이론
DP
DP의 조건
분할 정복이 가능한 문제에서 사용 가능하다.
분할 정복이란 하나의 문제를 같은 유형의 문제로 쪼개는 것을 말한다.
여기서 중요한 것은 같은 유형이란 것!
DP의 효과
시간 복잡도를 낮출 수 있다.
만약 알고리즘은 논리적으로 맞지만, 시간 초과가 발생하는 경우 도입해볼 수 있다.
구체적인 효과는 아래와 같다.
- cache를 이용해서 recursion depth를 얕게 만들 수 있다.(시간 복잡도 & 공간 복잡도 개선)
- cache를 이용해서 실행 속도를 빠르게 할 수 있다. (시간 복잡도 개선)
실제 구현
재귀함수와 캐시
실제 구현은 재귀함수와 캐시를 이용해서 구현한다.
단순히 캐시만을 이용해서 구현할 수도 있고, 재귀함수와 같이 사용해서 구현할 수 있다. 만약 캐시만 단독으로 사용된다면 실행 속도만이 개선되고, 재귀함수와 같이 사용된다면 recursion depth를 얕게 만들어서 마찬가지로 실행 속도를 개선할 수 있다.
Code!
Factorial 함수 (시간 복잡도 개선)
import time
cache = dict()
def factorial(n):
if n in cache:
return cache[n]
elif n <= 1:
cache[n] = 1
return 1
else:
result = n * factorial(n - 1)
cache[n] = result
return result
def main():
test_values = [10, 50, 100, 500, 1000, 2000] # decrease this number if you get recursion error
for n in test_values:
cache.clear() # Clear cache
start_no_cache = time.time()
result_no_cache = factorial(n)
end_no_cache = time.time()
print(f"Without cache, factorial({n}) took {end_no_cache - start_no_cache:.5f} sec")
start_with_cache = time.time()
result_with_cache = factorial(n)
end_with_cache = time.time()
print(f"With cache, factorial({n}) repeated took {end_with_cache - start_with_cache:.5f} sec\n")
if __name__ == "__main__":
main()
"""[코드 실행 결과]
Without cache, factorial(10) took 0.00000 sec
With cache, factorial(10) repeated took 0.00000 sec
Without cache, factorial(50) took 0.00001 sec
With cache, factorial(50) repeated took 0.00000 sec
Without cache, factorial(100) took 0.00002 sec
With cache, factorial(100) repeated took 0.00000 sec
Without cache, factorial(500) took 0.00017 sec
With cache, factorial(500) repeated took 0.00000 sec
Without cache, factorial(1000) took 0.00056 sec
With cache, factorial(1000) repeated took 0.00000 sec
Without cache, factorial(2000) took 0.00206 sec
With cache, factorial(2000) repeated took 0.00000 sec
"""
분석
여기서는 캐시가 recursion depth를 줄여주지 못한다. factorial 함수가 필요한 값이 caching 되려면 일단 한번은 모든 스택 프레임이 실행된 뒤어야 한다. 그래야 필요한 데이터가 cache에 저장되고, 그 이후부터 cache에 hit 될 수 있기 때문이다. 그래서 단순하게 실행 속도만이 개선된다.
Fibonacci 함수 (시간 복잡도 & 공간 복잡도 개선)
import time
cache = {}
def fib_without_cache(n):
if n <= 1:
return n
else:
return fib_without_cache(n - 1) + fib_without_cache(n - 2)
def fib_with_cache(n):
if n in cache:
return cache[n]
elif n <= 1:
result = n
else:
result = fib_with_cache(n - 1) + fib_with_cache(n - 2)
cache[n] = result
return result
def main():
start_with_cache = time.time()
print(fib_with_cache(30)) # Adjust this number if it takes too long
end_with_cache = time.time()
print(f"With cache, fib(30) took {end_with_cache - start_with_cache:.5f} sec")
start_without_cache = time.time()
print(fib_without_cache(30)) # Adjust this number if it takes too long
end_without_cache = time.time()
print(f"Without cache, fib(30) took {end_without_cache - start_without_cache:.5f} sec\n")
if __name__ == "__main__":
main()
"""[코드 실행 결과]
832040
With cache, fib(30) took 0.00002 sec
832040
Without cache, fib(30) took 0.09575 sec
"""
분석
여기선 recursion depth와 실행 속도가 모두 개선된다. 즉, 공간 복잡도와 시간 복잡도가 모두 개선되는 효과가 있다.
두 코드는 왜 차이가 생길까? (이 글을 쓰는 이유)
def fibonacci(n):
if n <= 1:
return n
else:
return fib_without_cache(n - 1) + fib_without_cache(n - 2)
def factorial(n):
if n <= 1:
return 1
else:
return n * factorial(n - 1)두 코드에서 Cache가 다르게 쓰이는 이유는 위와 같이 재귀함수를 호출하는 꼴이 서로 다르기 때문이다.
피보나치는 양 옆으로 스택 프레임이 생성되면서 캐시에 데이터가 적재되고, 캐시에서 데이터를 불러올 수 있는 구조인데 반해 팩토리얼은 일단 모든 스택 프레임의 연산이 끝난 뒤에야 캐시에 적재된 데이터를 불러올 수 있는 구조이다. 이를 한번 스택프레임이 생성되는 꼴을 그림을 통해 이해해본다.
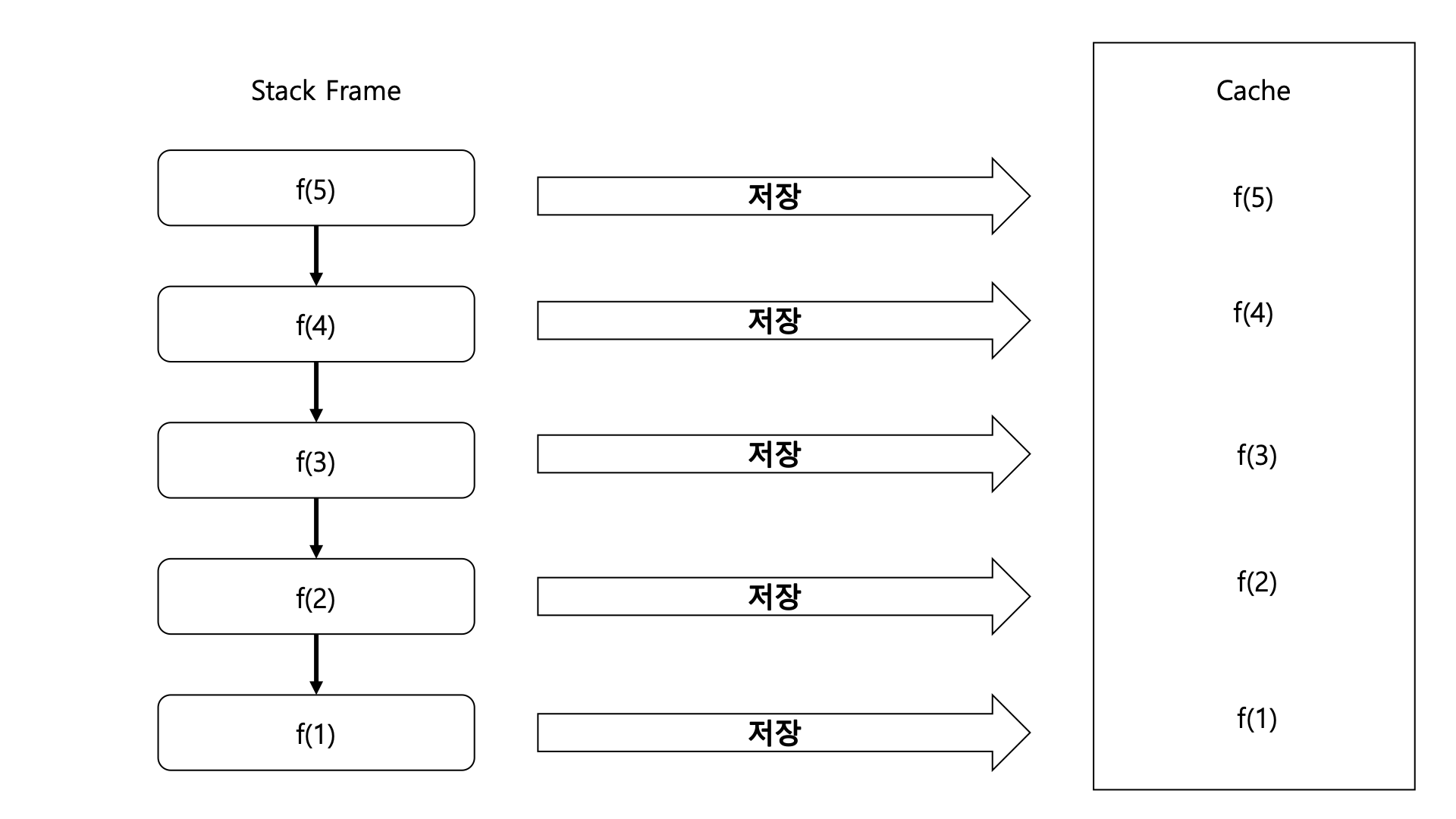
팩토리얼 함수
캐시에 데이터가 저장
캐시에 데이터가 저장된 이후에 캐시 사용
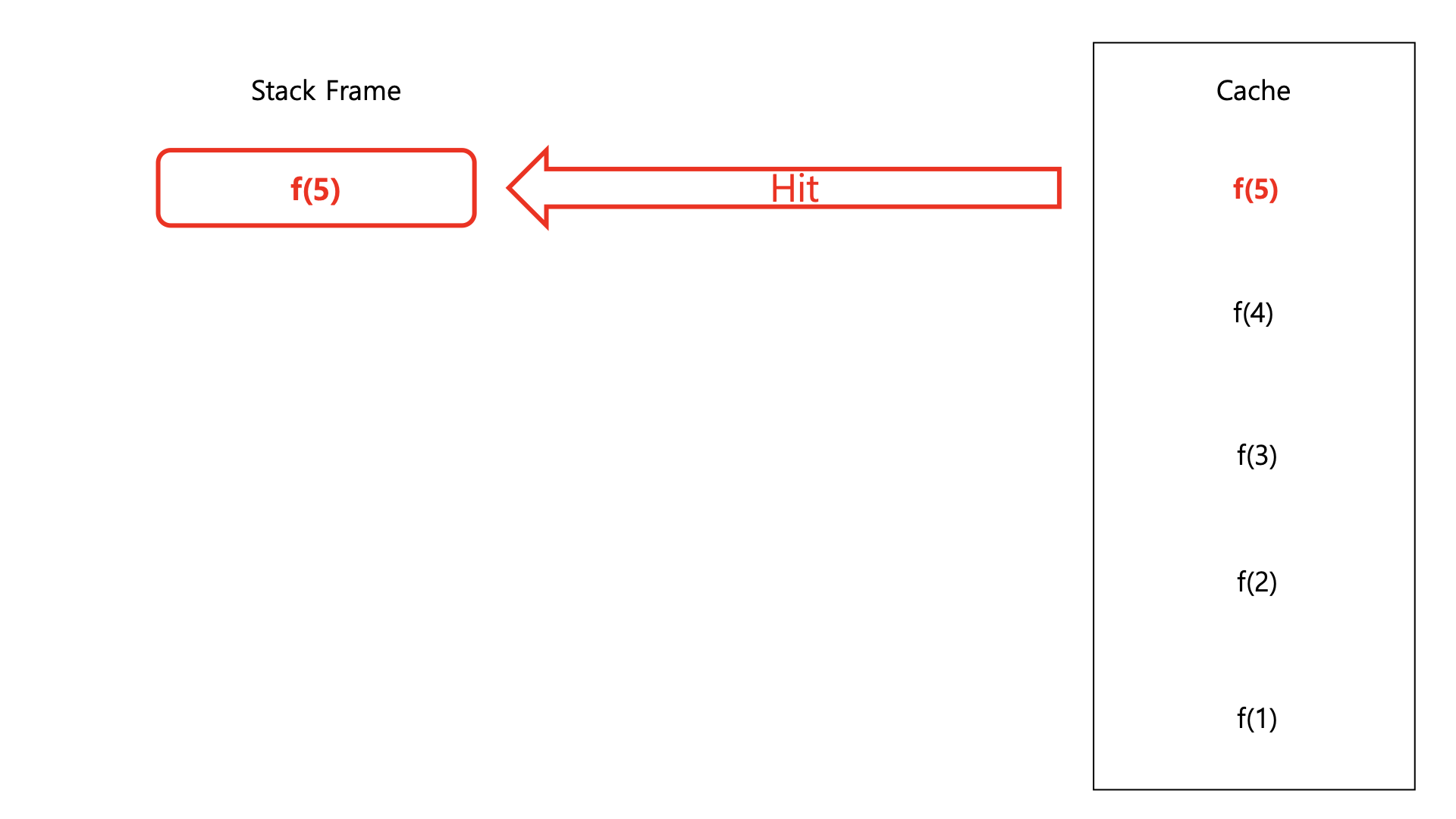
이러한 구조는 스택 프레임이 수직으로만 파고들면서 생성되기 때문에 스택 프레임 특성상 f(1)에 도달한 뒤부터 캐시에 데이터가 적재된다. 따라서 초기 연산 시에는 시간 복잡도와 공간 복잡도 모두 낮출 수 없다. 그러나 한번 캐시에 데이터가 적재되고 난 이후에는 시간 복잡도를 낮출 수 있는 효과를 가질 수 있다.
피보나치 함수
캐시에 데이터가 적재되면서 사용됨
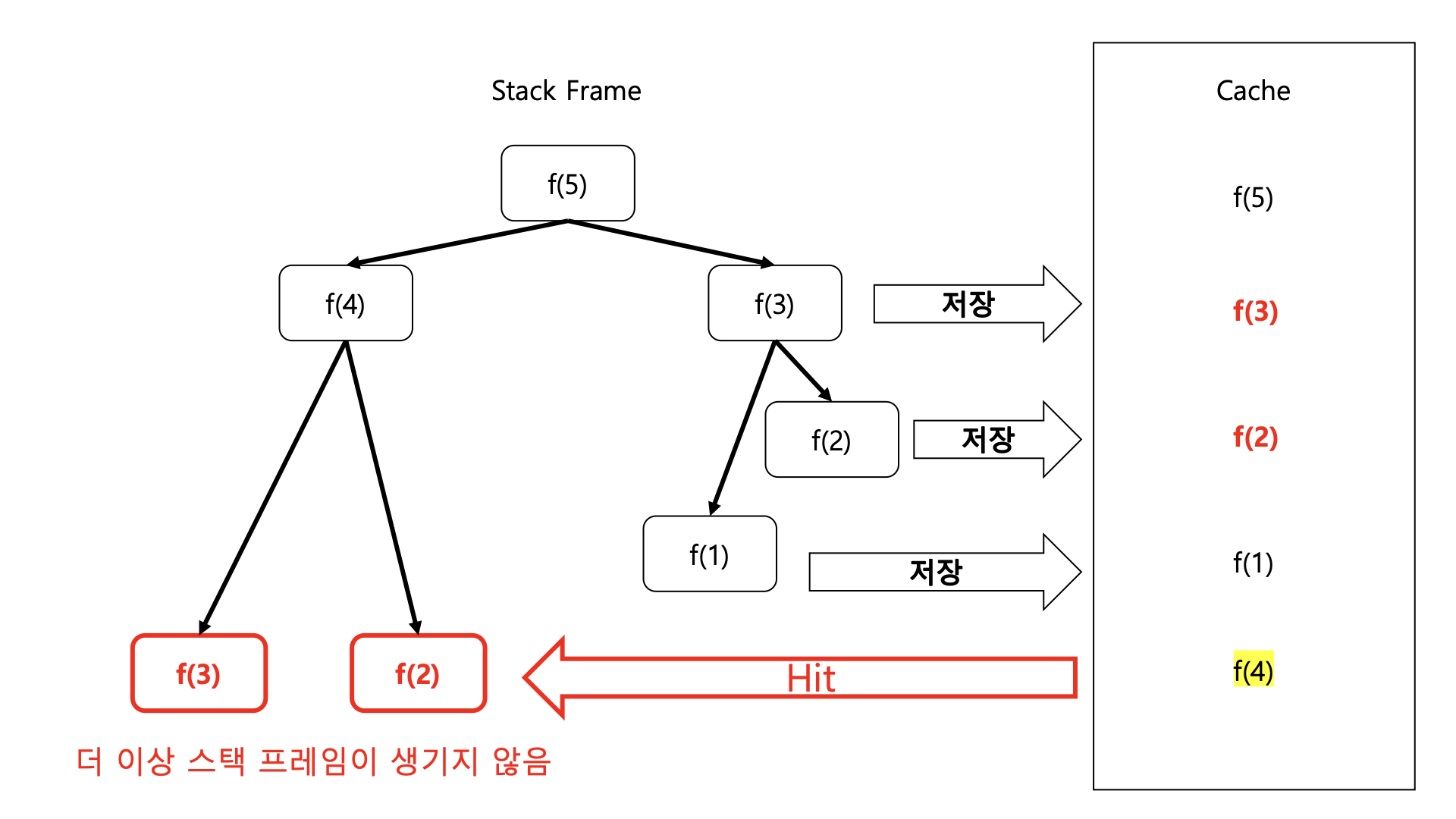
위와 같은 구조로 스택 프레임이 양옆으로 퍼지면서 생성되기 때문에 어느 한 쪽에서 스택프레임의 연산이 끝나면 해당 스택 프레임의 연산 값을 캐시에 저장할 수 있게 된다. 따라서 이후에 같은 연산이 중복되는 경우 캐시 값을 불러올 수 있다. 만약 캐시에 데이터가 hit되면 더 이상 스택 프레임이 생성되지 않기 때문에 공간 복잡도가 낮아지는 결과를 불러올 수 있다. 또한 더 이상의 연산을 하지 않기 때문에 실행 시간도 짧아지는 것이다.
결론
스택프레임이 생성되는 구조에 따라서 캐시의 역할이 시간 복잡도를 낮춰주거나 혹은 시간 복잡도와 공간 복잡도를 모두 낮출 수 있음을 위의 코드를 통해서 이해햇다.
