seaborn 이란?
seaborn은 파이썬의 데이터 시각화 도구이다.
Seaborn은 Matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화 패키지이다.
import seaborn as sns
# 이렇게 import 하여 사용한다.seaborn 깃헙에 있는 데이터를 가져와서 시각화에 사용 할 수 있다.
seaborn github : https://github.com/mwaskom/seaborn-data
iris = sns.load_dataset("iris") # 붓꽃 데이터
titanic = sns.load_dataset("titanic") # 타이타닉호 데이터
tips = sns.load_dataset("tips") # 팁 데이터
flights = sns.load_dataset("flights") # 여객운송 데이터pandas를 이용해서도 동일한 데이터를 불러 올 수 있다.
df = sns.load_dataset("anscombe")
df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/anscombe.csv")
#위 두 코드의 결과는 동일하다countplot
countplot 은 관측값의 카테고리별 갯수 즉 count 를 막대로 보여주는 plot 이다.
데이터 불러오기
titanic = sns.load_dataset("titanic") # 타이타닉호 데이터
titanic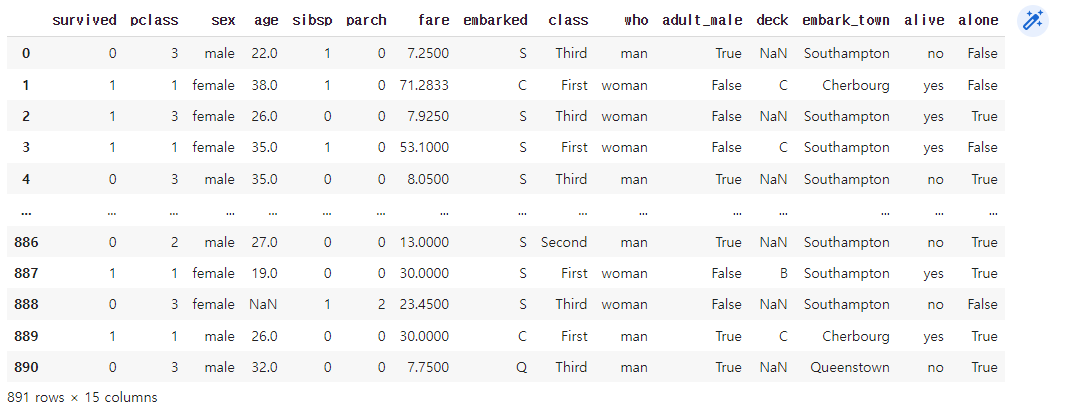
891개의 데이터가 있어서 하나하나의 데이터를 보며 의미를 찾아내기 힘들다.
특정 컬럼으로 묶어서 데이터를 확인 할 수 있다. (groupby)
groupby
titanic.groupby(["class"]).count()
"class" 로 묶여서 각 class 별 갯수를 나타내주고 있다.
titanic.groupby(["class", "sex"]).count()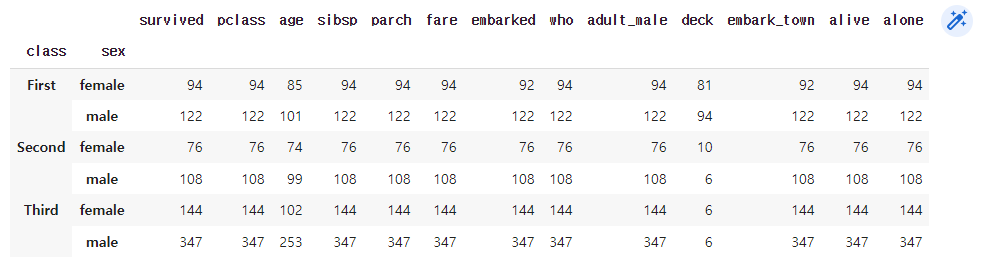
두가지 컬럼으로 groupby 해 줄 수도 있다.
위의 dataFrame은 class로 묶여진 데이터 안에서 sex를 나누어서 count 해준것이다.
countplot
이럴 때 시각화 하기 좋은 것이 countplot 이다.
일변량(univariate) 분석을 하는 plot 으로 범주형 변수의 발생 횟수를 센다.
http://seaborn.pydata.org/generated/seaborn.countplot.html
sns.countplot(data=titanic, x="class")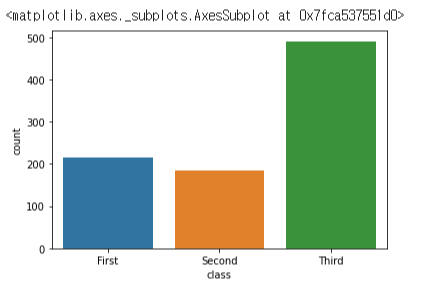
y 축 기준으로 보일 수 있도록 바꿀 수 있다.
sns.countplot(data=titanic, y="class")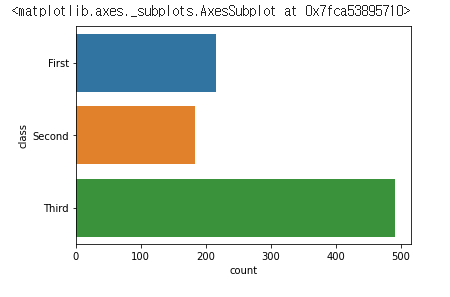
hue 를 사용하면 이렇게 두번째 grouping 을 시각화 하는 것도 가능하다.
sns.countplot(data=titanic, x="class", hue="sex")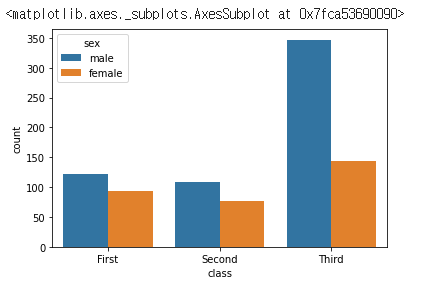
barplot
barplot 은 카테고리 값에 따른 실수 값의 평균과 편차를 표시하는 기본적인 바 차트를 생성한다.
평균은 막대의 높이로, 편차는 에러바(error bar)로 표시한다.
http://seaborn.pydata.org/generated/seaborn.barplot.html
데이터불러오기
df = sns.load_dataset("penguins")
df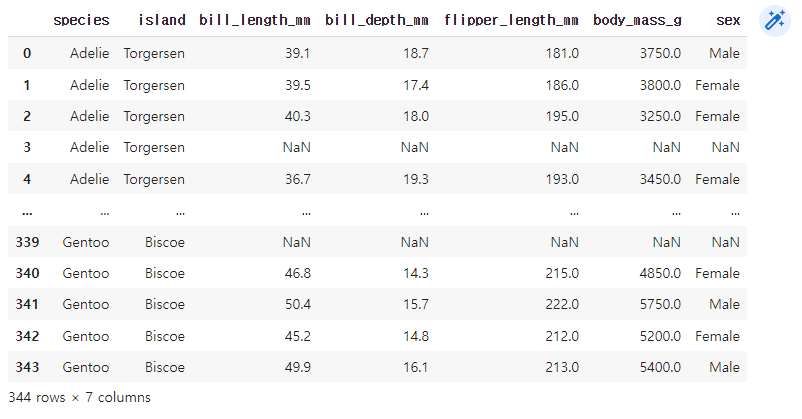
그냥 데이터를 보면 평균값을 알기 어렵다.
mean()
groupby 의 mean 함수를 사용하면 각 그룹의 평균을 계산해준다.
df.groupby("island").mean()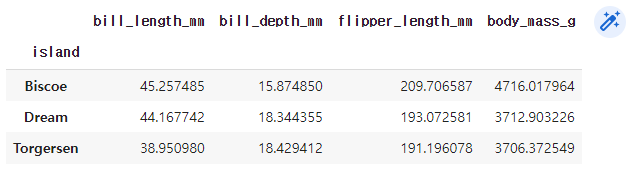
barplot
그리고 이 평균과 편차를 시각적으로 쉽게 나타내는게 바로 barplot이다.
barplot은 이변량 (bivariate) 분석을 위한 plot 으로
x축에는 범주형 변수, y축에는 연속형 변수를 넣는다.
sns.barplot(data=df, x="island", y="body_mass_g")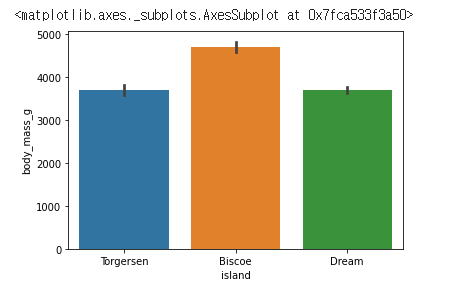
해당 차트는, "island" 별 "boss_mass_g"의 평균과 편차를 나타낸 것이다.
까만 줄은 errorbar 로 신뢰구간을 나타내는데, 변수 설정으로 없애거나 표준편차를 표현 할 수 있다.
# cd = "sd" 설정으로 에러바를 표준편차로 설정한다.
sns.barplot(data=df, x="island", y="body_mass_g", ci = "sd")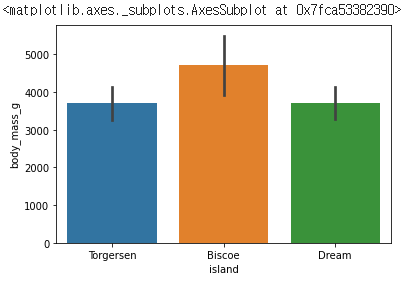
# ci = None 으로 에러바를 설정하지 않는다.
sns.barplot(data=df, x="island", y="body_mass_g", ci = None)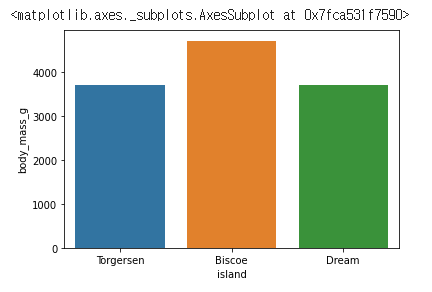
ci 도 같이 실행을 하면 시각화 하는데 시간이 오래 걸려서 ci = None 으로 설정하고 시각화 하는걸 추천한다.
이런 barplot은 데이터가 어떤 모양으로 얼마나 퍼져있는지 분포가 확인이 안된다는 문제점을 가지고 있다.
BoxPlot
boxplot 은 일변량, 연속형 데이터의 분포를 설명하기 위해 사용되는 그래프이다.
boxplot 은 데이터 분포를 사분편차 통계치를 시각화하는 방식으로 데이터의 분포를 간략하게 파악하기 좋은 방식이다.
boxplot 을 이해하려면 사분편차를 알아야 한다.
사분편차는 자료를 크기순으로 정렬하고, 그 자료 분포의 1/4의 해당하는 자료값과 3/4에 해당하는 자료값의 차이를 반으로 나눠준 값을 말한다. 즉 양 끝단의 데이터는 제외하고, 가운데에 몰려있는 50%의 데이터 분포를 보려고 하는 통계 방식이다.
사분편차가 크다는 것은 분포가 크게 퍼져있다는 것이고,
사분편차가 작다는 것은 데이터가 몰려있다는 의미이다.

boxplot 은 이를 그래프화 시킨거다.
| 값 | 의미 |
|---|---|
| Q1 | 데이터의 1/4 값 |
| Q2 | 데이터의 4/3 값 |
| M | 데이터의 1/2값으로 중앙값 |
| IQR | Q1과 Q3 범위의 차이 |
| box 에 달린 수염 | Box whisker 라고 부르며 보통 IQR의 1.5배이다. |
| box plot 밖에 값 | 아웃라이어라고 부르며 이상치이다. |
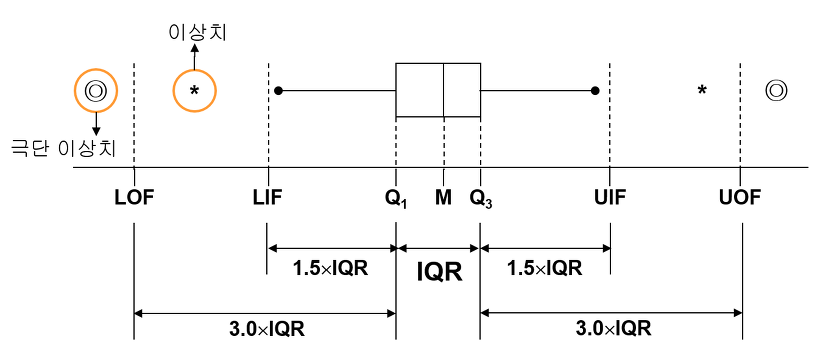
boxPlot 예시
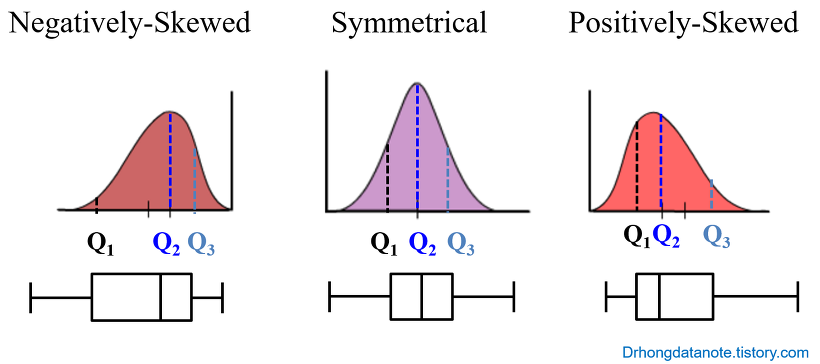
참고자료
https://drhongdatanote.tistory.com/30
seaborn으로 실습해보기
titanic = sns.load_dataset("titanic") # 타이타닉호 데이터
# 타이타닉에 탄 사람들의 나이를 boxplot 으로 표현하기
# 아래의 두 코드는 결과가 같다.
sns.boxplot(x=titanic["age"])
sns.boxplot(data=titanic, x="age")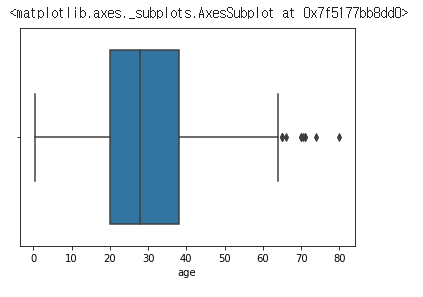
타이타닉에 탄 사람들의 나이 전체를 사분위로 표현했다.
boxplot도 group화 할 수 있다.
일변량 질적 자료
타이타닉에 탄 사람들을 class 별로 x 축으로 나누고,
age 를 사분위로 나타내는 코드이다.
sns.boxplot(data=titanic, x="class", y="age")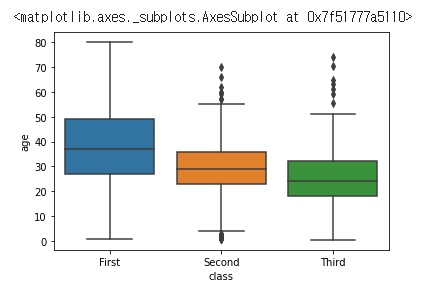
클래스별, 나이 사분위 분포를 알 수 있다.
위에서 봤던 펭귄들의 island 별 body_mass_g 의 사분위를 나타내는 코드이다.
sns.boxplot(data=df,x="island", y="body_mass_g")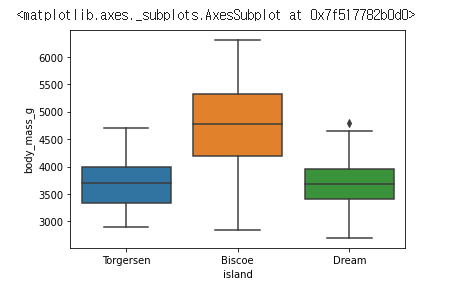
island 별로 group 화 되어 사분위가 나타나지는걸 볼 수 있다.
이변량 질적 자료
hue 파라메터를 이용하여, 2가지 변수에 대한 group 화도 할 수 있다.
sns.boxplot(data=titanic, x="class", y="age", hue="sex")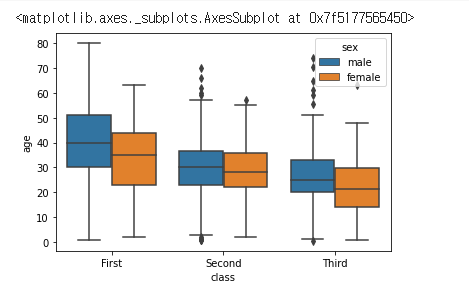
violinplot
violinplot 은 boxplot 과 동일하게
일변량, 연속성 데이터 분포를 설명하기 위한 그래프이며
커널 밀도 곡선과 boxplot 을 합친 형태이다.
카테고리값에 따른 각 분포의 실제 데이터 또는 전체 형상을 보여준다는 장점이 있다.
제대로 이해하기 위해서 먼저 KDE(커널 밀도 추정)에 대해서 알아보자.
밀도추정
관측 확률에 대한 빈도 분석을 통해 변수가 전체적으로 어떤 확률적인 특성을 나타내는지 파악하여, 그 확률정 특성이 변수의 특성이라고 추론하는 방법을 밀도 추정이라고 한다.
밀도 추정을 이해하기 쉽게 설명하자면, 추출된 데이터들을 통해서 확률 밀도함수를 구하는 행위이다.
확률 밀도함수는 확률 변수의 분포를 나타낸 함수인데,
구간 [a, b]에서 확률변수 X가 해당 구간에 있을 확률을
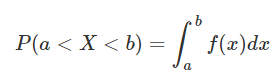
로 나타낸 함수이다.
월요일의 아침부터, 일요일 밤까지 24시간 365일 특정 구간의 차량 통행량 데이터를 집계한다면, 평균 데이터를 얻어서 1주일을 주기로 histogram을 만들 수 있다. 그렇다면 우리는 이 데이터를 통해 대략적으로 어느 시간대에 차량이 많이 통행하는지, 적게 통행하는지 알 수 있고, 그 데이터를 역으로 활용한다면 차량 한 대가 이 도로를 지나간다고 했을 때, 어떤 요일의 어떤 시간대에 통행했을 확률이 몇%인지 구할 수 있다.
이것이 Dessity estimation(밀도추정)이다.
히스토그램
히스토그램은 연속형 자료에 대한 도수분포표를 시각화한 그래프이다.
연속형 자료를 계급으로 나누어 계급별 도수를 막대로 나타낸다.
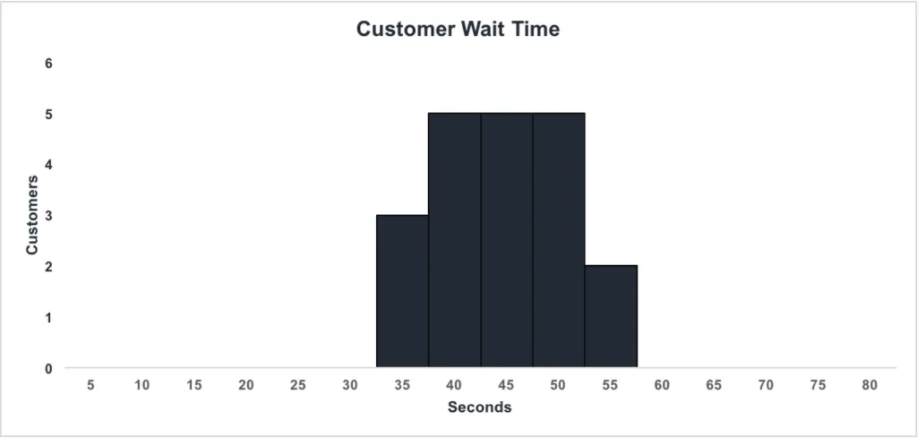
히스토그램과 막대그래프는 헷갈릴수 있다.
막대그래프는 자료의 범주별 빈도를 요약해서 나타낸 그래프로, 범주별 많고 적음을 나타내기 좋다.
히스토그램은 연속적 데이터를 구간(bin)으로 나누고, 그 각각의 분포를 나태내기위한 도구이다.
히스토그램 방식의 문제점
- bin(구간)의 경계에서 불연속성이 나타난다.
- bin의 크기나 시작 위치에 따라서 히스토 그램이 달라진다.
- 고차원 데이터에는 메모리 문제로 사용이 힘들다.
- 가장 큰 문제점은, 히스토그램은 구간을 어떻게 설정하냐에 따라 결과물이 매우 달라져서 엉뚱한 결론과 해석을 내릴 수 있어서 조심해야 한다.
KDE(커널밀도추정)
밀도 추정 방법 중 하나로, 커널함수를 이용하여 히스토그램 방법의 문제점을 개선한 방법이다.
데이터마다 그 데이터를 중심으로하는 특정 모양의 확률곡선을 그린다고 생각하면 된다.
커널 함수의 특징은
- 적분값이 1일이다.
- 중앙을 기준으로 대칭이다.
- 양수값만을 가진다.
이런 커널 함수를 가지고 하는 커널 밀도 추정은 다음과 같다.
- 관측된 데이터 각각마다 해당 데이터 값을 중심으로 하는 커널 함수를 생성한다. K(x-xi)
- 이렇게 만들어진 커널 함수들을 모두 더한다.
- 전체 데이터 갯수로 나눈다. (확률밀도곡선의 적분 값이 1이라서)
KDE를 통해 얻은 확률 밀도 함수는 히스토그램 확률밀도함수를 스무딩 한 것으로 볼 수 있다. 스무딩 한 정도는 어떤 커널 함수를 사용했느냐에 따라 달라진다. 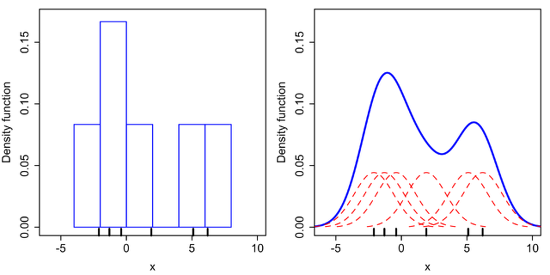
KDE plot
seaborn 으로 KDEplot 도 그려볼 수 있다.
df = sns.load_dataset("penguins")
sns.kdeplot(data=df, x="body_mass_g")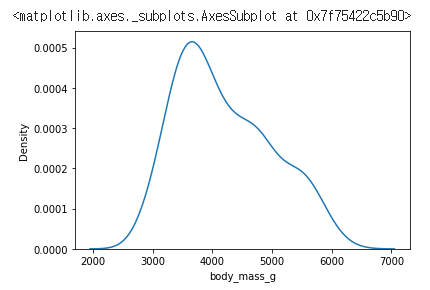
펭귄들의 body_mass_g를 KDE 그래프이다.
만약 이를 히스토그램으로 나타냈다면 아래와 같다.
df.hist(bins=10, column="body_mass_g")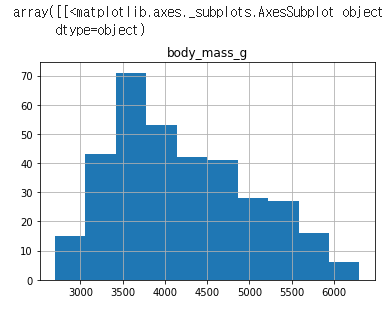
KED 밀도추정이 히스토그램의 스무딩 버전이라는게 와닿는다.
KDEplot도 hue 를 통해 group 화 하여 그래프를 나타낼 수 있다.
sns.kdeplot(data=df, x="body_mass_g", hue="island")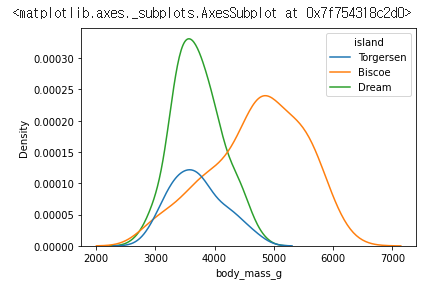
island 별 body_mass_g의 분포를 알 수 있다.
참고자료
https://junklee.tistory.com/9
KDE와 히스토그램에 대해 알 수 있는 자료
https://challenge.tistory.com/28
밀도추정
https://gnaseel.tistory.com/34
느낀점
아니...
boxplot을 이해하려면 4분편차에 대한 개념이 있어야 하고는데 그런것도 없고,
violinplot 을 이해하려면 커널 밀도 추정도 알아야 되고, 커널 밀도 추정을 알려면, 밀도추정도 알아야 하고! 히스토 그램도 알아야 되는데...
이해가 안되는게 당연한거 아닌가ㅜㅜㅜㅜ???
참고자료
자료에 대한 개념
https://blog.naver.com/PostView.nhn?blogId=tmdwls379&logNo=222044520761
어떤 데이터에 어떤 그래프를 그려야하는지
https://junklee.tistory.com/9?category=875761
