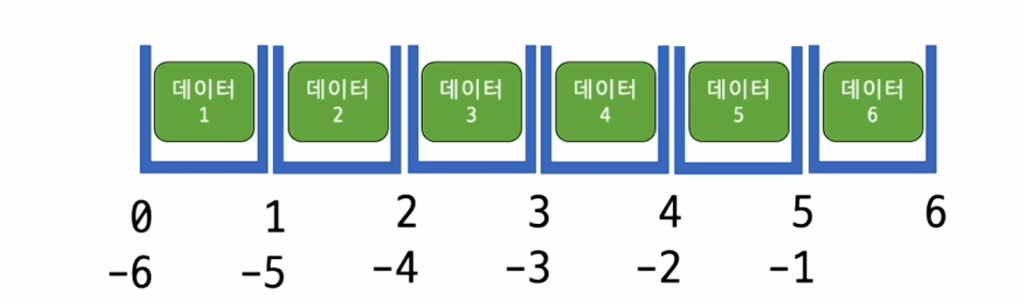
집합 자료형 (set)
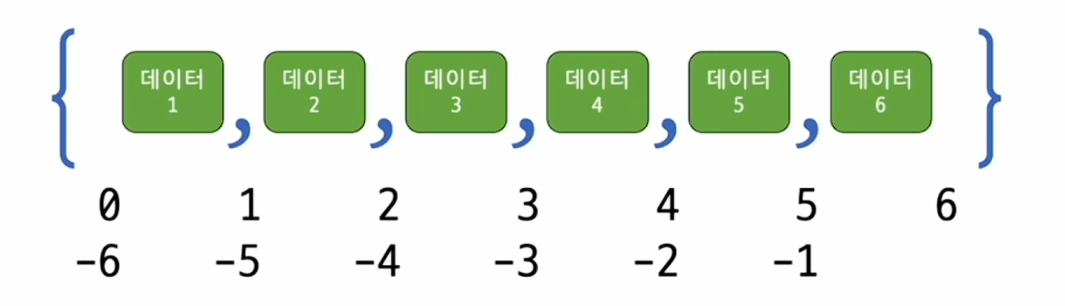
- 순서에 상관없이 중복을 제거하는 자료형
- 집합 자료형은 중복을 자동제거 한다
- 집합은 입력된 순서는 중요하지 않는다
- set() 생성자 함수 또는 {}를 이용해서 만들 수 있다
- 원소는 hashable 이어야 한다 (리스트는 원소로 추가할 수 없다)
집합의 특징
- 중복을 자동 제거한다
- 입력 순서가 유지되지 않는다
set1 = {1, 0, 2, 3, 3} print(set1, type(set1))출력 : {0, 1, 2, 3} <class 'set'>set2 = {3, 2, 1, ("a", "b"), ("a", "b")} print(set2, type(set2))출력 : {1, 2, 3 ('a', 'b')} <class 'set'>
집합 만들기
set1 = {1, 2, 3, 3, 0} print(set1, type(set1))출력 : {0, 1, 2, 3} <class 'set'>set2 = {3, 2, 1 ("a", "b"), ("a", "b")} print(set2, type(set2))출력 : {1, 2, 3 ('a', 'b')} <class 'set'>set3 = set({1, 2, 3}) print(set3, type(set3))출력 : {1, 2, 3} <class 'set'>set4 = set([1, 2, 3]) print(set4, type(set4))출력 : {1, 2, 3} <class 'set'>
집합의 기본 메소드
- add(추가할 원소) : 집합에 원소 추가
- update(추가할 원소들) : 집합에 여러 원소들 한번에 추가
- remove(삭제할 원소) : 집합에 원소를 삭제
- copy() : 집합 데이터 복사
- clear() : 모든 집합 원소들 삭제
set1 = set() print(set1, type(set1))출력 : set() <class 'set'>for i in range(5) : set1.add(i) print(set1)출력 : {0, 1, 2, 3, 4}set1.add('a') set1.add('문자열') set1.add(34.6) print(set1)출력 : {0, 1, 2, 3, 4, '문자열', 34.6, 'a'}set1.update({11, 22, 33}) print(set1)출력 : {0, 1, 2, 3, 4, '문자열', 34.6, 33, 11, 22, 'a'}set1.remove(0) set1.remove(2) print(set1)출력 : {1, 3, 4, '문자열', 34.6, 33, 11, 22, 'a'}set2 = set1.copy() print(set2, type(set2))출력 : {1, 34.6, 3, 4, '문자열', 33, 11, 22, 'a'} <class 'set'>set2.clear() print(set2)출력 : set()
set1 = set({1, 2}) print(set1, type(set1))출력 : {1, 2} <class 'set'>튜플은 원소로 추가 할 수 있다
set1.add((1, 2)) # 튜플은 hashable하기 때문에 들어 갈 수 있다. print(set1)출력 : {1, 2 (1, 2)}리스트는 원소로 추가 할 수 없다
set1 = set() set1.add([0, 1])
집합 자료형을 이용하여 리스트에 중복 원소들 제거하기
- 리스트의 순서가 중요하지 않을 경우
- 리스트의 모든 원소가 hashble일 경우
list1 = [0, 1, 2, 3, 1, 5, 4, 0, 1, "a", "b", "a"] list1 = list(set(list1)) print(list1, type(list1))출력 : [0, 1, 2, 3, 4, 5, 'b', a] <class 'list'>
- 집합을 이용하여 중복 여부 확인 (반복문을 활용하여 중복을 찾아내는 거)
nodes = [1, 2, 3, 1, 4, 2, 5] visited = set()for n in nodes: if n in visited: print("already visited", n) else: visited.add(n) print("new", n)출력 : new 1 출력 : new 2 출력 : new 3 출력 : already visited 1 출력 : new 4 출력 : already visited 2 출려 : new 5
- 합집합, 교집합, 차집합
set1 = {1, 2, 3, 4, 5, 6} set2 = {3, 4, 5, 6, 7, 8}합집합
set3 = set1 | set2 print("합집합 : ", set3)출력 - 합집합 : {1, 2, 3, 4, 5, 6, 7, 8}set4 = set1.union(set2) print("합집합 : ", set4)출력 - 합집합 : {1, 2, 3, 4, 5, 6, 7, 8}교집합
set5 = set1 & set2 print("교집합 : ", set5)출력 - 교집합 : {3, 4, 5, 6}set6 = set1.intersection(set2) print("교집합 : ", set6)출력 - 교집합 : {3, 4, 5, 6}차집합
set7 = set1 - set2 print("차집합 : ", set7)출력 - 합집합 : {1, 2}et8 = set1.difference(set2) print("차집합 : ", set8)출력 - 합집합 : {1, 2}*_update() method를 사용하면 원래의 set가 바뀐다. 결과 값은 None 이므로 주의해야 한다.
set9 = set1.difference_update(set2) # set1을 봐야함. print("set1 : ", set1) print("set9 : ", set9)출력 - set1 : {1, 2} 출력 - None
사전 자료형 (dict)
- 사전 자료형은 "키(Key)/값(Value)" 쌍을 요소로 갖는 자료형
- 흔히 Map 이라고도 불림
- 키(Key)로 신속하게 값(Value)을 찾아내는 해시테이블(Hash Table) 구조
- 사전의 키(key)는 그 값을 변경할 수 없는 Immutable 타입이어야 한다
- 사전은 dict() 생성자를 사용하거나 { }를 사용하여 만들 수 있다
- 3.5 이전 버전에서는 입력 순서 유지를 보장하지 않는다
사전 데이터 초기화
방법1
dict1 = {} dict1["name"] = "홍길동" dict1["age"] = 24 dict1["phone"] = "010-1234-5678" print(dict1, type(dict1))출력 : {'name' : '홍길동', 'age' : 24, 'phone' : '010-1234-5678'} <class 'dict'>방법2
dict2 = {"name": "홍길동", "age": 24, "phone": "010-1234-5678"} print(dict2, type(dict2))출력 : {'name' : '홍길동', 'age' : 24, 'phone' : '010-1234-5678'} <class 'dict'>방법3
dict3 = dict(name="홍길동", age=24, phone="010-1234-5678") print(dict2, type(dict3))출력 : {'name' : '홍길동', 'age' : 24, 'phone' : '010-1234-5678'} <class 'dict'>
사전 데이터 사용
- 하나의 key 값을 가져올 때
dict1 = {"name" : "홍길동", "age" : 24, "phone" : "010-1234-5678"} print(dict1["name"]) print(dict1["age"]) print(dict1["phone"])출력 : 홍길동 출력 : 24 출력 : 010-1234-5678key 값이 존재하지 않으면 에러가 발생
print(dict1["address"])
- key 값이 없을 때 default 값 리턴하기
dict1 = {"name" : "홍길동", "age": 24, "phone" : "010-1234-5678"} print(dict1.get("name", "이름 없슴")) print(dict1.get("address", "주소 없슴")) # default 값으로 주소 없음출력 : 홍길동 출력 : 주소 없음
- 하나의 key 값을 수정 할 때
dict1 = {"name" : "홍길동", "age" : 24, "phone" : "010-1234-5678"} dict1["phone"] = "010-1234-1234" dict1["age"] += 1 print(dict1)출력 : {'name' : '홍길동', 'age' : 24, 'phone' : '010-1234-1234'}
- 새로운 아이템을 추가 할 때
dict1 = {"name" : "홍길동", "age" : 24, "phone" : "010-1234-5678"} dict1["address"] = "서울시 영동대로 12" print(dict1)출력 : {'name' : "홍길동', 'age' : 25, 'phone' : '010-1234-5678', 'address' : '서울시 영동대로 12'}
- 여러 요소를 동시에 업데이트 할 때
dict1 = {"name" : "홍길동", "age" : 24, "phone" : "010-1234-5678"} dict1.update({"age":25, "address": "서울시 영동대로 12"}) print(dict1)출력 : {'name' : "홍길동', 'age' : 25, 'phone' : '010-1234-5678', 'address' : '서울시 영동대로 12'}
- 반복문(for)으로 사전 데이터 사용 하기
반복문
for key in dict1.keys(): print(key)출력 : name 출력 : age 출력 : phone값 반복
for value in dict1.values(): print(value)출력 : 홍길동 출력 : 24 출력 : 010-1234-5678(key,value)쌍 얻기
for key, value in dict1.items(): print(key, ':', value)출력 - name : 홍길동 출력 - age : 24 출력 - phone : 010-1234-5678
- 사전의 요소 삭제
dict1 = {"name" : "홍길동", "age" : 24, "phone" : "010-1234-5678"} del dict1["phone"] print(dict1)출력 : {'name' : '홍길동', 'age' : 24}

현재 : C# WPF 개발자 / 목표 : AI 의료 영상 분석 연구원