
1. 체격을 보고 초・중・고등학생을 구분
1.1 프로젝트 소개
여학생의 경우 성장 급등 시기가 빨라 초등학교 고학년과 고등학생의 체격이 크게 차이 나지 않으며,
남학생의 경우 중학생과 고등학생을 체격만 보고 구분하는 것은 쉽지 않다.
인공지능은 체격만으로 구분할 수 있을까
1.2 데이터 살펴보기
(1) 데이터 개요
서울시 교육청에서 공개한 학생 건강검사 데이터를 활용
(2) 피쳐 설정
우리가 유심하게 살펴보려고 하는 부분을 피쳐(feature)라고 한다.
어떤 피쳐를 학습에 활용할 것인지 선택하는 안목이 데이터분석의 실력
'키'와 '몸무게'는 체격과 관련된 정보
'성별'도 확인할 수 있다면 유용
'학교명'을 분석하면 초등학교, 중학교, 고등학교 구분 가능
(3) 피쳐와 레이블
함수에 입력하는 값을 X
함수가 출력하는 값을 Y
'성별', '키', '몸무게' 피쳐들을 X값으로 사용
'초등학교', '중학교', '고등학교'는 각각 0, 1, 2로 변환하여 Y값으로 사용
(4) 데이터의 노멀라이즈
'체중'은 대체로 100보다 낮은 편
'키'는 대체로 100보다 훨씬 큰 편
두 피쳐 사이의 값이 범위가 상당히 다른데,
AI가 공평하게 여러 피쳐를 학습할 수 있도록 노멀라이즈(normalize)라는 작업이 필요
이를 통해 '체중'과 '키' 값을 모두 0과 1 사이의 값으로 변환한다.
변환 방법은, 최댓값으로 모든 수치를 나누어 주는 것
ex) '체중' 데이터의 최댓값이 100kg이라면, 모든 '체중'값을 100kg으로 나누어 준다.
이 과정을 거치며 100kg은 1.0, 30kg은 0.3이 된다.
(5) 데이터 분할
전체 데이터를 잘 섞은 다음
80%는 학습에 활용, 20%는 평가에 활용
※ 테스트 데이터에는 트레이닝 데이터와 중복되는 데이터가 포함되면 안된다.
AI의 성능이 실제보다 더욱 뛰어난 것으로 왜곡된 결과가 발생
1.3 어떤 인공지능을 만드나
(1) 신경망의 구조
입력층 1개, 은닉층 1개, 출력층 1개

'크기'는 퍼셉트론의 개수
크기 3짜리 신경망은 퍼셉트론 3개로 구성
크기 128짜리 신경망은 퍼셉트론 128개로 구성
크기 128짜리 커다란 신경망이 중앙에 있는 대칭 구조 모델을 사용해본다.
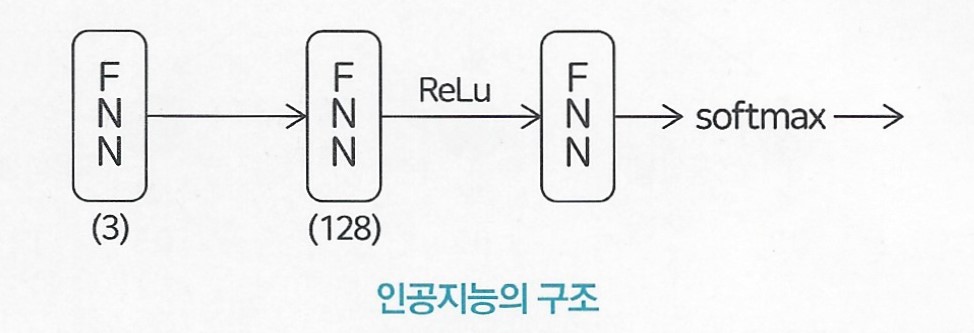
입력층은 '성별', '키', '체중' 3종류의 데이터를 입력받기 위해 크기를 3으로 설정
일반적으로 입력층의 크기는 피쳐의 개수와 동일하게 설정
크기가 작다면 일부 피쳐가 누락,
크기가 크면 아무 피쳐도 입력받지 못하는 불필요한 공간 발생
출력층은 '초등학생', '중학생', '고등학생' 3종류의 카테고리를 구분하기 위해 크기를 3으로 설정
분류 문제에서 출력층 크기 결정 방법은 다양하지만,
카테고리 개수와 출력층의 크기을 동일하게 설정하는 것이 일반적
(2) 분류에 사용하는 활성화 함수, softmax
softmax 함수는, 뉴런의 행동을 모사하기 보다는 분류 문제에서 확률 질량 함수의 정규화를 위해 사용
신경망의 출력값은 숫자에 불과하지만,
softmax 연산을 거치면 확률 질량 함수로서 의미가 생김
분류 문제에서는 Softmax 함수를 사용하면 좋다.
(3) 분류의 원리
인공신경망이 이리저리 학습되며, AI가 조금씩 의미 있는 추론을 하기 시작.
이 과정에서 출력층은 각각 숫자를 출력한다.
이 숫자들은 각각의 카테고리에 대한 확률이 된다.
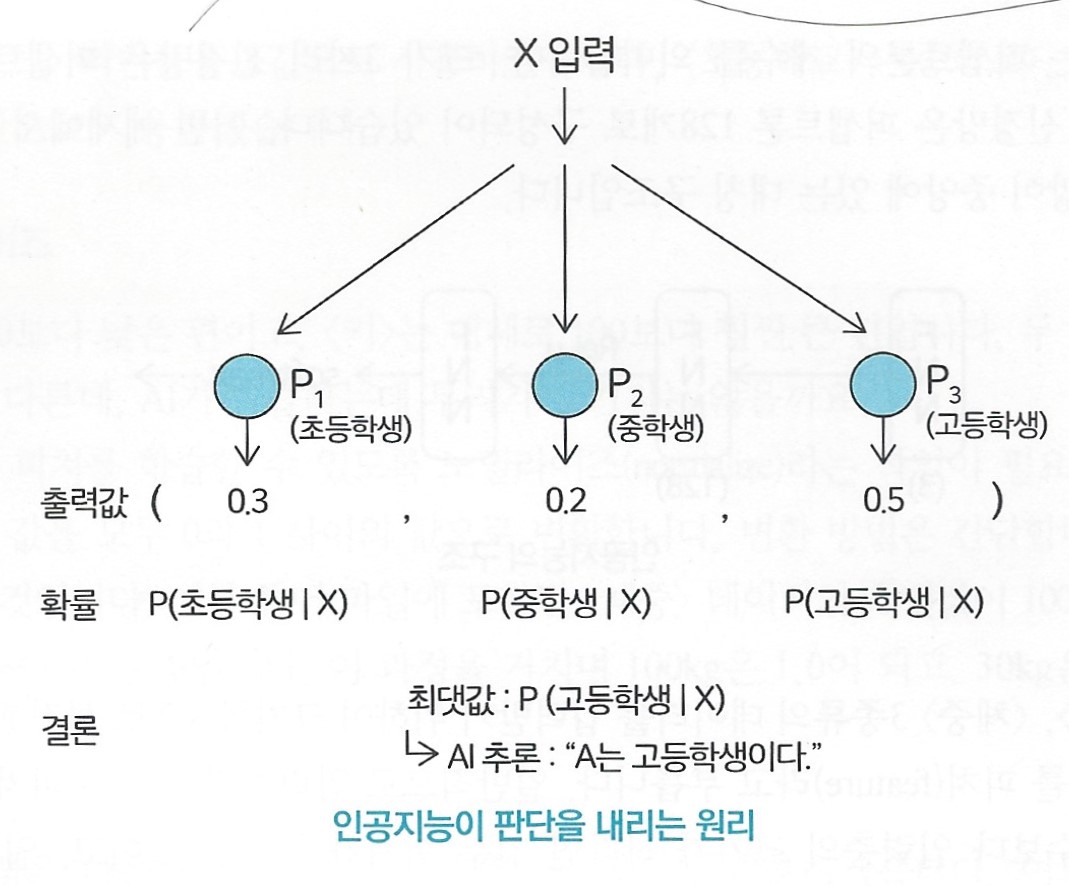
출력층의 퍼셉트론 3개는 각각 숫자를 출력하고, 이는 확률을 의미한다.
위 그림의 3개의 출력값 중 'X가 고등학생일 확률'이 0.5로 가장 큰 값을 가지며,
이때 'AI는 X를 고등학생으로 분류했다'라고 할 수 있다.
분류 인공지능의 학습은 '출력층이 추론한 확률이 최대한 잘 들어맞도록 노력하는 과정'이고,
분류 결과는 '인공지능이 가장 높은 확률을 출력한 카테고리'
1.4 딥러닝 모델 코딩
(1) 라이브러리 불러오기
from tensorflow import keras
import data_reader딥러닝 핵심 라이브러리인 keras를 불러온다.
데이터 처리를 도와주는 data_reader.py를 불러온다.
cf. 파이썬 스크립트를불러올 때는 확장자를 제외하고 이름을 기재해야 한다.
(2) 에포크(Epoch) 결정하기
# 몇 에포크 만큼 학습을 시킬 것인지 결정합니다.
EPOCHS = 20 # 예제 기본값은 20입니다.에포크는 일종의 학습 횟수
에포크가 1이면, 전체 데이터를 한 번 학습하고 학습이 종료
에포크가 10이면, 전체 데이터를 10번 학습하고 학습이 종료
이번 예제의 기본값은 20이며,
인공지능이 데이터를 20회 학습하면 학습이 종료
(3) 데이터 읽어오기
# 데이터를 읽어옵니다.
dr = data_reader.DataReader()변수 dr에 데이터가 저장된 '클래스'라는 장치가 저장된다.
(4) 인공신경망 제작하기
# 인공신경망을 제작합니다.
model = keras.Sequential([
keras.layers.Dense(3),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dense(3, activation='softmax')
])퍼셉트론으로 구성된 인공신경망 층은 layers.Dense()함수를 사용하여 제작가능
'activation'은 활성화 함수를 의미
1층은 활성화 함수 없이 신경망을 만들었다.
2층은 relu를 지정했고,
3층은 softmax를 지정했다.
완성된 신경망의 구조는 model 변수에 저장
(5) 인공신경망 컴파일하기
# 인공신경망을 컴파일합니다.
model.compile(optimizer="adam", metrics=["accuracy"],
loss="sparse_categorical_crossentropy")컴파일은 코드를 컴퓨터가 이해할 수 있는 형태로 변환하는 작업
keras에서 인공신경망을 컴파일할 때에는 옵티마이저(optimizer), 로스(loss), 메트릭(metrics) 세 가지 정보를 입력해야 한다.
optimizer는 인공신경망의 가중치를 조절하기 위한 알고리즘
다양한 알고리즘이 있지만, 'adam'을 사용하면 대체로 언제든지 좋은 결과를 얻을 수 있다.
loss는 인공신경망을 학습시키기 위한 기준이 되는 함수
loss가 작으면 작을수록 AI 성능이 높다.
분류 문제에선 '크로스 엔트로피(cross-entropy)'를 사용하는 것이 적절
크로스 엔트로피(cross-entropy)
- 두 개의 서로 다른 확률분포를 구분하기 위해 사용하는 척도
분류 문제에 적용하면 가중치 업데이트가 훨씬 잘 된다.
'sparse_categorical_crossentropy'는 크로스 엔트로피 함수의 한 종류
metrics는 성능 검증을 위한 척도
여기서는 정확도를 의미하는 accuracy를 사용
1.5 인공지능 학습
(1) 인공신경망 학습을 위한 코드
# 인공신경망을 학습시킵니다.
print("************ TRAINING START ************")학습 시작 안내 문구를 화면에 출력한다.
(2) 콜백, 학습을 조기에 중단하기 위한 도구
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)콜백(callback)은 학습을 중간에 중단시키기 위해 사용하는 기능
'에포트'를 너무 높게 설정하면 '오버피팅'등의 현상이 발생하며 오히려 성능이 떨어지는 경우가 발생할 수 있다.
인공지능의 성능이 적당히 상승했을 때 학습을 중단할 필요가 있다.
'monitor'는 학습을 조기에 중단하기 위한 기준으로 삼을 지표를 의미.
val_loss는 검증 과정의 '로스'를 의미
성능 검증을 실시하고, 로스가 딱히 개선되지 않는다면 학습을 중단하라는 의미
'patience'에는 숫자가 들어간다.
10이 입력되었다면, '10 에포크가 지나도록 성능 개선이 없으면 중단하겠다.'라는 의미
'patience'가 너무 길면 중단 시점에서 AI의 성능이 나쁠 수 있고,
너무 짧으면 충분한 학습이 진행되기 전에 학습이 종료되어버릴 수도 있다.
(3) 인공신경망 학습 개시
history = model.fit(dr.train_X, dr.train_Y, epochs=EPOCHS,
validation_data=(dr.test_X, dr.test_Y),
callbacks=[early_stop])학습에는 fit()함수가 사용된다.
fit() 함수
keras에서 AI를 학습하기 위해 사용하는 함수
'dr.train_X'와 'dr.train_Y'는 트레이닝 데이터를 의미.
'dr.train_X'는 AI에 입력해 줄 데이터
'dr.train_Y'는 AI의 출력 결과물을 채점하기 위한 레이블(label)
'epochs'에는 학습을 반복할 에포크 수를 입력
'validation_data'는 인공지능의 성능을 평가하기 위한 테스트 데이터
'dr.test_X'와 'dr.test_Y'를 활용
'callback'에는 콜백 입력
(4) 학습 결과 출력
# 학습 결과를 그래프로 출력합니다.
data_reader.draw_graph(history)'data_reader.py'라이브러리에는 학습 결과를 그림으로 표현해 주는 draw_graph() 함수가 내장되어 있다.
학습 결과(history변수)를 함수에 입력하면 결과가 출력된다.
(5) 전체 코드
from tensorflow import keras
import data_reader
# 몇 에포크 만큼 학습을 시킬 것인지 결정합니다.
EPOCHS = 20 # 예제 기본값은 20입니다.
# 데이터를 읽어옵니다.
dr = data_reader.DataReader()
# 인공신경망을 제작합니다.
model = keras.Sequential([
keras.layers.Dense(3),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dense(3, activation='softmax')
])
# 인공신경망을 컴파일합니다.
model.compile(optimizer="adam", metrics=["accuracy"],
loss="sparse_categorical_crossentropy")
# 인공신경망을 학습시킵니다.
print("************ TRAINING START ************")
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(dr.train_X, dr.train_Y, epochs=EPOCHS,
validation_data=(dr.test_X, dr.test_Y),
callbacks=[early_stop])
# 학습 결과를 그래프로 출력합니다.
data_reader.draw_graph(history)1.6 인공지능 학습 결과 학인하기
(1) 인공지능 성능 확인하기

인공지능의 성능은 'val_accuracy'를 살펴보면 된다.
이번 예제의 인공지능이 '성별', '키', '체중'을 보고 초・중・고등학생 중 어디에 해당하는지 맞힐 확률은 대략 70~73% 가량이다.
(2) 학습 기록 확인하기

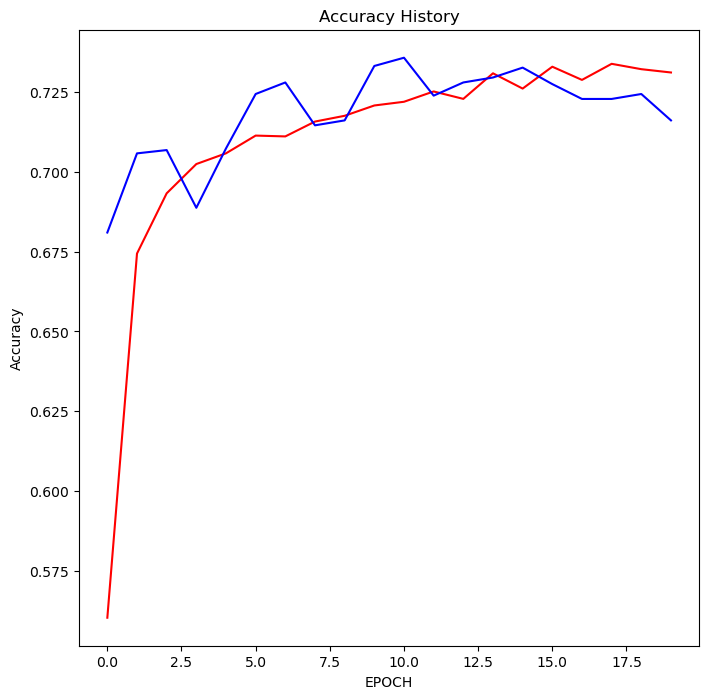
이 두 그래프는 각각 학습이 진행되면서 로스 함수와 정확도가 어떻게 변했는지 보여준다.
빨간선은 트레이닝 데이터, 파란선은 테스트 데이터
Loss History를 보면 트레이닝, 테스트 모두 에포크가 증가함에 따라 점점 감소하는 것을 확인할 수 있다.
Accuracy History의 결과는 다르다.
트레이닝 정확도는 에포크가 증가함에 따라 증가하고 있으나,
테스트 정확도는 증가세가 안정되지 못하다.
대부분의 경우 테스트 성능은 트레이닝에 비해 들쭉날쭉하게 증가하거나, 에포크가 지나면서 오히려 감소하기도 한다. 따라서 학습을 어느 시점에 중단시킬지 결정하는 것도 인공지능 성능 측면에서 중요한 이슈
1.7 오버피팅(overffiting)과 언더피팅(underfitting)
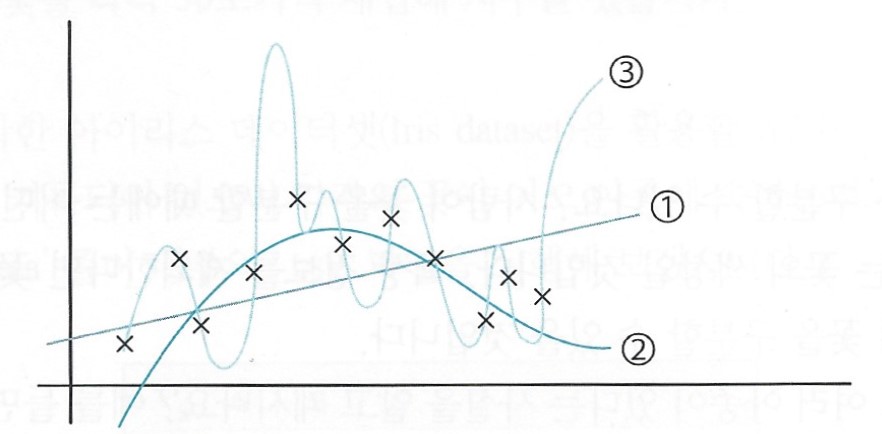
①번 모델은 데이터의 경향성을 전혀 따라가지 못하는 것 같다.
이런 결과를 언더피팅(underfitting)이라고 부른다.
②번 모델은 데이터의 경향성을 대체로 잘 따라가고 있다.
하지만, X 표시를 직접 관통하고 있지는 않다.
③번 모델은 모드 X 표시를 관통한다.
loss를 구하면 굉장히 낮게 나올 것.
하지만 점이 없는 영역에서는 굉장히 이상한 값을 추론한다.
이 모델을 활용해 인공지능을 만들면 X 표시에 해당하지 않는 데이터에서 정상적으로 작동하지 않을 것.
이런 결과를 오버피팅(overfitting)이라고 한다.
모델의 variance에 비해 데이터의 규모가 작을수록 오버피팅이 쉽게 발생한다.
따라서, 딥러닝에서는 빅데이터를 확보하는 것이 가장 중요한 문제 중 하나.
데이터의 규모가 작다면 퍼셉트론의 개수를 줄이거나, 층수를 낮춰 모델의 variance를 낮춰 줘야 한다.
모델을 너무 오랜 에포크 동안 학습시켜도 오버피팅이 발생
인공지능이 트레이닝 데이터에만 너무 집중해서 ③과 같은 형태로 학습이 진행된 것
오버피팅을 방지하는 것은 딥러닝에서 가장 중요한 문제 중 하나.
학습과정에서 오버피팅 발생 여부는 앞서 살펴본 학습 결과 그래프를 살펴보면 간단하게 확인할 수 있다.
트레이닝 성능에 비해 테스트 성능이 부족하면 오버피팅이 발생한 것.
1.8 하이퍼 파라미터 조작
뉴럴 네트워크의 층수,
각 층에 포함된 퍼셉트론의 개수,
에포크 등 인공지능을 제작할 때 인간이 직접 지정해 주는 값을 하이퍼 파라미터(Hyper Parameter)라고 한다.
뉴럴 네트워크의 층수를 늘려보던가,
(keras.Sequential() 함수 내부에 Dense() 레이어 추가)
은닉층의 퍼셉트론 개수를 늘리거나 줄여본다.
(keras.layers.Dense() 함수 안에 기재된 숫자 변경. 단, 입력층, 출력층 퍼셉트론 개수를 수정하지 않는다.)
2. 꽃 구분하기
2.1 프로젝트 소개
동일한 꽃의 아종을 구분해내는 AI를 만들어본다.
2.2 데이터 살펴보기
붓꽃은 'Iris'라는 종이면서, 하위로 Iris Setosa, Iris Versicolor, Iris Virginica라는 세 가지 종이 있다.
150개의 꽃으로부터 수집된 수치가 기록되어 있으며, 각각의 꽃이 어느 아종에 속하는지도 기록되어 있다.
'꽃받침의 길이', '꽃받침의 너비', '꽃잎의 길이', '꽃잎의 너비', '꽃의 종류' 데이터가 있으며,
왼쪽 4개 값이 피쳐
'꽃의 종류'가 레이블이 된다.
치수 정보는 노멀라이즈해 X값으로 사용하고,
꽃의 종류는 (0, 1, 2)로 변환하여 Y값으로 사용해본다.
전체 데이터를 섞은 후,
80%는 트레이닝 데이터, 20%는 테스트 데이터로 활용한다.
2.3 어떤 인공지능을 만드나
(1) 신경망의 구조
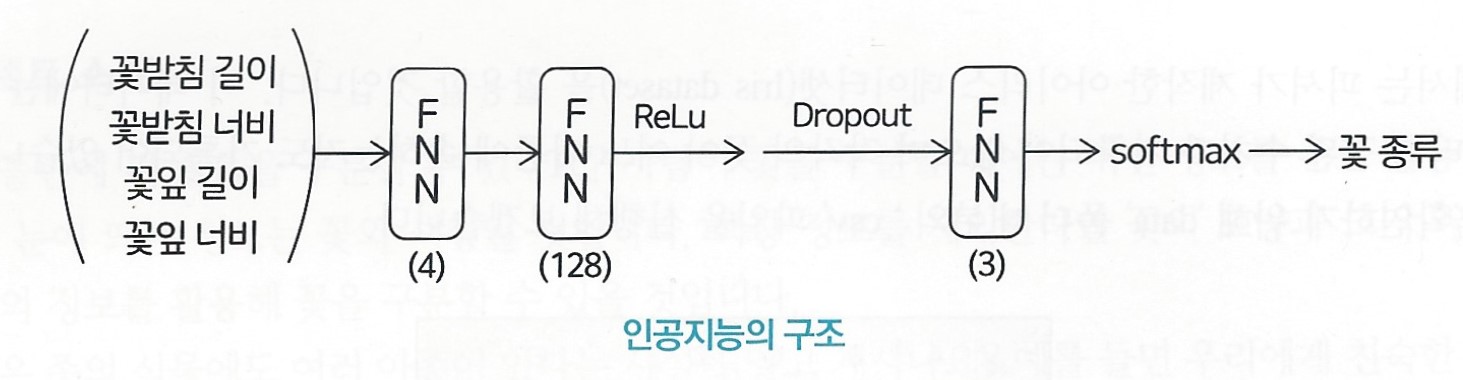
4개의 피쳐를 입력받기 위해, 1층의 크기는 4
최종적으로 3종류의 꽃 아종을 구분하기 위해 출력층의 크기는 3으로 지정
분류 문제이므로 출력층의 활성화 함수는 소프트맥스로 지정
2층의 크기는 128이며, 활성화 함수는 ReLu 사용.
그런데 2층 아래에 'Dropout'이라는 값이 기재되어 있다.
(2) 신경을 버리는 드롭아웃
드롭아웃(dropout)은 신경 일부를 버리는 기법
드롭아웃의 크기에 'rate=0.5'라고 기재되어 있다.
학습마다 임의로 50%의 퍼셉트론을 선택하여 드롭아웃 대상으로 선정한다는 의미'
드롭아웃 대상은 매번 임의로 선택된다.
드롭아웃 대상으로 지정된 퍼셉트론은 잠시동안 가중치가 0으로 설정되어 다른 퍼셉트론으로 정보를 전달하지 못한다.
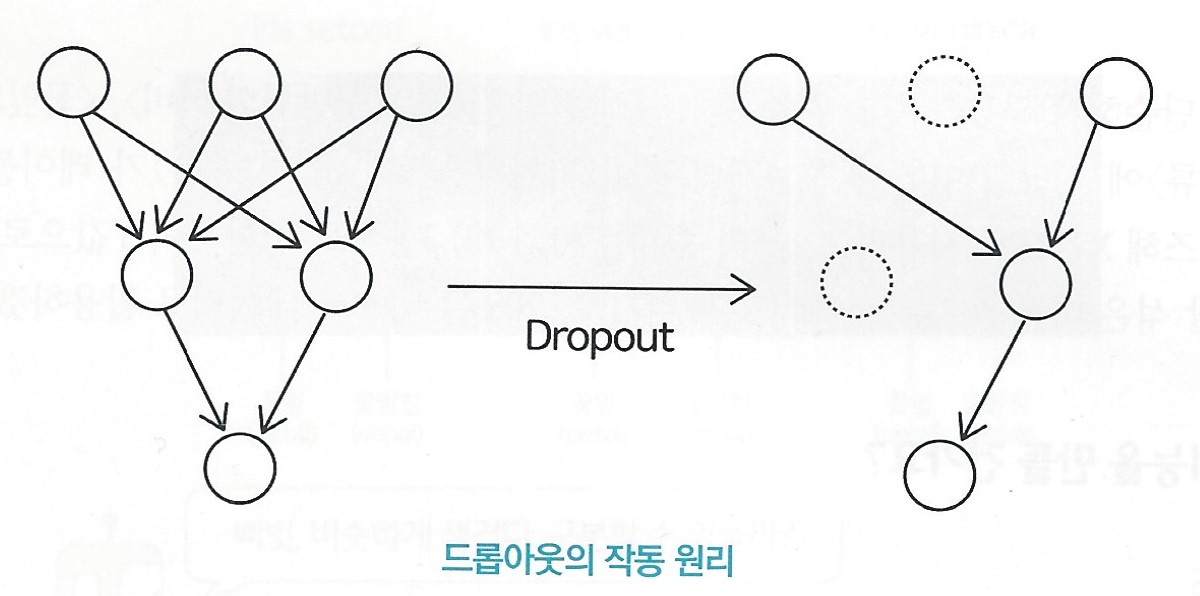
드롭아웃을 적용하면 오버피팅이 방지되는 효과가 있다.
매번 신경망의 형태가 변형되므로 앙상블 기업과 유사하게 학습의 일반화에 유리해진다.
완성된 인공지능에 드롭아웃을 추가하면 갑작스레 성능이 향상되는 경우가 있으나, 드롭아웃을 적용하면 계산 시간이 늘어난다.
학습 결과를 살펴보며 오버피팅이 발생하지 않았다면 굳이 드롭아웃을 적용할 필요는 없다.
2.4 딥러닝 모델 코딩
(1) 라이브러리 불러오기
from tensorflow import keras
import data_reader(2) Epoch 결정하기
# 몇 에포크 만큼 학습을 시킬 것인지 결정합니다.
EPOCHS = 20 # 예제 기본값은 20입니다.(3) 데이터 읽어오기
# 데이터를 읽어옵니다.
dr = data_reader.DataReader()DataReader()가 호출되면 보이지 않는 곳에서 데이터의 노멀라이즈가 자동으로 수행되고, 트레이닝 데이터와 테스트 데이터가 8:2로 분할된다.
(4) 인공신경망 제작하기
# 인공신경망을 제작합니다.
model = keras.Sequential([
keras.layers.Dense(4),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dropout(rate=0.5),
keras.layers.Dense(3, activation='softmax')
])Sequential() 함수를 활용해 인공신경망을 제작한다.
Dropout() 함수를 호출하면서 rate를 입력해 주면 드롭아웃이 간단하게 적용된다.
드롭아웃 함수를 호출하면, 함수가 호출되기 전 가장 최근에 호출된 레이어에 드롭아웃이 적용되며,
위 코드의 경우에선 2층에 드롭아웃이 적용된다.
(5) 인공신경망 컴파일하기
# 인공신경망을 컴파일합니다.
model.compile(optimizer="adam", metrics=["accuracy"],
loss="sparse_categorical_crossentropy")optimizer는 adam
metrics는 accuracy
loss는 cross entropy로 적용한다.
2.5 인공지능 학습
(1) 인공신경망 학습
# 인공신경망을 학습시킵니다.
print("************ TRAINING START ************ ")
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(dr.train_X, dr.train_Y, epochs=EPOCHS, batch_size=5,
validation_data=(dr.test_X, dr.test_Y),
callbacks=[early_stop])콜백을 정의하고, fit() 함수를 활용해 학습을 진행한다.
(2) 학습 결과 출력
# 학습 결과를 그래프로 출력합니다.
data_reader.draw_graph(history)(3) 전체 코드
from tensorflow import keras
import data_reader
# 몇 에포크 만큼 학습을 시킬 것인지 결정합니다.
EPOCHS = 20 # 예제 기본값은 20입니다.
# 데이터를 읽어옵니다.
dr = data_reader.DataReader()
# 인공신경망을 제작합니다.
model = keras.Sequential([
keras.layers.Dense(4),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dropout(rate=0.5),
keras.layers.Dense(3, activation='softmax')
])
# 인공신경망을 컴파일합니다.
model.compile(optimizer="adam", metrics=["accuracy"],
loss="sparse_categorical_crossentropy")
# 인공신경망을 학습시킵니다.
print("************ TRAINING START ************ ")
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(dr.train_X, dr.train_Y, epochs=EPOCHS, batch_size=5,
validation_data=(dr.test_X, dr.test_Y),
callbacks=[early_stop])
# 학습 결과를 그래프로 출력합니다.
data_reader.draw_graph(history)2.6 인공지능 학습 결과 확인하기
(1) 인공지능 성능 확인하기

AI가 꽃받침의 길이, 꽃받침의 너비, 꽃잎의 길이, 꽃잎의 너비의 4가지 피쳐를 보고 붓꽃의 3가지 아종을 구분해낼 확률은 대략 90~94% 가량의 성능을 보여준다.
인공지능의 성능은 동일한 데이터를 사용하더라도 학습 결과는 조금씩 달라진다.
(2) 학습 기록 확인하기
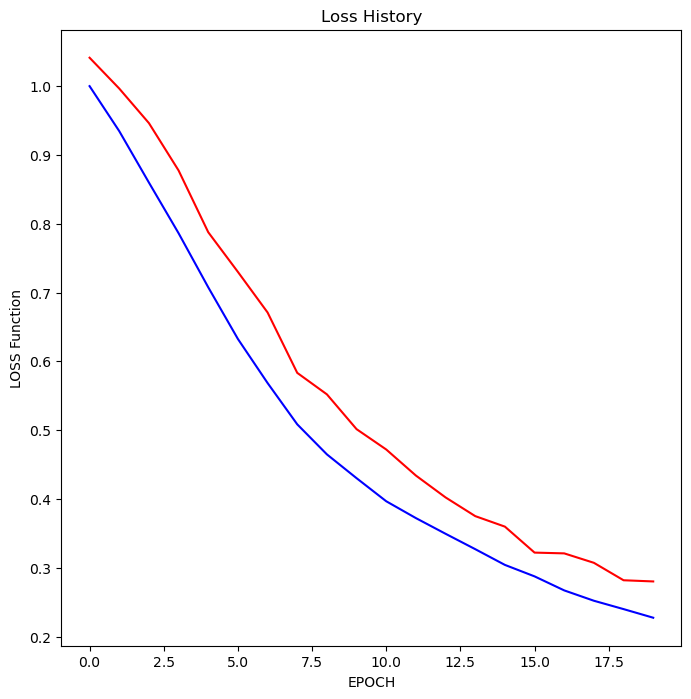
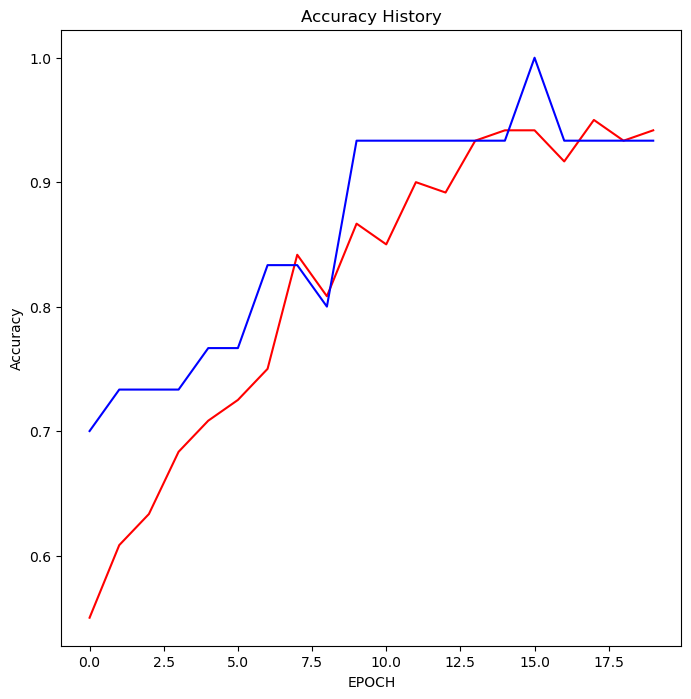
빨간선은 트레이닝 데이터, 파란선은 테스트 데이터
loss는 둘 모두 잘 떨어진다.
accuracy 곡선은 둘 모두 후반부에 결과가 요동치고 있다.
loss는 인공지능의 학습 오차를 의미하지만, 정답률과 직결되지 않을 수도 있다.
AI가 확신에 차서 정답을 맞히던, 긴가민가하게 정답을 맞히던 정확도에는 영향을 주지 못하지만, 확신에 찬 정답은 로스를 훨씬 낮춘다.
AI의 출력값은 카테고리 자체가 아닌, 카테고리에 대한 확률이기에 발생되는 현상
2.7 앙상블 학습
드롭아웃은 앙상블과 유사한 효과가 있어 오비피팅을 피할 수 있다고 언급했다.
앙상블(ensemble)은 하나의 문제를 해결하기 위해 여러 개의 모델을 학습시키는 것을 의미
동일한 알고리즘 모델을 여러 개 학습시키는 방법이나, 여러 종류의 알고리즘을 각각 학습시키는 방법
하나의 데이터로 여러 개의 인공지능을 제작한다는 점에는 차이가 없다.
각각의 인공지능들이 내놓은 의견들을 어떻게 취합하는지에 따라 앙상블 기법이 나눠지기도 한다.
다수결의 원칙에 따라 AI의 의견을 투표로 취합하는 보팅(voting) 기법이 가장 쉬운 방법
드롭아웃을 적용하면 매번 임의의 퍼센트론이 제외되면서 매번 조금씩 다른 형태의 신경망이 학습된다.
이 모습이 서로 다른 여러 개의 모델을 학습시키는 앙상블과 유사하다고 평가된다.
