습니다.
GoogLeNet은 AlexNet보다 약 12배 적은 파라미터를 가지며, 더 높은 성능을 보여줍니다.
또다른 요소는 모바일, 임베디드 컴퓨팅 부분에서 GoogLeNet의 높은 효율성이 각광받는다는 것입니다.
일반적으로, 대부분 모델은 예측하는 동안 15억번의 컴퓨팅 예산이 필요하기 때문에 이론으로 끝납니다. 하지만, GoogLeNet은 합리적인 비용으로 실제 환경에서 사용할 수 있습니다.(큰 데이터셋에서도 사용 가능하다고 합니다.)
논문에서 아키텍처를 구성할 때, '깊은' 네트워크를 구성하는 것을 목표로 삼았습니다.
"깊다"라는 것을 논문에서는 다음과 같이 생각했습니다.
- "Inception Module"로써의 새로운 level
- 단어 그대로의 깊이
그리고 이렇게 나온 GoogLeNet은 2014 ImageNet Classification 대회에서 좋은 성능을 내며 증명했습니다.
2. Motivation and High Level Considerations
모델의 성능을 높이는 확실한 방법은 모델의 크기를 늘리는 방법입니다.
크기를 늘린다는 것은 깊이와 넓이를 늘린다는 것입니다.
(넓이는 layer의 수(depth)이며, 넓이는 각 레벨의 유닛 수 입니다.)
하지만, 이렇게 모델의 크기를 늘리면 두 가지 문제점이 발생합니다.
✔ Overfitting
모델의 큰 사이즈는 전형적으로 파라미터의 증가를 의미합니다.
또한, 이렇게 증가된 파라미터는 오버피팅을 유발합니다.(특히, 데이터가 한정되어 있을 때)
이런한 현상은 병목 현상을 유발할 수도 있습니다.
높은 퀄리티의 데이터를 만들려면, 비용이 많이 들고, 까다롭기 때문에 이런 병목 현상이 생기게 됩니다.

위 사진처럼 비슷하게 생긴 데이터의 경우 일반 사람은 구별하기 힘드니 전문가가 필요합니다.
즉, 비용이 비싸짐과 동시에 데이터도 한정되게 됩니다.
✔ Computational resources
모델의 크기가 커지면, 컴퓨팅 자원이 많이 소모됩니다.
이는 모델이 비효율적으로 사용된다면, 낭비되는 컴퓨팅 자원이 많아진다는 의미입니다.
컴퓨팅 자원은 제한적이기 때문에 효율적인 컴퓨팅 자원의 분배가 선호됩니다.
이런 문제를 해결하기 위한 기본적인 방법은 fully-connected 아키텍처를 sparsely connected 아키텍처로 바꾸는 것입니다.
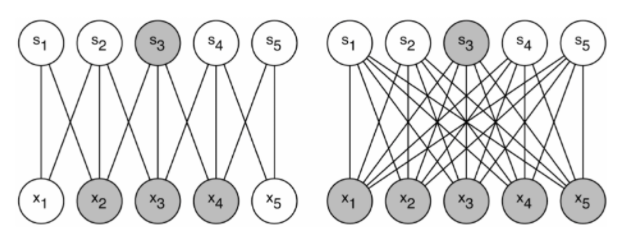
이렇게 dense layer를 더 큰 sparse layer로 바꿀 수 있다면, layer들간의 통계적 유사성을 통해 상관성 있는 뉴런들을 클러스터링할 수 있습니다.
이당시 희소 행렬 컴퓨팅 문헌에서 "희소 행렬을 상대적으로 밀집된 행렬로 클러스터링하는 것이 좋은 성능을 낸다"라고 주장했었습니다.

Inception 아키텍처는 유사 희소 행렬을 연구하기 위해 만들어졌습니다.
이는 Localization과 Object Detection에서 좋은 성능을 냈습니다.
3. Architecture
Inception의 주요 아이디어는 데이터에서 최적의 sparse local structure로 근사치 시키는 것이며, 이를 dense components로 바꾸는 방법에 초점을 뒀습니다.
다시 말해, 아키텍처가 최적의 local structure를 찾고, dense components로 바꾸는 로직으로 구성되어있다는 것을 의미합니다.(이를 공간적으로 반복합니다.)
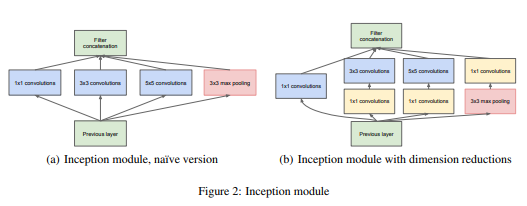
이미지마다 크기도 저마다 다르고 특징도 다르기 때문에 kernel 사이즈도 다를 필요가 있습니다. 따라서 Inception 모듈마다 1 X 1, 3 X 3, 5 X 5 크기를 병렬적으로 수행합니다.
일반적으로 Convolution 연산을 진행해 feature extracture를 진행하면 high-level로 올라갈 수록 데이터가 추상화 됩니다. 이런 경우, 공간적 집중도가 감소해 3 X 3, 5 X 5 filter수가 늘어나야 합니다.
하지만, 3 X 3, 5 X 5 filter의 경우 컴퓨팅 연산량이 크게 늘어납니다.
논문에서는 이를 해결하기 위해 1 X 1 filter를 이용해 dimension-reductions을 진행합니다.
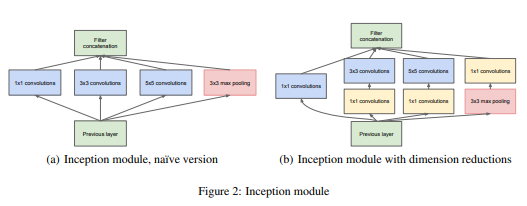
또한, Pooling의 경우 성능 향상에 좋다는 것이 밝혀졌기 때문에 Pooling을 적용하기 위해 Padding을 진행합니다.
이렇게 구성된 Inception Module을 low-level부터 high-level로 연결합니다.
논문에서는 메모리 효율성을 고려해 상대적으로 추상화된 high-level에 Inception Module을 적용하는 것이 좋다고 말합니다.
이렇게 만들어진 GoogLeNet은 Inception Module이 적용되지 않은 비슷한 성능을 내는 모델과 비교해봤을 때, 2-3배 더 빠르다고 합니다.
최종적으로 Inception Module이 적용된 전체 GoogLeNet 아키텍처는 다음과 같습니다.
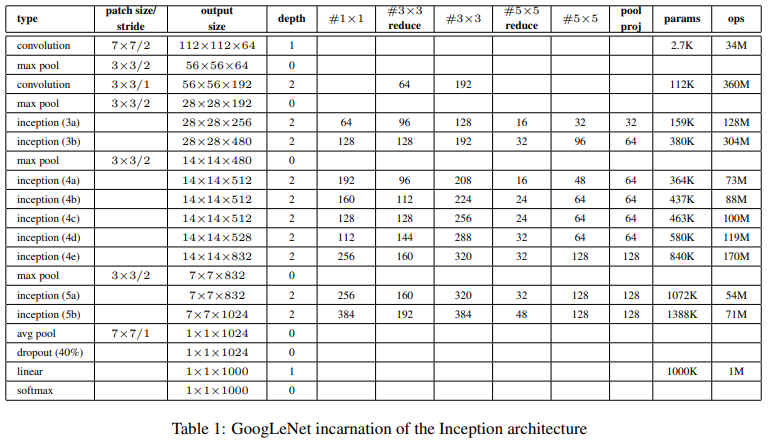
데이터는 224 X 224 X 3으로 들어옵니다. low-level에서는 Inception Module을 적용하지 않습니다. 일반적인 Convolution layer와 Pooling을 거치면서 데이터를 28 X 28크기로 줄인 후 Inception Module을 적용합니다.(상대적으로 high-level 즉, 추상화 되었을 때)
4. Conclusion
GoogLeNet은 Inception Module이라는 참신한 아이디어를 내세워 성능을 개선시켰습니다.
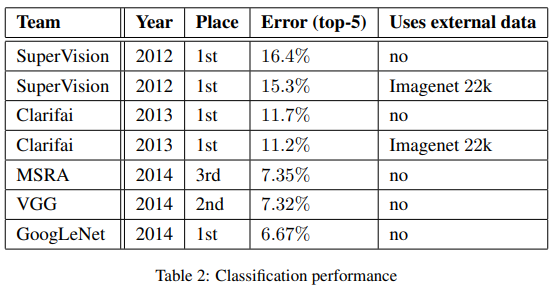
이는 희소 행렬을 밀집 행렬로 근사하는 과정을 적용한 결과입니다.
기존 모델의 성능을 높이기 위한 방법들과 다른 참신한 방법이었으며 성능은 대폭 상승하지만, 컴퓨팅 연산량은 소폭 증가하였습니다.
tensorflow 구현
아래 코드는 tensorflow로 GoogLeNet을 구현한 코드입니다.
논문 아키텍처에는 3개의 output을 내보내지만, 여기서는 최종 output2만 구현했습니다.
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, BatchNormalization, Activation, Concatenate
from tensorflow.keras.layers import GlobalAveragePooling2D, Dense, Dropout
from tensorflow.keras.models import Model
def inception_module(x, filters_1x1, reduce_filters_3x3, filters_3x3, reduce_filters_5x5, filters_5x5, pool_proj):
x_1x1 = Conv2D(filters=filters_1x1, kernel_size=(1, 1), padding='same')(x)
x_1x1 = BatchNormalization()(x_1x1)
x_1x1 = Activation('relu')(x_1x1)
x_3x3 = Conv2D(filters=reduce_filters_3x3, kernel_size=(1, 1), padding='same')(x)
x_3x3 = BatchNormalization()(x_3x3)
x_3x3 = Activation('relu')(x_3x3)
x_3x3 = Conv2D(filters=filters_3x3, kernel_size=(3, 3), padding='same')(x_3x3)
x_3x3 = BatchNormalization()(x_3x3)
x_3x3 = Activation('relu')(x_3x3)
x_5x5 = Conv2D(filters=reduce_filters_5x5, kernel_size=(1, 1), padding='same')(x)
x_5x5 = BatchNormalization()(x_5x5)
x_5x5 = Activation('relu')(x_5x5)
x_5x5 = Conv2D(filters=filters_5x5, kernel_size=(5, 5), padding='same')(x_5x5)
x_5x5 = BatchNormalization()(x_5x5)
x_5x5 = Activation('relu')(x_5x5)
pool_prj = MaxPooling2D(pool_size=(3, 3), strides=1, padding='same')(x)
pool_prj = Conv2D(filters=pool_proj, kernel_size=(1, 1), padding='same')(pool_prj)
pool_prj = BatchNormalization()(pool_prj)
pool_prj = Activation('relu')(pool_prj)
inception_output = Concatenate(axis=-1)([x_1x1, x_3x3, x_5x5, pool_prj])
return inception_output
input_tensor = Input(shape=(224, 224, 3))
x = Conv2D(filters=64, kernel_size=(7, 7), strides=2, padding='same')(input_tensor)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
x = Conv2D(filters=192, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=192, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
# inception (3a)
x = inception_module(x, 64, 96, 128, 16, 32, 32)
x = inception_module(x, 64, 96, 128, 16, 32, 32)
# inception (3b)
x = inception_module(x, 128, 128, 192, 32, 96, 64)
x = inception_module(x, 128, 128, 192, 32, 96, 64)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
# inception (4a)
x = inception_module(x, 192, 96, 208, 16, 48, 64)
x = inception_module(x, 192, 96, 208, 16, 48, 64)
# inception (4b)
x = inception_module(x, 160, 112, 224, 24, 64, 64)
x = inception_module(x, 160, 112, 224, 24, 64, 64)
# inception (4c)
x = inception_module(x, 128, 128, 256, 24, 64, 64)
x = inception_module(x, 128, 128, 256, 24, 64, 64)
# inception (4d)
x = inception_module(x, 128, 128, 256, 24, 64, 64)
x = inception_module(x, 128, 128, 256, 24, 64, 64)
# inception (4e)
x = inception_module(x, 256, 160, 320, 32, 128, 128)
x = inception_module(x, 256, 160, 320, 32, 128, 128)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
# inception (5a)
x = inception_module(x, 256, 160, 320, 32, 128, 128)
x = inception_module(x, 256, 160, 320, 32, 128, 128)
# inception (5b)
x = inception_module(x, 384, 192, 384, 48, 128, 128)
x = inception_module(x, 384, 192, 384, 48, 128, 128)
# fully-connected-layer
x = GlobalAveragePooling2D()(x)
x = Dropout(0.4)(x)
x = Dense(1000)(x)
output = Dense(1000, activation='softmax')(x)
model = Model(inputs=input_tensor, outputs=output)Reference
