
오픈 API나 크롤링을 통해 데이터를 수집한다면 어떻게 해야할까?
그냥 무작정 크롤링 하는 코드만 있으면 될까?
오픈 API나 크롤링을 통해 데이터를 수집할 때, 단순히 코드 작성만으로는 관리와 유지보수가 어려워진다. 특히 외부 요인에 대한 의존성이 크므로, 전체 프로세스를 체계적으로 관리하는 것이 중요하다. 이러한 과정을 효율적으로 관리할 수 있는 도구 중 하나가 Airflow이다.
데이터 수집을 하기 전 고려할 점이 뭐가 있을까?
1. 작업 스케줄링 및 모니터링
예를 들어, 매일 오전 9시에 주식 시장 정보를 수집하고 이를 분석해야 한다고 가정해보자. Airflow에서는 DAG 을 통해 이 작업을 정의할 수 있으며, CRON 표현식을 사용하여 9시에 주기적으로 실행되도록 스케줄링할 수 있다. 이를 통해 수동으로 작업을 실행할 필요 없이, Airflow가 정해진 시간에 작업을 자동으로 시작한다. 또한 작업이 성공적으로 완료되었는지, 지연이 발생했는지, 실패했는지를 Airflow UI에서 실시간으로 모니터링할 수 있다.
2. 지연 시간 조절이나 재시도 로직
오픈 API나 크롤링을 사용할 때 외부 서버의 응답 속도나 서버 상태에 따라 지연이 발생할 수 있다. 이러한 상황에서 재시도 로직이 없으면 수집 실패로 이어질 수 있다. 예를 들어, 외부 API를 호출할 때 종종 서버 응답이 느리거나 일시적으로 다운될 수 있다. Airflow의 retry 기능을 활용하여 작업이 실패하면 일정 횟수만큼 재시도하도록 설정할 수 있다.
3. 에러 발생 시 처리 방안
데이터 수집 중 에러가 발생할 경우 이를 어떻게 처리할지에 대한 방안을 미리 설계해 두는 것이 중요하다. Airflow에서는 작업 실패 시 에러 핸들링을 설정하여, 실패한 작업을 기록하고 해당 데이터를 관리하는 담당자에게 Slack 또는 이메일 알림을 보낼 수 있다.
4. 수집된 데이터를 처리하고 저장하는 단계
데이터 수집이 완료되면, 이를 적절히 처리하여 저장하는 단계가 필요하다. 이 과정에서 데이터 전처리, 변환, 저장 등의 작업을 체계적으로 관리할 수 있어야 한다. Airflow의 DAG을 통해 이러한 작업 순서를 정의하고 자동으로 실행할 수 있으며, 각 단계가 성공적으로 완료되었는지 확인할 수 있다. 또한, 수집된 데이터를 저장할 때는 데이터 무결성 및 중복성을 고려해야 하며, Airflow를 사용하면 중복된 데이터 처리를 방지하는 로직도 포함시킬 수 있다.
기본 DAG
현재 나는 Open API로 여러 패키지의 메타데이터를 수집하고 있다.
여러 API로 수집을 하다보니 세부적인 내용은 조금씩 다르지만, 대략적인 구조는 다음과 같다.

- 전체 패키지 이름 목록 수집
- 패키지 메타데이터 API 요청 → 데이터 적재
앞서 말했듯 API로 데이터를 수집한다. 무지성으로 모든 데이터를 수집할 때까지 URL 리스트를 돌면서 요청을 보낸다면 굉장히 느릴 것이다.
동기 vs 비동기
이유는 동기로 처리하기 때문인데 요청의 응답이 와야만 다음 요청으로 넘어간다. 그럼 어떻게 하면 될까? 비동기로 요청하면 된다. 비동기 처리하게 된다면 요청을 보내고 응답이 올 때까지 기다리지 않아도 된다. 요청을 보내고 다른 일을 하면 된다.
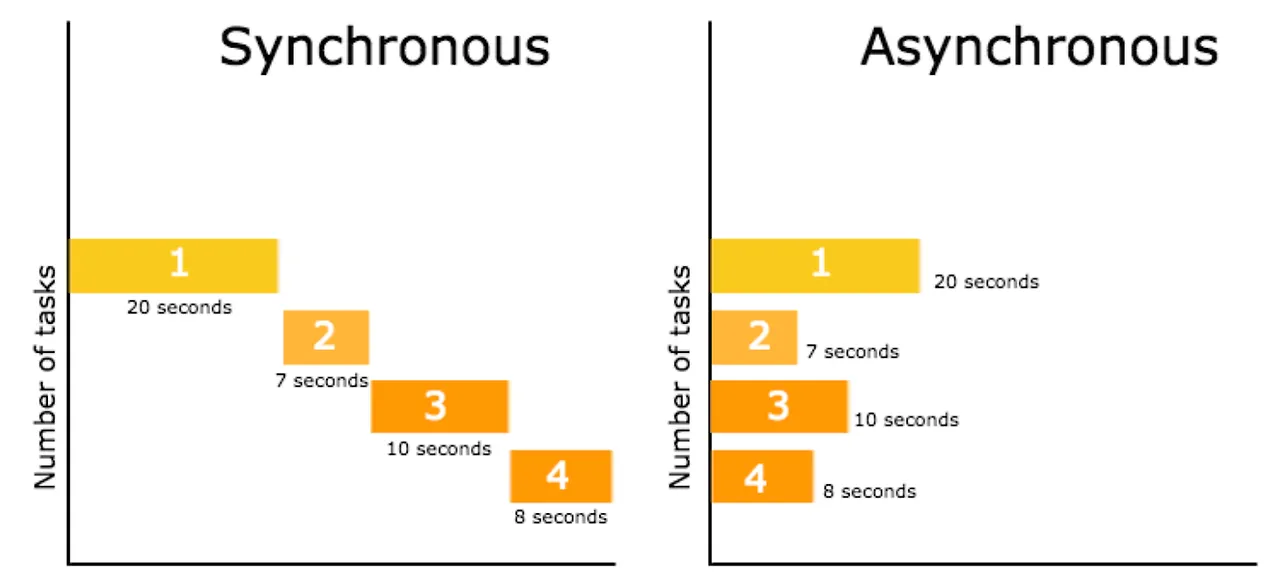
동기 처리에서는 각 요청이 완료될 때까지 기다리기 때문에 전체 시간이 오래 걸릴 수 있다. 반면 비동기 처리에서는 요청을 보내고 응답을 기다리는 동안 다른 요청을 처리할 수 있어 병목을 줄일 수 있다.
그럼 멀티스레딩은요?
동시성 vs 병렬성
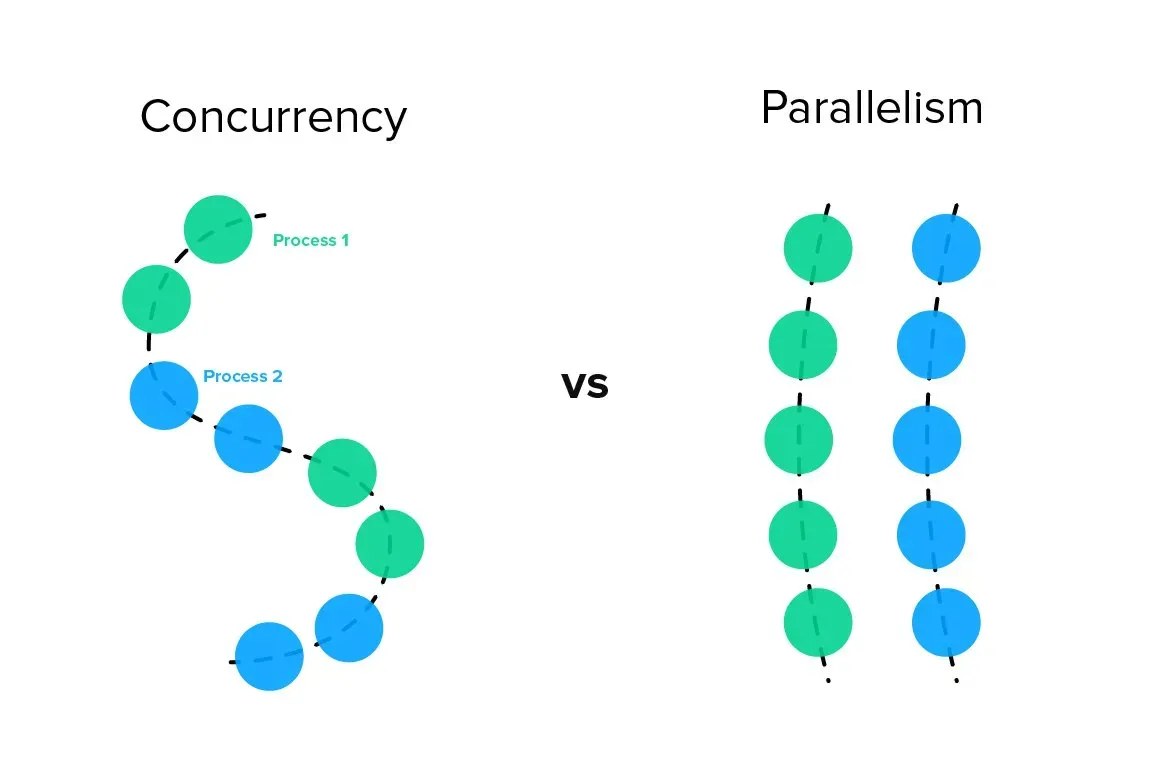
파이썬의 GIL 때문에 멀티스레딩은 제한적이다. GIL은 한 번에 하나의 스레드만 실행되게 하기 때문에 멀티스레딩을 통해 얻을 수 있는 성능 향상이 제한된다. 그리고 외부 API의 의존도가 높은 작업이다. 결국 병렬성보단 동시성을 활용하는 것이 중요해진다. 멀티스레딩 대신 멀티프로세싱을 사용할 수도 있지만, 이는 프로세스 간 통신 비용이 크고, 메모리 사용량이 많아져 API 요청과 같은 네트워크 I/O에 적합하지 않을 수 있다.
비동기로 동시성을 활용하려면 추가로 고민해야하는 사항이 있다. 바로 논블로킹과 블로킹이다. 비동기 논블로킹 방식은 요청을 보내고, 응답을 기다리는 동안 다른 작업을 처리할 수 있게 하여 시스템 자원을 더 효율적으로 사용한다. 예를 들어, 웹 요청을 보낸 후 응답을 기다리는 동안 다른 요청을 보낼 수 있어 전체 처리 시간이 단축된다. 그렇기 때문에 비동기 논블로킹 방식으로 구현하고자 한다.
비동기 코루틴
현재 파이썬을 활용해 개발할 예정이기 때문에 asyncio 라이브러리를 활용할 것이다.
asyncio는 코루틴을 통해 함수가 특정 지점에서 대기할 때 다른 작업을 진행할 수 있게 하여, 주로 I/O-bound 작업에서 유용하다. 예를 들어, 많은 API 호출이 필요한 경우 asyncio를 통해 모든 호출을 병렬로 실행함으로써 효율성을 극대화할 수 있다.
활용한 예시 코드
# package_names은 다른 API를 통해 가져온 후, 다음 Task
@task()
def task_1(package_names: list[str]):
async def run_async_task():
async with aiohttp.ClientSession() as session:
await fetch_pypi_metadata(session, package_names)
asyncio.run(run_async_task())
async def collect_metadata(session: aiohttp.ClientSession, package_names: list[str]) -> None:
...
tasks = []
for name in package_names:
task = asyncio.create_task(store_metadata(session, db_handler, name))
tasks.append(task)
await asyncio.sleep(0.05)
await asyncio.gather(*tasks)이 코드에서 중요한 포인트 2가지가 있다.
-
asyncio.sleep()다들
time.sleep()은 많이 사용해보셨을 것이다. 잠시 작업을 대기하기 위해서 많이들 사용한다. 하지만, 비동기 작업에서time.sleep()를 사용한다면 어떻게 될까? 비동기 블로킹이 된다.현재 작업은 주로 I/O 바운드가 매우 높은 작업이므로 블로킹이 된다면 동기 방식과 차이를 느낄 수가 없을 것이다.asyncio.sleep()은 이벤트 루프를 차단하지 않으면서 대기할 수 있으므로, 해당 시간 동안 다른 코루틴이 실행될 수 있도록 한다. 따라서, 비동기 논블로킹을 사용하기 위해서는asyncio.sleep()를 활용해야 한다. -
세션 재활용
세션을 요청마다 생성한다면 너무 많은 세션으로 인해 Task의 성능이 저하될 수 있다. 따라서, 세션을 처음 시작할 때 생성하고 이를 재활용할 수 있도록 개발했다.
세마포어 방식
async def collect_metadata(session: aiohttp.ClientSession, package_names: list[str]) -> None:
...
tasks = []
for name in package_names:
task = asyncio.create_task(store_metadata(session, db_handler, name))
tasks.append(task)
await asyncio.sleep(0.05)
await asyncio.gather(*tasks)기존 코드에서는 await asyncio.sleep(0.05)를 사용하여 각 요청 사이에 대기 시간을 두어 동시에 너무 많은 API 요청을 보내는 것을 피하도록 설계되었다. 그러나 네트워크 문제로 인해 응답이 늦어질 경우, 이러한 방식은 일관성이 떨어지며, 비효율적인 대기 시간이 발생할 수 있다.
이를 개선하기 위해, 세마포어 방식을 도입하여 동시에 처리할 수 있는 API 요청의 수를 제한하였다. 이 방식은 네트워크의 상태에 따라 유동적으로 동작하며, 특정한 수 이상의 요청이 동시에 처리되지 않도록 제어함으로써 API 서버에 과부하를 주는 것을 방지하고 안정적인 수집 작업을 유지할 수 있다.
async def collect_metadata(session: aiohttp.ClientSession, package_names: list[str]) -> None:
...
semaphore = asyncio.Semaphore(15)
tasks = []
for name in package_names:
task = asyncio.create_task(store_metadata(session, db_handler, name, semaphore))
tasks.append(task)
await asyncio.gather(*tasks)
...
async def store_metadata(session: aiohttp.ClientSession, db_handler: PyPiDatabaseHandler, name: str, semaphore: asyncio.Semaphore) -> None:
async with semaphore:
...기존 코드에서 await asyncio.sleep(0.05)로 각 요청 사이의 대기 시간을 설정하면, 실제로 응답을 기다리는 동안에도 시스템 자원이 점유될 수밖에 없다. 이는 대기 시간 동안에도 비효율적인 리소스 사용이 발생하며, 특히 응답이 지연되는 상황에서는 불필요하게 많은 리소스를 소비하게 된다.
반면, 세마포어 방식을 도입하면 동시에 처리할 수 있는 요청의 수를 아예 제한함으로써, 불필요하게 많은 리소스를 점유하는 상황을 방지할 수 있다. 세마포어는 동시 요청 횟수를 제어하고 조율하여 필요 이상의 요청이 일어나지 않게 하며, 요청이 응답을 기다리는 동안에도 시스템 리소스를 더 적게 소비할 수 있도록 돕는다. 이는 결국 전체 시스템에서 사용되는 메모리와 CPU 리소스를 효율적으로 관리할 수 있다.
데이터 적재는 어떻게 하면 될까?
현재 데이터는 PostgresSQL에 적재하고 있다. 하지만 데이터 수집 특성상 대량의 데이터를 적재해야 한다. 이를 레코드 하나씩 적재한다고 하면 I/O 작업이 많이 생기게 된다. 그래서 이를 벌크로 한번에 처리해야 한다고 생각했다.
from psycopg2.extras import execute_values
from airflow.providers.postgres.hooks.postgres import PostgresHook
class DatabaseHandler:
def __init__(self, postgres_conn_id) -> None:
self.hook = PostgresHook(postgres_conn_id=postgres_conn_id)
self.connection = self.hook.get_conn()
self.cursor = self.connection.cursor()
...
def bulk_insert_data(self, insert_sql: str, data: list[tuple]) -> None:
try:
execute_values(self.cursor, insert_sql, data)
self.connection.commit()
except Exception as e:
self.logger.error(f"Failed to bulk insert data: {e}")
self.connection.rollback()
...공통 데이터베이스 핸들러를 두고 상속 받아 활용할 수 있도록 구현했다.
API 요청 후 응답이 제대로 오지 않는다면 어떻게 해야할까?
재시도 로직을 구현할 수 있다. 그럼 재시도 간격은 어떻게 해야할까? 재시도의 재시도가 실패한다면 어떻게 해야할까? 이를 해결하기 위해 지수 백오프 전략을 활용할 수 있다.
async def handle_with_retries(url, session, retries=3):
for attempt in range(retries):
try:
async with session.get(url) as response:
return await response.text()
except Exception as e:
if attempt < retries - 1:
await asyncio.sleep(2 ** attempt)
...지수 백오프 전략은 네트워크 장애나 일시적인 서버 문제 등에서 API 호출을 반복할 때 유용하다. 위 코드에서 await asyncio.sleep(2 ** attempt)은 재시도 간격을 점점 늘려가는 부분이다. 처음 실패 시 2초, 다음에는 4초, 그 다음엔 8초 후 재시도하는 방식이다. 이를 통해 서버에 대한 과부하를 줄이고 성공 가능성을 높일 수 있다.
하지만 재시도 횟수를 무한정 늘리면 클라이언트도 무기한 대기하게 될 수 있기 때문에 retries 매개변수로 재시도 횟수를 제한하는 것이 중요하다. 또한, 실패하는 요청에 대해 적절한 로그를 남기거나, 최종 실패 시 예외를 발생시켜 에러 처리가 가능한 상태로 만드는 것이 바람직하다.
따라서 상태를 관리할 수 있는 테이블을 만들어서 관리하고자 했다. HTTP 상태코드를 해당 라이브러리의 버전과 이름과 함께 저장하여 HTTP 상태 코드에 맞춰 추후 재수집 시 대응할 수 있도록 구현하였다.
메타데이터가 업데이트되면 어떻게 하나요?
메타데이터가 업데이트되었는지 확인할 때, API에서 직접 변경 여부를 알 수 있는 정보, 예를 들어 "last_updated" 같은 필드를 제공해주면 가장 간단하게 해결할 수 있다. 그러나 현실적으로 모든 API가 그런 정보를 제공하지는 않는다. 그래서 우리는 업데이트를 관리할 수 있는 자체적인 방법을 마련해야 한다.
앞서 언급한 것처럼, 상태를 관리하는 테이블에 각 레코드의 해시 값을 저장하는 방식을 사용할 수 있다. 이 방식의 장점은 매번 레코드의 모든 칼럼을 하나씩 비교할 필요 없이, 해시 값만 비교하면 변경 여부를 쉽게 확인할 수 있다는 점이다. 즉, 기존 데이터와 새로운 데이터를 각각 해시하고, 그 값이 다르면 업데이트된 것으로 판단하는 것이다.
물론, API가 이러한 메타데이터 업데이트 여부를 제공해주면 좋겠지만, 그렇지 않은 경우에도 이 해시 비교 방식은 효율적이고 유용한 대안이 될 수 있다. 데이터를 비교할 때 일일이 각 필드를 체크하는 것보다 해시 비교는 성능 면에서 훨씬 유리하고, 변경 감지 로직도 간결하게 유지할 수 있다.
해싱 데이터는 Unique할텐데 중복되면 어떻게 하나요?
해싱 데이터가 유니크하다고 가정하지만, 실제로 같은 메타데이터를 가진 URL이 여러 번 존재할 수 있다. 이럴 때 중복된 데이터를 처리하는 가장 좋은 방법은 무엇일까?
처음에는 중복 제거를 위해 각 데이터를 하나하나 비교하고, 이를 분산 처리를 통해 효율적으로 해결하려는 방법도 고려했었다. 하지만 이런 방식은 복잡하고, 시간이 많이 소요될 수 있다. 이를 대신해 더 간단하고 효율적인 접근법이 Upsert 쿼리다.
Upsert 쿼리를 사용하면 데이터베이스에 동일한 해시 값이 있는 경우 업데이트하고, 없으면 새로운 데이터를 삽입할 수 있다. 이를 통해 중복 데이터 처리를 자동화하고, 코드 복잡도를 줄일 수 있다. 이러한 방식은 중복 확인과 처리를 데이터베이스 레벨에서 해결하기 때문에, 추가적인 분산 처리나 복잡한 중복 제거 로직을 구현하지 않아도 된다. 즉, Upsert를 사용하면 중복 데이터 처리는 데이터베이스가 담당하게 되어 개발자는 더 중요한 로직에 집중할 수 있다.
DAG 작성
task를 개발하기 전에 먼저 어떤 환경에서 Airflow를 활용할 지 생각해야한다.
현재 로컬에선 도커 환경에서 테스트 진행 중이고 추후에 EKS 환경에 배포할 예정이다.
따라서, 어떤 Executor를 활용하면 좋을 지 생각해보자.
Executor
Executor는 Airflow에서 Task를 어떻게 실행할지 결정하는 구성 요소이다. 간단히 말해, DAG에서 정의한 각 Task를 어떤 방식으로, 어떤 환경에서 실행할지 정해주는 역할을 한다.
1. SequentialExecutor
모든 Task를 순차적으로 한 번에 하나씩 실행합니다. 즉, 동시에 여러 Task를 실행하지 않는다. 주로 테스트 환경에서 사용되며, 작업이 병렬로 실행될 필요가 없거나 작업량이 매우 적은 경우에 적합하다. 분산 환경에서는 사용이 불가능하며, 오직 단일 프로세스에서만 작동한다. 따라서 성능이 제한적이고, 실제 운영 환경에는 적합하지 않다.
2. LocalExecutor
Airflow를 설치한 단일 호스트 내에서 Task를 병렬로 실행할 수 있다. 여러 개의 Worker 프로세스를 사용해 동시에 여러 Task를 실행한다. 로컬에서 빠르게 개발을 하거나, 모든 Task가 한 머신에서 실행해도 충분할 때 유용하다. 분산 환경에서는 사용이 불가능하며, 한 머신에만 의존하기 때문에 확장성 면에서 제한이 있다. 즉, 리소스 확장이 필요하거나 대규모 분산 처리가 필요한 환경에서는 적합하지 않다.
3. CeleryExecutor
분산 환경에서의 Task 실행을 지원한다. 여러 Worker 노드를 사용해 Task를 동시에 실행하며, Celery를 사용해 Task의 분배와 관리를 수행한다. 멀티 호스트 환경에서 확장 가능한 분산 처리가 필요한 경우 적합하다. 대규모 워크로드를 처리할 수 있으며, 노드가 여러 대일 경우 쉽게 추가해서 확장할 수 있다. 확장성이 뛰어나고, Celery를 통해 Worker들을 효율적으로 관리할 수 있다. 하지만, 설정이 비교적 복잡하며, RabbitMQ나 Redis와 같은 메시지 브로커를 필요로 한다. 따라서 인프라 관리가 좀 더 복잡해질 수 있다.
4. KubernetesExecutor
Kubernetes 기반의 클러스터에서 Task를 실행한다. 각 Task가 독립적인 Kubernetes Pod로 실행되어 격리된 환경에서 구동된다. 쿠버네티스 클러스터에서 Airflow를 사용하여 확장성 있고 격리된 환경을 제공할 때 적합하다. Task마다 개별 Pod가 생성되므로 리소스 관리가 용이하고, 대규모 클러스터에서 유연하게 확장할 수 있다. 분산 환경에서 사용 가능하지만, 다른 Executor처럼 일반적인 멀티 호스트 방식으로 동작하는 것이 아니라 쿠버네티스 인프라를 기반으로 한다. 따라서, KubernetesExecutor는 쿠버네티스 환경에서만 작동하며, 이를 위해 쿠버네티스 클러스터가 필요하다.
이미 쿠버네티스 환경이 구축되어 있고 대규모 데이터를 병렬로 수집하고 적재하는 작업은 각 Task가 서로 독립적으로 실행될 수 있기 때문에 KubernetesExecutor가 적합하다고 생각했다. 각 Task가 개별적인 Kubernetes Pod로 실행되기 때문에 작업 간에 격리된 환경에서 실행되고, 리소스 할당이 유연하게 가능하다. 따라서, KubernetesExecutor를 사용하고 로컬로 테스트할 땐 도커 환경에서 작업할 예정이므로 LocalExecutor를 활용해서 작업하도록 결정했다.
병렬 Task 처리하기
전체 패키지 목록을 수집하고 적게는 수만개, 많게는 수백만개 있는 URL를 하나의 Task로 처리한다면 시간이 무진장 오래 걸릴 것이다. 그래서 생각한 것은 리스트를 쪼개어 병렬로 실행시키자 였다.
코드단에서 병렬로 돌릴 Task의 수를 간단하게 관리하고 싶었다.
그래서 거대한 리스트를 나눌 수 있는 나름의 알고리즘을 작성했다.
def split_into_chunks(data, num_chunks) -> List[List[str]]:
chunk_size = len(data) // num_chunks
remainder = len(data) % num_chunks # 나머지
return [
data[i * chunk_size + min(i, remainder): (i + 1) * chunk_size + min(i + 1, remainder)]
for i in range(num_chunks)
]등분이 딱 떨어지지 않을 것을 대비하여 remainder 변수를 활용하여 나머지를 처리해줬다.
이 리스트를 돌면서 DRY(Don't Repeat Yourself) 한 Task를 만들 수도 있지만 Airflow2의 기능을 활용한다면 훨씬 간편하게 구현 가능하다.
@task
def split_urls(urls: list[str], parallel_tasks: int):
return split_into_chunks(urls, parallel_tasks)
split_urls_list = split_urls(package_info_urls, 2)
metadata_collection = metadata_collector.expand(urls=split_urls_list)이렇게 병렬로 처리할 갯수만 입력해주고 리스트를 2차원 리스트로 나눈다면 Airflow 2.3.0 부터 지원한 기능인 TaskFlow API의 expand 활용하여 쉽게 병렬로 처리할 수 있다.
expand()는 여러 인자를 입력으로 받아 다수의 Task 인스턴스를 생성하며, 작업을 매핑하여 각각 다른 파라미터로 실행할 수 있게 한다.
TaskFlow API의 expand 주요 개념
Dynamic Task Mapping: expand()는 동적 Task 매핑 기능을 제공한다. 이는 동일한 Task를 여러 인자로 실행하는 과정에서 유연하게 사용할 수 있다. 예를 들어, 데이터 파이프라인에서 여러 파일을 동시에 처리하거나 여러 API 호출을 병렬로 진행할 때 매우 유용하다.
Dynamic Expansion: 각 인자 값에 대해 별도의 Task 인스턴스를 생성한다. 예를 들어, 위의 예제에서는 총 3개의 Task 인스턴스가 각각 "data1", "data2", "data3" 값을 처리하도록 만들어진다.
DAG 실행 관리
현재 계획은 한 DAG가 하루에 한번 실행하도록 할 예정이다.
하지만, 수집할 데이터량이 워낙 많고 해당 API의 rate limit까지 지키다보니 하루를 넘기는 경우가 종종 있다. 거기에 네트워크 사정에 따라(개발자가 침범할 수 없는 영역) 매일 다르게 마치다보니 고민이 많았다.
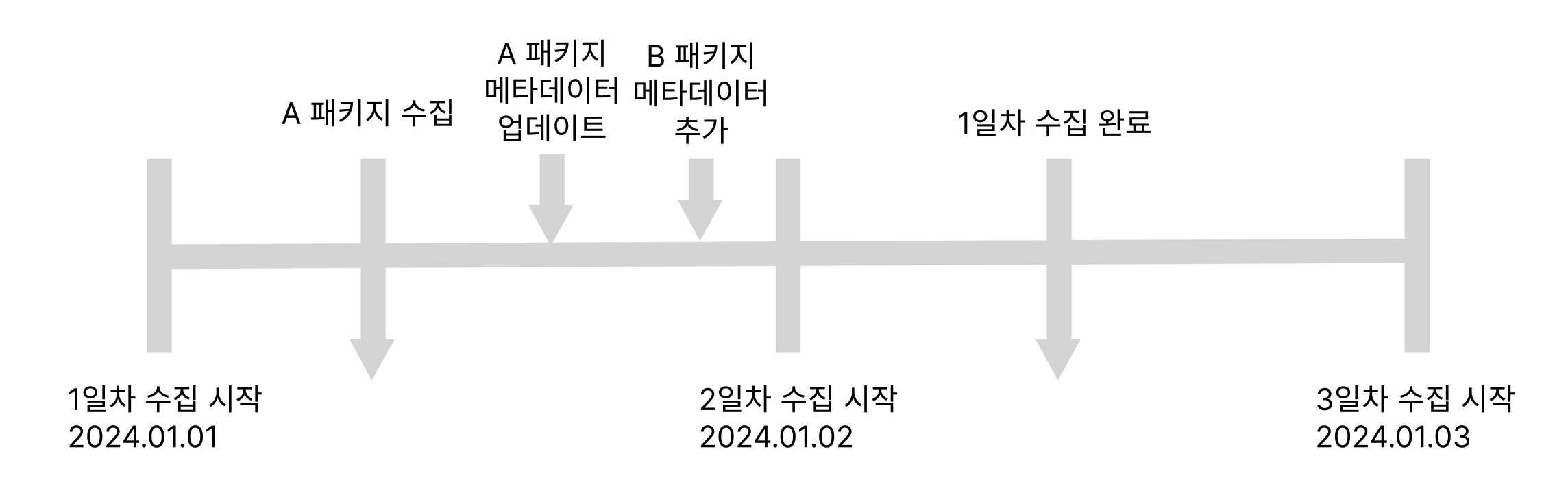
예를 들어 설명하자면, 데이터 수집이 2024.01.01 ~ 2024.01.02 이 걸렸다고 가정하자.
수집 시작 일자를 기준으로 하루에 한번씩 DAG가 실행되기 때문에 A 패키지 수집이 되고나서 A 패키지 메타데이터 업데이트된 내용은 무시하게 된다. 왜냐하면 이미 A 패키지 내용은 수집했기 때문이다. 또한, 추가된 B 패키지 메타데이터 정보는 알 수가 없다. 이미 수집을 시작할 때 전체 패키지 이름을 가지고 URL을 생성했기 때문이다. 거기에 아직 1일차 수집 시작이 마무리되지 않았음에도 2일차 수집을 시작하면서 데이터 수집 간 중복이나 누락 문제가 발생할 가능성이 생긴다.
이는 데이터를 정확히 동기화하는 데 어려움이 발생하고, 중복된 패키지 메타데이터가 저장되거나 반대로 최신의 데이터를 놓칠 수 있는 상황을 만든다. 이러한 방식은 결국 수집된 데이터의 일관성과 정확성을 해치게 되고, 수집된 데이터를 분석하거나 활용하는 데 있어 신뢰성을 저하시킬 위험이 있다.
어떻게 하면 데이터의 일관성과 정확성을 해치지 않고 안정적으로 데이터를 수집할 수 있을까?
DAG를 관리하는 DB 테이블을 두기로 결정했다.
수집을 시작할 때는 DAG의 실행 정보를 포함하여 데이터를 데이터베이스에 기록하고, 이와 함께 XCom에 해당 기록의 고유 ID를 저장한다. 이렇게 함으로써 이후의 수집 과정에서 이 ID를 쉽게 참조할 수 있게 된다. 수집이 성공적으로 완료되면, 종료 시간을 기록하기 위해 XCom에 저장된 데이터 ID를 사용해 데이터베이스를 업데이트한다. 반면, 수집 중 Task가 하나라도 실패할 경우에는 실패 메시지와 함께 동일한 ID를 이용해 해당 수집의 상태를 '실패'로 업데이트한다.
@task(trigger_rule=TriggerRule.NONE_FAILED)
def finish_succeed_task(**context):
save_finish_datetime(..., **context)
@task(trigger_rule=TriggerRule.ONE_FAILED)
def finish_failed_task(**context):
save_failed_finish_datetime(..., **context)@task 데코레이터를 사용해 TriggerRule을 설정하여 수집이 성공한 경우와 실패한 경우를 명확히 구분하고 각각의 상태에 맞는 후처리를 할 수 있게 하였다. 수집이 성공했을 경우에는 finish_succeed_task에서 수집 종료 시간을 업데이트하고, 만약 수집이 실패했을 경우 finish_failed_task에서 해당 실패 이유와 함께 종료 시간을 기록한다.
첫 수집 / 재수집 / 전체 작업 스킵
데이터 수집 프로세스를 효율적으로 관리하기 위해, 수집 작업의 상태에 따라 분기하는 로직을 도입했다. 이 로직은 Airflow의 BranchPythonOperator를 활용하여 '첫 수집', '재수집', 그리고 '전체 작업 스킵'의 세 가지 시나리오로 작업을 분기한다.
def branch_collection_status(**context):
status = get_collection_status(..., **context)
if status == "first":
return "package_name_collector"
if status == "recollection":
return "package_name_refresh"
if status == "skip":
return "continue_task"
branching = BranchPythonOperator(
task_id="branch_collection_status",
python_callable=branch_collection_status
)첫 수집
처음 데이터 수집을 수행할 때, 데이터베이스에 해당 저장소의 수집 기록이 없다면 이를 첫 수집으로 간주한다. 이 경우, 새로운 데이터 수집 작업이 시작되며 수집 상태를 기록하기 위해 데이터베이스에 정보를 저장한다. 수집 시작 시점의 날짜 및 시간도 함께 기록하여 이후 재수집 또는 데이터 갱신에 참조할 수 있도록 했다.
재수집
이전에 수행한 수집 작업이 정상적으로 완료되었고 새로운 데이터 갱신이 필요할 때, 수집 상태는 '재수집'으로 설정된다. 이 경우, 이전 수집 완료 날짜를 참조하여 이후 변경된 데이터를 수집하거나 최신 상태로 업데이트할 수 있도록 한다. 재수집 작업 시에는 데이터베이스에 새로운 수집 기록을 추가하여, 해당 작업이 재수집임을 명시하고 이후 수집 히스토리를 관리한다.
전체 작업 스킵
특정 상황에서는 데이터 수집 작업 자체를 스킵해야 할 필요가 있다. 예를 들어, 이전 작업이 아직 완료되지 않았거나 실패로 인해 종료되지 않은 경우, 동일한 데이터를 중복하여 수집하지 않도록 현재의 Task를 스킵해야한다.
최종 DAG

느낀점
API로 데이터를 수집한다고만 생각했을 때는 단순히 구현만 하면 된다고 생각했다. 하지만, 실제로 API 응답은 내 마음대로 되지 않았고, 외부 서비스에 대한 높은 의존성 때문에 내가 통제할 수 없는 상황이 많아 예상보다 어렵게 느껴졌다. 이러한 한계를 경험하면서, 처음부터 완벽하게 구현하려고 하기보다는 하나씩 데이터를 정합성 있게 수집하고, 점진적으로 업그레이드하는 과정이 더 중요하다는 것을 깨달았다. 이 과정이 때로는 복잡하고 도전적이었지만, 그만큼 많은 것을 배울 수 있어서 재미있었다.
특히, 데이터량이 많아질수록 이 블로그에 다 담지 못한 어려움도 많았다. 그럼에도 불구하고 완벽하지는 않더라도, 더 좋은 DAG를 만들기 위해 지속적으로 개선하려 노력했다. 이러한 발전을 경험하며, 내가 만든 수집 시스템이 조금씩 더 나아지는 것을 보면서 뿌듯함을 느꼈다. 앞으로도 데이터의 정확성과 일관성을 유지하면서 안정적인 수집 파이프라인을 만드는 데 집중하며, 계속해서 성장해 나가고 싶다.
