
1.뇌세포를 모방한 기계, 퍼셉트론
1.1 퍼셉트론의 구조
신경세포의 수상돌기 : 외부 자극을 입력받음
퍼셉트론 : 다양한 데이터를 입력받음
퍼셉트론은 (외부에서 들어오는 입력값 x 가중치())를 모두 더하여 하나의 입력값으로 정돈한다.
가중치를 곱하는 이유는?
뇌 속의 신경들은 서로 얽힌 채 정보를 주고 받는다.
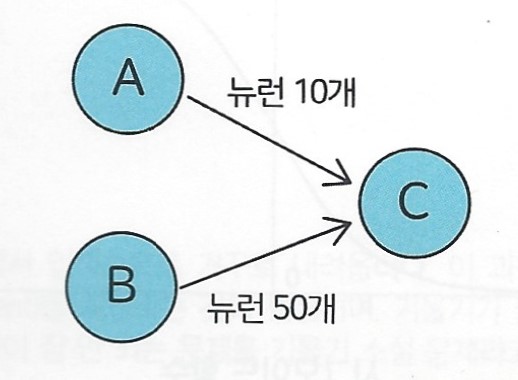
사람의 뇌 속에 A, B, C 세 부위가 있다고 가정
A 부위에서 C 부위로 정보를 전달하는 뉴런은 10개
B 부위에서 C 부위로 정보를 전달하는 뉴런은 50개
이때 C는 당연히 A보다 B부위에서 입력되는 정보를 더욱 중요하게 처리할 것
가중치는 이와 같은 현상을 모사하기 위해 도입된 개념
퍼셉트론은 여러 종류의 입력값에 영향을 받고,
그 영향력의 크기가 바로 가중치
가중치가 큰 입력값은, 퍼셉트론에 큰 영향을 미치고,
가중치가 작은 입력값은, 퍼셉트론에 작은 영향을 미친다.
입력값에 가중치를 곱한 값을 모두 더하여 하나의 정돈된 통합 입력값X를 만들었다면,
이 X를 함수에 입력한다.
이것이 퍼셉트론의 구조이자 작동 원리.
1.2 활성화 함수(Activation Function)
뉴런은 0 또는 1 두 가지 값만 출력할 수 있는 기계
퍼셉트론의 출력값을 뉴런의 출력값과 유사하게 다듬어주려는 시도가 있었으며, 이를 위한 도구를 활성화 함수라고 한다.
인간의 뉴런은 작은 값을 입력받았을 때 0을 출력하고,
입력값이 적당히 커지면 1을 출력한다.
활성화 함수 또한 유사한 형태
(1) 시그모이드 함수(Sigmoid function)
입력값을 0부터 1 사이의 값으로 다듬어주는 함수
입력값이 클수록 1에 가까운 값이 출력되고,
입력값이 작을수록 0에 가까운 값이 출력
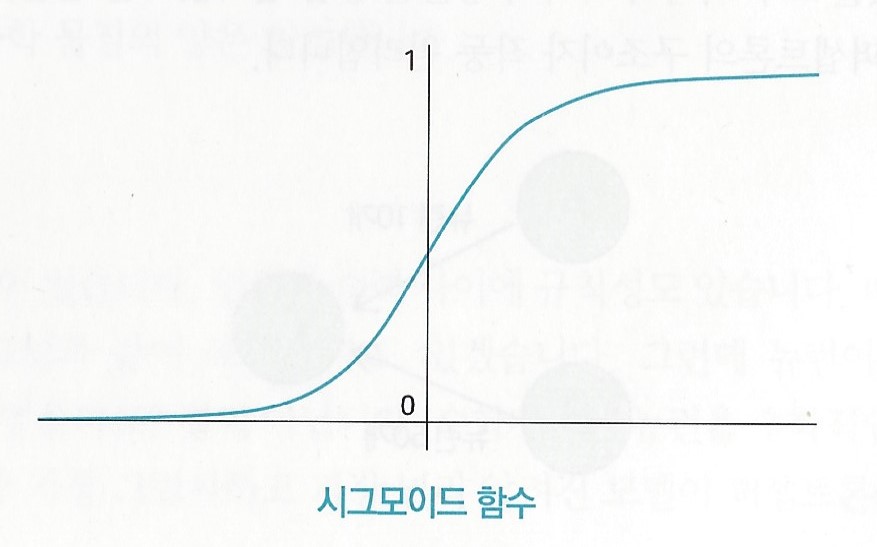
(2) 하이퍼볼릭 탄젠트 함수(tanh, hyperbolic tangent function)
입력값을 -1부터 1 사이의 값으로 다둠어주는 함수
원점을 기준으로 대칭
입력값이 클수록 1에 가까운 값이 출력되고,
입력값이 작을수록 -1에 가까운 값이 출력
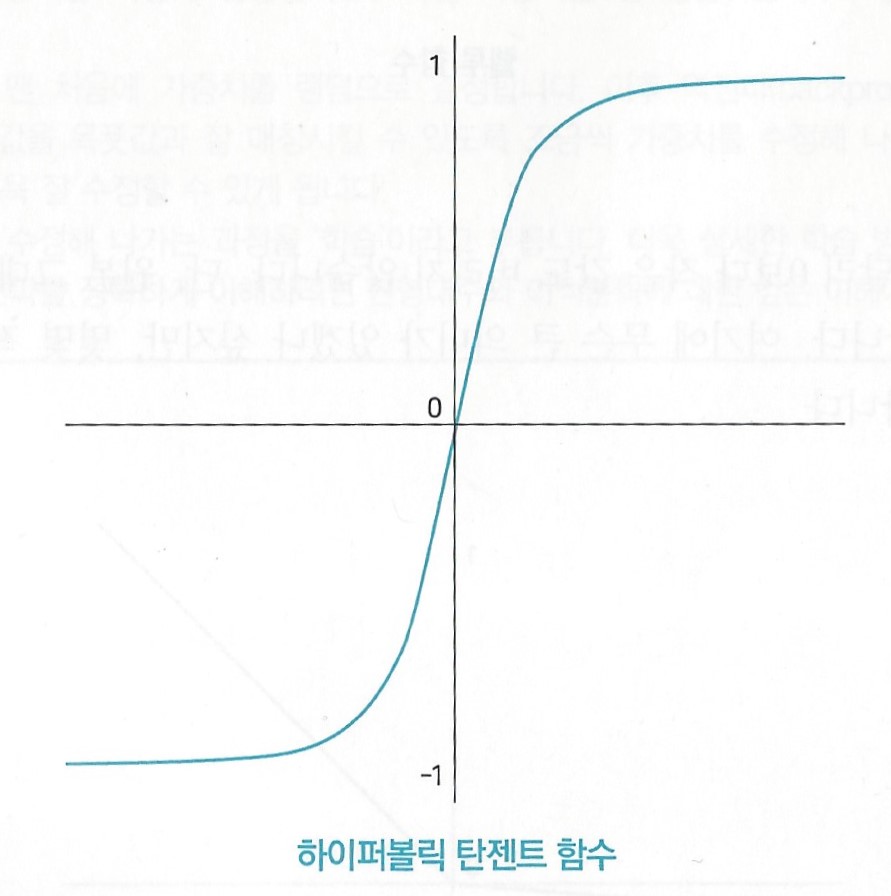
(3) 렐루(ReLU, Rectified Linear Unit)
0보다 작은 값은 0으로 만들고, 0보다 큰 값은 그대로 출력하는 함수
단일 뉴런보다 신경 다발의 정보전달 현상에 가깝다.
뉴런의 활동을 모사하기보다는 기울기 소실 문제를 해결하기 위한 방법으로 조명받음.
어떤 활성화 함수를 적용하면 좋을지 잘 모르겠으면 일단 렐루를 적용.
대부분의 경우 높은 성능을 보인다.
기울기 소실 문제(vanishing gradient problem)
딥러닝에서 신경망의 가중치 수정은 출력층에서 입력층으로 가꾸로 내려온다. 역전파(backpropagation)
역전파 알고리즘은 미분을 통해 기울기(gradient)를 계산하는 것이 핵심.
기울기가 클수록 가중치가 많이 수정된다.
출력층과 거리가 멀어질수록 기울기가 작아지며,
가중치 수정이 잘 안 되는 문제를 기울기 소실 문제라고 한다.
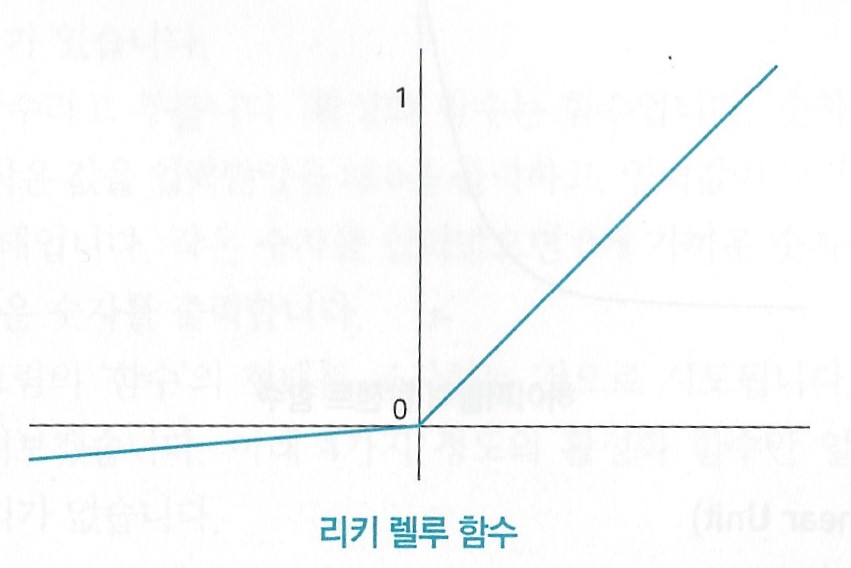
(4) 리키 렐루(Leaky ReLU)
렐루 함수와 달리 0보다 작은 값도 버리지 않는다.
단, 원본보다 약간 더 작은 값을 출력
몇몇 사례에서 렐루에 비해 월등한 성능을 보이기도 한다.
가중치를 잘 결정하는 것이 딥러닝의 전부
일반적으로, 맨 처음에는 가중치를 랜덤으로 결정
이후, 역전파(backpropagation) 알고리즘 적용으로, 퍼셉트론이 입력값을 목표값과 잘 매칭시킬 수 있도록 조금씩 가중치를 수정해 나간다.
2. 인공신경망과 딥러닝
2.1 인공신경망
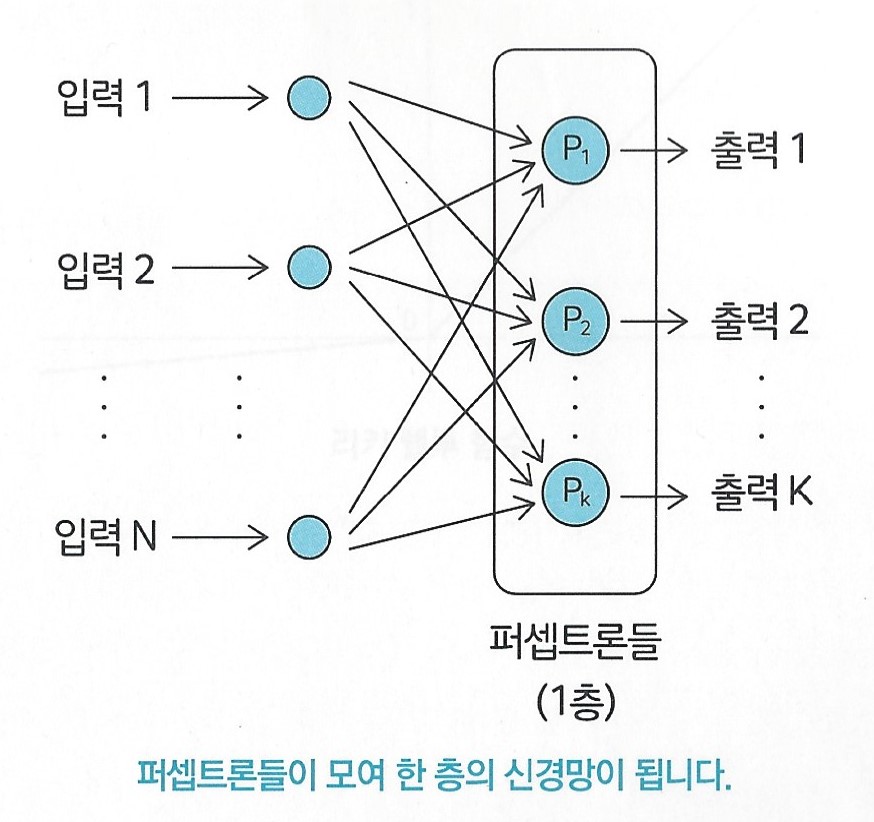
퍼셉트론을 이리저리 연결하면 그것을 인공신경망이라고 부른다.
마구잡이로 연결하기보다는 한 번에 한 층씩 쌓아 올리는 경우가 많다.
(한 층의 신경망은 하나의 행렬로 표현할 수 있어 계산이 더 쉽기 때문)
퍼셉트론들이 모여 한 층의 신경망이 된다.
2.2 딥러닝
인공신경망을 여러 층으로 쌓아 올리는 것을 다층 퍼셉트론(multilayer perceptron)이라고 부른다.
다층 퍼셉트론을 사용한 머신러닝 알고리즘을 딥러닝이라고 부른다.
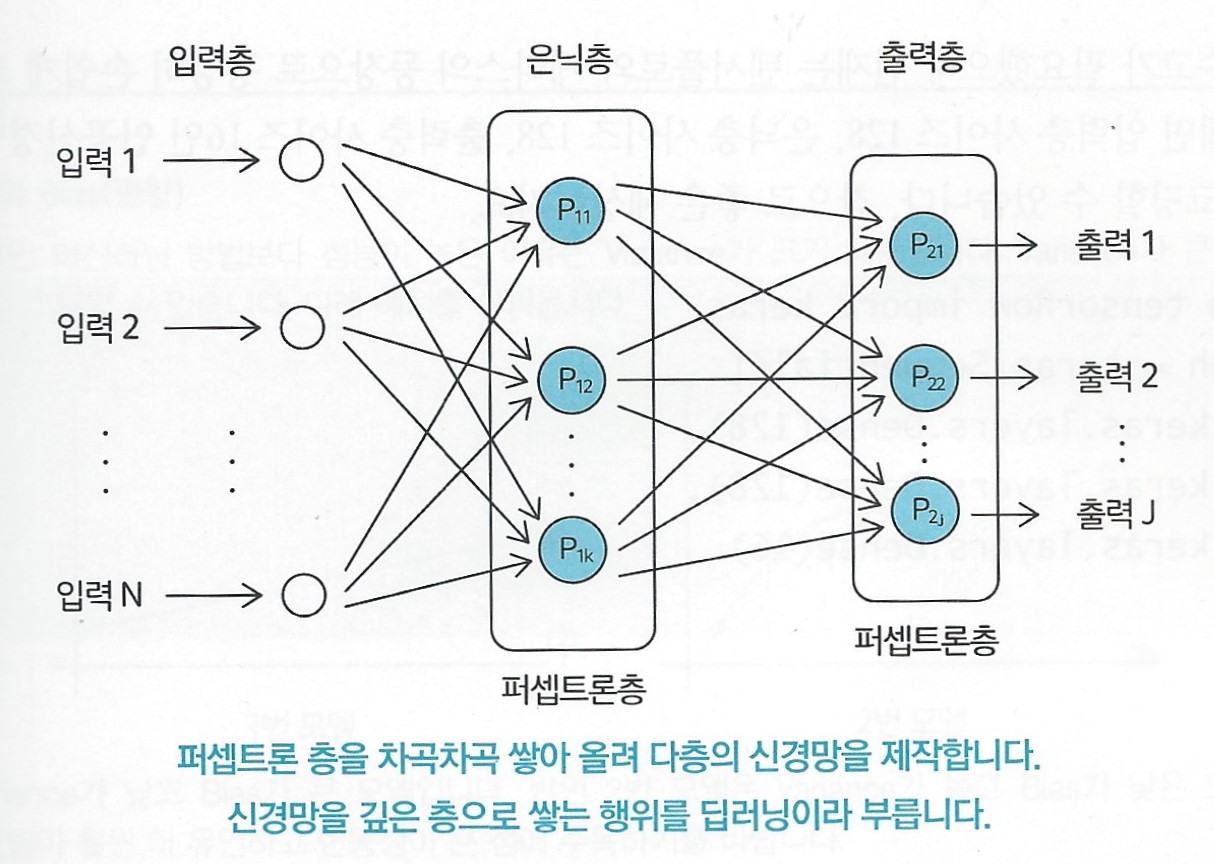
그림은 신경망을 2층으로 쌓은 다층 퍼셉트론 모델
입력층(input layer) : 입력값들로 구성
은닉층(hidden layer) : 첫 번째 퍼셉트론 층
출력층(output layer) : 출력값과 연결된 마지막 층
입력층, 출력층은 외부에서 직접 접근하여 조작할 수 있으나,
은닉층은 불가능
출력층의 경우 출력값과 기댓값의 오차를 구할 수 있기에 손쉽게 가중치를 수정할 수 있었으나, 은닉층에 속한 퍼셉트론의 출력값은 오차를 측정할 기준이 없었기에 은닉층 퍼셉트론의 가중치를 수정할 방법이 없었다.
이 방법은 역전파(backpropagatin) 기법으로 인해, 은닉층의 학습이 가능해져, 이때부터 본격적으로 인공신경망을 2층 이상 쌓는 딥러닝 연구가 시작됨.
다층 퍼셉트론은 입력받은 정보를 앞으로 전달하기에, FNN(Feedforward Neural Network)라고 부른다.
2.3 딥러닝 코딩 방법
딥러닝은 인공신경망을 여러 층 쌓은 것이고,
인공신경망은 여러 개의 퍼셉트론으로 구성되어 있다.
즉, 딥러닝은 엄청나게 많은 퍼셉트론을 서로 복잡하게 이어 붙인 모델
어떻게 코딩할 수 있을까
텐서플로와 케라스로 손쉽게 가능
■ 입력층 사이즈 128, 은닉층 사이즈 128, 출력층 사이즈 16인 인공신경망
from tensorflow import keras
graph = keras.Sequential([
keras.layers.Dense(128),
keras.layers.Dense(128),
keras.layers.Dense(16)
])Variance(분산)과 Bias(편향)
딥러닝 성능이 머신러닝보다 높은 이유는 Variance가 크기 때문.
Variance가 큰 모델은 복잡한 데이터 분포도 잘 추론할 수 있다.
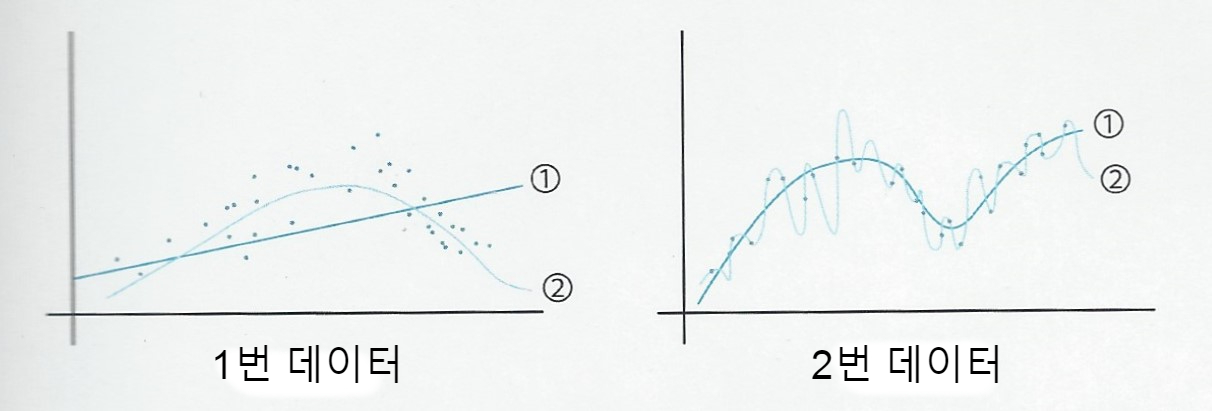
1번 모델은 Variance가 낮고 Bias가 큰 모델
2번 모델은 Variance가 높고 Bias가 낮은 모델
1번 모델보다 2번 모델이 훨씬 더 유연하고 변동성이 크다.
1번 데이터의 분포는 포물선 형태
1번 모델은 직선 형태의 모델
유연성이 낮아 곡선 형태의 데이터를 충분히 반영하지 못하고 있다.
2번 모델은 비교적 Variance가 높아 포물선 형태의 데이터를 잘 반영
그렇다면 Variance가 높고 Bias가 낮은 모델은 항상 뛰어난 성능을 보여줄까?
2번 데이터의 1번 모델은 데이터의 점을 단 하나도 지나고 있지 않다.
2번 모델은 데이터의 점을 모두 지나고 있다.
오차를 계산할 경우, 1번 모델보다 2번 모델의 오차가 더욱 낮게 표시될 것이다.
하지만, 1번 모델이 2번 데이터를 더욱 잘 표현한 모델이다.
2번 모델은 그래프의 점이 없는 영역에서 완전히 엉뚱한 값을 추론하고 있다.
1번 모델은 점을 통과하고 있지 않지만, 데이터의 경향성을 따라 움직이고 있어, Variance가 낮은 1번 모델이 훨씬 더 뛰어난 모델.
즉, Variance가 높은 모델을 활용한다고 항상 성능이 높아지지는 않는다.
그러나 2번 데이터의 점 개수가 10만 개로 늘어난다면,
2번 모델은 경향성을 모두 따라가려 할 것이고,
1번 모델과 유사한 그래프의 모양으로 변화할 것이다.
결국, Variance가 높은 모델은 데이터의 양이 늘어날수록 정교하게 작동한다.
