이번에 백엔드로 숙박 예약 서비스를 구축하는 프로젝트에 참여하게 되었고 백엔드 포지션으로 프로젝트를 진행하며 생긴 이슈들, 고민을 해결하는 과정 등을 뒤늦게 기록으로 남긴다.
어떤 방식으로 프로젝트를 진행했고 내가 작업했던 내용, 배운 것, 느낀 점 등을 바탕으로 회고를 작성해보겠다.
인원 구성 및 기간
3월 18일 ~ 4월 5일 약 3주 기간동안 서비스를 1차적으로 완성하고 이후 3주의 추가기간을 가지는 동안 부족했던 부분을 리팩토링 하고 추가 공부를 통해 서비스 기능을 고도화하는 시간을 가졌다.
팀원은 FE 3명 BE 2명으로 구성되어 Slack을 중심으로 질문 사항이나 이슈 사항을 즉각적으로 피드백 받고 주기적인 회의를 통해 서로의 진행 상황과 문제점 등을 공유하는 시간을 가졌다.
구현해야할 사항들이 회의를 통해 빠르게 fix되는 과정을 거쳐 정기 회의가 많이 필요하지 않다고 느꼈었다. 하지만 실제 구현이 이루어지는 과정에서 FE, BE 양쪽에서 생각보다 많은 이슈 사항이 발생했고, 프로그래밍 외적인 부분에서도 발생하는 이슈들을 공유하기 위해 조금 더 많은 회의를 통해 서로의 고민과 문제점을 공유하는 시간을 더 가졌다면 좋았을 것이라는 생각을 했다. 다음 프로젝트를 진행할 때는 짧은 시간이라도 간단하게 스탠드업 미팅을 가지는 시간을 가져 서로의 고민을 공유하는 시간을 가지는 것도 좋고, 같은 파트의 팀원과도 조금 더 많은 이야기를 나누고 싶다.
Github Issue & Project를 활용한 프로젝트 관리
개인 프로젝트를 진행할 때도 Issue 발급을 중심으로 한 프로젝트 진행 상황 문서화를 선호했기 때문에 이번 팀 프로젝트를 진행할 때도 Issue를 중심으로 feature branch를 효율적으로 사용하고, 구현 내용을 Project에서 제공하는 QC보드를 활용해 시각화하는 방법을 도입했다.
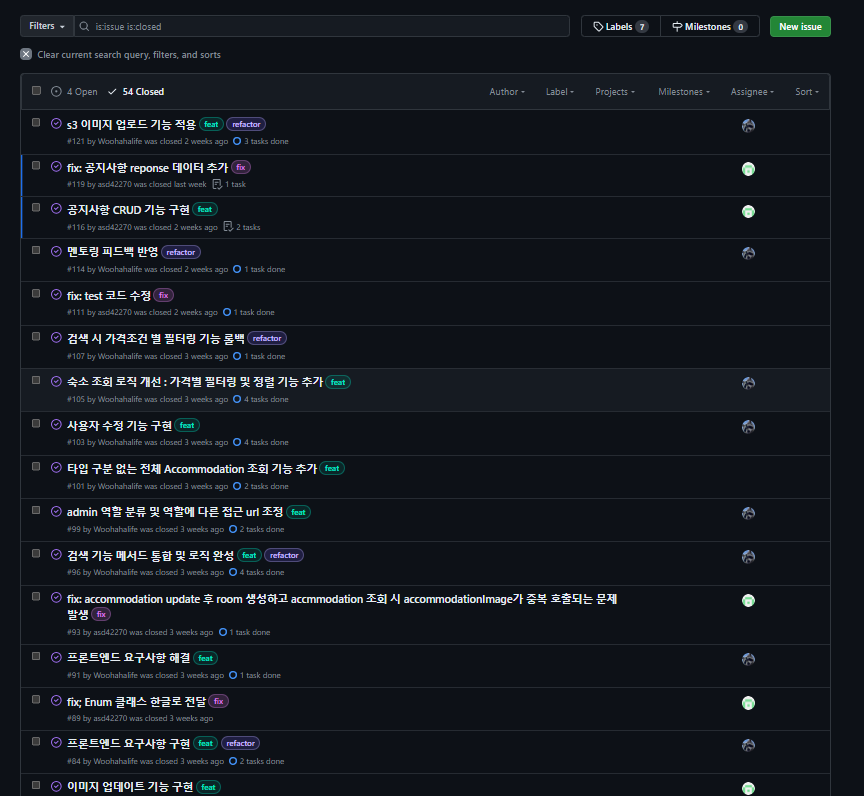
Issue 발급을 활용해 진행한 작업 내용과 상세 task를 팀원과 공유했다.
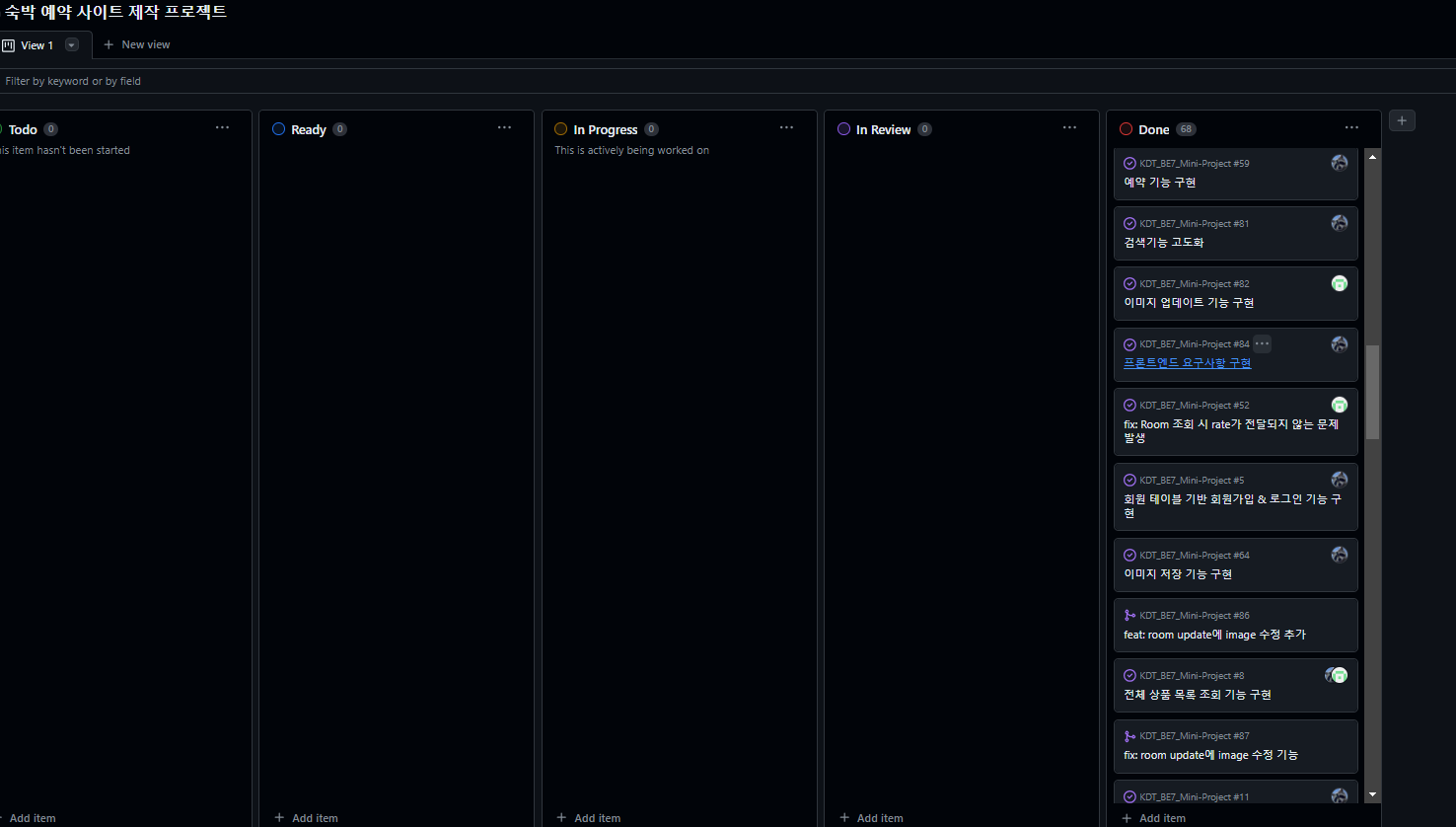
또한 발급한 Issue의 진행 상황과 완료 여부를 시각화할 수 있도록 Project기능을 적극 활용했다.
Github에서 제공하는 두 기능을 사용해 프로젝트를 관리하면서 팀원과의 작업 진행 상황을 공유하는 과정이 훨씬 수월해져서 큰 도움이 되었다. Issue 작성에 부담이 없도록 작성 템플릿을 따로 만들어 설정해 작업 내용을 공유하는 과정에서 가독성을 향상시켰고, 이외에도 pr templete을 적극 활용해 Github상에서의 컨벤션을 수월하게 지키면서 구현에 조금 더 집중할 수 있었다.
진행 과정에서 겪었던 Issue 사항과 고민들
1. 숙소 - 예약 내역을 동적으로 조회해 사용자들이 조회 과정에서 정확한 정보를 받을 수 있도록 하는 과정
숙박 예약 시스템 개발을 진행하면서 제일 많이 했던 고민이 사용자가 선택한 일자에 예약을 원하는 숙소 리스트를 조회할 때, 선택 일자의 범위에 예약 내역이 있는 숙소가 있는 경우 이를 어떻게 필터링하여 남은 결과만 조회할 수 있도록 할 것인가 하는 문제였다.
2024-03-28(checkIn) ~ 2024-03-31(checkOut) 의 숙박 기간을 설정해 검색할 경우
- 2024-03-28 ~ 2024-03-31 기간 안에 포함된 예약 내역을 보유한 숙소는 필터링 되어야 한다.
- checkIn 일자가 03-28 ~ 03-31 범위에 포함되고 checkOut 일자가 03-31 이후인 예약 내역을 보유한 숙소는 필터링 되어야 한다.
- checkOut 일자가 03-28 ~ 03-31 범위에 포함되고 checkIn 일자가 03-28 이전인 예약 내역을 보유한 숙소는 필터링 되어야 한다.
- checkIn 일자가 03-28 이전 이고, checkOut 일자가 03-31 이후인 예약 내역을 보유한 숙소는 필터링 되어야 한다.( 소비자가 검색한 기간이 예약된 기간 범위 안에 포함된 경우 )
이 조건들을 동적으로 설정해 쿼리로 필터링 하는 과정이 아직도 몹시 힘들었다.
정규화를 통해 테이블을 적극적으로 분리했던 상황이었고, 숙박과 예약 데이터를 조회하는 과정에서 depth가 깊어져 n+1 문제 또한 해결할 수 없어 난항을 겪고 있었다.
이에 대한 해결 방안으로,
2. nativeQuery 사용
@Query(value = """
SELECT DISTINCT a.*
FROM Accommodation a
LEFT JOIN Room r ON a.accommodation_id = r.accommodation_id
LEFT JOIN Rate rate ON a.accommodation_id = rate.accommodation_id
LEFT JOIN AccommodationImage ai ON a.accommodation_id = ai.accommodation_id
left join location l on a.location_id = l.location_id
LEFT JOIN Discount d ON a.discount_id = d.discount_id
LEFT JOIN Reservation res ON r.room_id = res.room_id
WHERE a.is_deleted = false
AND (res.room_id IS NULL OR res.is_visited <> 'VISIT_DATE')
AND (res.room_id IS NULL OR res.is_visited <> 'VISITED')
AND (res.room_id IS NULL OR ((res.check_in >= :checkIn AND res.check_out <= :checkOut) OR (res.check_in < :checkIn AND res.check_out > :checkOut)))
AND (res.room_id IS NULL OR (res.check_out <= :checkIn OR res.check_in >= :checkOut))
AND (res.room_id IS NULL OR (res.check_out <= :checkOut OR res.check_in >= :checkOut));
""", nativeQuery = true)fetch Join을 활용해 가져온 데이터를 한번 더 fetch하는 경우는 카테시안 곱을 해결할 수 없어 런타임 단계에서 예외가 발생하게 된다. fetch Join을 사용하는 과정에서 중복 데이터가 발생하게 되는데 이를 한번더 fetch 하게 되는 경우, 데이터 매핑이 불가함이 문제라고 한다.
테이블 구조를 변경해 해결할 수도 있었지만, 시간이 많이 없었고 쿼리 상에서 해결하고 싶었다.
해결 과정에서 사용한 방법은 JPQL을 그대로 사용하기 보다는 nativeQuery를 사용해 쿼리를 벌크로 가져오는 방법을 선택했다.
default_batch_fetch_size: 1000batch size를 설정해 벌크로 쿼리를 가져올 수 있도록 하였다. 결과 데이터를 하나의 객체로 가져옴으로써 n+1 문제는 해결하였지만, 아직 JPA의 내부 동작원리 관련 개념이 많이 부족하다고 다시 한번 느낀 순간이었다. 아무래도 JPA 관련 공부를 조금 더 깊게했으면 해당 문제 해결 뿐만 아니라 쿼리 최적화 측면에서도 나은 방법이 있을 것이라고 생각했다. ( JPA 공부하자 !! )
이미지 업로드 구현
이미지를 구현하는 방법으로 AWS S3 스토리지를 활용해 이미지 관련 로직을 작성하고 관리했다.
s3를 활용한 이미지 관련 로직 구현 방식이 인기가 있다 보니까 학습할 수 있는 내용이 많았고, 러닝 커브가 낮다고 판단했다.
객실(Room) 이미지의 경우 하나의 이미지만 사용하다 보니 구현 과정에서 발생한 문제는 크게 없었지만 숙소(Accommodation)의 경우 한번에 5개의 이미지까지 저장되도록 구현해야 하다 보니 다중 이미지 업로드 방식으로 따로 구현해야 했다.
public class RoomUploader {
private final AmazonS3Client amazonS3Client;
@Value("${spring.cloud.aws.s3.bucket}")
private String bucket;
// MultipartFile을 전달받아 File로 변환한 후 S3에 업로드
public String upload(MultipartFile multipartFile, String dirName) throws IOException {
File uploadFile = convert(multipartFile)
.orElseThrow(() -> new IllegalArgumentException("MultipartFile -> File 전환 실패"));
return upload(uploadFile, dirName);
}
// 이하 생략
} public class AccommodationUploader {
private final AmazonS3Client amazonS3Client;
@Value("${spring.cloud.aws.s3.bucket}")
private String bucket;
// MultipartFile을 전달받아 File로 변환한 후 S3에 업로드
public List<String> upload(List<MultipartFile> multipartFile, String dirName) throws IOException {
List<File> uploadFiles = convert(multipartFile)
.orElseThrow(() -> new IllegalArgumentException("MultipartFile -> File 전환 실패"));
return uploadFileList(uploadFiles, dirName);
}
// 이하 생략
}
RoomUplodatr의 경우 단일 MultipartFile을 파라미터로 받고 AccommodationUploader의 경우 List로 file 데이터를 받았다. 이미지 저장을 위한 흐름은 비슷했지만 파라미터를 다르게 둔 관계로 로직을 통합하지 못했다. 조금 더 고민을 했으면 다른 패턴을 활용해서 Uploader를 추상화 할 수 있었는데 그 정도 수준까지 리팩토링을 하지 못해 조금 아쉬웠다...
배포 과정의 변화
이번 프로젝트에서 제일 만족스러웠던 건 인프라를 관리하고 개발 & 운영 환경에서의 트러블 슈팅을 A-Z까지 해결해본 경험이었다. 기본적으로 Github Actions를 기반으로 CI/CD 시나리오를 구축 하되 배포 속도, 중단점 발생 여부, 인프라 확장 가능성 등을 고려해 통합 & 배포 방식을 변경했다.
1. S3 & CodeDeploy 활용
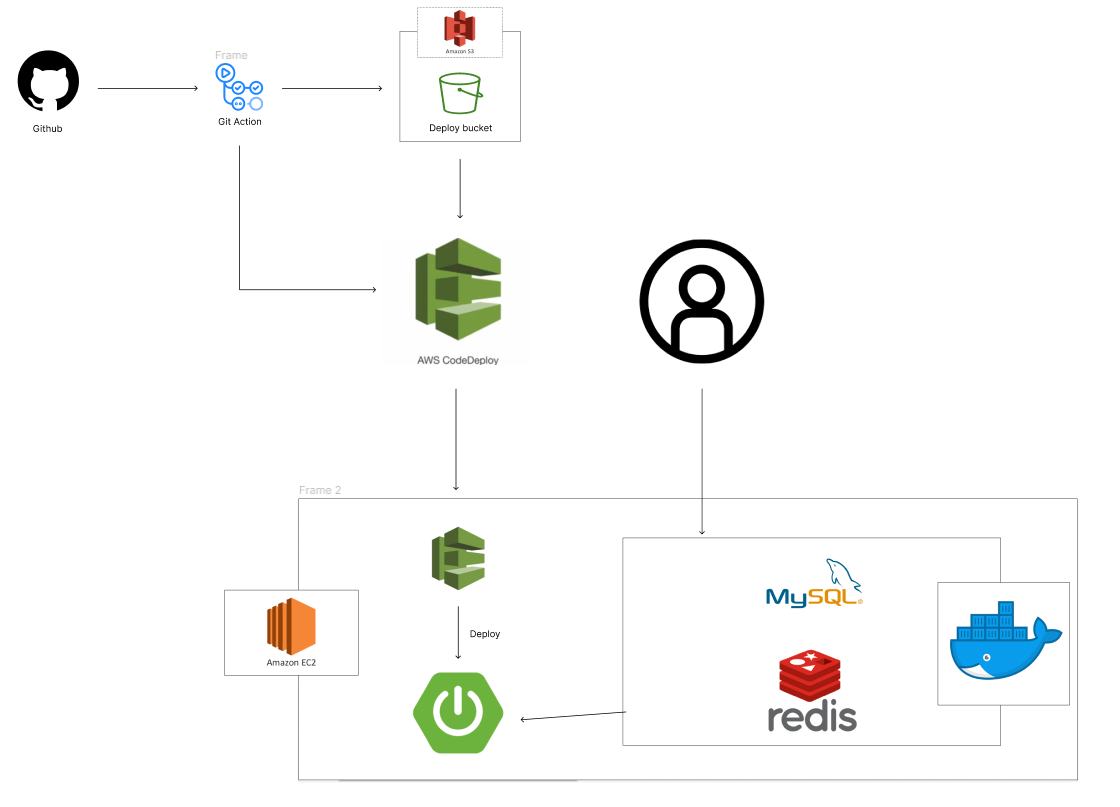
S3와 CodeDeploy를 활용한 자동 배포 방식을 채택했다. CodeDeploy의 배포 자동화 기능 및 모니터링 기능을 활용할 수 있고 appspec.yml로 손쉽게 CodeDeploy의 배포 시나리오를 작성할 수 있다는 점을 고려해 러닝 커브가 낮을 것 같아 선택했다.
하지만 배포 환경을 구축하는 과정이 생각보다 힘들었다. EC2 인스턴스가 S3 및 CodeDeploy를 사용하도록 하기 위한 IAM 설정 및 EC2에 DeployAgent를 설치하는 과정에서 Ubuntu 버전과 호환이 안되는 문제로 인해 난항을 겪었다.
그래도 환경 구축 이후에는 손쉽게 배포가 되는 것을 눈으로 확인할 수 있었고, 배포 속도 또한 빨라서 활용하기 상당히 편했다.
2. Docker 기반 CI/CD 구축
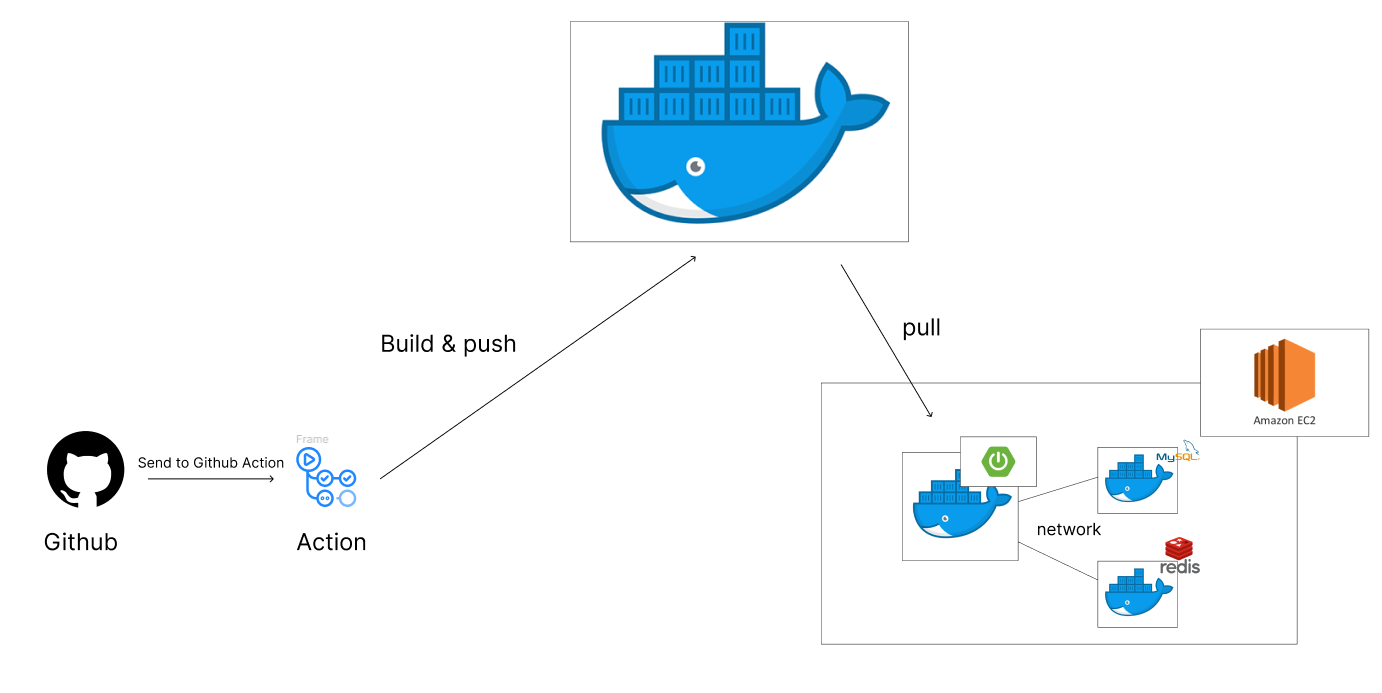
DB는 실제로 Docker를 활용해 구축한 상황이었고, 서버 규모가 커지면서 최적화의 필요성을 느꼈다. 이 과정에서 추후 인프라 확장 가능성, 개발 환경 통합 편의성 등을 고려해 기존 CodeDeploy를 사용하던 방식에서 Dockerfile을 DockerHub로 push하고 ec2 환경에서 다시 pull 하여 서버를 배포하는 방식을 사용했다.
Dockerfile을 사용하면서 스프링 부트 이미지 크기를 최적화 하고 build 소요 시간 단축을 위해 레이어 별로 빌드를 세분화 하는 방식을 선택했다.
#7 [builder 2/3] COPY ./build/libs/*.jar accommodation-backend.jar
#7 DONE 0.2s
#8 [builder 3/3] RUN java -Djarmode=layertools -jar accommodation-backend.jar extract
#8 DONE 1.0s
#9 [stage-1 2/5] COPY --from=builder ./dependencies/ ./
#9 DONE 0.2s // caching
#10 [stage-1 3/5] COPY --from=builder ./spring-boot-loader/ ./
#10 DONE 0.0s // caching
#11 [stage-1 4/5] COPY --from=builder ./snapshot-dependencies/ ./
#11 DONE 0.0s // caching
#12 [stage-1 5/5] COPY --from=builder ./application/ ./
#12 DONE 0.0s // caching
이 외에도 Gradle caching 스크립트를 작성해 빌드 최적화를 진행하며 안정적인 CI/CD를 구축하기 위한 노력을 지속했다. 하지만 서비스 규모가 커지면서 스프링부트 실행 과정에서의 중단점이 커지게 되고 이를 위한 개선 작업이 추가로 필요했다.
3. blue/green 무중단 배포를 활용한 중단점 제거
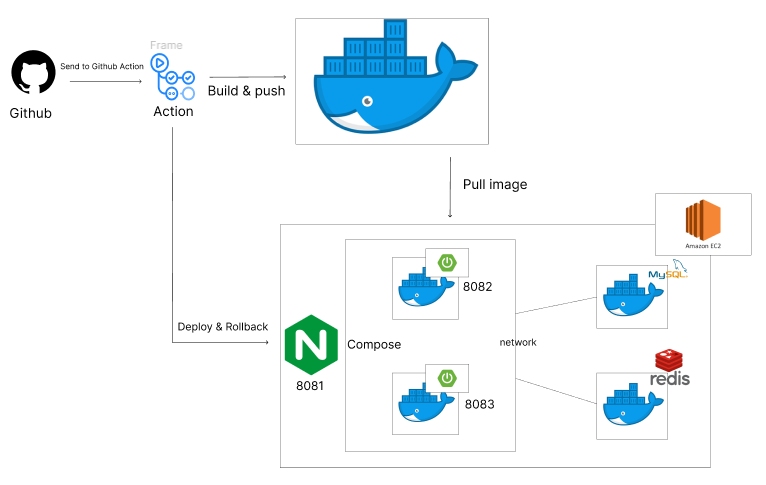
배포 완료된 스프링부트 서버 실행이 완료될 때까지 200~280초가 소요되는 기간 동안은 접속 상의 중단점이 생기는 문제가 발생하였는데 이 문제를 해결하고 업데이트 내용에 문제가 생길 경우 손쉽고 빠르게 이전 버전으로 rollback할 수 있도록 무중단 배포를 구현했다.
blue/green 배포 방식의 핵심은 2개의 서버가 올라간다는 것과 이를 통해 신버전에 문제가 생길 경우 이전 버전으로 빠르게 롤백해 문제 해결 및 복구를 원활하게 할 수 있어야 한다는 것이라고 생각한다.
운영 서버 / 업데이트 서버를 구분하기 위해 배포 시점에 nginx와 연결되어 있는 스프링부트 서버의 포트번호를 체크해 결과에 따라 동적으로 deploy & rollback이 가능하도록 스크립트를 짜야하는 부분이 상당히 어려웠다. 운영하지 않는 서버를 내려 exit 상태로 만들면 어떨지도 고민해 보았지만 nginx reroad 만으로도 바로 rollback이 가능한 상태를 유지하기 위해선 이전 서버를 살려놓는 방식을 채택했다. 하지만 인프라 비용과 서버 규모를 고려해 유동적으로 정책을 바꿀 수 있다는 생각도 들었다.
아쉬웠던 점
과연 내가 구현한 코드의 품질이 좋았을까..? 라는 질문이 온다면 나는 Yes라고 답하지 못할 것 같다. 이번 프로젝트를 진행하면서 테스트 코드 작성을 주도해 코트 품질을 높이고 안정적인 구현을 리드하고 싶었지만, 구현 과정에서 발생하는 이슈를 해결하는 과정에 시간적 비용이 생각보다 많이 투자되었고, 운영 환경의 이슈와 인프라까지 맡게 되면서 코트 품질까지 신경쓰기가 상당히 힘들었다.(물론 개인적인 변명이긴 하지만)
다음 프로젝트를 진행할 때는 인프라와 운영적인 이슈를 해결하는 것도 중요하지만 프로그램을 구현하는 개발자로서 코드상에서 문제가 발생하지 않도록 테스트 코드의 의존성을 조금 더 높여 코드 품질을 좀 더 개선해보고 싶다.
또한 개인적으로 팀원들과의 소통도 부족하다고 느꼈던 만큼 이 부분에 대해서도 적극적인 질문과 응답으로 언어 & 문서적 소통을 조금 더 활성화 해야겠다는 생각을 한다.
