Amazon Athena
• 표준 SQL을 사용해 Amazon S3에 저장된 데이터를 분석할 수 있는 쿼리 서비스
• Athena로 데이터를 로드 할 필요 없이 S3에 저장된 데이터를 직접 사용
• CSV, JSON, ORC, Avro 또는 Parquet와 같은 다양한 종류의 데이터 형식을 지원
• 예, S3에 csv 데이터 파일을 저장하여 Athena를 사용해 SQL 쿼리를 하는 비용 효율적인 솔루션 구축
• Athena 연합 쿼리를 사용하여 Amazon CloudWatch Logs, Amazon DynamoDB, Amazon DocumentDB,
Amazon RDS, JDBC 호환 관계형 데이터베이스(Apache 2.0 라이선스에 따른 MySQL, PostgreSQL 등)와 같은 데이터 원본에 저장된 데이터에 대해 SQL 쿼리 수행 가능
• Amazon QuickSight와 통합하여 쿼리된 데이터를 시각화 할 수 있음
Amazon Redshift
• 데이터웨어하우스 서비스
• 데이터 웨어하우스는 의사 결정을 위한 정보의 집합
• 데이터 웨어하우스는 여러 소스로부터 얻은 구조화되거나 반 구조화된(정형 및 반정형) 대량의 데이터를 중앙 집중화 및 통합 하여 데이터 웨어하우스의 분석 기능을 통해 데이터에서 귀중한 비즈니스 통찰력을 도출 하여 의사결정을 개선
• Amazon S3, Amazon RDS, Amazon DynamoDB, Amazon Kinesis Data Firehose, Amazon EMR, AWS Glue, AWS Data Pipeline 및 Amazon EC2 또는 온프레미스의 모든 SSH 지원 호스트를 비롯하여 다양한 데이터 소스에서 Amazon Redshift로 데이터를 로드
• 비즈니스 애널리스트, 데이터 엔지니어, 데이터 사이언티스트 및 의사 결정권자는 비즈니스 인텔리전스(BI)
도구(예, Amazon QuickSight), SQL 클라이언트 및 기타 분석 응용 프로그램을 통해 데이터에 액세스
Amazon OpenSearch Service (Amazon Elastic Search Service)
• OpenSearch는 Elasticsearch에서 파생된 오픈 소스 분산 검색 및 분석 제품
• 로그 분석, 실시간 애플리케이션 모니터링 및 웹사이트 검색 등을 쉽게 수행할 수 있게 해주는 서비스
• 다양한 소스에서 스트리밍 데이터를 Amazon OpenSearch Service 도메인으로 로드
✓ Amazon Kinesis Data Firehose 및 Amazon CloudWatch Logs와 같은 일부 소스는 OpenSearch Service 를 기본으로 지원
✓ Amazon S3, Amazon Kinesis Data Streams 및 Amazon DynamoDB와 같은 다른 소스는 AWS Lambda 함수를 이벤트 핸들러로 사용하여 로드
AWS QuickSight
• 클라우드 기반의 비즈니스 인텔리전스(BI) 도구
• 대시보드, 그래프 등의 시각화를 통한 데이터 분석을 통해 의사결정을 도와주는 서비스
• AWS 데이터, 타사 데이터, 빅 데이터, 스프레드시트 데이터, SaaS 데이터, B2B 데이터 등의 다양한 데이터 소스와 연결 가능
• CSV 파일과 Excel 파일을 업로드하고, Salesforce와 같은 SaaS 애플리케이션에 연결하고, SQL Server, MySQL 및 PostgreSQL과 같은 온프레미스 데이터베이스에 액세스하고, Amazon Redshift, Amazon RDS, Amazon Aurora, Amazon Athena 및 Amazon S3와 같은 AWS 데이터 소스를 원활하게 검색
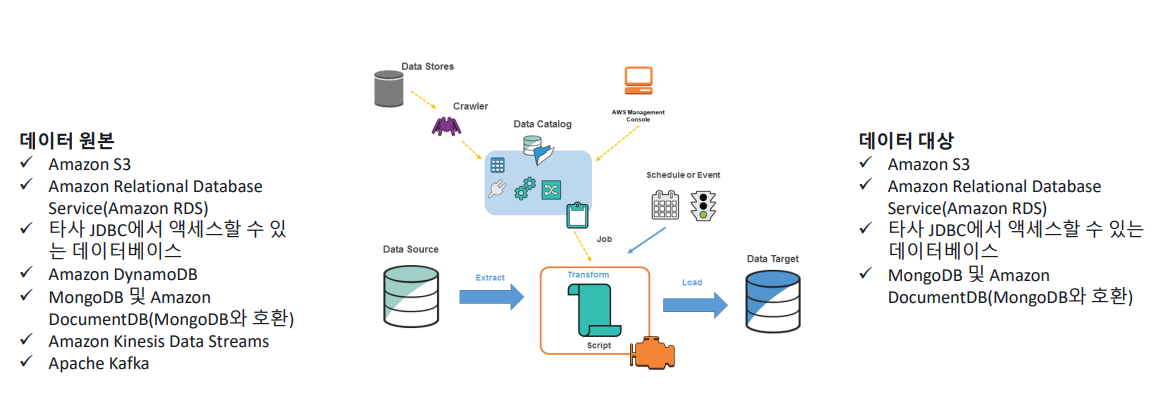
AWS Glue
• 데이터 분석을 위한 ETL(Extract, Transform and Load, 추출, 변환 및 로드 ) 서비스
• 다양한 소스에서 데이터 검색 및 추출, 데이터 강화, 정리, 정규화 및 결합, 데이터베이스, 데이터 웨어하우스 및 데이터 레이크에 데이터 로드 및 구성 등의 여러 작업을 포함
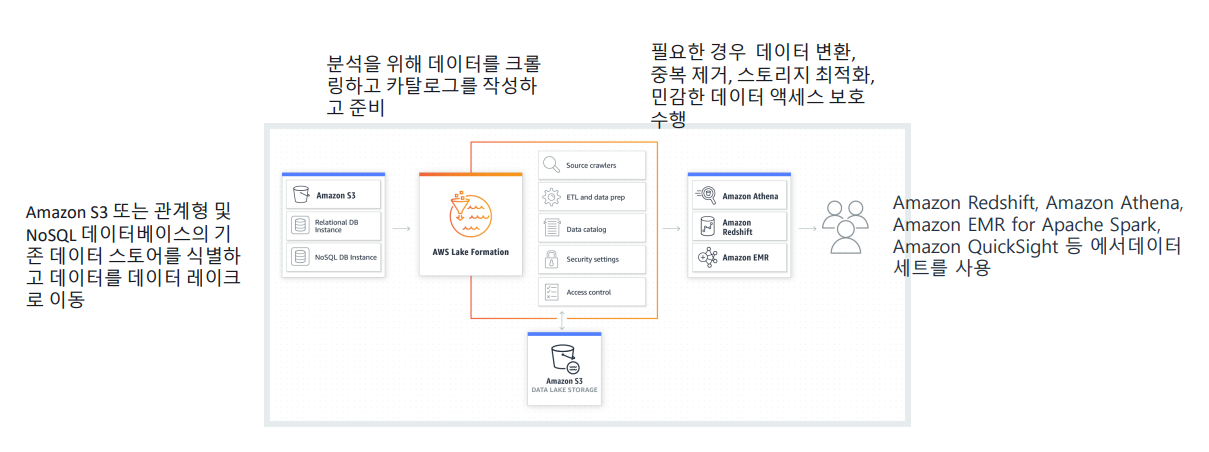
AWS Lake Formation
• 데이터 레이크 서비스
• 데이터 레이크는 조화되거나 반구조화되거나 구조화되지 않은 모든 유형의 대량의 데이터를 저장, 처리, 보호하기 위한 중앙 집중식 저장소
Amazon EMR(Elastic MapReduce)
• 클라우드 빅데이터 플랫폼
• MapReduce는 분산 병렬처리 컴퓨팅 모델의 이름
• EMR은 빅데이터 플랫폼인 Hadoop 클러스터를 손쉽게 생성해 주는 서비스
• Apache Spark, Apache Hive 및 Presto와 같은 오픈 소스 프레임워크를 사용
• 데이터 처리를 위한 EMR 클러스터(수십 ~ 수백 대의 EC2 인스턴스)를 자동으로 구성하고 확장 및 축소를 하는 기능을 함
• 머신러닝, 빅데이터 처리 등에 사용
