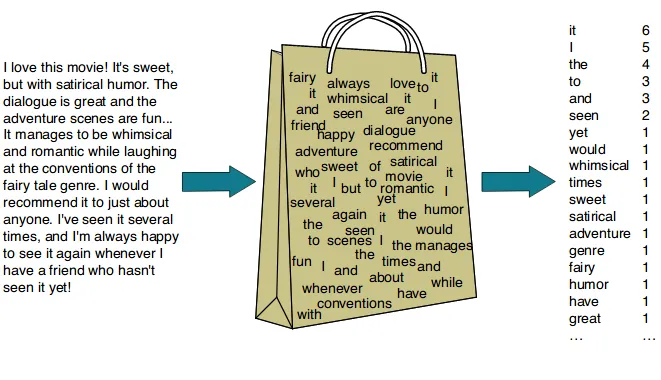
이번 장에서는 텍스트 분석에서 Feature Vectorization을 수행할 때, 사용하는 기법중 하나인 BOW(Bag of Words) 벡터화에 대해 공부하려고 합니다.
📚 Feature Vectorization
머신러닝 알고리즘은 일반적으로 숫자형 피처들을 입력 값으로 받아 동작합니다.
즉, 텍스트와 같은 데이터를 입력받기 힘듭니다.
그렇다면 텍스트는 모델에 어떤 식으로 입력될까요?
주어진 텍스트에 대해서 피처 벡터화를 수행하여 숫자형 피처들로 만들어주면 됩니다.
다시 말해, 텍스트에 대해 피처 벡터화를 수행한다는 것은 텍스트를 숫자형 피처들로 변환해주는 것입니다.
✅ BOW(Bag of Words)
BOW란, 단어들의 순서는 고려하지 않고 단어들의 출현 빈도에만 집중하는 텍스트 데이터의 수치화 표현 방법입니다.
BOW의 정의에서도 알 수 있듯이 장단점이 명확하게 나뉩니다.
장점
- 쉽고 빠른 구축
단점
- Semantic Context(문맥 의미) 반영 부족
- 희소 행렬 문제
문맥 의미를 파악하기 힘들다는 건 직관적으로 이해할 수 있습니다. 하지만, 희소 행렬 문제에 대해서는 좀 더 고민해 볼 필요가 있다고 느꼈습니다.
따라서 희소 행렬에 관한 내용은 마지막에 다룰 예정입니다.
(내용이 루즈해질 수도 있고, 제가 공부하는 책의 순서를 따라가기 위함입니다.)
일반적으로 BOW의 피처 벡터화는 카운트 기반의 벡터화, TF-IDF 이렇게 두 가지 방식으로 나눌 수 있습니다.
카운트 기반의 벡터화
카운트 기반의 벡터화는 단어 피처에 값을 부여할 때 각 문서에서 해당 단어가 나타나는 횟수를 부여하는 것으로 피처를 벡터화 합니다.
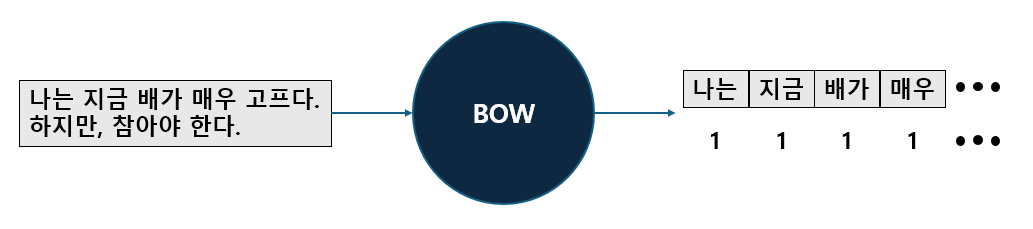
카운트 벡터화에서는 카운트 값이 높을수록 중요한 단어로 인식됩니다.
단순히 자주 나오는 단어일수록 높은 값이 나오는 것은 특별히 중요하지 않은 단어가 중요하다고 인식하게 될 수로 있습니다.
예를들어, '그리고'라는 단어는 문맥상 중요하지 않은 단어일 수도 있지만 많은 문장에서 나옵니다. 이런 문제를 보완하기 위해 TF-IDF 벡터화를 사용합니다.
TF-IDF 벡터화
TF-IDF는 개별 문서에서 자주 나타나는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 페널티를 주는 방식으로 값을 부여합니다.
여러개의 문서가 있을 때, 하나의 문서에서만 많이 나타나는 단어면 중요한 단어일 수도 있습니다. 하지만, 이 단어가 모든 문서에서 많이 나타나는 단어면 범용적으로 많이 쓰이는 단어일 가능성이 높습니다.
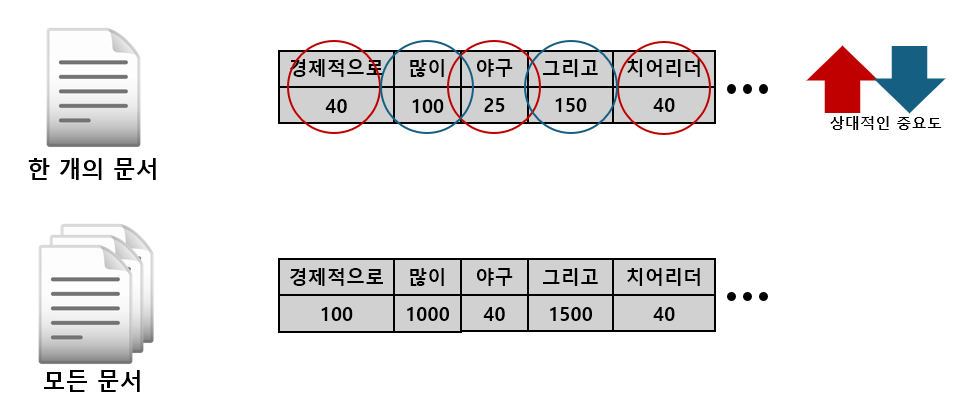
TF-IDF에서 단어의 중요도를 나타낼 때, 다음 공식을 이용합니다.

즉, 개별 문서에서의 단어 i 빈도가 크고 단어 i를 가지고 있는 문서 개수가 작을수록 중요도가 커집니다.(N은 여기서 고정값이라고 해도 무방합니다.)
문서마다 텍스트가 길고 문서의 개수가 많은 경웅 카운트 방식보다는 TF-IDF방식을 사용하는 것이 더 좋은 예측 성능을 보장할 수 있습니다.
✔️ Sparse Matrix(희소 행렬)
앞에서 BOW 방식은 희소 행렬 문제를 일으킨다고 했습니다.
희소 행렬이란, 행렬에서 대부분의 값이 0으로 채워지는 행렬 입니다.
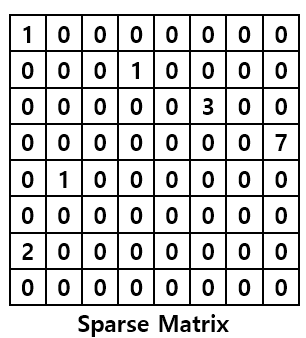
대량의 데이터에서(흔히, 비정형 데이터) 희소 행렬은 쓸데없이 많은 데이터를 잡아먹습니다. 또한, 모델의 속도를 느리게 만드는 원인이 되기도 합니다.
이런 희소 행렬을 물리적으로 적은 메모리 공간을 차지할 수 있도록 변환해야 하는데, 대표적인 방법으로 COO, CSR 형식이 있습니다.
COO(Coordinate) 형식
COO 형식은 0이 아닌 데이터만 별도의 배열에 저장하고, 그 데이터가 가리키는 행과 열의 위치를 별도의 배열로 저장하는 방식입니다.
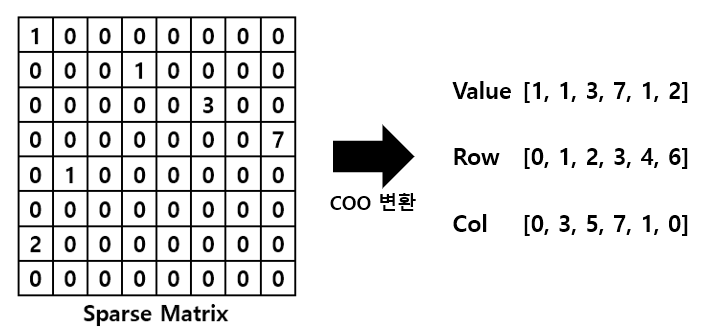
즉, 0이 아닌 값에 대해서만 데이터가 만들어지므로 더 효율적인 구조로 바뀌게 됩니다.
CSR(Compressed Sparse Row) 형식
CSR 형식은 COO 형식이 행과 열의 위치를 나타내기 위해서 반복적인 위치 데이터를 사용해야 하는 문제점을 해결한 방식입니다.
아래처럼 희소 행렬을 COO 변환했다고 해봅시다.
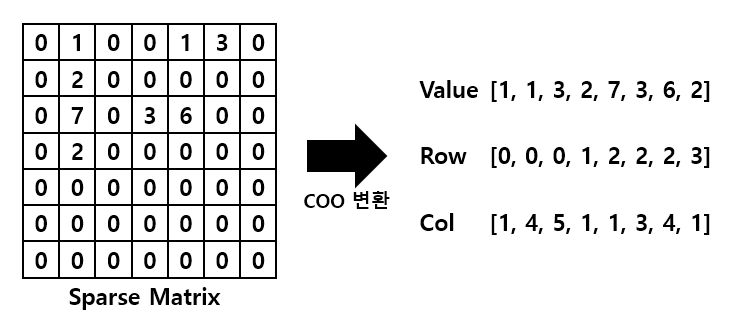
이때, 행의 위치를 나타내는 배열이 연속으로 중복된 값이 많이 나타남을 알 수 있습니다.
CSR은 이런 중복되는 위치 배열의 인덱스를 이용해 또 다른 배열을 만듭니다.
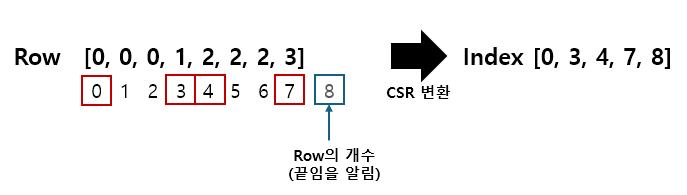
일반적으로 희소 행렬을 변환할 때, CSR 형식이 많이 쓰입니다.
아래에서 공부하겠지만, 사이킷런에서 피처 벡터화를 진행할 때 반환 값은 희소 행렬을 CSR형식으로 변환한 값입니다.
✅ CountVectorizer / TfidfVectorizer
사이킷런에서는 CountVectorizer와 TfidfVectorizer 클래스를 제공합니다.
두 클래스의 파라미터와 변환 방법은 동일합니다.
-
lowercase: 모든 문자를 소문자로 변환하는 작업을 수행하는 파라미터입니다.(default=True)
-
max_df: 전체 문서에서 너무 높은 빈도수를 가진 단어는 제외하기 위한 파라미터 입니다. max_df=100처럼 정수형을 입력하면 100개 이하로 카운트 되는 단어만 피처로 사용하며, max_df=0.95처럼 부동소수점 값을 입력하면 카운트 수 95%까지의 단어만 피처로 사용합니다.(상위 5%이내면 제외)
-
min_df: 전체 문서에서 너무 낮은 빈도수를 가진 단어는 제외하기 위한 파라미터 입니다. min_df=2처럼 정수형을 입력하면 전체 문서에서 2번 이하로 카운트된 단어는 제외합니다. min_df=0.02처럼 부동소수점 값을 입력하면 카운트 수 하위 2%의 값은 제외합니다.
-
max_features: 추출하는 최대 피처 수를 제어합니다. max_features=2000이면, 카운트가 높은 단어 순으로 정렬하여 2000개 까지의 단어만 추출합니다.
-
stop_words: stop_word를 적용합니다. stop_words='english'를 입력하면 영어 스톱워드를 적용합니다.
-
n_gram_range: 문맥상의 단점을 보완하기 위해 n_gram을 수행하는 파라미터 입니다. n_gram_range=(1, 2)로 지정하면 토큰화된 단어를 1개, 2개씩 묶어서 피처로 모두 나타냅니다.
-
analyzer: 피처 추출을 수행한 단위를 지정하는 파라미터 입니다. analyzer='word'를 입력하면 단어 단위로 피처를 만듭니다.
-
token_pattern: 토큰화를 수행하는 정규 표현식 패턴을 지정하는 파라미터 입니다.
-
tokenizer: 토큰화를 별도의 커스텀 함수로 이용시 적용합니다. analyzer='word'인 경우에만 적용 가능합니다.
이렇게 피처 벡터화까지 공부해봤습니다.
큰 그림으로 봤을 때, Raw 데이터에서 피처 벡터화까지의 과정을 나타내보면 다음과 같습니다.
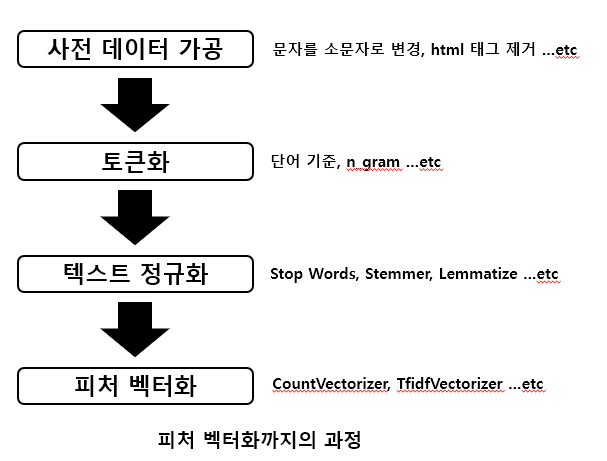
예를 들어, 제가 임시로 만든 데이터에 CountVectorizer를 적용하면 다음과 같습니다.
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
x_data = np.array([
'my name is chiyeon',
'my name is chiyeon',
'my name is chiyeon',
'he is chiyeon',
'chiyeon likes coffee',
'he is chiyeon',
'he is funny',
'chiyeon is great',
'my name is chiyeon'
])
vectorizer = CountVectorizer()
vectorizer.fit(x_data)
count_vectorized_array = vectorizer.transform(x_data)
print(count_vectorized_array)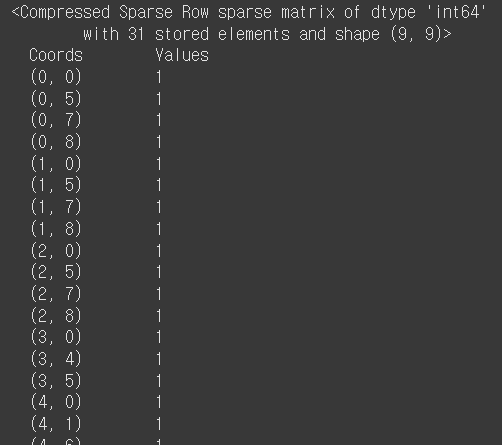
아래 오픈 소스를 보면 아시겠지만, 벡터화를 시키면 최종적으로 CSR 변환이 적용된 상태로 나오게 됩니다.
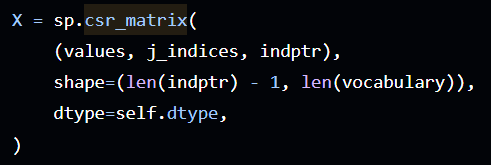
오픈 소스 위치는 여기를 클릭하시면 됩니다.(1303번째 줄)
이렇게 오늘은 Feature Vectorization중에서도 BOW에 대해 공부했습니다.
예상했던 것보다 필요한 개념이 많아 놀랐던 것 같습니다.
새롭게 희소 행렬에 대해 자세히 공부하게 되었으며, BOW의 종류에도 단순 count 방식과 TF-IDF방식이 있다는 것을 알게되었습니다.
최종적으로 그동안 공부했던 토큰화, 정규화 이후의 작업에 대해서 개괄적으로 파악하는 계기가 되었습니다.😊
📜 Reference
[개정판] 파이썬 머신러닝 완벽 가이드
An Introduction to Bag of Words (BoW)
사이킷런 CountVectorizer 공식 문서
사이킷런 TfidfVectorizer 공식 문서
