출처 유튜브
OJ Tube. 문자 인코딩 초간단 개념 정리 ( UTF-8, 아스키, 유니코드... )
문자열 인코딩의 역사
문자표
컴퓨터는 계산을 수행 한 후, 그 결과를 사람이 알아볼 수 있는 방법으로 표현해야 하는디,
- Ex. 0100 0001은 A라고 표현해줭~
이를 위해 숫자와 문자를 매칭하는 표를 표준화 하게 되는데, 이를 문자표 라고 부른다
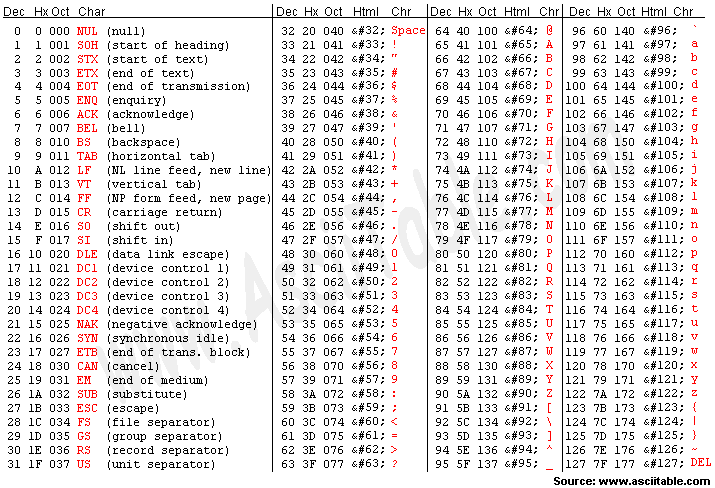
- 최초의 문자표, ASCII
- American Standard Code for Information Interchange
영어권에서 만들어진 최초의 문자표. '숫자'와 '영어의 알파벳'을 매칭하였다.
ASCII 코드표
- 영어가 아닌 문자의 문자표
영어권이 아닌 언어들 (한국어, 일본어, 러시아어 등등)의 문자표들은 최초엔 아무런 표준 없이 국소적으로 정의된 문자표를 사용하고 있었다.
이렇다 보니 광주에서는 "3을 '가'라고 하자", 부산에서는 "23을 '가'라고 하자" 라는 식의 문제가 생기기 시작.
- Ex. 썛씠덂쒗뙑같은 문자 깨짐...
이를 해결하고자 국제 표준 문자표인 UNICODE가 생기게 되었다.
- UNICODE (feat. UCS, UTF 인코딩)
전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이며, 유니코드 협회가 제정한다 -위키백과-
전 세계의 모든 문자를 표현할 수 있는 문자열이라는 취지로 제정된 산업 표준 문자표 이다.
하지만, UNICODE에는 각 문자마다 이를 표현하기 위해 사용하는 바이트 수가 다른 문제점이 있었다
- Ex. 영어 1-byte, 한글 2-byte
이러한 가변적인 크기를 컴퓨터가 이해할 수 있게 하도록 각 문자 앞에 표시를 해서 컴퓨터에게 넘겨주게 된다.
이렇게 표시로스 약속된 저장 방식을 바로 인코딩이라고 말한다.
- Ex. 유니코드 인코딩 방식 UTF-8, UTF-16 등등
- Ex. UTF-16으로 저장되어 있는 문자를 UTF-8로 읽으면 당연히 깨진다
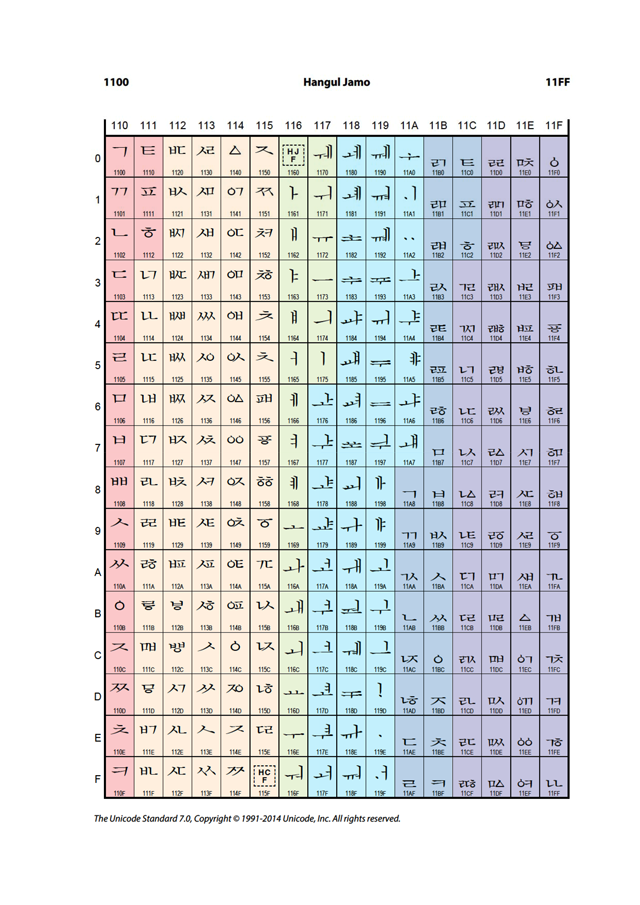
그림) 유니코드 한글 문자표
: column과 row는 각각 16진법의 자릿수 이다. 유니코드에서는 문자와 U+(16진법 수)를 매칭하므로, ㄱ은 U+1100으로 매칭될 수 있다.
한글 깨짐 현상
한글이 깨지는 이유는 대부분 EUC-kr로 인코딩 된 문자를 UTF-8로 읽거나, UTF-8로 인코딩 된 문자를 EUC kr로 읽으려 해서 이다
- KS X 1001 (feat. EUC-KR 인코딩)
- UNICODE 이전에 한글을 표현할 수 있도록 정의된 문자표,
, 옛 이름 KS C 5601
근데 이를 Microsoft에서 윈도우OS 개발에 채택해버렸다. 그리고 이를 인코딩 하는 방식이 바로 EUC-KR이다.
UNICODE의 UTF-8이나 UTF-16으로 인코딩된 한글을
윈도우OS위에서 열려고 하니, 이상한 글자(ex. 썛씠덂쒗뙑)가 출력되게 된다...
( 참고로 요즘 web은 거의 UTF-8인코딩 방식을 많이 씀 )
