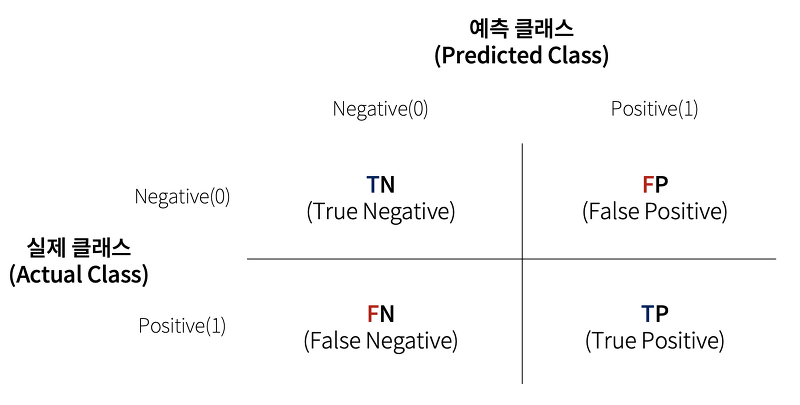
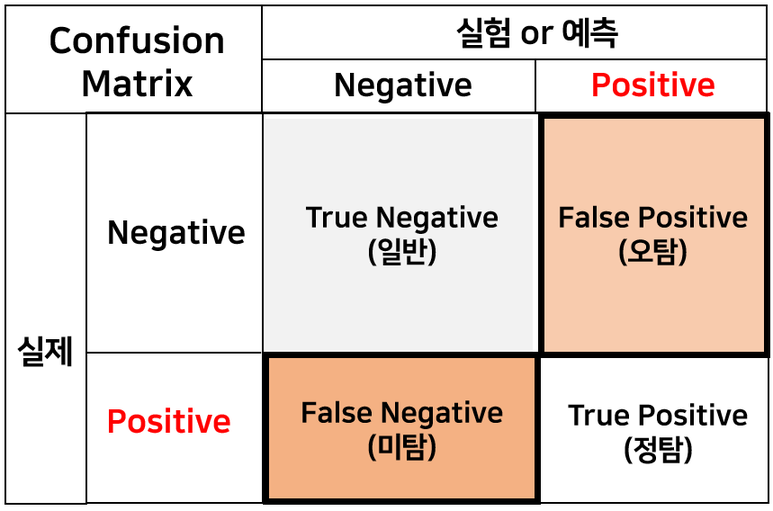
혼동행렬(Confusion Matrix)
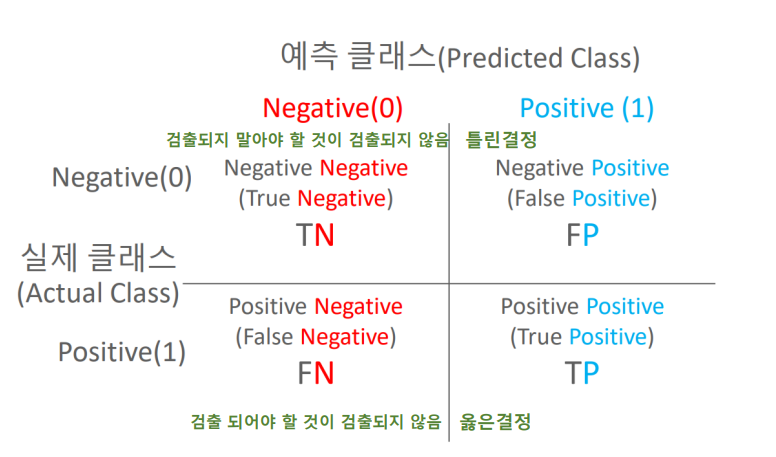
혼동행렬은 분류 모델의 성능을 평가하는 지표로 영어로는 confusion matrix라고 하며 혼돈행렬, 오차행렬, 정오행렬, 오분류표 등으로도 불린다.
Confusion Matrix 는 예측 오류가 얼마인지와 더불어 어떤 유형의 예측 오류가 발생하고 있는지를 나타내는 지표이다.
Confusion Matrix 를 이용한 평가지표
- 정밀도 Precision
- 재현율 Recall
- 특이도 Specificity
- F1-Score
정확도(Accuracy)
- 모델이 입력된 데이터에 대해 얼마나 정확하게 예측하는지를 나타낸다.
- 실제 분류 범주를 정확하게 예측한 비율
- 전체 예측에서 참 긍정(TP)와 참 부정(TN)이 차지하는 비율
정확도 단점!
예측하려고 하는 종속변수의 비율이 불균형할때 점수를 신뢰 할 수 없다.
- T : 예측성공
- F : 예측실패
- P : 맞다고 예측함
- N : 틀리다고 예측함
- TP : 맞는거를 맞다고 예측함
- TN : 틀린거를 틀리다고 예측함
- FP : 틀린거를 맞다고 예측함 (1종오류)
- FN : 맞는거를 틀리다고 예측함 (2종오류)
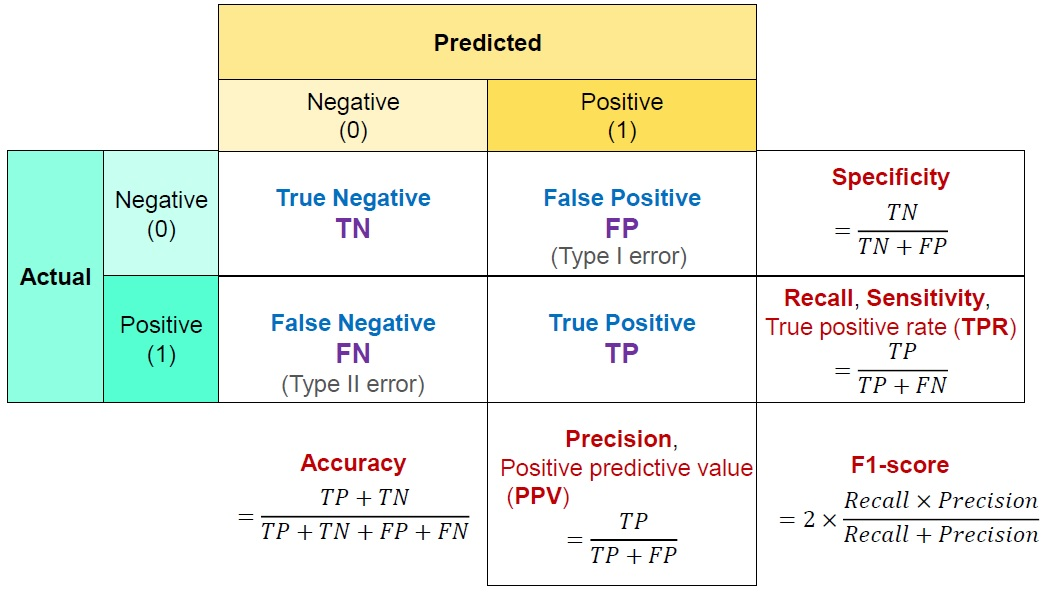
정밀도 (Precision)
- 정밀도란 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율이다.
- 모델이 1로 분류해낸 그룹 A가 있을 때, 모델이 얼마나 믿을만한 정도로 A를 만들어 냈는지 평가하는 척도
- 양성 예측 중에 맞은 비율
- 예측 중에 얼마나 맞았는지를 측정
- 예시 : 추천 알고리즘
정밀도 (Precision) 이해해기
분자: 실제 Positive를 잘 판단한 경우 분모: 예측을 Positive로 한 모든 경우 잘못된 Positive를 줄이는 데에 초점 ex) 스팸메일 분류 스팸을 스팸메일로 분류하지 않는 것(FN)은 큰 문제가 없다. 스팸메일이 아닌 것을 스팸메일로 분류하면(FP) 업무 차질 발생한다. 이와 같이 FN보단 FP를 줄이는 것이 중요한 경우 정밀도를 사용한다.
재현율 (Recall)
- 재현율이란 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율이다.
- 실제 양성값 중에서 모델이 예측한 양성 비율을 나타내는 지표
- 보통 모형의 실용성과 관련된 척도이다.
- 예시 : 코로나 자가키트
재현율 (Recall) 이해하기
분자: 실제 Positive를 잘 판단한 경우 분모: 실제 값이 Positive인 모든 경우 잘못된 Negative를 줄이는데 초점 ex) 실제 암환자들이 병원에 갔을때 암환자라고 예측될 확률 ex) 악성코드 판별 악성코드가 아닌데 악성코드로 분류하면(FP) 사용자가 확인하고 예외처리 하면 된다. 악성코드인데 악성코드가 아닌 것으로 분류하면(FN) 악성코드에 감염되어 위험 노출된다. 이와 같이 FP보단 FN를 줄이는 것이 중요한 경우 재현율 사용된다.
Precision과 Recall
Precision과 Recall 은 1종오류, 2종오류와 관련이 있다.
1종 오류
귀무가설이 실제로 참이지만, 귀무가설을 기각하는 오류
= 대립가설이 거짓인데, 맞다고 하는 오류
= FP (틀렸는데 맞다고 예측함)2종 오류
귀무가설이 실제로 거짓이지만, 귀무가설을 기각하지 못하는 오류
= 대립가설이 참인데, 틀렸다고 하는 오류
= FN (맞는거를 틀렸다고 예측함)
1종 오류(FP)와 2종 오류(FN)는 trade off 관계에 있기 때문에, Precision과 Recall 도 trade off 관계에 있다.

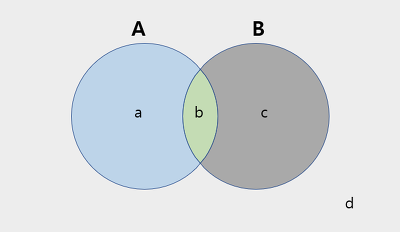
A는 실제 날씨가 맑은 날이고 B는 모델에서 날씨가 맑은 날이라고 예측한 것이다.
b의 영역은 TP로 실제 맑은 날씨를 모델이 맑다고 제대로 예측한 영역이다. 이때 수식은 아래와 같다.
Precision과 Recall 예시
특이도 (Specificity)
- 특이도란 현실이 실제로 부정일 때 예측 결과도 부정적일 확률이다.
- 민감도와 대칭을 이루는 지표이다.
- 특이도가 높다는 것은 현실이 부정일 때 그 예측도 제대로 잘 이루어지고 있다는 의미이다.
- 많이 쓰이지 않는다.
- 많이 쓰이지 않는다.
F1-Score
실습
- pima 인디언 데이터로 실습해보자.
# 사전 준비
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
df = pd.read_csv("http://bit.ly/data-diabetes-csv")
# 데이서셋 준비
feature_cols = ['Pregnancies', 'Insulin', 'BMI', 'Age','Glucose','BloodPressure','DiabetesPedigreeFunction']
y = df["Outcome"]
X = df[feature_cols]
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size = 0.3,
random_state = 1
)
# 머신러닝 모델 예측
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=42)
y_pred = model.fit(X_train, y_train).predict(X_test)
y_pred[:5]sklearn으로 Confusion matrix
from sklearn.metrics import confusion_matrix
confusion_matrix?
'''
분류의 정확성을 평가하기 위해 혼동 행렬이다.
confusion_matrix(
y_true,
y_pred,
*,
labels=None,
sample_weight=None,
normalize=None,
)
the count of
TN : true negatives is :math:`C_{0,0}`,
FP : false positives is :math:`C_{0,1}`,
FN : false negatives is :math:`C_{1,0}`,
TP : true positives is:math:`C_{1,1}`
'''
confusion_matrix(y_test, y_pred)
# 결과값
>>> array([[128, 18],
[ 34, 51]], dtype=int64)
참고
it wiki 혼동 행렬
오차행렬은 왜 필요할까?
분류성능평가지표 - Precision(정밀도), Recall(재현율)
1종 오류와 2종 오류 & 오차행렬

열심히 사는 중