배경
요즘의 개인적인 소프트웨어 엔지니어링의 화두는 서버리스와 함수형 프로그래밍인 듯 하다. 그러나 이런 기술이 나오게 된 배경은 대부분의 IT 서비스가 빅데이터 환경에서 제공되기 때문이라고 생각한다. 즉, 대량의 데이터를 주어진 시간 안에 처리해야 한다. 그러기 위해선 첫 번째로 반드시 병렬 처리를 사용해야 한다. 그리고 확장 가능한 시스템을 사용해야 한다. 대량의 데이터를 처리할 수 있어야 할 필요성은 있지만 그것이 어느 시기에 얼마만큼 지속될 지는 알 수 있기 때문이다. 그리고 이런 시스템은 클라우드 환경에서 제공하기 적합하다. 그러나 사용이 어렵기 때문에 높은 추상화를 제공하는 서버리스의 선호도가 올라가고 있는 것이다. 그리고 카프카 또한 이런 시대적 배경 속에서 태어났으며, 비동기적으로 이벤스 드라이븐 아키텍처를 사용하여 Pub/Sub 구조의 메시지 브로커 역할을 수행할 수 있다.
아키텍처
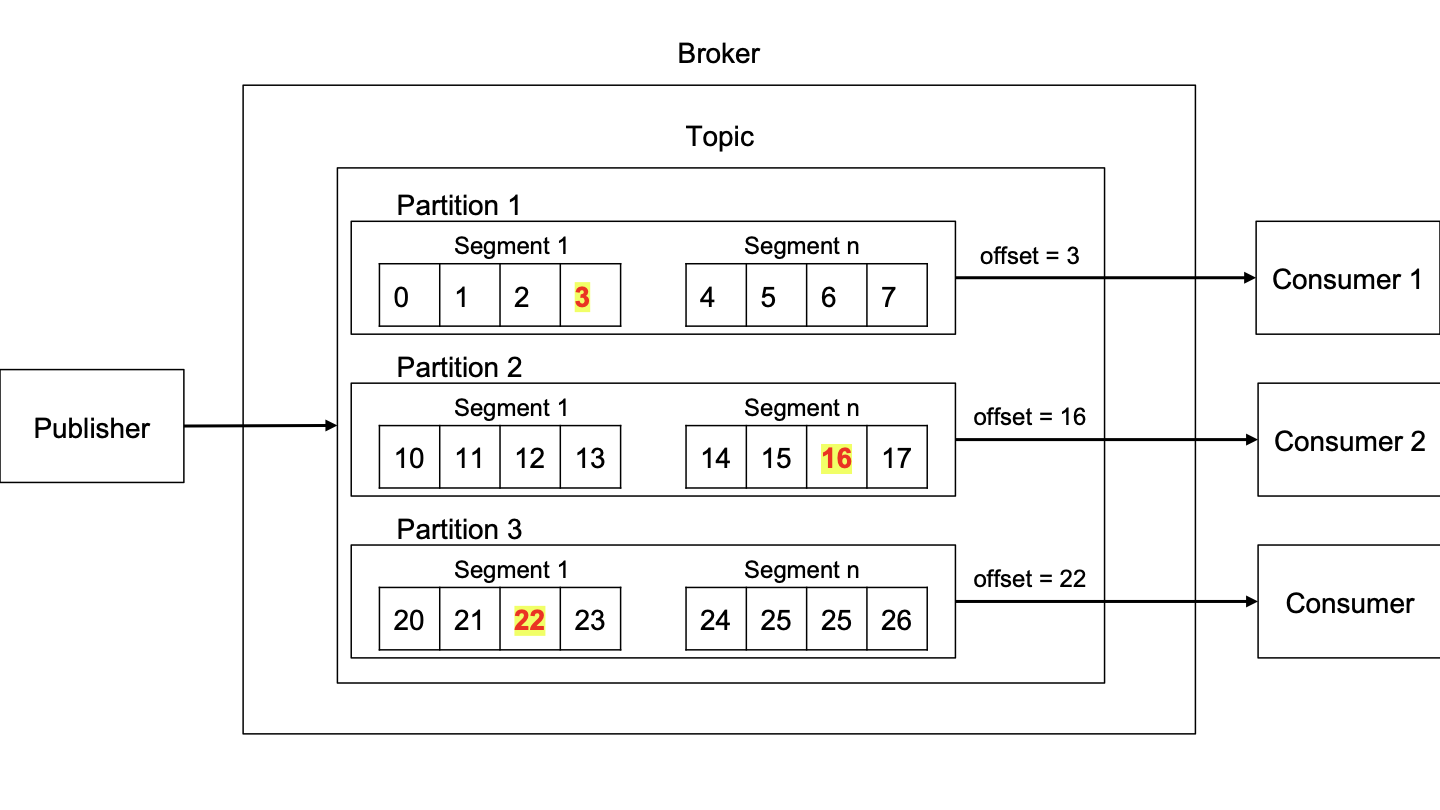
참고로 카프카는 TCP 통신을 한다.
용어
- publisher : 카프카 브로커로 메세지를 보내는 컴퓨터
- broker : publisher와 cunsumer 사이를 중개하는 컴퓨터
- topic : message의 종류를 구분하는 메타 데이터 (추상적인 정보일 뿐 구현체가 아님)
- partition : message를 분할해서 저장하는 장소 (디렉토리로 구현되어 있음)
- segment : 실제로 저장되는 로그 파일 (.log 확장자를 사용)
- offset : segment를 어디까지 읽었는지 확인하는 포인터 (.index)
- cunsumer : 메세지를 가져오는 컴퓨터
설명
- 카프카는 단순하게 메세지 브로커라고 생각하면 편하다. 그러나 대용량 트래픽을 감당하는 용도로 쓰이기 때문에 RabbitMQ와 같은 메세지 브로커와는 용도에서 차이가 난다. 즉, 데이터의 크기가 커질 때 신뢰도 측면에서 차이가 발생한다. 또한 트래픽이 커질 것을 염두하여 카프카는 확장성이 고려된 설계를 가지고 있다. 아마도 이는 각각의 인스턴스가 상태를 갖고 있지 않거나 갖고 있더라도 매우 쉽게 복제가 가능한 설계일 것이라 추측해본다.
- 퍼블리셔는 동기 및 비동기 방식으로 메세지를 송신할 수 있다. 즉, 메세지가 보내진 것을 확실하게 확인하거나 안 할 수 있다.
- 컨슈머도 동기 및 비동기 방식으로 메세지를 수신할 수 있다. 이때 읽어오는 방식에 따라서 오프셋이 설정되는 방식이 약간 달라진다.
- 오프셋은 세그먼트를 어디까지 읽었는지 표시하는 정보이다. 인덱스 파일에 해당 정보가 저장되어 있다. 오프셋이 있기 때문에 읽기 순서를 보장할 수 있다.
- 파티션은 데이터를 분할 저장하기 위한 용도로 만들어진 것이다. 구체적으로는 디렉토리로 구현되어 있으며, 토픽으로 들어오는 데이터들은 파틱션 별로 분할하여 저장된다. 또한 파티션마다 컨슈머를 만들어 둔다고 한다. 아마도 검색의 속도를 높이고 처리 속도를 빠르게 하기 위함이 아닐까 추측해본다.
- 세그먼트는 파티션 디렉토리에 내부에 있는 로그 파일이다. 로그 파일뿐만 아니라 오프셋 데이터를 포함하여 기타 메타 데이터들도 해당 디렉토리에 같이 저장되어 있다.
- 토픽은 추상적인 정보로서 들어오는 데이터들의 종류를 구분한다. 사실 나는 토픽에 대해서 이해하는 것이 오래 걸렸다. 그래서 내가 이해한 방식을 간략하게 소개해본다. 토픽은 인터넷 게시판이라고 생각하면 된다. 그러면 publisher라는 다양한 사용자들이 글을 남긴다. 그 뒤에 consumer라는 다양한 곳의 사용자들이 게시판에 접속하여 글을 읽는다. 이런 n대n 관계를 이어주는 매개체가 토픽이라고 이해하면 된다. 그리고 이것에 대한 정보는 카프카 브로커 내부에 메타 데이터로서 저장되리라 추측하고 있다.
대략적으로 알아봤는데 앞으로는 카프카, 스파크, HDFS에 대해서 각각 알아보고, 데이터 파이프라인이 어떻게 구성되는 지 알아볼 생각이다.
지금까지 간략하게 알아본 결과로는 카프카는 데이터를 이동시키는 터널 같은 것이며, 스파크와 HDFS는 데이터를 저장 및 처리하는 컴퓨터라고 볼 수 있다. 그런데 병렬처리에 특화되어 있는 컴퓨터라는 게 특이점이다.
공부를 할수록 low level과 high level 모두 공부해야 한다는 생각이 든다. 언젠간 내 생각의 지도를 전부 맞춰보는 날이 오길!

lim (time → ∞) Life(time) = LOVE