관계형 데이터베이스 (RDS)
• 데이터들이 서로 연결되어 관계들로 구성된 데이터베이스
• 데이터를 테이블 형태('스키마'라고 부른다)로 관리 하여 관계를 통해서 연결된 여러 테이블에 분산
• SQL 언어를 사용하여 데이터를 검색 및 조작
• 데이터를 중복없이 다루기에 데이터 무결성이 보장
• 관계를 맺고 있는 데이터가 자주 변경 되는 애플리케이션에서 주로 사용
• Amazon RDS, Amazon Aurora 가 대표적인 서비스

NoSQL = non-SQL = non relational database
• NoSQL = non-SQL = non relational databases
• 관계 구조를 갖지 않는 데이터베이스 관리 시스템
• 관계 구조가 없기에 대규모의 데이터를 유연하게 처리할 수 있는 것이 강점
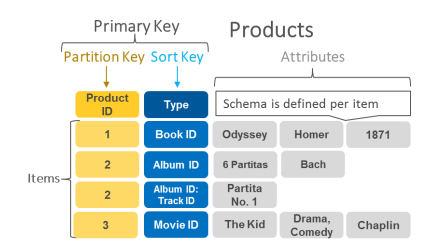
• NoSQL 데이터 베이스는 Key-Value Database, Document Database, Column Family Database, Graph
Database 종류가 있음
• 대표적인 AWS Key-Value 데이터 베이스는 Amazon DynamoDB
인 메모리 데이터베이스
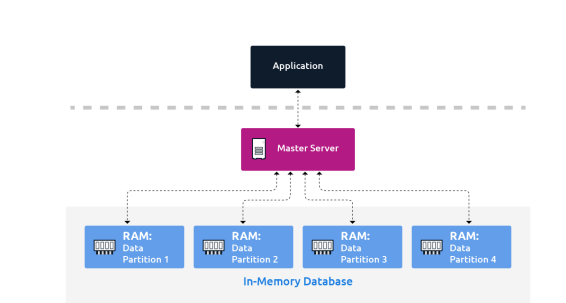
• 디스크가 아닌 주 메모리에 데이터를 보유하고 있는 데이터베이스
• 디스크 검색보다 자료 접근이 훨씬 빠른 것이 가장 큰 장점
• 데이터 양의 빠른 증가로 데이터베이스 응답 속도가 떨어지는 문제를 해결할 수 있는 대안
• Amazon Elasticache 가 대표적인 AWS 인-메모리 데이터 베이스 서비스
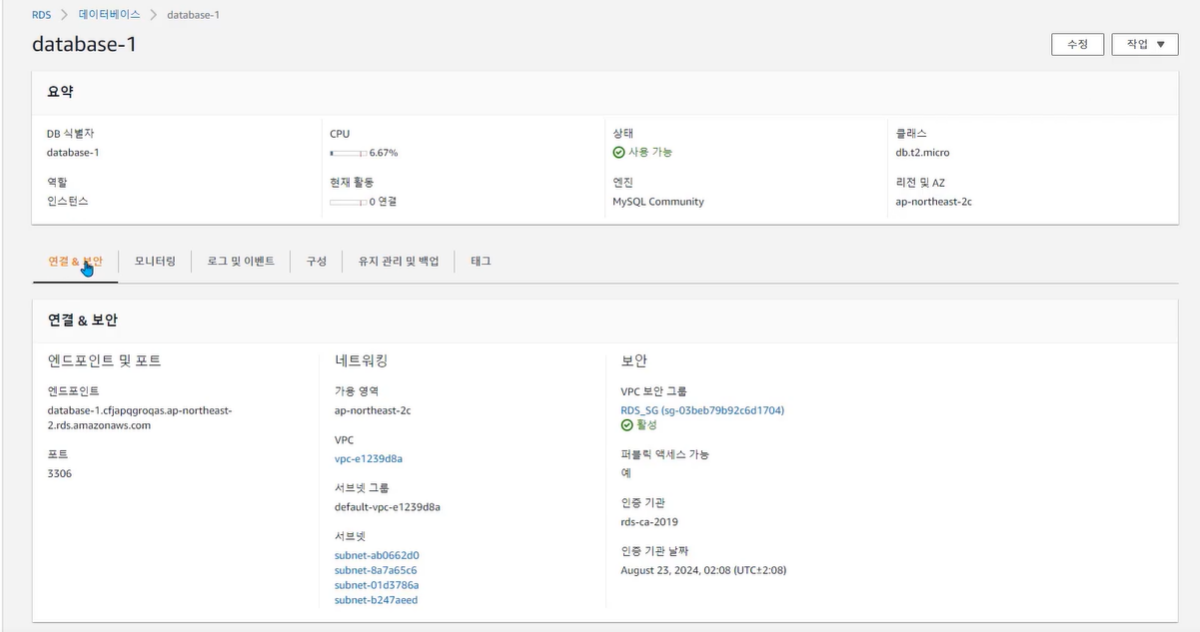
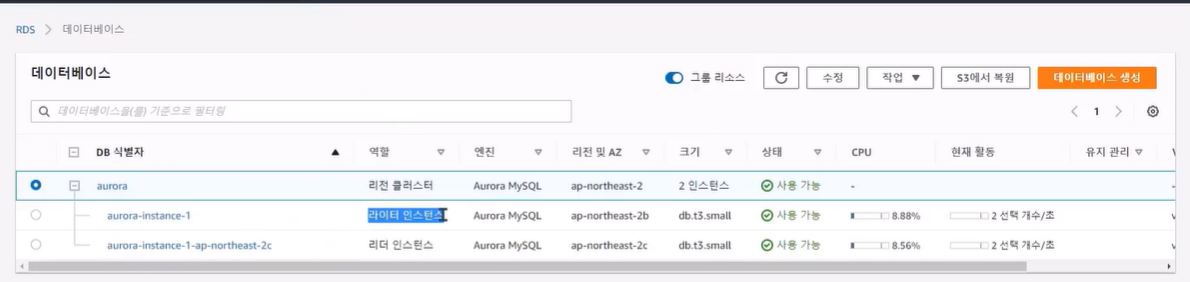
RDS
• 관계형 데이터 베이스 서비스 (Relational Database Service)
• Aurora, PostgreSQL, MySQL, MariaDB, Oracle, SQL Server 등의 RDS 엔진을 AWS에서는 제공
• SQL 쿼리를 이용하는 데이터 베이스 용도에 사용
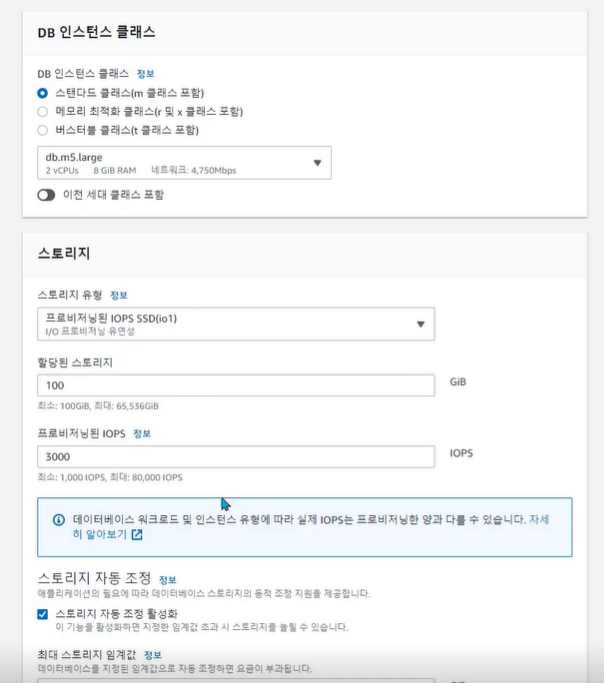
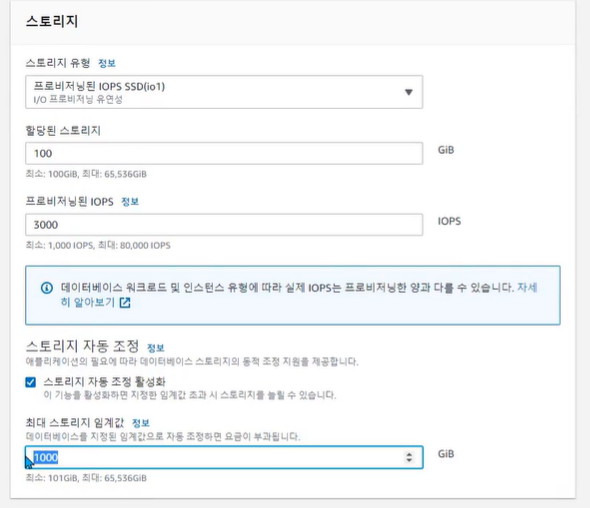
• DB 다운타임 없이 스토리지 용량만큼 자동으로 확장 가능 (Storage Auto Scaling)
• 3가지 데이터베이스 스토리지 유형 제공
✓ 범용 SSD 스토리지: 일반적인 용도
✓ 프로비저닝된 IOPS SSD 스토리지: 빠른 I/O가 필요한 경우 사용
✓ 마그네틱 스토리지: 액세스 빈도가 낮은 경우 사용

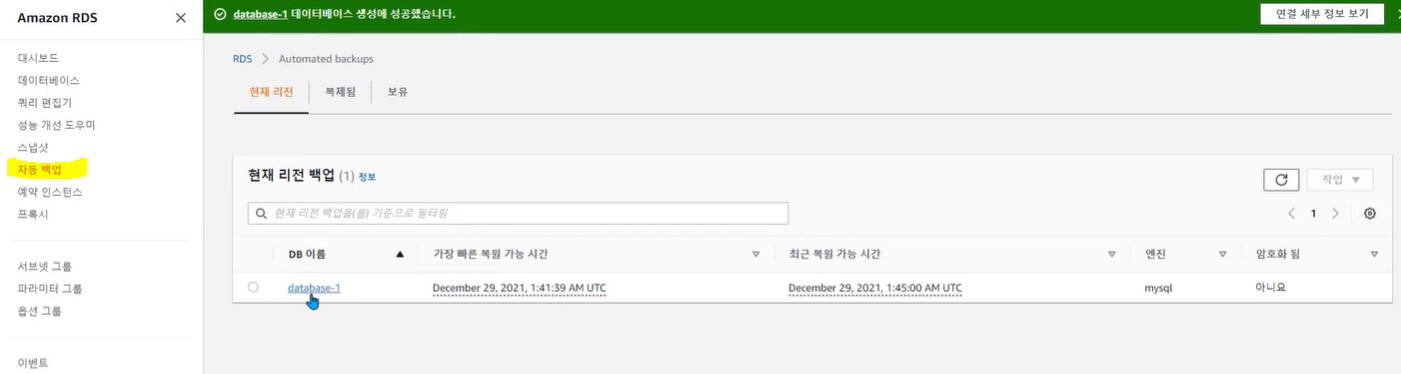
RDS 백업
(• Amazon RDS는 DB 인스턴스 백업 및 복구를 위한 두 가지 방법, 즉 자동 백업 및 데이터베이스 스냅샷(DB스냅샷)을 제공)
자동백업 (Automated backup)
✓ 백업을 수행하는 백업 기간을 설정
✓ 백업 보존 기간은 1일 부터 최대 35일까지 설정 가능
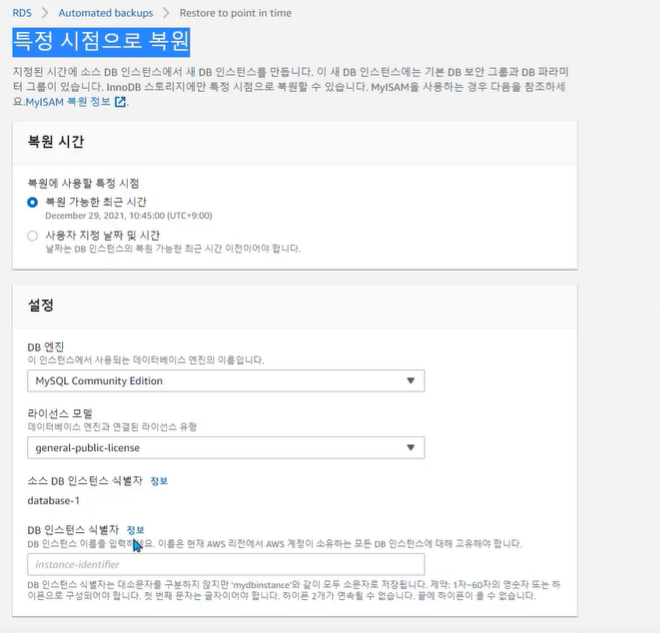
✓ DB 인스턴스를 특정 시점으로 복구 가능 (Point in time recovery)
✓ RDS는 DB 트랜잭션 로그를 5분마다 백업 하므로 가장 오래된 시점 부터 5분전까지 시점으로 복구 가능
✓ 자동백업을 비활성화 하려면 보존기간을 0으로 설정
데이터베이스 스냅샷(DB Snapshots)
✓ 사용자가 수동으로 스냅샷 생성가능(수동 백업)
✓ 사용자가 지정한 만큼 백업을 보존할 수 있음 (스냅샷 보존기간 없음)
• 특정 시점으로 복구 또는 DB 스냅샷에서 복구 작업을 수행하면 새로운 엔드포인트를 가지는 새 DB 인스턴스가 생성 됨(필요한 경우 기존 DB 인스턴스를 삭제할 수 있음)
• Amazon RDS DB 스냅샷과 자동 백업은 S3에 저장
RDS 보안
• SSL/TLS를 사용하여 애플리케이션과 DB 인스턴스 간의 전송 중 암호화 가능
• AWS Key Management Service(KMS)를 통해 관리하는 키를 사용하여 모든 데이터베이스 엔진에 대한 저장 중 암호화 가능
• 암호화 되지 않은 DB 인스턴스 암호화
1. RDS 인스턴스 스냅샷 생성
2. 암호화 된 스냅샷 복사본 생성
3. 암호화 된 스냅샷에서 RDS 인스턴스 복원
• 암호/패스워드 이외에 IAM 사용자 및 역할을 통해 데이터베이스 인증 적용 가능
• RDS에 보안그룹을 연결하여 IP주소, EC2 인스턴스에 대한 데이터베이스 연결 제어 가능
• RDS Audit Logs 기능을 사용해 보안 감사에 활용 가능 (로그 데이터 장기 보관을 위해 로그를 CloudWatch Logs에 보낼 수 있음)
RDS - 읽기 전용 복제본 (Read Replica)
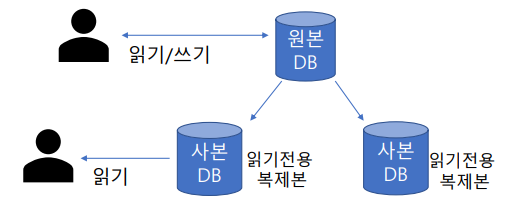
• 읽기만 가능한 DB 인스턴스의 복제복을 여러 개 만드는 기능
• 읽기를 별도로 분리하여 성능을 향상
• 원본 DB의 읽기/쓰기 트래픽을 분산시켜 성능 향상
• SQL쿼리를 많이 하는 리포팅 툴의 경우 읽기 복제본으로 연결하여 쿼리 성능 향상
• 읽기 전용 복제본이 작동하려면 백업이 활성화된 상태로 유지되어야 함
• 활성 상태의 장기 실행 트랜잭션이 있으면 완료 후에 읽기 전용 복제본을 생성하는 것을 권장
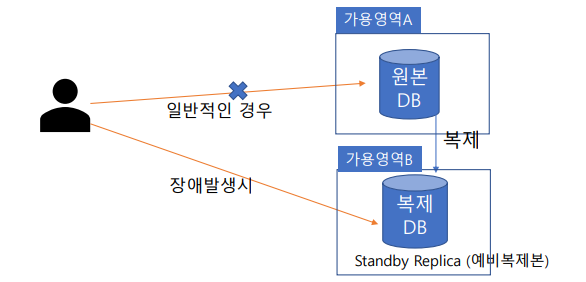
RDS – 다중 AZ (Multi-AZ) :데이터 베이스를 여러 가용영역에 배치 하는 것
• 내구성과 가용성을 향상 시킬 수 있음 (RDS 데이터베이스 다운타임이 가장 적게 할 수 있음)
• DB 인스턴스에 대한 업데이트는 가용 영역 전체에서 예비 복제본에 동기식으로 복제
• 한곳의 DB가 장애 발생하면 다른 곳으로 자동연결 하도록 장애 조치 수행 (재해 복구 용도로 사용)
• Standby Replica(예비복제본)은 읽기 트래픽 처리 불가 (다중 AZ RDS는 읽기 트래픽 분산 용도가 아님)
//
RDS – RDS Custom
• EC2에 RDS를 설치하여 구성하는 경우는 사용자가 서버를 포함한 모든 부분을 관리
• RDS는 AWS에서 데이터베이스와 운영체제(OS)를 모든 부분을 관리하는 완전관리형 서비스
• RDS Custom은 사용자가 데이터베이스와 운영체제에 대한 관리 권한을 가짐
✓ 예) 사용자 지정 DB 및 OS 패키지 설치, 특정 DB 설정 구성, 파일 시스템 구성, 자체 라이센스 관리 등

RDS PROXY
Proxy는 중계하는 기능, 그냥 RDS만 사용하면 애플리케이션과 데이터베이스가 다이렉트로 연결이 됨. 그런데 프록시 서버를 중간에 놓게 되면 애플리케이션과 데이터베이스 사이에 RDS Proxy가 놓이게됨 (중간에 연결하는 기능)
여러개의 애플리케이션이 있을수 있고 이게 여러개의 RDS 프록시에 연결되고, 프록시가 데이터베이스에 연결하면 여러 어플리케이션이 데이터베이스 연결을 공유할 수 있기 때문에 리소스를 효율적으로 사용할 수 있음!
장점1) 장애조치 시간이 감속
애플리케이션 연결을 유지하면서 예비 DB인스턴스에 자동으로 연결됨ㅁ으로
장점2) 보안 - 중간에 프록시가 있으니까!
장점3) 데이터베이스 성능 유지
매번 새로운 연결을 데이터베이스에 직접 만들 필요가 없기 때문에
이 연결을 만드는데 필요한 데이터베이스의 메모리 및 cpu 등의 사용량을 감소 시킬수 있음, 데이터베이스에 열린 연결 수 제어
• 데이터베이스 프록시 기능
• 애플리케이션이 데이터베이스와 연결 풀링(pool)하고 공유하도록 하는 기능
• 여러 애플리케이션 연결에서 데이터베이스 연결을 공유할 수 있으므로 데이터베이스 리소스를 효율적으로
사용
• 데이터 베이스 장애 조치 시간 감소
✓ 애플리케이션 연결을 유지하면서 예비 DB 인스턴스에 자동으로 연결
• 보안 개선
✓ 데이터베이스에 AWS IAM 인증을 필요에 따라 적용하고 AWS Secrets Manager에 보안 인증 정보를
안전하게 저장
• 데이터 베이스 성능 유지
✓ 데이터베이스 연결 풀을 설정하고 매번 새 데이터베이스 연결을 여는 데 필요한 메모리 및 CPU 오버헤드 없이 이 풀에서 연결을 다시 사용
✓ 연결 요청이 지정된 한도를 초과하는 경우 애플리케이션 연결을 거부 (데이터 베이스 열린 연결 수 제어) 하여 부하 감소
Aurora는 aws에서 개발한 rds엔진임
auto scaling
Aurora
>특징
• RDS 호환형 관계형 데이터 베이스
• RDS에서 제공하는 읽기 전용 복제본, KMS암호화, 스냅샷 백업, 오토스케일링, RDS Proxy 등을 제공
• AWS에서 만든 서비스로 다른 RDS보다 저렴한 비용에 성능이 더 뛰어남
• 다른 RDS보다 속도는 3-5배 빠름
• 데이터베이스 설정, 패치 적용 및 백업과 같은 관리 태스크를 자동화
• 개별 DB 인스턴스 기반이 아닌 여러 인스턴스를 하나로 운영하는 클러스터 DB 기반으로 구성 됨
Aurora DB 클러스터
• 하나 이상의 DB 인스턴스와 이 DB 인스턴스의 데이터를 관리하는 클러스터 볼륨으로 구성
• DB 인스턴스는 읽기/쓰기 작업을 하는 기본 DB인스턴스와 읽기 작업만 하는 Aurora 복제본으로 구성
• 각 Aurora DB 클러스터는 기본 DB 인스턴스에 더해 최대 15개까지 Aurora 복제본을 구성
Aurora 복제본(Replicas)
• 3개의 가용영역에 6개의 데이터 사본을 자동 복제하여 고 가용성 및 성능 향상 지원
• 마스터 DB와 최대 15개의 Aurora Read Replica 지원
• 읽기 로드를 여러 복제 본에 분산시켜 성능을 향상시킬 수 있음
• 마스터 DB에 장애 발생시 최대 30초 이내에 복제본 중 하나가 기본 인스턴스 역할로 변경 되는 장애조치 (Failover) 가능 - rds는 MZ를 사용하여 standby
• Aurora Auto Scaling을 사용해 워크로드에 따라 Aurora 복제본 수를 자동으로 조정 가능
Aurora 글로벌데이터베이스
• 다른 리전으로 데이터베이스 복제하는 기능
• 1초 미만의 대기 시간(RPO 1초)으로 최대 5개의 보조 리전에 복제
• 보조 리전 중 하나가 1분 이내에 읽기 및 쓰기 기능으로 승격 가능 (RTO 1분)
• 재해복구 용도, 사용자가 가까운 리전에서 빠르게 액세스 가능
Aurora Database Cloning
• 현재 Aurora DB 클러스터를 복제하여 원본과 동일 데이터를 갖는 새 Aurora DB 클러스터를 생성하는 기능
• Snapshot을 만들고 복원하는 것보다 빠르고 비용 효율적
• Production DB 클러스터에 영향없이 테스트, 개발 등의 용도를 위한 Staging DB 클러스터 생성 가능
Aurora Machine Learning
• Aurora DB에서 Machine Learning 기능 사용
• Amazon SageMaker 또는 Amazon Comprehend 서비스와 통합하여 사용 가능
• 예, 쿼리를 사용해 고객 프로필, 쇼핑기록, 제품 카달로그 데이터를 SageMaker 모델로 전달하여 학습 후 제품 권장 사항 데이터를 가져옴
Aurora 멀티 마스터 클러스터
• 단일 마스터 클러스터
✓ 단일 DB 인스턴스는 모든 쓰기 작업을 수행하며, 기타 모든 DB 인스턴스는 읽기 전용입니다. 라이터 DB 인스턴스가 사용 불가 상태가 되면 장애 조치 메커니즘이 읽기 전용 인스턴스 중 하나를 새 라이터로 승격
• 멀티 마스터 클러스터
✓ 모든 DB 인스턴스는 쓰기 작업을 수행
✓ 라이터 DB 인스턴스가 사용 불가 상태가 될 때 어떤 장애 조치도 없음
✓ 읽기/쓰기 DB 인스턴스가 사용 불가 상태가 될 때 장애 조치 프로세스 및 관련 지연이 발생하지 않음
Aurora Serverless
• DB 인스턴스 운영 및 데이터 베이스 용량을 수동으로 관리 하지 않음
• 특정 DB 인스턴스 유형을 선택하지 않음
• 사용량에 따라 DB 용량을 자동으로 빠르게 용량을 확장하고 축소하는 기능
• 사용한 만큼만 DB 용량을 초당 요금으로 지불
• DB 사용빈도가 낮은 애플리케이션에 효과적
ElasticCache
• 인메모리 데이터 스토어
• 1밀리 초 미만의 빠른 응답시간을 제공
• 빠른 응답이 필요한 애플리케이션에 사용
• 기존의 DB와 연결하여 DB응답성능을 개선하기 위해 사용 (사용하는 DB 데이터를 캐시)
• ElastiCache를 사용하기 위해서는 애플리케이션의 코드변경이 필요
• 세션 스토어, 게임 리더보드, 스트리밍 및 분석과 같이 내구성이 필요하지 않는 기본 데이터 스토어로 사용
• 오픈소스 인메모리 데이터베이스 솔루션인 Redis또는 Memcached 두가지 유형을 지원
• Memcached는 멀티쓰레드 지원, Redis는 싱글쓰레드만 지원
• 일반적으로 Redis가 더 많은 기능을 지원 (스냅샷 백업, 복제기능, 고가용성 제공 등)
ElastiCache vs. Read Replica
RDS Read Replica
• 데이터베이스: 영구적인 데이터 저장
• 데이터가 계속 변경되는 쿼리(Query)의 읽기 성능 향상에 적합 (데이터가 지속적으로 원본과 동기화 됨)
ElastiCache
• 인-메모리 캐싱: RAM과 같이 빠른 하드웨어에 일시적으로 저장
• 지연시간을 줄이는 목적으로 주로 사용
• 속도는 빠르지만 저장할 수 있는 공간에 제약이 있음
• 변경이 없는 동일한 데이터를 계속 읽는 경우의 성능 향상에 적합 (데이터 변경 시 원본으로 부터 데이터를 로드해야 함)
DynamoDB
• NoSQL 데이터베이스 서비스
• 키-값, 문서 데이터 모델 지원
• 서버리스 서비스
• 용량에 맞게 자동으로 확장 및 축소(Auto Scaling) 하므로 관리 및 운영 오버헤드 최소화
• 10밀리 초 미만의 빠른 응답을 제공
• 초당 수백만개 이상의 요청 처리 가능
• 지연시간이 짧은, 빠른 응답이 필요한 애플리케이션에 사용
• 쇼핑몰 장바구니, 은행 트랜잭션, 게임 플레이어 기록 저장 등에 사용
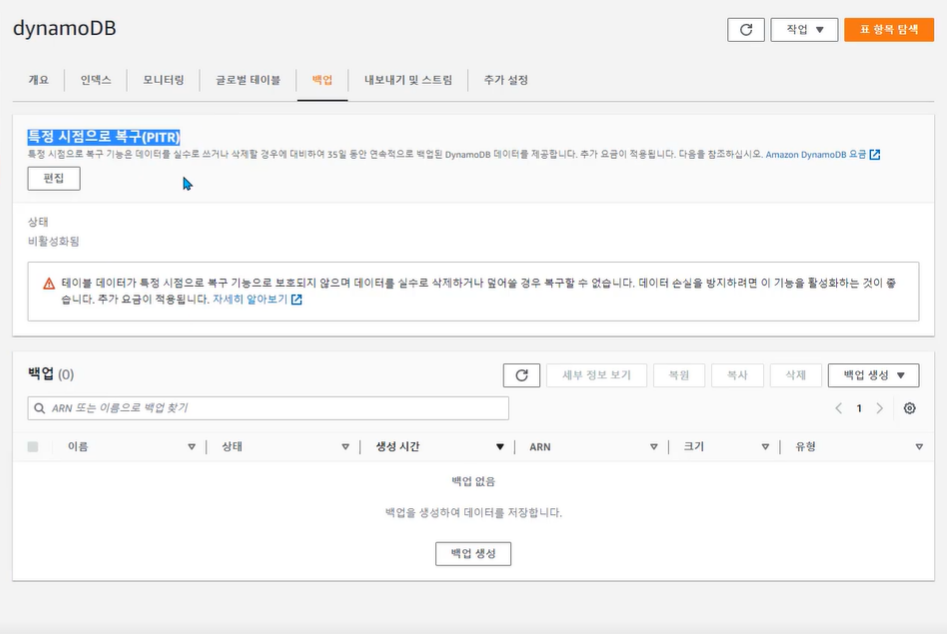
백업 및 복구
• DB 테이블에 대해 온디맨드 백업을 생성하고 특정 시점으로 복구를 활성화
• 특정 시점으로 복구 PITR(Point-in-time recovery)를 사용해 최근 35일 이내 원하는 시점으로 테이블 복원가능
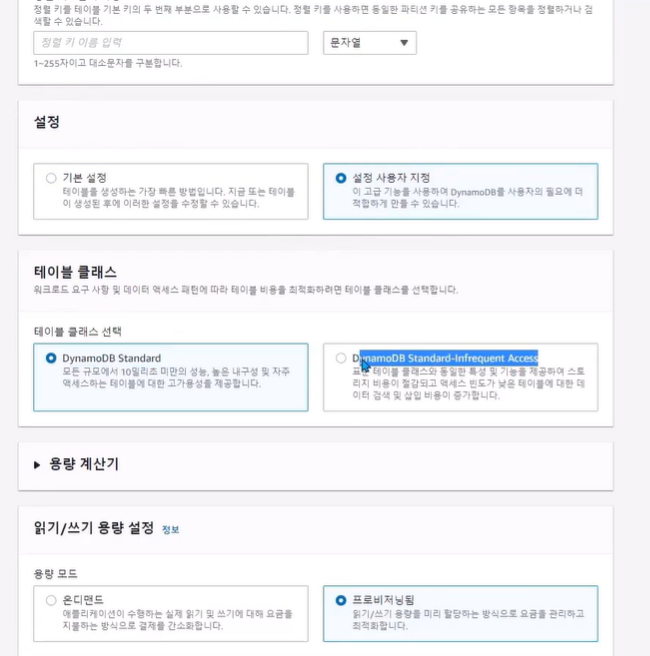
DynamoDB 테이블 클래스
• DynamoDB Standard : 기본형으로 대부분의 워크로드에 권장
• DynamoDB Standard-IA : 애플리케이션 로그, 오래된 소셜 미디어 게시물, 전자 상거래 주문 내역 및 과거 게임 성과와
같이 자주 액세스하지 않는 데이터를 저장하는 테이블에 대한 비용을 줄임
읽기/쓰기 용량모드
• 온디맨드 모드: 초당 읽기/쓰기 처리량을 자동으로 조정, 트래픽 예측이 불가능한 경우 사용
• 프로비전드 모드: 읽기/쓰기 횟수를 수동으로 조정. 트래픽 예측이 가능한 경우 사용
DynamoDB Accelerator (DAX)
• 데이터베이스 앞에 인메모리 캐시를 사용해서 DB의 읽기 성능을 향상시키는 기능
• 마이크로 초 단위의 응답시간을 제공
TTL(Time to Live)
• DynamoDB 유지 시간(TTL)을 사용하여 항목별 타임스탬프를 정의하여 항목이 더 이상 필요하지 않은 시점을 결정
• 지정된 타임스탬프 날짜 및 시간이 지나면 DynamoDB 테이블에서 항목을 삭제
• 예, 애플리케이션에서 1년 동안 사용하지 않은 사용자 또는 센서 데이터를 제거
• 예, 만료된 항목을 Amazon DynamoDB Streams 및 AWS Lambda를 통해 Amazon S3에 보관
글로벌테이블
• 리전간에 데이터베이스를 복제하는 기능
• 모든 리전에서 읽기, 쓰기 가능
• 복제본 테이블에 있는 항목의 모든 변경 사항은 동일한 글로벌 테이블 내의 다른 모든 복제본에 1초 이내로 복제됨
• 하나의 리전에 문제가 발생해도 다른 리전으로 라우팅 되므로 재해 복구 기능을 함
• 사용자는 가까운 리전에서 DB를 사용하기에 더욱 빠른 성능 지원
DynamoDB Streams
• DB 테이블에 저장된 항목에 변경이 발생하는 경우 변경 사항을 캡쳐하는 기능
• 예, 변경 사항에 대해 Kinesis Data Stream으로 보낼 수 있음
• 예, 변경 사항 이벤트가 발생할 때마다 이벤트를 Lamba로 트리거 하여 Amazon SNS로 전송하여 이메일 등의 이벤트 알림을 생성할 수 있음
읽기 일관성
• DynamoDB에서 데이터를 읽을 때, 사용자는 읽기를 최종적 일관된 읽기나 강력한 일관된 읽기로 지정 가능
• 최종적 일관된 읽기(기본값)
✓ 최종 일관성 옵션은 읽기 처리량을 최대화
✓ 최종적 일관된 읽기는 최근 완료한 쓰기 결과를 반영하지 못할 수 있음
• 강력한 일관된 읽기
✓ 읽기 전에 성공적인 응답을 수신한 모든 쓰기를 반영한 결과를 반환
✓ 최종적 일관된 읽기 보다 읽기 지연시간이 길어지거나 처리 용량을 많이 사용
**
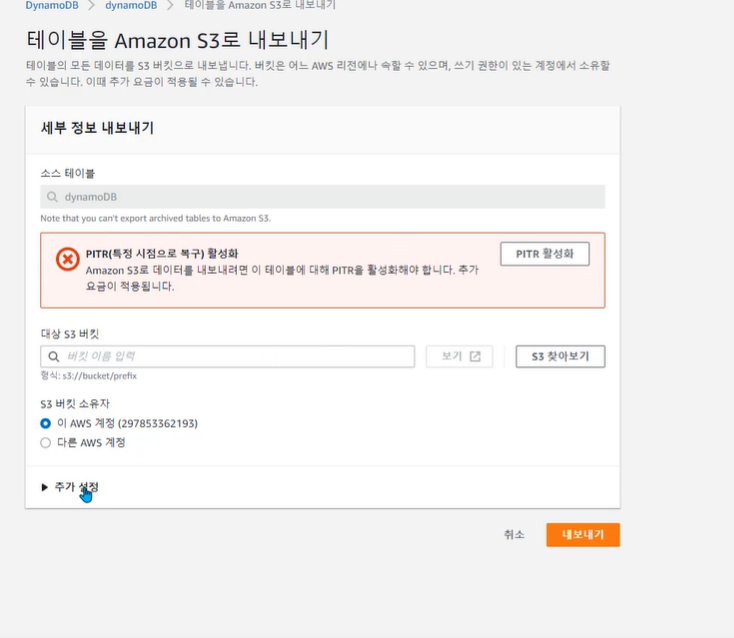
DynamoDB – Amazon S3와 통합
Export to Amazon S3 (S3로 내보내기)**
• DynamoDB 테이블의 데이터를 S3 버킷으로 보내는 기능
• 자동 백업인 특정 시점으로 복구(PITR)기간내의 데이터만 내보낼 수 있음 (최대 35일)
• 기능 사용을 위해서는 특정 시점으로 복구 PITR(Point-in-time recovery)가 활성화 되어야 함
• 데이터를 DynamoDB JSON 형식 또는 Amazon Ion 텍스트 형식으로만 내보낼 수 있음
• S3로 내보낸 데이터를 Athena, AWS Glue, Lake Formation 등의 다른 AWS 서비스를 사용하여 데이터에 대한 분석과 복잡한 쿼리를 수행 가능
• 테이블 내보내기는 테이블의 읽기 용량을 사용하지 않으며 테이블 성능 및 가용성에 영향을 주지 않음
• 테이블 데이터를 다른 AWS 계정이 소유한 S3 버킷 및 해당 테이블이 있는 리전과 다른 리전으로 내보낼 수 있음
Import to Amazon S3 (S3에서 가져오기)
• S3의 데이터를 DynamoDB 테이블로 가져오는 기능
• CSV, DynamoDB JSON 형식 또는 Amazon Ion 텍스트 형식을 가져올 수 있음
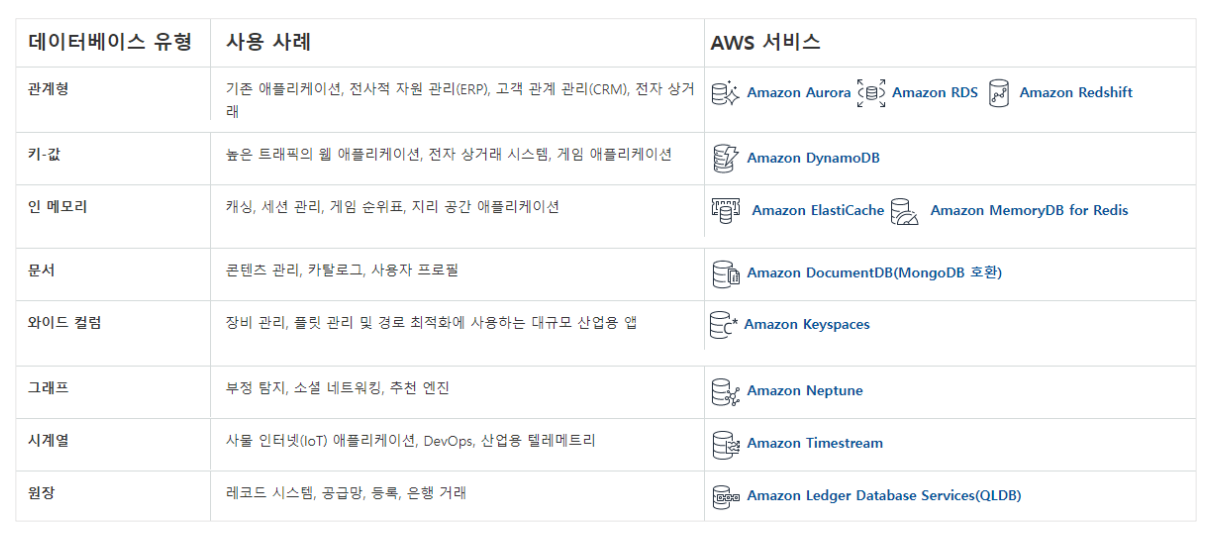
Other Databases
Amazon DocumentDB (with MongoDB compatibility)
• MongoDB를 호환하는 Document Database
• MongoDB는 JSON 데이터를 저장, 쿼리 및 인덱싱하는 데이터베이스 시스템
Amazon Keyspaces (for Apache Cassandra)
• Apache Cassandra 호환 데이터베이스 서비스
• Apache Cassandra는 오픈소스 NoSQL 분산 데이터베이스
• Wide Column 데이터 베이스 모델 사용
Amazon Neptune
• 그래프 데이터베이스 서비스
• 노드들의 관계들로 이루어진 데이터 베이스 (예, SNS)
Amazon Quantum Ledger Database(Amazon QLDB)
• 원장(Ledger) 데이터 베이스
• 데이터에 적용된 모든 변경 사항에 대해 암호로 확인할 수 있는 완전한 기록을 제공
Amazon Timestream
• 시계열(time serise) 데이터베이스 서비스
• 시계열 데이트는 시간에 따라 저장된 데이터 (예, IoT 센서 데이터)
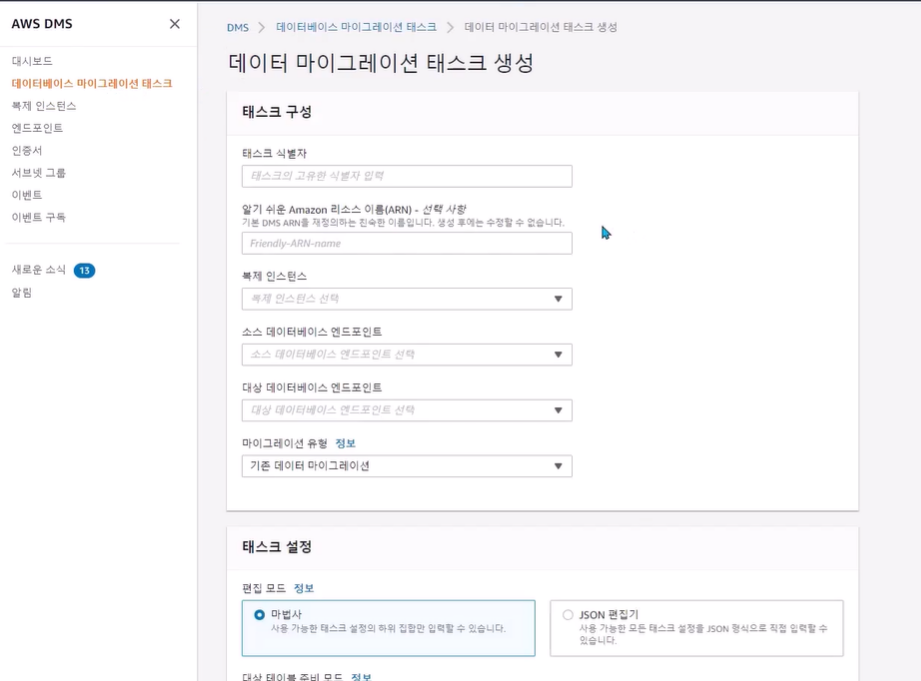
Database Migration Service (DMS)
데이터베이스를 마이그레이션 하는 서비스 (DB -DB)
온프레미스에서 aws 또는 aws내에서 마이그레이션 가능
원본 db를 사용하는 중에도 지속적으로 마이그레이션가능
같은 종류의 서로 다른 종류 DB도 마이그레이션 가능
이 기종의 DB는 Schema Conversion Tools(SCT)를 이용하여 데이터 스키마를 마이그레이션 대상 db에 적합하게 변환해야함
같은 종류의 db는 데이터 변환 필요가 없음