react란?
1. front-end 개발을 위한 JavaScript 오픈 소스 라이브러리. 동적 웹 구축에 사용됨
동적 웹이란 사용자의 요청을 반영하여 보여주는 웹 페이지다. 대표적으로 SNS, 마켓 플랫폼들이 있다.
인스타그램의 좋아요 버튼을 누르면 좋아요 갯수가 바뀌어 표시되듯이 동적 웹 페이지는 사용자와 서버가 상호작용할 수 있다.
정적 웹페이지는 서버에 저장된 내용을 사용자가 읽기 밖에 못하는 페이지다. 버튼을 통한 사용자 요청 반영이 없는 페이지라고 할 수 있다.
기업들의 홈페이지가 대표적일 수 있다.
기업들의 홈페이지는 기업의 사업을 소개하는 페이지가 주로 구성되어있고 방문자와 상호작용하는 기능들은 없는 경우가 대부분이다.
2. 3가지 특징이 있다
a. 선언형 -
JSX을 활용하여 HTML과 JS를 넘나들며 작업을 해야했던 불편함을 해소하고 하나의 파일에 직관적인 코드 작성을 진행할 수 있다.

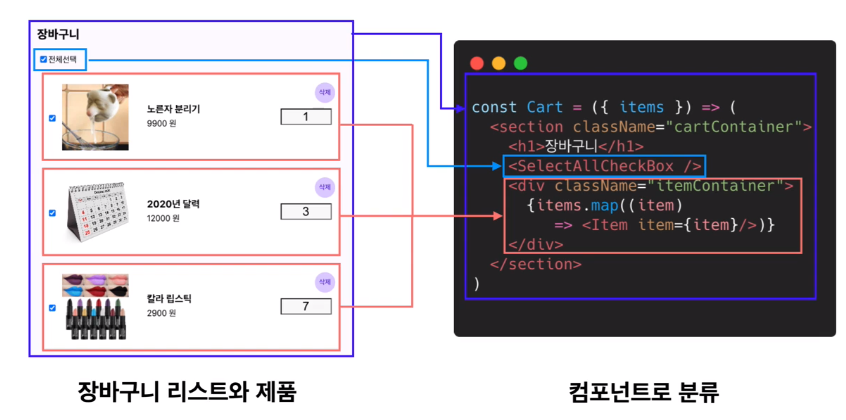
b. 컴포넌트 기반 -
컴포넌트란 하나의 기능 구현을 위해 여러 코드를 묶어놓은 것을 의미하며 컴포넌트별로 코드를 작성하면 서로 독립적으로 기능하고 재사용이 가능한 이점이 있다
c. 범용성 -
리액트는 meta( (구) facebook ) 의 주도하에 관리되는 라이브러리로 여러 라이브러리와 호환되어 사용할 수 있다. 리액트 네이티브로는 모바일 개발도 가능하다

JSX 규칙






React SPA란?
SPA : Single Page Application
서버로부터 페이지를 넘겨받을 때 완전한 새 페이지를 넘겨받는 것이 아니라 업데이트가 되는 부분만 서버로부터 전달받고 JavaScript로 HTML 요소를 생성해서 화면에 보여주는 방식
Youtube, Facebook, Airbnb, Netflix 등에서 사용 중이다.
우리가 많이 사용하는 SNS를 예로 들면
친구가 올린 사진에 "좋아요"를 누르고, 댓글을 달고, 궁금할 땐 검색을 한다.
이렇게 애플리케이션과 사용자 사이에 수시로 상호작용이 발생하는데, 이때 페이지 전체를 렌더링하는 것이 아니라 필요한 부분만 업데이트하기 때문에 SPA는 사용자의 행동에 빠르게 반응한다.
서버 입장에서는 요청받은 데이터만 넘겨주면 되기 때문에 과거와 같은 과부하 문제도 현저히 줄일 수 있다.
하지만 단점도 있다.
브라우저는 첫 화면 로딩 시에 HTML 파일을 읽어들인 후 그 안의 script tag 안에 있는 JavaScript 파일을 다시 받아오는 과정을 거치는데
이때 첫 화면 로딩 시 읽어들인 HTML 파일은 거의 비어있고, 대부분의 코드는 JavaScript 파일 안에 들어있다 보니 자연스럽게 JavaScript 파일이 무거워진다.
때문에 이 JavaScript 파일을 기다리는 시간으로 인해 첫 화면의 로딩 시간이 길어진다.
검색 엔진 최적화가 좋지 않다. 검색엔진 최적화란 구글이나 네이버 같은 검색엔진이 자료를 수집하기 좋도록 웹 페이지를 구성하는 것을 뜻한다.
여기서 검색 엔진의 작동 방식을 잠깐 알아보면, 검색 로봇이 웹 페이지에 있는 정보를 수집하고 분석해서 그 결과값에 인덱스를 만들어 보관하고 있다가 사용자가 검색어를 입력하면 보관하고 있던 인덱스에서 검색어와 가장 연관성이 높은 웹 페이지들을 순서대로 보여주는 방식으로 작동한다.
검색 로봇은 자료를 수집할 때에 웹 페이지의 URL은 물론이고 HTML 문서 내의 각종 태그나 링크 등을 분석한다. SPA는 HTML이 거의 비어있다 보니 검색 로봇이 충분한 자료를 수집하지 못한다.
이 때문에 검색 노출이 중요한 웹 애플리케이션은 검색 엔진 최적화에 대한 대응책을 따로 마련해야 하고, 더불어 앱 안에서 브라우저의 앞으로 가기/뒤로 가기 등의 상태 관리도 해야 하기 때문에 개발의 복잡도가 더욱 늘어난다.
다만 SPA에서도 검색 엔진 최적화에 대응할 수 있도록 검색 엔진이 발전하고 있어서, 점차 이 단점은 사라지고 있는 추세이다.
Routing
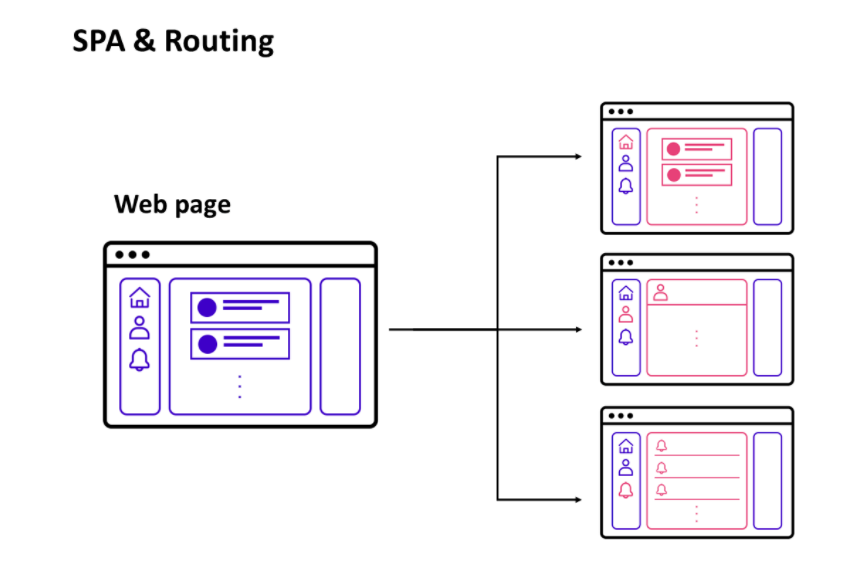
SPA는 하나의 페이지를 가지고 있다 하지만 사실은 여러개의 페이지와 연결되는 링크를 가지고 있다.
링크를 구현하기 위해 Routing을 적용시켜야 하고 React Router라는 라이브러리를 활용할 수 있다.
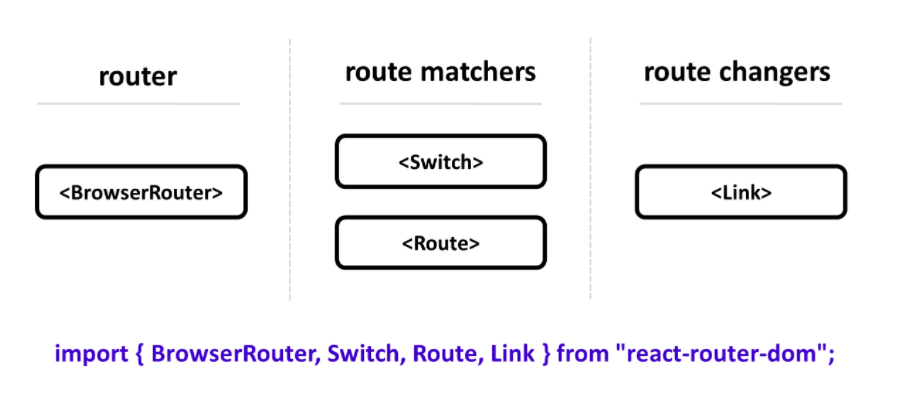
React Router의 주요 컴포넌트는 크게 3가지로 나눌 수 있다. 라우터 역할을 하는 BrowserRouter, 경로를 매칭해주는 Switch 와 Route, 그리고 경로를 변경하는 역할을 하는 Link가 있다. 이들을 사용하기 위해선 문서(JS) 상단에서 라이브러리를 import 해와야 한다.
1. BrowserRouter --
<BrowserRouter>는 웹 애플리케이션에서 HTML5의 History API를 사용해 페이지를 새로고침하지 않고도 주소를 변경할 수 있는 역할 수행
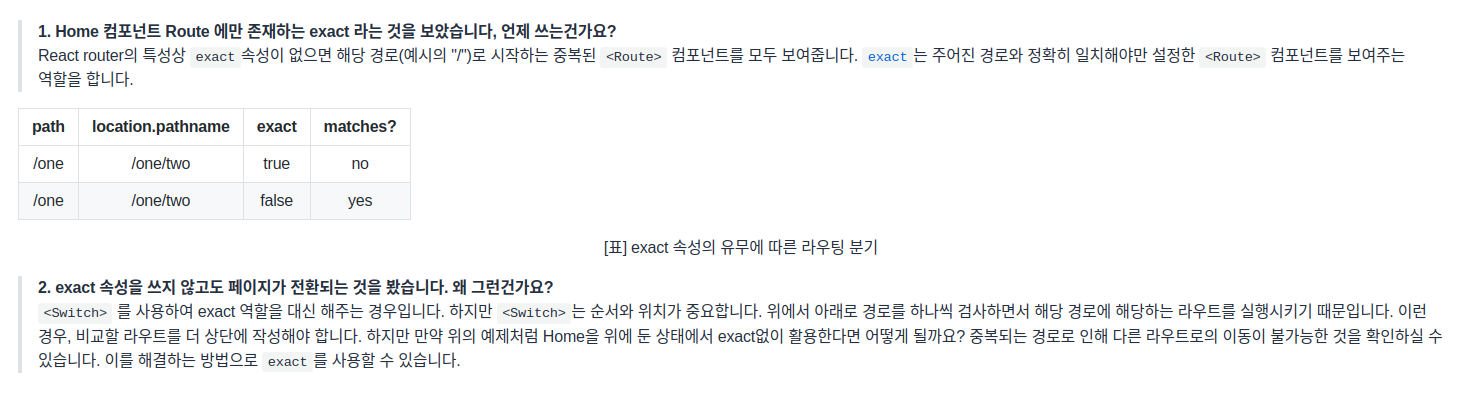
2. Switch & Route ---
<Switch> 컴포넌트는 여러 <Route>를 감싸서 그 중 경로가 일치하는 단 하나의 라우터만 렌더링을 시켜주는 역할을 수행. <Switch> 를 사용하지 않으면 매칭되는 모든 요소를 렌더링한다.
<Route> 컴포넌트는 path 속성을 지정하여 해당 path에 어떤 컴포넌트를 보여줄지 정한다. 아래에서 배울 Link 컴포넌트가 정해주는 URL 경로와 일치하는 경우에만 작동.
3. Link ---
경로를 연결해주는 역할을 하는 컴포넌트. 페이지 전환을 통해 페이지를 새로 불러오지 않고 애플리케이션을 그대로 유지하여 HTML5 History API 를 이용해 페이지의 주소만 변경.
ReactDOM으로 렌더를 시키게 되면 <Link> 컴포넌트는 <a> 태그로 바뀌는 모습을 볼 수 있음.
** React Router 에서 <a> 태그가 아닌 <Link>를 사용하는 이유가 있는지?
<a>태그는 페이지를 전환하는 과정에서 페이지를 불러오기 때문에 다시 처음부터 렌더링을 진행.
즉, 새로고침 현상이 일어남.
하지만 <Link> 컴포넌트는 페이지 전환을 방지하는 기능이 내장되어있기 때문에 SPA를 구현할 수 있음.
function App () {
return (
<BrowserRouter>
<div>
<nav>
<ul>
<li>
Home
</li>
<li>
MyPage
</li>
<li>
Dashboard
</li>
</ul>
</nav>
{/* 주소경로와 우리가 아까 만든 3개의 컴포넌트를 연결해줍니다. */}
<Switch>
<Route exact path="/">
<Home />
</Route>
<Route path="/about"> {/* 경로를 설정하고 */}
<MyPage /> {/* 컴포넌트를 연결합니다. */}
</Route>
<Route path="/dashboard">
<Dashboard />
</Route>
</Switch>
</div>
</BrowserRouter>
)
}