안녕하세요. 오늘은 SPP-Net 논문 리뷰를 하려고 합니다.
SPP-Net Paper
SPP-Net은 기존 R-CNN 모델을 계승하며, 더 뛰어난 성능을 내는 모델입니다.
Abstract

지금까지 존재하는 CNN 아키텍처는 fixed-size를 요구했습니다.
이는 인풋 이미지가 "인공적"이고, 모델 성능을 저하시킬 수 있습니다. 논문에서는 "spatial pyramid pooling(SPP)"을 이용해 이미지의 크기에 상관없이 fixed-length representation을 만들었습니다.
SPP-Net은 이전 R-CNN보다 성능이 뛰어날 뿐만 아니라, Detection 시간도 24-102배 빨라졌습니다.
1. Introduction

CNN이 나타나면서 Object Detection 영역이 발전하고 있습니다.
하지만, 지금까지의 모델들은 대부분 고정된 이미지 사이즈를 입력 받아야 했고 이는 이미지의 크기와 비율을 제한한다는 문제를 동반했습니다.
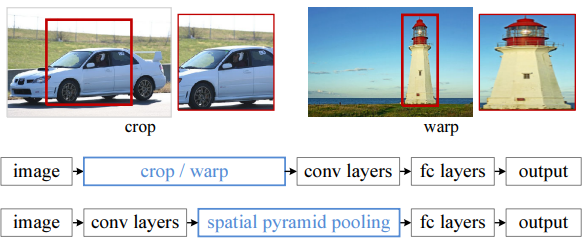
고정된 이미지 사이즈를 입력받기 위해서 crop/warp 방식을 이용했는데, 이는 원본 이미지의 기하학적인 왜곡을 유발한다는 문제점이 있습니다. 특히나, Object의 스케일이 다양한 경우 적합하지 않은 방법입니다.
그렇다면, 여기서 다음과 같은 질문이 생깁니다.
"어째서 CNN은 고정된 이미지 사이즈를 원하는가?"
CNN은 convolutional layer와 fully-connected layer로 이루어져 있습니다.
convolutional layer 부분에서는 이미지 사이즈를 고정할 필요가 없지만, fully-connected layer에서는 이미지 사이즈가 고정되어야 합니다.
따라서 CNN은 고정된 이미지 사이즈가 필요한 것입니다.
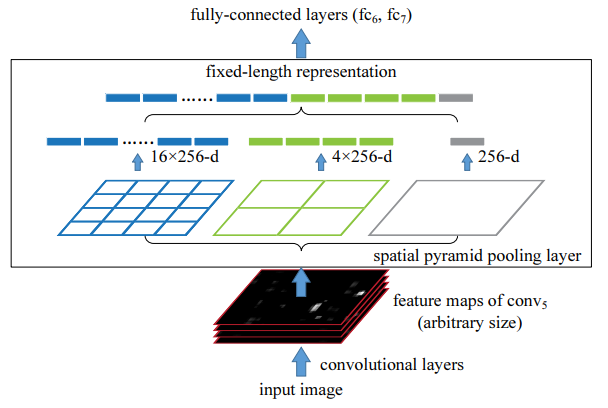
논문에서는 spatial pyramid pooling(SPP)을 convolutional layer 마지막 부분에 적용하여 이미지 크기 제약을 없앱니다. SPP layer는 feature를 풀링하며, 고정된 아웃풋을 만들어 냅니다.
이는 SPP layer가 convolutional layer와 fully-connected layer 사이에서 "aggregation"함을 의미합니다. 논문에서는 SPP layer를 이용한 네트워크를 SPP-Net이라고 명명합니다.

SPP는 BoW에서 확장된 개념으로, 컴퓨터 비전 영역에서 뛰어난 방법으로 알려져 있습니다.
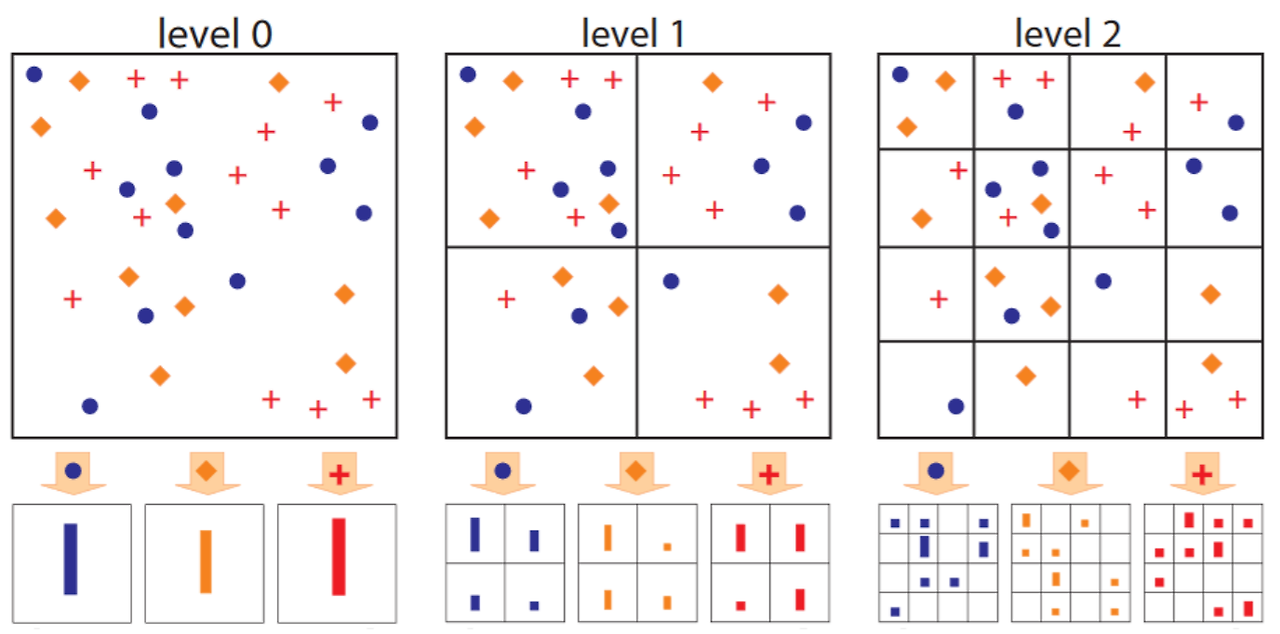
이는 이미지를 다양한 레벨에서 분할한 다음 local features를 계산하는 방식으로 진행됩니다.
논문에서 SPP를 CNN에 적용할 때, 놀랄만한 특징 3가지가 있다고 말합니다.
1). 인풋 이미지 사이즈에 상관없이 고정된 길이의 아웃풋을 생성한다.
2). multi-level spatial bins를 이용하므로, Object의 왜곡도를 줄여준다.
3). 다양한 스케일 정보를 추출한다.
논문에서는 실험을 통해 이러한 요소들이 모델의 성능을 높이는데 이바지 한다는 것을 증명했습니다. 또한, SPP를 통해 Overfitting을 방지할 수 있다고 합니다.
SPP를 기존에 존재하는 4개의 CNN 모델에 적용해본 결과 성능이 좋아졌다고 합니다.
이렇게 만들어진 SPP-Net은 ILSVRC 2014 대회에서 객체 탐지에서는 2등, 분류에서는 3등을 하게 됩니다.
R-CNN 모델보다 Detection 속도가 약 100배 가량 빨라짐과 동시에 성능도 올렸다는 점은 SPP가 모델 성능 향상에 얼마나 영향을 미치는지 알 수 있습니다.
2. DEEP NETWORKS WITH SPATIAL PYRAMID POOLING
✔ Convolutional Layers and Feature Maps

7개 층을 가지는 CNN 아키텍처를 생각해봅시다. 일반적인 CNN 모델의 경우 고정된 크기의 이미지를 입력받아야 합니다.
Convolutional layer는 5개이며, fully-connected layer는 2개 입니다. Convolutional layer는 입력 데이터의 크기에 따라 output feature map의 크기가 달라집니다. 즉, Convolutional layer는 이미지 크기에 상관없이 output 값을 도출해냅니다. 반면에, fully-connected layer는 입력 데이터의 크기가 고정되어야 합니다.

Convolutional layer의 경우 슬라이딩 필터 방식을 적용하여 'feature map'을 추출합니다.
이때, 각 필터는 특정 부분에 대해 강한 반응을 보일 수 있습니다.
예를 들어, 왼쪽 그림 (b)의 아래에 적용된 필터는 동그라미 모양에 더 반응하며, 오른쪽 그림 (b)의 위에 적용된 필터는 ∧ 모양에 더 반응합니다.
✔ The Spatial Pyramid Pooling Layer

앞에서 Convolutional layer는 들어오는 이미지 크기에 따라 최종 feature map 크기가 달라진다고 말했습니다. 그리고 SVM, fully-connected layer는 고정된 이미지 크기를 입력받아야 합니다.
논문에서는 이를 해결하기 위해 BOW(Bag of Word)를 응용합니다.
[ML] BOW Feature Vectorization
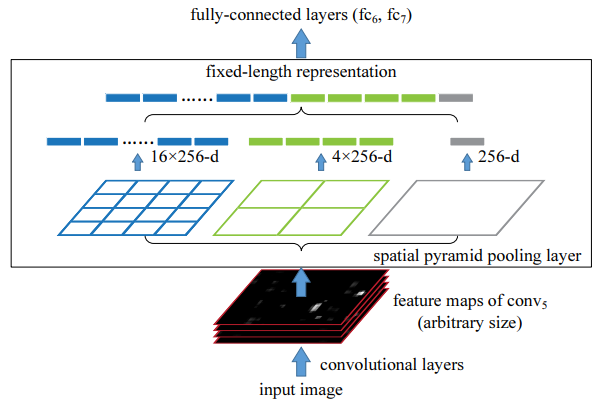
Spatial Pyramid Pooling 방식은 local spatial bins에서 풀링을 적용하기 때문에 공간적인 정보를 유지할 수 있습니다. local spatial bins란, "공간을 부분적으로 나눈 영역"이라는 의미입니다.
SPP는 입력 feature map의 크기에 상관없이 고정된 데이터를 반환해주며, 오로지 local spatial bins 설정에 의해 반환되는 데이터의 크기가 달라집니다.
나뉘어진 spatial bins마다 풀링을 적용해 주는데, 논문에서는 max pooling을 적용했습니다.
위 그림의 경우 5개의 Convolutional layer를 거친 feature map이 각각 1 X 1, 2 X 2, 4 X 4로 나뉜 local spatial bins에서 각각 풀링을 적용하여 최종적으로 5376(256 x 21)크기의 벡터가 만들어집니다.
반환되는 벡터의 크기는 local spatial bins 설정에 따라 바뀌며, 반환되는 벡터 크기를 공식으로 나타내면 다음과 같습니다.
k x M dimensional vectors
(k는 마지막 Convolutional layer 필터 수, M은 spatial bins의 수)
이렇게 SPP를 적용하면 어떤 이미지의 비율, 사이즈가 들어와도 상관없어지게 됩니다. (사실, 1 X 1 spatial bins만 가지는 경우에는 Global Average Pooling 방식과 동일합니다. 일반적으로 Global Average Pooling은 지도학습에서 많이 쓰입니다.)
✔ Training the Network

이론적으로 위 네트워크는 이미지 사이즈에 상관없이 오차역전파를 적용할 수 있습니다.
하지만, 학습 시 GPU를 효율적으로 사용하기 위해서는 고정된 이미지 사이즈를 입력받는 것이 좋습니다.
여기서는 SPP를 유지하면서 이러한 GPU 이점을 가지고 학습시키는 방법에 대해 설명합니다.
Single-size training

"Single size training"이란, 하나의 이미지 크기로만 훈련하는 방법을 의미합니다.
이전에는 이미지를 Crop하여 고정된 이미지를 모델에 학습시켰습니다. 입력 이미지의 크기가 일정하면 SPP에 필요한 bins 크기를 미리 계산할 수 있습니다.
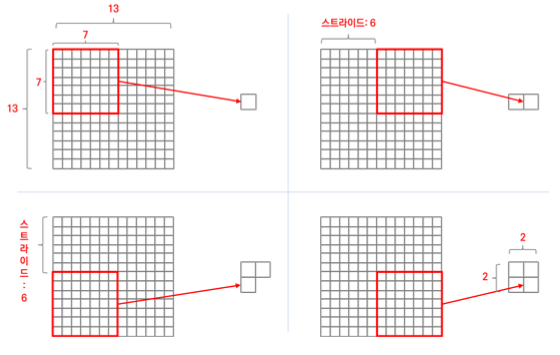
예를 들어, 5 layer의 Convolutional layer를 거쳐 13 X 13 feature map이 나온다고 가정합시다. 이때 2 x 2 크기의 saptial bins를 원한다면 window는 7, stride는 6으로 정하면 됩니다.
a x a 크기의 feature map에서 n x n 크기의 spatial bins를 원한다면, 이때 widow의 크기와 stride의 크기는 다음과 같습니다.
window(size) = ceiling(a/n)
stride(size) = fooling(a/n)
SPP를 거쳐 나온 다양한 vector는 다음 fully-connected layer에서 합쳐집니다.

위 사진은 3 level pyramid에서 각각 3x3, 2x2, 1x1 spatial bins를 원하는 경우, 계산된 window와 stride 크기를 보여줍니다. sizeX와 stride는 각각 window와 stride의 크기를 의미합니다.
Single-size training의 목적은 Multi-level pooling을 적용하기 위해서입니다.
Multi-size training

Multi-size training이란, 다양한 이미지 크기로 훈련하는 방법을 의미합니다.
논문에서는 224 X 224, 180 X 180 크기의 이미지가 들어온다고 가정했습니다.
(여기서 180 X 180 이미지는 224 X 224에서 resize한 것이므로 resolution만 차이가 있습니다.)
180 X 180 이미지의 경우 마지막 Convolutional layer를 거치면 10 X 10 feature map이 나오게 됩니다.
이때, Single-size training에서 살펴본 공식에 따라 window와 stride의 크기가 정해지게 됩니다. 224 X 224 이미지의 경우도 동일하기 때문에 최종적으로 같은 크기의 vector가 나오게 됩니다.
Multi-size training의 경우 180 X 180 이미지에 대해 전체 epoch를 수행합니다.
그 후 224 X 224 이미지에 대해 다시 한번 전체 epoch를 수행합니다. 이를 반복합니다.
이렇게 Multi-size training을 반복하면 Single-size training과 비슷해진다고 합니다.
Multi-size training의 주요 목적은 다양한 크기의 이미지 데이터에 대해서 학습하기 위함입니다.
이렇게 살펴본 Single/Multi-size training은 모두 '학습'을 위한 것입니다.
3. SPP-NET FOR OBJECT DETECTION

논문에서는 Object Detection에 SPP를 적용한 모델을 설명합니다.
이전 R-CNN의 경우를 살펴보자면, Object Detection에서 deep network는 각 윈도우의 피처를 추출하고, 이를 SVM으로 분류를 수행합니다.
이런 메커니즘은 Selective Search된 2000개의 윈도우가 모두 Convolutional layer를 거치기 때문에 시간이 너무 오래 걸린다는 문제가 있습니다.
SPP-net은 전체 이미지에서 feature map은 오직 한번만 추출합니다. 그리고 이렇게 추출된 feature map에서 선택된 영역에 대해 spp를 적용합니다. SPP-net은 다양한 형태의 윈도우를 추출할 수 있습니다.
✔ Detection Algorithm

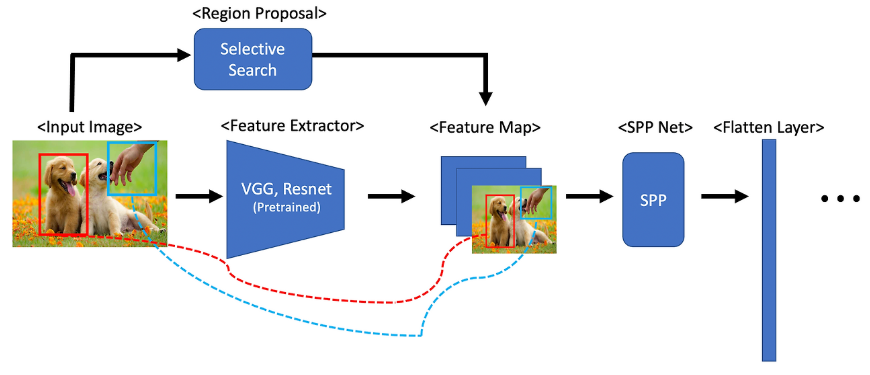
R-CNN과 마찬가지로 SPP-net도 Selective Search를 통해 하나의 이미지당 2000개의 영역을 뽑습니다. 다만, SPP-net에서는 이미지에 대해 한번의 합성 곱 연산을 진행하고 최종 feature map에서 2000개의 영역을 뽑습니다. 각 영역에 spp를 적용할 때, 4-level spatial pyramid를 사용합니다.(1x1, 2x2, 3x3, 6x6으로 총 50개의 bins가 생깁니다.)
이렇게 생긴 fixed vector는 SVM 모델의 입력 값이 됩니다.
또한, R-CNN에서는 backbone으로 AlexNet을 적용했지만, SPP-net의 경우 ZF-5 모델을 사용합니다.
Positive sample의 경우, ground-truth를 사용합니다. Negative sample의 경우, Positive sample과 IOU가 30%까지인 것들을 사용합니다.(0~30%) 또한, Negative sample끼리 IOU가 70%를 넘는 경우에는 제외 됩니다. SVM을 학습시키기 위해 standard-hard-negative-mining 기법을 사용했습니다.
최종적으로 SVM은 feature map에서 선택된 윈도우에 대해 점수를 예측하며, 이후에 NMS를 적용합니다.(threshold=30%)
(NMS 참고: [CV] IOU-NMS-mAP)
논문에서는 multi-scale feature extraction을 통해 모델의 성능을 더 올렸다고 합니다.
(480, 576, 688, 864, 1200 사이즈를 각각 학습시켰습니다.)
또한, 파인 튜닝도 적용시켰으며 이때 ground-turth와 IOU가 [0.5, 1]인 경우 Positive sample로, [0.1, 0.5)인 경우 Negative sample로 정의했습니다.
bounding box regression도 진행하였습니다.(ground-truth와 0.5 이상의 IOU를 가지는 경우에 대해서만 학습했습니다.)
✔ Detection Results
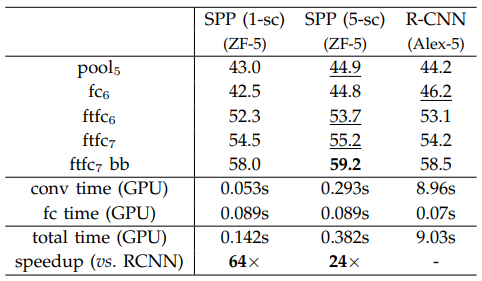
SPP-net은 R-CNN에 비해 높은 성능과 빠른 Detection time을 보여줍니다.
5 multi-scale feature extraction을 적용한 SPP-net의 경우, 기존 R-CNN보다 24배 빠른 Detection 속도를 보여주었으며 기존 map 58.5 -> 59.2로 높아지는 성능을 보여줍니다.
(참고로 성능 평가는 PASCAL VOC 2007 데이터를 기준으로 했습니다.)
single-scale feature extraction의 경우 map 58.0으로 기존보다 약간 떨어지긴 했으나, 64배 빠른 Detection 속도를 보여줍니다.
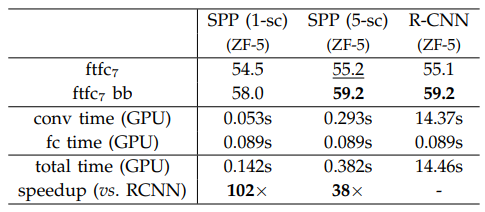
backbone을 같은 ZF-5로 사용한 R-CNN과 비교해보면, 5 multi-scale feature extraction을 적용한 SPP-net의 경우 기존보다 38배 빨랐으며 single-scale feature extraction의 경우 102배 빨랐습니다.
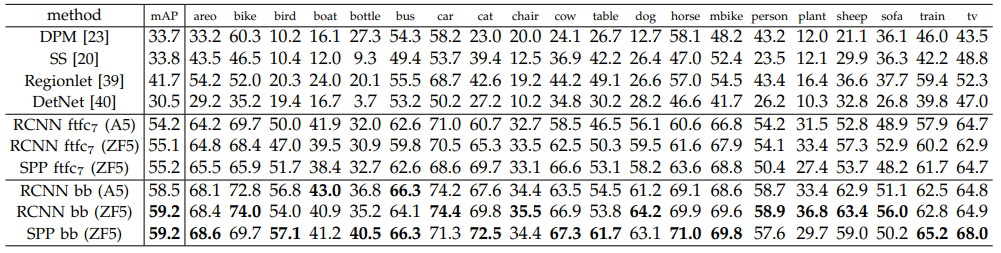

전체적인 성능 비교는 위와 같습니다.
✔ Complexity and Running Time

R-CNN과 비슷한 성능임에도 불구하고, 월등히 빠른 Detection속도를 보여줍니다.
R-CNN의 경우에는 O(n x 227^2)이라는 계산 복잡도를 가지고, SPP-net은 O(r x s^2)이라는 계산 복잡도를 가집니다. (n = window number(~2000), r = aspect ratio, s = 이미지 크기)
예를 들어 s = 688, r = 4/3이라고 가정하면 R-CNN보다 1/160의 복잡성을 가집니다. 5 scale의 경우에는 1/24의 복잡성을 가집니다.
기존 Selective Search 방식은 1~2초 정도의 시간이 걸렸지만, 최근에 나온 EdgeBoxes는 ~0.2초의 시간밖에 안 걸립니다. 따라서 논문에서는 이 둘을 이용해서, 학습 시에는 Selective Search와 EdgeBoxes를 모두 사용했습니다. 최종적으로 테스트 시에는 EdgeBoxes만 이용했습니다. 논문에서는 모델 테스트 시 EdgeBoxes만으로도 충분하다고 했습니다.
이렇게 만들어진 SPP-net은 모든 단계를 거칠 때, 하나의 이미지당 ~0.5초 정도의 Detection시간이 소요된다고 합니다.(2fps~)
4. Conclusion
SPP-net은 R-CNN에 Spatial Pyramid Pooling를 적용한 모델로, 성능과 Detection 시간 모두 올린 모델입니다.
고정된 크기의 이미지를 입력받았던 이전 모델들과는 달리 SPP를 적용해 multi-scale 이미지를 입력받을 수 있게 되었습니다.
SPP를 적용함으로써 합성 곱 연산 횟수가 대폭 감소하면서 Detection 시간을 대폭 감소시킬 수 있었습니다. 이렇게 감소된 Detection 시간은 Real-time-Detection을 가능하게 하는 원동력이 되었다고 생각합니다.
Reference
논문 리뷰 - SPP-net 톺아보기
[ML] SPP(Spatial Pyramid Pooling) Object Detection 모델
