
1-1. 머신러닝과 딥러닝
- 딥러닝 : 인공 신경망을 이용한 머신러닝 알고리즘
- 머신러닝 : 반복적으로 자신의 성능을 개선해나가는 컴퓨터 알고리즘
- 인공지능 : 인간의 지능을 모방한 기계 혹은 그에 준하는 컴퓨터 기술
1-2. 지도 학습, 비지도 학습, 강화 학습
- 지도 학습supervised learning : 정답이 있는 학습
- 비지도 학습unsupervised learning : 정답이 없는 학습
- 강화 학습reinforcement learning : 인공지능이 직접 체험하며 학습하는 학습
1) 지도 학습 :
고양이 사진에는 고양이라는 정답이 붙어 있고,
토끼 사진에는 토끼라는 정답을 붙여 제공해 학습.
학습된 인공지능에 정답 없는 고양이 또는 토끼 사진을 넣는다.
학습된 인공지능이 고양이와 토끼 사진을 구분한 예측 결과를 출력
2) 비지도 학습 :
구매 이력으로 소득 수준을 파악하든가, 취향을 판단할 수 있다.
정답은 없으나 주어진 정보를 이용해 상관관계를 찾아내는 것
데이터를 그룹으로 나누는 클러스터링과 이상치 탐지에 사용
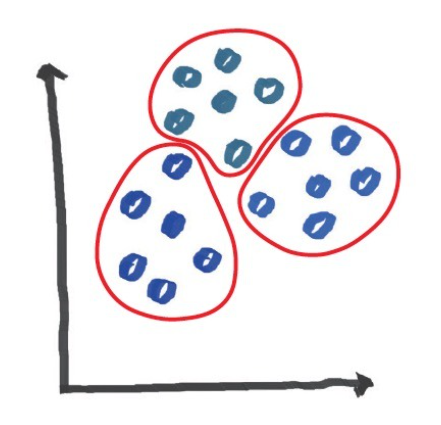
개별 데이터 간 구별은 불가능하지만 그룹으로 나눌 수 있다.
3) 강화 학습 :
지도 학습과 비지도 학습은 모두 데이터를 입력으로 제공
강화 학습은 데이터를 입력으로 받지 않는다.
주어진 환경과 인공지능이 직접 상호작용
인공지능의 행동을 수정해나가도록 학습
인공지능이 직접 자신의 행동을 개선
ex) 알파고
1.3 왜 딥러닝에 파이토치인가?
딥러닝 모델을 만들고 학습하는 데 필요한 도구를 모아놓은 프레임워크가 여럿 있다.
텐서플로TensorFlow, 케라스Keras, 파이토치PyTorch
현재, 파이토치는 논문에서 가장 많이 사용되는 딥러닝 프레임워크
파이토치 코드는 파이썬 본래의 코드와 유사해 직관적
텐서플로
- 텐서플로는 구글에서 공개한 프레임워크로 다양한 플랫폼에서 사용 가능
- 케라스를 고수준 API로 사용
- 파이썬으로 작성된 오픈 소스 신경망 라이브러리로, 파이토치와 마찬가지로 파이썬과 유사한 코딩 스타일을 가지고 있음
- 정적 계산 그래프 :
-- 변수를 정의할 때 그래프 형태가 만들어진다.
-- 중간에 변수의 값을 바꿀 수 없다.
-- 정의한 순서대로 계산하므로 속도가 빠르다.
-- 텐서플로
- 동적 계산 그래프 :
-- 변수를 호출할 때 그래프를 만들어가며 사용.
-- 중간에 변수의 값을 바꿀 수 있다.
-- 파이토치
파이토치는 동적 계산 그래프를 활용
즉, 코드를 읽어오면서 그래프를 만들어가며 사용
프레임워크들은 서로 코딩 스타일과 문법이 다르고 공개하는 모델도 다르기에,
자신이 사용하고자 하는 모델에 따라 프레임워크를 바꿔야 할 때도 있다.
1.4 파이토치 권고 코딩 스타일
텐서
- 데이터를 담고 있는 개체
# 두 텐서의 합을 구하는 예제
import torch
# 1, 2, 3이 들어 있는 텐서를 만든다.
a = torch.tensor([1, 2, 3])
# 4, 5, 6이 들어 있는 텐서를 만든다.
b = torch.tensor([4, 5, 6])
c = a + b
print(c) # tensor([5, 7, 9])파이토치는 클래스를 사용하도록 권고한다.
(1) 모듈 클래스를 이용해 신경망을 만들고,
(2) 데이터셋 클래스를 이용해 데이터를 불러와 학습한다.
■ 모듈 클래스
파이토치 딥러닝 신경망은 모두 모듈(nn.Module 클래스)로 구성되어 있다.
# 파이토치 신경망의 기본 구성
class Net(nn.Module):
def __init__(self):
```
# 신경망 구성요소 정의
```
def forward(self, input):
```
# 신경망의 동작 정의
```
return outut
모듈 클래스는 신경망의 구성요소를 정의하는 init() 함수와
신경망의 동작을 정의하는 forward() 함수로 구성되어 있다.
파이토치는 미리 정의해둔 신경망 모듈을 제공.
제공하는 모듈을 불러와 init() 함수 안에 정의
forward() 함수에 신경망 동작 정의
(init()함수에서 정의한 모듈을 연결하거나, 필요한 연산 등을 정의)
■ 데이터셋 클래스
# 데이터를 호출하는 데이터셋 클래스의 뼈대
class Dataset():
def __init__(self):
```
필요한 데이터 불러오기
```
def __len__(self):
```
데이터의 개수 반환
```
return len(data)
def __getitem__(self, i):
```
i번째 입력 데이터와
i번째 정답을 반환
```
return data[i], label[i]init() 함수
- 학습에 사용할 데이터 불러오기
len() 함수
- 데이터 개수 반환
getitem() 함수
- 지정한 i번째 입력 데이터와 정답 반환
모듈 클래스 & 데이터셋 클래스를 이용한 학습을 진행하는 뼈대
# '데이터로더'로부터 데이터와 정답을 받아옴
for data, label in DataLoader():
# 모델 예측값 계산
prediction = model(data)
# 손실 함수를 이용해 오차 계산
loss = LossFunction(prediction, label)
# 오차 역전파
loss.backward()
# 신경망 가중치 수정
optimizer.step()파이토치는 학습에 사용할 입력 데이터와, 정답을 불러오는 데이터로더를 제공한다.
데이터로더
- 데이터셋 클래스를 입력으로 받아 학습에 필요한 양 만큼의 데이터를 불러오는 역할
- 데이터로더로부터 데이터와 정답을 불러와 신경망의 예측값을 계산
(신경망은 파이토치 모듈)
예측값을 계산했으면,
손실 함수를 이용해 신경망의 오차 계산,
backward() 메서드를 이용해 오차를 역전파,
step() 메서드를 이용해 신경망 가중치 수정
1.5 딥러닝 문제 해결 프로세스
-
해결할 문제 정의
ex) 이미지를 읽어들여 분류, 문장 안 비어 있는 단어 맞추기 등의 문제 정의 -
데이터 수집
딥러닝은 데이터를 기반으로 학습이 이뤄진다.
입력 데이터에 대한 딥러닝 모델의 예측이 올바른지를 판단할 정답이 필요 -
데이터 가공
수집 시, 정답이 잘못된 데이터, 도움이 되지 않는 데이터 등은 제거해줘야 한다.데이터 전처리
- 모델 입력으로 사용하기 전에 학습이 원활하게 이루어지도록 데이터를 가공하는 작업
-
딥러닝 모델 설계
문제에 알맞는 모델 설계 -
딥러닝 모델 학습
데이터를 입력하면 예측이 올바른지, 정답과 비교해가며 모델 학습손실
- 얼마나 올바르게 학습했는가를 근사적으로 나타내는 수치
- 손실이 작아지도록 학습
-
성능 평가
학습 때 이용하지 않은 데이터를 이용하여 학습이 완료된 모델의 성능 평가
성능 평가에 '평가 지표' 이용
평가 지표가 딥러닝 모델의 성능을 근사적으로 나타냄
1.6 딥러닝 문제 해결 체크리스트
1) 풀어야 할 문제 이해하기
□ 정확한 값을 예측하는 회귀 문제인가?
□ 입력이 속한 범주를 예측하는 분류 문제인가?
2) 데이터 파악하기
□ 입력 자료형, 정답 확인
□ 클래스 간 불균형 확인
□ 누락된 데이터, 자료형에 맞지 않는 데이터 확인
3) 데이터 전처리
□ 데이터 부족시 데이터 증강
□ 데이터 정규화하여 값 범위 맞추기
4) 신경망 설계
□ 데이터 공간 정보가 중요하면 합성곱 적용하기
□ 데이터 순서 정보가 중요하면 RNN 적용하기
5) 신경망 학습
□ 적합한 손실 함수 찾기
□ 가중치 수정을 위한 최적화 정하기
□ 평가 지표 정하기
6) 손실이 무한대로 발산
□ 손실 함수 바꿔보기
□ 데이터 이상치 확인하기
□ 학습률 줄이기
7) 손실이 0으로 수렴
□ 데이터 부족한지 확인
□ 신경망 크기 줄이기
1-7. 딥러닝에 필요한 최소한의 통계 개념
1. 독립변수와 종속변수
독립변수independent variable
- 다른 변수에 영향을 받지 않는다.
- 다른 변수의 값을 결정하는 변수
- 입력값으로 사용
종속변수dependent variable
- 독립변수에 의해 값이 결정되는 변수
- 출력 대상이 되는 변수(목푯값)
2. 평균과 분산
데이터의 대략적인 분표를 알수 있게 해준다.
평균
- 데이터의 합 / 데이터 수
- 정규분포와 같이 종형 분포를 갖는 확률 분포에서 랜덤하게 데이터를 뽑았을 때 평균에 가까운 값이 나올 확률이 가장 크다는 것을 의미
분산
- 데이터가 얼마나 펴졌는가
- 분산이 크다 : 평균으로부터 넓게 흩어져 있는 데이터가 많다.
- 분산이 작다 : 평균 근처에 데이터가 몰려있다.
- 표준편차 :
마무리
머신러닝은 데이터를 분석해, 가설을 만들어 데이터를 분류하는 과정
딥러닝은 머신러닝의 한 종류로 인공 신경망을 이용한 학습 방법
지도 학습은 데이터에 정답이 붙어 있는 학습 방법
비지도 학습은 데이터에 정답이 붙어 있지 않은 학습 방법
강화 학습은 데이터를 제공하지 않아도 인공지능이 스스로 시행착오를 겪으며 성장하는 학습 방법
