멋사AI
1.[day5][멋사AI] 판다스 정리

데이터 타입이 하나라도 바뀌면 전체 serise 의 타입도 바뀐다.데이터 중에 하나가 np.nan 일 경우 전체 타입 dtype: float64axis 0:행, 1:컬럼을 의미합니다.df = df.drop("종류2", axis=1) method traning 할 때 잘
2.[day6][멋사AI] Seaborn 복습하기
seaborn은 파이썬의 데이터 시각화 도구이다.Seaborn은 Matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화 패키지이다.seaborn 깃헙에 있는 데이터를 가져와서 시각화에 사용 할 수 있다.df = sns.load_data
3.[day7][멋사AI] python 함수의 return
return은 함수의 결과값을 돌려주는 명령어이다함수의 결과값은 return 명령어로만 돌려 받을 수 있다.return을 함수에서 선언하지 않을 경우 결과값이 없으므로 None이 반환된다.함수의 결과값은 하나다!함수 내에 return이 여러개 있어도 하나의 return
4.[day8][멋사AI] mysql 기초
실제 데이터 분석 환경은 mysql 을 많이 사용한다. 이미 기업들이 mysql 을 사용하는 곳이 많기 때문인듯.sqld 자격증은 별로 소용이 없다. 실제로 데이터 분석을 할 때 사용하는 sql 과는차이가 좀 있기 때문이다. 데이터 분석가가 되려면 서브쿼리, 윈도우 함
5.[day9][멋사AI] 추상화도구로 기술통계
EDA는 Exploratory Data Analysis의 약어로 탐색적 데이터 분석을 뜻한다. 데이터를 분석하고 결과를 내는 과정에 있어서 지속적으로 해당 데이터에 대한 ‘탐색과 이해’를 기본으로 가져야 한다는 것을 의미한다.참고자료EDA에 대한 통찰EDA 개념 및 종
6.[day10][멋사AI] 수치형,범주형 데이터별 시각화 하기
데이터 통계 분석 방법은 자료의 속성과 분석의 목적에 따라 달라진다. 따라서 자료에 대한 이해와 자료의 속성을 잘 파악해야만 적절한 통계 분석 방법을 적용할 수 있다. 수치형자료는 관측된 값이 수치로 측정되는 자료를 말한다. 양적자료(Quantitative Data)라
7.[day12][멋사AI] 추상화 도구 복습
전체적인 시각화 데이터를 쉽게 그려보기 좋다.pandas profiling 공식pandas profiling githubpandas profiling 참고자료ProfileReport 의 사용법은 아래와 같다.프로파일링 실제로 볼 수 있는 예제 urlOverview 를
8.[day13][멋사AI] SQL 중급
해커랭크, 리트코드 에서 문제를 풀어볼거다. 목표 : 프로그래머스의 고득점sql 키트 를 풀 수 있도록 하는 것https://www.hackerrank.com/dashboardhttps://www.w3schools.com/sql/trysql.asp?f
9.[멋사AI] 미니프로젝트 : 웹 스크랩핑하고 데이터 분석하기!!
수업에서 실습을 할 때 주식 및 금융 데이터로 분석을 했었기 때문에 그렇다면 부동산을 해볼까?는 생각으로 '부동산 데이터' 로 설정하고 스크랩핑 및 EDA 분석을 진행하기로 했다. 대부분의 부동산 데이터들이 지도상에 표기가 되어 있어서 스크랩핑을 할 수 없었다. 스크랩
10.[day14][멋사AI] 데이터수집
여기서 데이터 수집을 할거다.https://opengov.seoul.go.kr/civilappeal/list링크를 추출 할 수 있다. https://www.seoul.go.kr/sgnb/getGnbJson.do?callback=jQuery1111027
11.[day15][멋사 AI] plotly
map apply apply map 많이 사용하게 된다. 문서 참고하기 https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html 더 쉬운 문서 https://pandas.pydata.org/pand
12.[스터디][멋사 AI]
list.sort(\*, key=None, reverse=False)리스트의 항목들을 제자리에서 정렬합니다 (인자들은 정렬 커스터마이제이션에 사용될 수 있습니다.)리스트만 가능리스트를 직접 정렬하고 None 리턴sorted(iterable, /, \*, key=None
13.[AI]기초통계
데이터 분석가는 의사결정권자에게 정보를 주는 사람이다. QnA데이터 분석가가 통계를 많이 알면 좋은가?너무 복잡한 통계를 얘기하고자 하면 의사결정권자가 이해를 못할 수 있다. 통계를 생각보다 많이 공부하지 않아도 된다. 의사결정권자에게 많이 설명 하지 않아도 되서...
14.[221014][AI] SQL union
union 은 세로로 데이터를 붙여주고, 중복값들을 없앤 데이터를 반환한다. union all 은 중복 포함 전체를 보여준다. Symmetric Pairs 문제풀기나는 x!=y 인 경우로 조인을 했는데, 그냥 조인 한다음에 x!=y 경우를 제거해도 되는거였다!!순서 정
15.[멋사][AI] 심평원 자료 스터디
출처파이썬을 활용한 데이터AI 분석 사례회귀분석 63~, 결정트리와 앙상블 86~100,𝑥와 𝑦변수 간에 관계가 어떤 선형적인 관계를 갖고 있는지를 파악하고, 두 변수가 변하는 패턴이 얼마나 비슷한가를 확인하는 과정이 상관분석이다. Q. 왜? 범주형 자료에 한하여라
16.[멋사][AI] 결정트리, CART
참고 \[ML] 결정트리(Decision Tree) - 기본구조와 CART, ID3 알고리즘 의사결정 나무 (Decision Tree) 기본 설명 결정 트리 학습법 - 위키백과, 우리 모두의 백과사전결정 트리 학습법은 머신러닝 지도학습에서 가장 유용하게 사용되고
17.[멋사][AI] 앙상블(Ensemble)
결정트리의 단일 모델의 한계점을 해결하기 위해서 의사결정 나무를 여러개 만들어서 예측 결과를 종합하는 앙상블(Ensemble)알고리즘을 사용한다. 참고 앙상블 (Ensemble)의 기본 개념여러 개의 weak learner들이 모여 투표 (voting)를 통해 더욱
18.[멋사][AI] 앙상블 모델
참고 GBM(Gradient Boosting Machine) 부스팅 앙상블 (Boosting Ensemble) 2-1: Gradient Boosting for Regression여러 개의 약한 학습기(weak learner)를 순차적으로 학습 → 예측을 하면서 잘못
19.[멋사][AI] 앙상블 실습
data set : Pima Indians Dataset 이용인슐린 수치 결측치(0) 채우는 전처리만 진행 이전실습 에서 전처리 코드 확인 가능회귀는 수치형 데이터를 예측하는 것이므로 전처리와 label_name 을 바꿔줘야 한다. 전처리
20.[Dacon][대회] 구내식당 식수 인원 예측 AI 경진대회 도전
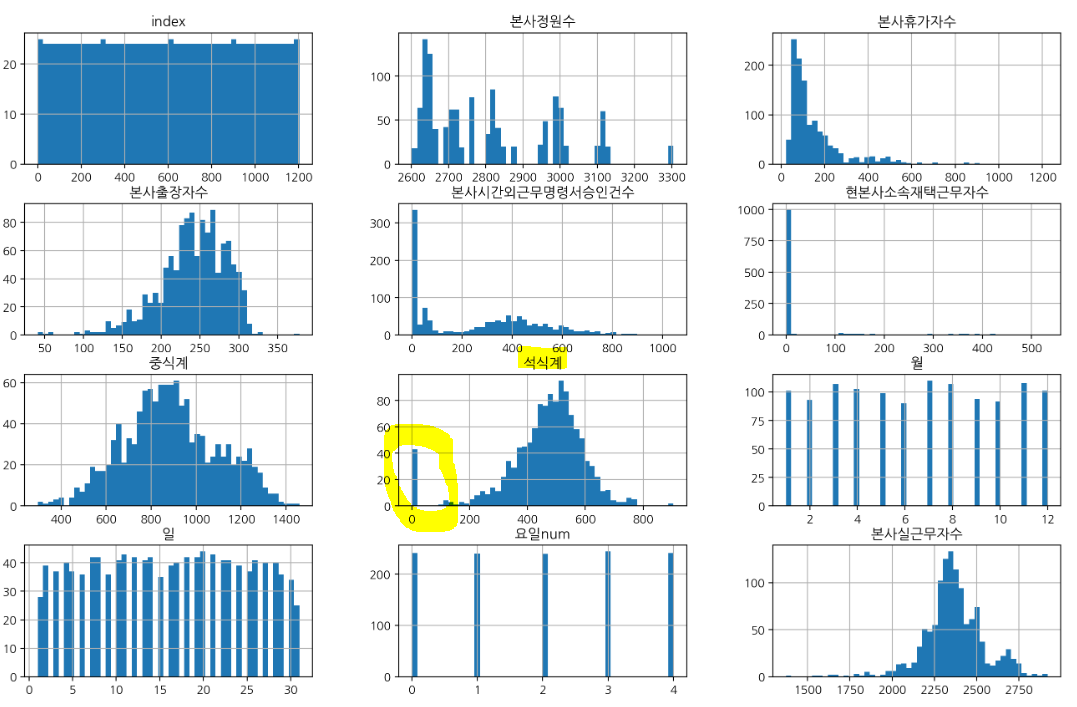
구내식당 식수 인원 예측 AI 경진대회 링크histogram 으로 확인한 결과, 석식계에 0값이 많아서 이를 파생변수로 만들어주기로 했다.이거를 하고 석식계 점수가 많이 올랐다. (60점대에서 70점대로!)lunch model importances 시각화dinner m
21.[멋사][AI] TIL - RMSLE, emp
one-hot-encoding => pd.get_dummies()ordinal-encoding => category 데이터타입으로 변경하면 ordinal encoding 을 할 수 있다.점수(rmsle)가 43 -> 47로 높아짐. 성능이 안좋아졌다. 도움이 안되는 피
22.[멋사][AI] TIL - 스케일링
표준화(Z-score) : 평균을 빼주고 표준편차로 나눠준다. (X - X.mean) / std평균이 0표준편차가 1평균을 이용하여 계산해주기 때문에 이상치에 영향을 받는다. (평균: 이상치의 값에 크게 영향을 받기 때문)Min-Max : 0~1 사이값으로 만든다. (
23.[멋사][AI] Bike Sharing Demand (1) EDA
Bike Sharing Demand점수 평가 기준 : RMSLE대회 이름에 demand가 들어가면 대부분 수요예측 문제이다.Data Fields(컬럼 설명)datetime - hourly date + timestamp ▶️시간 season - 1 = spring
24.[멋사][AI] 데이터 분석에서 정규 분포 활용 정리
데이터 분석 - 정규 분포 활용참고 비대칭(skewed) 데이터를 처리하는 3가지 방법 / Skewed Data \[ML] 데이터 스케일링 (Data Scaling) 이란? \[sklearn] 데이터 전처리 - 피처 스케일링 & 정규화 Pandas에서 데이터 정규화 하
25.[멋사][AI] 221114
22.11.14 701 실습\_ = test.hist(figsize=(20,16), bins=50)histogram 의 목적수치데이터의 분포 확인왜도 -> 너무 한쪽이 치우쳐져 있지는 않은지 확인첨도 -> 한쪽에 데이터가 너무 몰려있지 않는지 확인막대가 떨어져 있다면
26.[멋사][AI] 221115
221115결측치처리 고민결측치가 너무 많다고 삭제를 하는게 나은 방법이 아닐 수 있다. 이상치, 특잇값을 찾는다면 오히려 특정 값이 신호가 될 수도 있다. 번주형 값이라면 결측치가 많더라도 채우지 않고 인코딩 해주면 나머지 없는 값은 알아서 0으로 채워지게 된다. 그
27.[멋사][AI] Mercedes-Benz Greener Manufacturing 실습
221116801 실습Mercedes-Benz Greener Manufacturing 링크802 실습 : 다른 트리모델도 사용해보는게 목표DecisionTreeRegressorRandomForestRegressorGradientBoostingRegressorExtraT
28.[멋사][AI]
참고 점프 투 파이썬 Loss Functions 손실함수(loss function), Cross Entropy Loss주로 딥러닝에서 쓰인다. 분류 클래스가 2개인 로지스틱 함수를 클래스가 n개일 때로 확장한 것이 딥러닝에서 주로 사용하는 softmax function
29.[멋사][AI] boosting 3e대장실습! with Benz 데이터셋
복습하기!Kmooc 강의중 4강, 8강, 10강, 11강 듣기실습으로 배우는 머신러닝(http://www.kmooc.kr/courses/course-v1:SSUk+SSMOOC20K+2022_T1/course/배깅 => 오버피팅부스팅 => 개별 트리의 성능이 중
30.[멋사][AI] ML 불균형 데이터 SMOTE 와 분류 측정지표
현실 데이터들은 굉장히 치우쳐 있는 경우가 많다. 예를들면 검사자중에 0.15% 만이 암환자다. 그렇다면, '암환자다 아니다'라고만 하면 정확도가 99.85%가 된다. 이런경우에 정확도 이외에 다른 측정지표가 필요해진다!불균형 데이터 예시 : 코로나 검사결과, 암환자
31.[멋사] [AI] 분류성능평가지표 - Confusion matrix
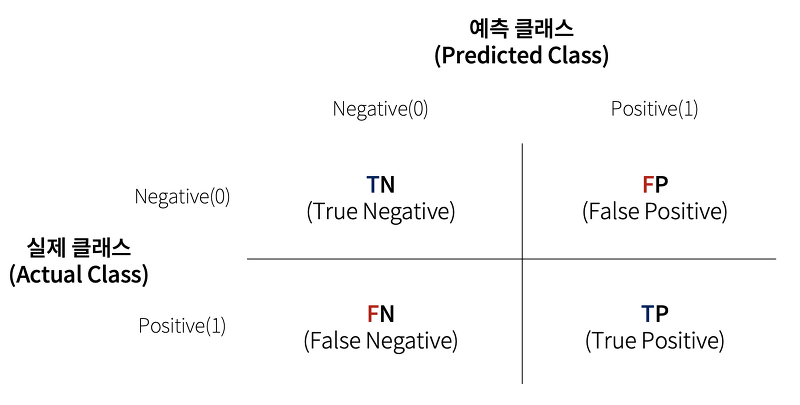
혼동행렬은 분류 모델의 성능을 평가하는 지표로 영어로는 confusion matrix라고 하며 혼돈행렬, 오차행렬, 정오행렬, 오분류표 등으로도 불린다.Confusion Matrix 는 예측 오류가 얼마인지와 더불어 어떤 유형의 예측 오류가 발생하고 있는지를 나타내는
32.[멋사] [AI] 코딩테스트 준비
결코 단시간에 되지 않는다. 하지만 충분히 재미있게 여행할 수 있습니다. 개념을 정의하고 외우는 것 보다, 반복된 훈련과 시간으로 알고리즘에 익숙해 지는게 가장 좋다. (- 매일 프로그래머스문제풀기)매일매일의 훈련으로 차이를 만들어가자알고리즘이란: 생각하는 방법, 일련
33.[멋사] [AI] 분류평가기준 & Credit Card Fraud Detection 실습
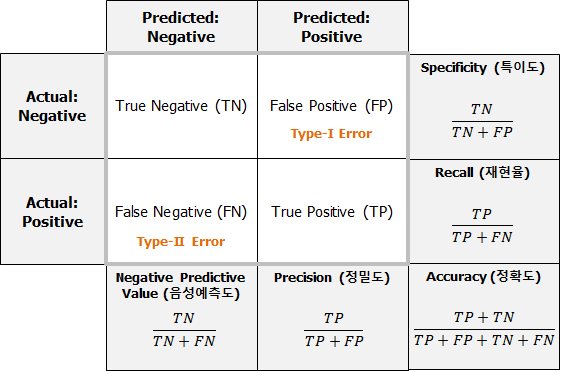
Q.정확도로 제대로 된 모델의 성능을 측정을 하기 어려운 사례는 어떤게 있을까?클래스가 불균형한 데이터일 때, 제대로된 평가를 내리기 어렵습니다. 희귀병의 검사 결과 등불량품검출스팸메일 분류금융 => 은행 대출 사기, 신용카드 사기, 상장폐지종목 여부제조업 => 양불
34.[멋사][AI] 딥러닝 비기너 실습
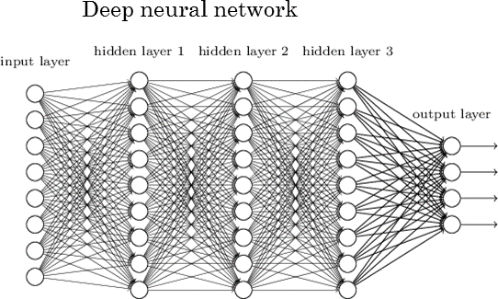
지금은 처음이라 생소하지만, 앞으로 보다보면 익숙해지겠지! 라고 생각해보자.누구에게나 처음은 어렵다. 딥러닝은 데이터 전처리 과정을 포함한다. 즉, 딥러닝은 비정형 데이터로도 학습이 가능하다.
35.[멋사][AI]
Q. loss, metric 의 차이는 무엇일까?A. loss 는 실제값과 예측값이 얼마나 다른지를 나타냅니다. metric은 얼마나 잘 예측했는지를 나타내는 평가 지표입니다.loss는 훈련에 사용해서 가중치와 편향을 업데이트하고, metric은 검증에 사용한다.los
36.[멋사][딥러닝] 합성곱 신경망 (CNN)

Dense 가 1인 경우 회귀 모델이라는 것을 모델이 어떻게 알 수 있을까?A. loss 함수로 알 수 있다. 분류에서 units이 2개라면 softmax 로 반환받는게 맞다. 이 때는 둘 중에 확률 값이 높은 값을 선택해서 사용한다. 멀티클래스 예측값이 나왔을 때 가
37.[멋사][딥러닝] 데이터 증강 & 말라리아 실습

tensorflow cnn 이미지 분류해당 튜토리얼은 꽃 5가지 이미지를 학습하고 분류하는 예제다. 'daisy', 'dandelion', 'roses', 'sunflowers', 'tulips' 5가지 꽃을 분류해 본다.Q. 이미지 사이즈가 다 다르면 계산을 할 수
38.[멋사][AI] 전이학습 & 날씨이미지 분류

이미지 증강을 할 때 주의해야 할 사항이 있다면?노이즈를 확대하거나 크롭하면 문제가 된다.6을 180도 돌리면 완전히 다른 의미인 9가 되기 때문에 이런 숫자 이미지는 돌리지 않는다.색상이 중요한 역할을 하는 이미지일 경우에 색상 반전 혹은 변경을 하면 안된다.신호등,
39.[멋사][AI] 딥러닝 모델 - LeNet
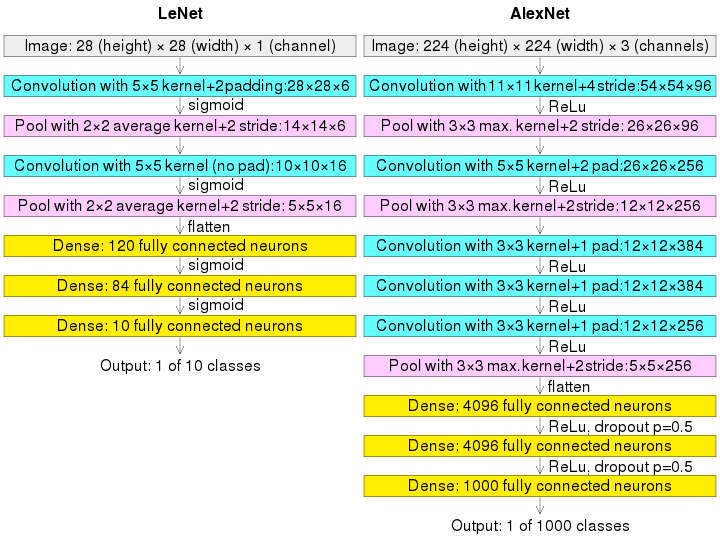
참고LeNet-5 논문 리뷰, 구현(tensorflow)딥러닝 텐서플로 교과서: 6.1.1 LeNet-5\[CNN 알고리즘들] LeNet-5의 구조LeNet - WikipediaLeNet은 CNN을 처음으로 개발한 얀 르쿤(Yann Lecun) 연구팀이 1998년에 개
40.[멋사][AI] CNN, RNN
이번주 목요일에는 보강이 있습니다. 다음주 수요일에도 보강이 있습니다.CNN은 주로 이미지에 주로 사용이되고 물론 텍스트에도 사용을 합니다. 하지만 이미지에서 더 나은 성능을 보여줍니다.텍스트 분석을 할 때 머신러닝(Bag Of Words, TF-IDF), 딥러닝(RN
41.[멋사][AI] 텍스트분석과 자연어처리
자연어 처리 활용스팸메일분류, 뉴스기사 분류고객센터 비슷한 문의끼리 모으기뉴스 기사로 주가 예측등등딥러닝 연습?하기좋은 데이터셋이미지 : MNIST, FMNIST, cifar10텍스트 : IMDB, 영화리뷰 데이터셋, 네이버 영화리뷰 데이터셋<기본용어 >말뭉치(C