알고리즘
1.[알고리즘] 교점에 별 만들기

시간 복잡도나 공간 복잡도는 신경 쓰지 않았다.구현에 더 집중한 문제이다.수학 공식을 이용하여 모든 교점을 구한다.리스트 컴프리헨션(조건부 집합)을 이용하여 모든 좌표가 정수인 교점만 남기고, 타입도 변경해준다.출력할 별들의 x 범위를 계산한다.출력할 별들의 y 범위를
2.[알고리즘] 행렬 테두리 회전하기
알고리즘이 있다기 보단 구현에 가깝다.동작 방식은 주석에 넣었다
3.[알고리즘] 삼각 달팽이
내가 놓친 점은 방향 전환을 위한 좌표 조정 부분이다.대략적인 큰 알고리즘 설계는 어렵지 않다고 생각한다.그러나 엣지 케이스에서 발생하는 처리들이 어렵다고 생각한다.그렇기 때문에 알고리즘을 구성하는 절차 중에서 다음 절차로 넘어갈 때 엣지 케이스와 같은 것들이 발생하는
4.[알고리즘] 거리두기 확인하기
한 좌표에서 어느 곳에서도 다른 P를 못 찾은 경우에느 다음 좌표로 넘어가야 했는데, 이 부분에서 break를 해버렸다. 이를 continue로 바꿔주고 테스트 케이스를 모두 해결할 수 있었다.1\. 큰 흐름에서 알고리즘의 과정을 다시 생각해본다.2\. 큰 흐름을 미시
5.[알고리즘] 행렬 연산
행렬 연산은 아래의 코드로 간단하게 구현할 수 있다.그런데 그것을 알지 못하고, 어렵게 구현해버렸다.
6.[알고리즘] 진법 변환기
추상화된 레벨에서 함수가 제공되는 경우가 많다.그러나 함수에서 사용되는 알고리즘에 대해선 알고 있어야 한다는 생각이 최근에 들었다. 결국 알고리즘 레벨까지 내려갔을 때도 어떤 일이 일어나는지 알고 있어야 한다는 소리이다.이는 수학에서 증명을 외우고 있어야 하는 경우와
7.[알고리즘] 두 수의 연산값 비교하기
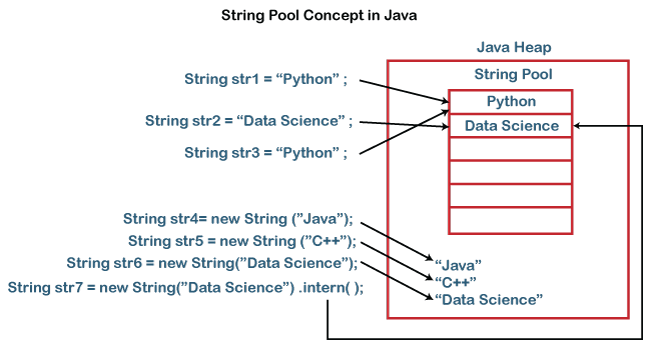
이 문제에서 필요했던 내용만 정리한다Java에서 String은 위와 같이 두 개의 메모리 영역에 할당된다. 하나는 Java Heap 메모리 영역이고, 하나는 String Constanct Pool이란 영역이다.큰 따옴표로 이용하여 선언한 String 같은 경우에는 St
8.[알고리즘] 시저 암호
결국은 f:N->N,x->y인 함수를 주어진 설명에 맞게 만드는 행위이다.이때 나머지 정리를 잘 활용해야 하는데, 머리로만 생각한게 바로 들어맞지 않는다. 따라서 직접 하나씩 연산마다 어떻게 맵핑을 시켜 가야 하는지 적는 편이 낫다.그리고 작은 스케일에서 함수를 짜본
9.[알고리즘] 이상한 문자 만들기
공간 복잡도가 높은 풀이였다.공간 복잡도를 낮추기 위해서 원래 문자열에 바로 접근하여 최적화를 진행할 수 있다.새로운 변수를 선언하는 기준은 원본 데이터가 아닌 아예 새로운 데이터를 저장해야 할 때이다.즉, 어떤 정보를 기억해야 하는 지에 따라서 새로운 변수를 선언할
10.[알고리즘] 튜플
잘 짜려고 하지 말고 일단 논리를 작성해보는게 중요함을 느꼈다.일단 짜보면 매우 쉽다고 느껴지기 때문이다.그러나 동시에 파이썬이 아닌 자바로 풀기 위해선 문자열 클래스가 제공하는 메소드를 잘 알고 있어야 함을 느꼈다.서로 다른 스코프에서 같이 사용하는 코드는 함수로 따
11.[알고리즘] 실패율
프로그래머스 실패율테스트 케이스 22번에서 문제가 발생했다.stages의 길이가 200000, 그리고 그 원소의 대부분이 500인 경우에 시간 초과가 발생했다.그리고 시간 초과가 나는 부분의 코드는 위의 주석으로 표시해놨다.반복문이 중첩되는 경우, 내부 반복문의 로직을
12.[알고리즘] 체육복
if-elif 문을 사용할 때 조건문을 꼼꼼하게 작성해야 한다. 그렇지 않으면 의도치 않게 작동하여 실패한다.
13.[알고리즘] 소수 찾기
시간 복잡도가 O(n \* root(n) )이다. 근데 n이 1000000이다 보니 이것보다 더 적은 시간 복잡도를 가져야만 한다.if의 조건문에 조건을 빨리 끝낼 수 있도록 and 연산자의 전항을 추가했다.그럼에도 불구하고 시간 초과와 공간 복잡도를 만족시키지 못했다
14.[알고리즘] 같은 숫자는 싫어
스택/큐 종류의 문제란 것을 모르고 풀었는데, 지금 보니 맞다.그 이유는 기억해야 할 데이터가 스택의 가장 앞에 있는 top이었기 때문이다.중복 제거는 스택을 사용할 수 있다는 것을 기억하자!
15.[알고리즘] 구명보트
문제링크투포인터를 이용해서 풀었다.투포인터를 생각해내게 된 루트는 이렇다.먼저 보트를 최소한을 이용하기 위해선 보트를 꽉 채워야 한다.덧붙여 주어진 문제가 그리디스럽기 때문에 정렬한 뒤에 접근해야 하지 않을까 생각했다.그리하여 정렬된 상태에서 보트를 꽉 채울 수 있는
16.[알고리즘] 점프와 순간 이동
문제링크1에서 n까지 bfs를 이용해서 모든 경우를 탐색하려고 했다.이때 한번에 이동 가능한 거리를 1로 제한했는데, 이는 최소한으로만 배터리를 써서 도달하는 경우를 찾기 위함이었다. 그러나 이로 인해서 불필요한 노드가 많이 발생해서 주어진 시간 안에 문제를 풀 수 없
17.[알고리즘] 멀리 뛰기
문제 링크시간 초과가 발생했다.즉, 쓸데 없는 노드가 불필요하게 많이 발생했다는 뜻이다.시간 초과가 났다. 팩토리얼을 이용했다는 것부터 사실 깨름칙한 접근이긴 했다.사실 여기서 보다 더 dp스럽게 접근한다는 걸 깨달아야 했다.시간 초과가 주요하게 발생할 때는 DP를 고
18.[알고리즘] 기능개발
문제 링크스택을 이용해서, 만약에 스택의 탑에 있는 원소가 100을 넘으면 완료가 된 것이므로 팝시킨다. 이때, 스택을 사용한 이유는 앞에 일을 끝마쳐야만 다음 기능을 배포할 수 있다는 순서가 있기 때문이었다. 즉, LIFO 순서로 자료가 처리되어야 했기 때문이다.FI
19.[알고리즘] [3차] 압축
문제 링크(https://school.programmers.co.kr/learn/courses/30/lessons/17684처음에는 투포인터로 풀려고 했다.그 접근은 투포인터로 문자를 순회할 때 종결 조건을 생각해내기 어려웠다.즉, 사용하려는 자료구조가 잘못된
20.[알고리즘] 땅따먹기
문제 링크(https://school.programmers.co.kr/learn/courses/30/lessons/12913그리디 막히면 무조건 모든 경우를 다룰 수 있는 방법을 생각해야 됨 그리디는 크게 큰 거 순으로 정렬, 작은 순으로 정렬이 있으니 두
21.[알고리즘] 완주하지 못한 선수
완주하지 못한 선수효율성 테스트에서 실패와 성공이 갈렸다. 시간 복잡도에서 문제가 있었던 듯 하다.두 코드 모두 파이썬의 리스트와 딕셔너리를 사용하고 있습니다. 이들의 공간 복잡도는 입력 크기에 비례합니다. 즉, O(n)의 공간 복잡도를 가집니다. 여기서 n은 part
22.[알고리즘] 가장 큰 수
가장 큰 수정렬 기준으로는 아스키 코드 기준도 있다.아래의 참고문헌을 봐라.x\*3을 하게 되면 3, 310, 30이 333, 310310310, 303030 이렇게 된다. 자릿수를 맞춰 비교하기 위함이다. 그렇다면 자릿수는 왜 3개였을까?문자열을 3번 쓰는 이유는 문
23.[알고리즘] [1차] 프렌즈4블록
문제 링크함수 이름 변경: findBox에서 find_blocks로 변경하여 함수의 기능을 더 명확하게 표현하였습니다.중복 함수 호출 제거: find_blocks 함수를 한 번만 호출하여 중복 연산을 제거하였습니다.튜플 사용: 좌표를 문자열 대신 튜플로 저장하여 코드의
24.[알고리즘] 2 x n 타일링
문제 링크처음에 bfs로 문제를 풀었더니 시간 초과가 났다.너무나 간단한 논리의 문제였기에 논리의 문제가 아닌 최적화의 문제임을 깨달았다.그래서 최적화 기법 중에 하나인 DP를 적용하기 위해 점화식 관계가 있는지 살펴보았다.그러니 f(n) = f(n-1) + f(n-2
25.[알고리즘] 숫자변환
문제 링크recursion depth limit에 걸려서 런타임 에러가 발생했다.그리고 시간 초과가 발생한다.사실 로직이 맞는데도 시간 초과가 발생했다면 무조건 dp를 써야 하지만 위의 코드는 제대로 dp를 쓸 수 없는 문제였다. 왜냐면 dp를 쓸려면 적어도 분할 정복
26.[알고리즘] 택배상자
문제 링크이 문제는 각각의 행위에 대한 조건을 찾는게 포인트였다. 내가 찾기 어려웠던 조건은 서브 컨테이너 밸트에 실는 조건이었다. 그래서 아래와 같이 작은 스케일에서 법칙을 찾아보고자 했다.여기서 보면 5에서 종결이 되었다. 그런데 사실 5에서 끝내지 않고 서브 컨테
27.[알고리즘] 124 나라의 숫자
문제 링크(https://school.programmers.co.kr/learn/courses/30/lessons/12899\`\`\`pythondef solution(n): answer = \[] while n >= 3: if n %
28.[알고리즘] 문제 접근법, 사고의 흐름
알고리즘이 보인다. -> 바로 적용알고리즘이 보이지 않는다.구현 문제인지 의심한다.자료의 크기가 작다면 구현해도 상관 없다.그리디 문제인지 의심한다.작은 스케일에서 문제를 관찰해본다. (귀납추론 -> 연역추론)순열적인 접근 : 순서에 따른 규칙이 존재하는지 본다.정수론
29.[알고리즘] 두 큐 합 같게 만들기
문제링크문제 해결 논리이것은 맞게 풀었다. 그러나 시간 초과가 발생했다. 근데 한 가지 빠트린 것은 반복문 탈출 조건이었다. 완전 변형을 하고 다시 원래의 모습을 되찾기까지 걸리는 연산 횟수를 탈출 조건으로 주어야 했다. 이것은 암기해두자.시간 초과 발생알고리즘은 대충
30.[알고리즘] 메뉴 리뉴얼
문제 링크사실 내가 풀어내지 못했다.그 이유는 문제를 제대로 해석하지 못했다.가능한 모든 경우를 다뤄야 했는데 나는 놓치는 경우가 있었다.따라서 가능한 모든 경우를 위와 같이 구하는 것이라고 암기해야겠다.카카오 구현 문제는 조건이 많을 뿐, 제대로 해석해서 접근하면 풀
31.[알고리즘] 괄호 변환
문제 링크해당 문제는 얼핏 보면 어려워 보인다.그러나 구현 문제, 특히 카카오 구현 문제는 문제 자체의 조건이 어렵지 코딩이 어려운 유형은 아니다. 그렇기 때문에 문제를 처음 본 순간부터 차분하게 문제에서 하란 대로 하는게 제일 중요하다.난 뇌를 빼고 문제에서 적힌대로
32.[알고리즘] DP, 재귀함수 그리고 캐시
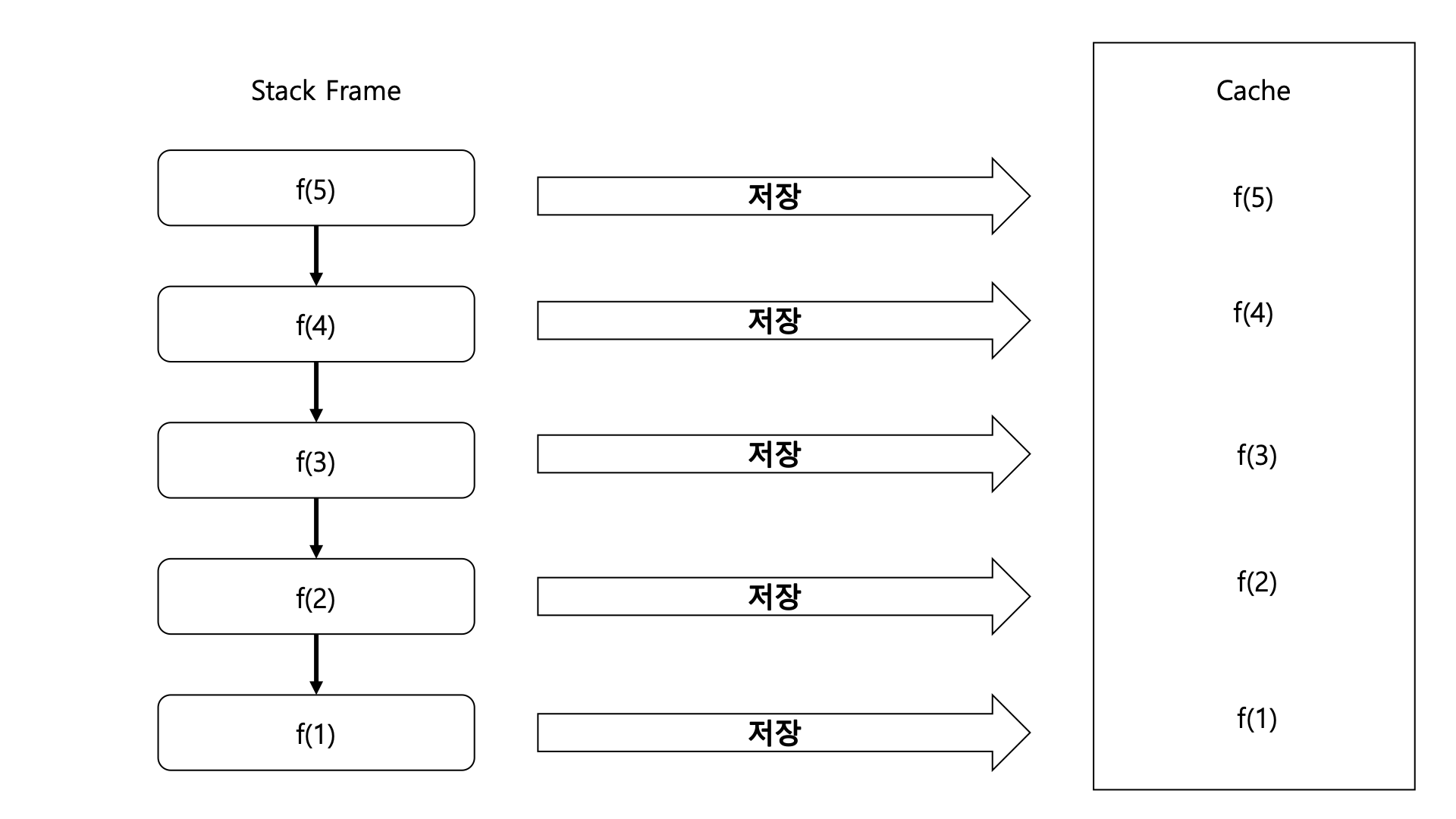
분할 정복이 가능한 문제에서 사용 가능하다.분할 정복이란 하나의 문제를 같은 유형의 문제로 쪼개는 것을 말한다.여기서 중요한 것은 같은 유형이란 것!시간 복잡도를 낮출 수 있다. 만약 알고리즘은 논리적으로 맞지만, 시간 초과가 발생하는 경우 도입해볼 수 있다.구체적인
33.[알고리즘] [카카오 인턴] 수식 최대화
문제 링크전형적인 카카오 구현 문제 스타일이다.카카오 구현 문제는 첫 번째로 문제 해석이 중요하다. 왜냐하면 문제 자체의 조건이 복잡하다. 그래서 이것을 꼼꼼히 찢어서 구현하기 쉬운 상태로 만들어야 한다. 그리고 분석을 바탕으로 차분하게 구현하면 끝이다.1\. 주어진
34.[알고리즘] 전력망을 둘로 나누기
문제 링크전형적인 카카오 구현 문제 유형이다. (문제 분석이 중요한 유형)1\. 그래프의 노드 개수를 세는 함수를 구현한다. 1\. BFS 또는 DFS를 통해 완전 탐색 로직을 구현한다. 2\. 인접 리스트, 방문한 노드를 기록하는 리스트를 구현한다. 3\.
35.[알고리즘] 줄 서는 방법
문제 링크위의 코드는 논리적으로 반드시 맞는 코드이다. 그러나 시간 초과가 발생했다. 이는 즉, 최적화가 필요하다는 뜻이다. 그러나 시간 초과가 발생한 경우에는 다양한 접근 방법이 있는데, 나는 일단 수학적인 공식을 통해 함축적으로 논리를 압축하는 방향으로 접근해야겠다
36.[알고리즘] 정수 삼각형
문제 문제 링크 코드 DP (Cache) 접근법 전형적인 캐시를 이용한 문제 풀이 방법이었다. 시도했던 최적화 기법 해시 함수 캐시에 키값을 저장할 때 먼저 해싱을 한 뒤에 키로 사용하였다. 원래는 서브 삼각형을 평준화 한 뒤에 이것을 튜플로 만들어서 키로 사용했
37.[알고리즘] 수를 대하는 자세
수란 무엇인가? 수란 계산 가능한 모든 것을 말한다. 이때 어떤 계산이 가능한 지에 대해서 수의 종류가 달라진다. 그리고 컴퓨터 세계에서는 보통 정수와 실수가 다뤄진다. 내가 이 글에서 말하고 싶은 것은 특히 정수에 대한 것이다. 왜냐하면 정수를 어떻게 다루느냐에 따라
38.[알고리즘] 입출력 문제 - try catch 로 예외처리
링크입력이 예측할 수 없는 지점에 멈춘다.그래서 이런 경우를 어떻게 처리할 지 고민을 했는데 try catch로 처리할 수 있었다.
39.[알고리즘] 호텔 대실
링크문제는 곧이곧대로 풀거나, 수학적인 공식을 통해서 단번에 풀어낼 수 있다.여기선 호텔을 정말 빌리는 행위를 실제 세계와 대응해서 구현하거나flag나, 각 시간대마다 겹치는 시간대의 개수를 세거나 위와 같이 구현할 수 있다. 그러나 실제로 선택한 것은 호텔에서 시간대
40.[알고리즘] 숫자 카드 나누기
링크말 그대로 문제를 구현한 것이다.그러나 시간 초과가 발생했다. 메모리제이션을 이용해서 실행 시간을 줄여보려고 했으나 실패했다.시간을 좀 더 줄여보고자 분할 정복 방식을 적용했다.메모리제이션과 함께 사용하면 좀 더 시간을 줄여볼 수 있지 않을까 생각했다.그러나 실패했
41.[알고리즘] 연속된 부분 수열의 합
링크(https://school.programmers.co.kr/learn/courses/30/lessons/178870포인터만을 사용하도록 변경투포인터의 핵심은 상수 포인터 두 개를 사용하는 것이다.그리고 k 값보다 크면 조금 줄여본다. 즉, 그래서 s를 1
42.[알고리즘] Regular Expression Matching
링크먼저 나의 코드가 형편 없음을 고백한다.그럼에도 불구하고 이 글을 작성하는 이유는 형편 없는 코드를 짜는 과정 속에서 깨달음 바가 있기 때문이다.나는 처음에 모든 경우의 수를 처리할 수 있다면, 해당 문제를 풀 수 있다고 판단했다. 그래서 나는 크게 세 가지의 경우
43.[알고리즘] 시소짝꿍
link이 문제의 경우, 경우의 수를 줄이는 방법이 중요했다.이때, 자주 사용할 수 있는 패턴은 바로 Counter와 같은 것들을 사용해서 키-값 딕셔너리를 만드는 것이다. 이와 같이 코드를 짜면, 중복된 원소들을 O(k)와 같이 상수 시간 복잡도로 처리 가능하다.아래
44.[알고리즘] 가장 많이 받은 선물
link이런 어려운 구현 문제의 특징은 조건이 많다는 점이다. 즉, 세부적으로 고려해야할 조건들이 복합적으로 엮여져 있는데, 이것을 단번에 고려하려는 순간 문제 푸는 것이 어려워진다.따라서 다음과 같은 규칙을 따르는 것이 좋다.조건 하나마다 함수를 만든다. 객체 지향적
45.[알고리즘] 2개 이하로 다른 비트
link이 코드는 시간 초과가 발생하였다.그래서 내가 정리한 최적화 방법 중 하나인 수학적인 공식을 이용하여 시간 복잡도를 줄여야 한다. 사실 그래서 케이스별로 수열적인 관점에서 패턴을 찾아내려고 했지만 실패하였다. 계속 시간을 투자했던 이유는 안타깝게도 패턴이 보일
46.[알고리즘] 평범한 배낭
link미리 말하자면, 배낭문제란 알고리즘 유형이 따로 있는데, 나는 그 유형 중에서 해당 문제를 분할 가능한 배낭 문제로 이해하고 접근하였다가, 틀렸다. 이 문제는 0-1 배낭 문제로 접근해야 한다.이렇게 접근한 이유는 이전에 풀었던 배낭 문제가 위와 같은 방법으로
47.[알고리즘] 집합
link처음에는 시간 초과가 나서, 도저히 이해할 수가 없었다.알고리즘 자체에는 문제가 없었기 때문이다. 그래서 GPT에게 도움을 요청한 결과 input 함수에서 시간이 느려질 수 있다는 것을 알았다. 그래서 다음과 같은 두 줄을 추가하고 나서 채점이 통과 됐다.pyt