시계열 데이터 분석
- 시계열 데이터란 시간별로 계측하고 나열한 데이터를 말한다. 흔히 보는 주식시세나 월별 매출, 일자별 기온 등은 모두 같은 방식으로 기록한 데이터를 시간순으로 나열한 시계열 데이터이다.
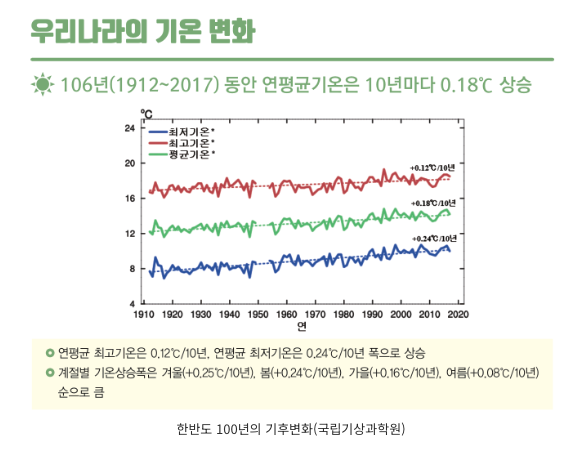
시계열 데이터의 특징 3가지
일상에서 흔하게 접하는 데이터기 때문에 이미 다들 알고있지만, 시계열 데이터의 특징은 Trend(추세), Seasonality(계절성), Cycle(주기성) 3가지로 크게 나눌 수 있다.
첫번째, 추세(Trend)는 말그대로 방향성을 나타낸다. 지구 온난화 현상으로 인한 평균기온 변화, 의학기술 발달로 인한 기대수명 연장 등 데이터가 관측되는 환경 자체가 변화하면 방향성에 영향를 주게 된다.
두번째는 계절성(Seasonality)으로 지구와 인간사회에서 발생하는 수 많은 데이터가 계절의 영향을 받는다. 하지만 여기서 계절성이란 단지 봄, 여름, 가을, 겨울만 말하는 것이 아니라 계절처럼 일정 기간 동안 반복된 패턴을 보이는 것을 계절성으로 통칭한다. 매월 초에 반복적으로 거래가 증가하거나 매년 추석에만 판매가 늘어나는 현상은 모두 계절성으로 분류된다.
세번째, 계절성처럼 일정하게 반복되진 않지만 더 장기적으로 싸이클을 가진다면 주기성(Cycle)으로 분류한다. 인플레이션과 경제 성장 등의 싸이클이 주기성에 해당한다.
시계열 분해 알고리즘
시계열 예측 알고리즘으로 바로 넘어가 보는 것도 좋지만, 시계열 예측 시 발생할 수 있는 실수를 줄이고 시계열 데이터의 특성을 좀 더 쉽게 이해할 수 있는 시계열 분해 알고리즘을 먼저 알아보려고 한다.
시계열 분해란 시계열 데이터를 앞서 알아본 3가지 특성으로 분류해주는 방법으로 결과가 매우 직관적이라 이해하기 쉽고, 분석결과를 바로 써먹을 수 있을 뿐 아니라 시계열 예측 시 사전 탐색이나 모델 개선을 목적으로 활용할 수 있다.
10년간 월별 배추가격 데이터
자, 이제 이러한 요인들을 seasonal_decompose 알고리즘을 이용해 정량화해보자. 우선 구글 코랩에 배추 가격 데이터를 업로드 한 후 아래의 코드를 이용해서 X변수에 데이터를 등록해준다.
import pandas as pd
X = pd.read_csv('seasonal_decompose.csv')그리고 다음과 같이 3줄을 입력해주면 바로 시계열 분류 결과를 볼 수 있다.
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(X.price, model='addictive', period=12)
result.plot()첫번째줄은 seasonal_decompose라는 시계열 분류 알고리즘을 호출하는 문장으로 그대로 복사하면 된다.
두번째줄은 함수를 실행하는 부분으로 총 3개의 인자로 구성되어있다. 첫번째 인자는 데이터로 price라는 컬럼명을 지정하였다. 두번째 인자는 분류 방법으로 보통 addictive를 그대로 사용한다. 마지막 세번째 인자 Period는 데이터의 계절성 주기를 말하며 월별데이터는 12(개월), 주별데이터는 7(일)을 입력한다.
세번째줄은 result에 저장한 분석결과에 plot()을 실행하는 보여주는 것으로 아래와 같은 차트가 표시된다.
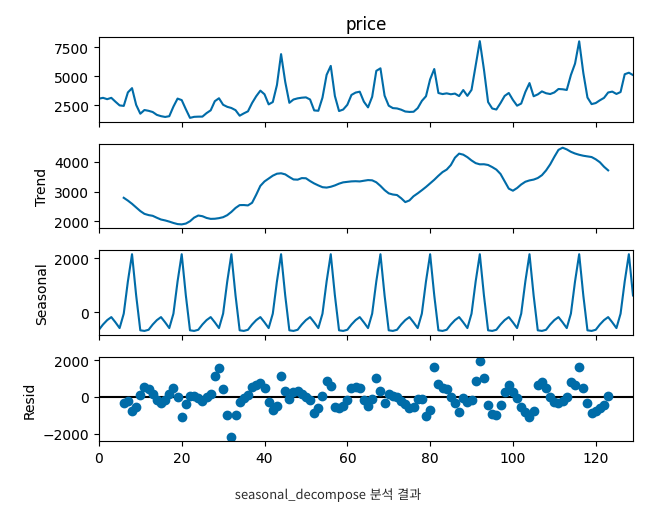
맨 윗줄은 입력했던 데이터이고 순서대로 Trend(추세) / Seasonal(계절성) / Residual(나머지값)으로 분해되었으며, 모두 더해주기만 하면 원래의 차트가 완성된다.
차트를 해석해보면 배추값은 2천원부터 4천원까지 등락하고 있지만 상승추세이며, 매년 -500원에서 +2천원정도의 계절적 요인을 가지고 있다. 그리고 2가지 요인을 제외하고 -2천~+2천정도의 변동성을 가지고 있다.
※차트에 표기된 실제값을 추출하고자 한다면, Result.seasonal / .resid / .trend를 입력하면 월별 값을 확인할 수 있다.
추세와 나머지 값의 변동폭이 커서 아주 만족스러운 결과는 아니지만, 규칙성을 가지고 있으며 계절성은 일정수준을 유지하기 때문에 각 값을 활용하면 좀 더 정확한 월별 배추값을 예측할 수 있다.
※ 예) Trend값의 월 평균 상승률 + 전년 동기 Seasonal값 + 최근 1년간 Resid평균 값
시계열 데이터 예측 방식
시계열 예측은 이러한 요소들을 조합하여 최적화 된 예측값을 계산하는 알고리즘으로 데이터에 따라 단일 값(단변량)을 이용하는 예측하는 방법과 같은 시기에 측정된 여러 데이터(다변량)을 활용하는 방식으로 나눌 수 있다.
단일 값을 이용한 예측 방식은 앞서 알아본 배추값의 사례처럼 월별 배추값으로 추세와 계절성 등을 분해하고 이를 조합하여 예측하는 방식으로 진행된다. 이는 결국 과거 자신의 값에서 규칙성을 발견하여 미래를 예측하는 방식이라 볼 수 있다. 그러나 여러 데이터를 이용한 시계열 예측 방법은 과거 자신의 값 뿐만 아니라 해당 값에 영향을 주는 값들도 예측에 활용한다.
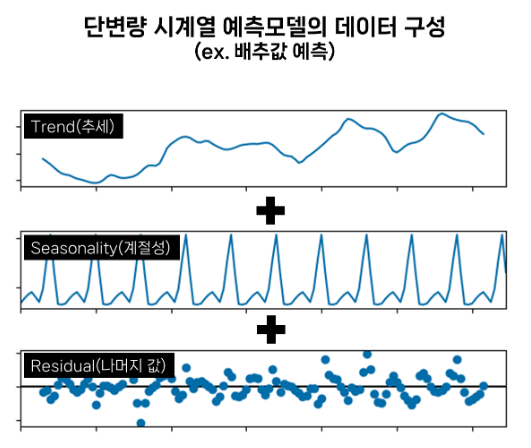
이해를 돕기 위해 모델 데이터 구성방법을 그림으로 표현하면 다음과 같다. 먼저, 단변량 시계열 예측은 예측하려는 데이터의 과거 패턴과 추세, 변동성을 적절하게 더하여 최적값을 찾아내는 방식이다.
그리고, 다변량 시계열 예측모델은 단변량에서 사용했던 추세와 패턴에 동일 시기에 관측한 데이터와의 상관관계를 추가하여 시계열을 예측한다.
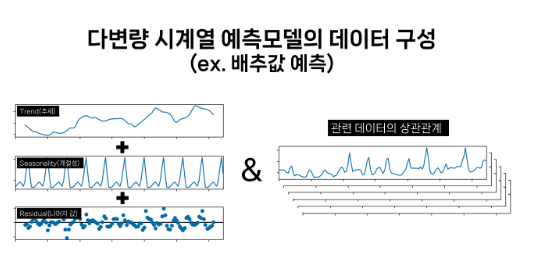
배추값을 예측할 경우 같은 시기의 배추가격에 영향을 줄만한 시계열 데이터를 같이 사용한다면 예측하려는 시기에 앞서 관련 데이터들이 먼저 영향을 줄테니 예측 결과가 좀 더 정확하게 나타날 것이다.
단변량 시계열 예측하는 방법
시계열 예측은 전통적인 ARIMA부터, 금융에서 많이 사용하는 GARCH, 딥러닝 방식의 RNN/LSTM 등 다양한 알고리즘이 있지만, 각각 파라미터에 따라 결과가 크게 바뀌는 경향이 있어 충분히 경험해보지 않으면 활용하기 쉽지 않다.
이번 포스트에서 사용하려는 알고리즘은 페이스북(현 메타)에서 발표한 딥러닝 방식으로 개발한 것으로 예언자라는 이름을 가진 Neural Prophet다. 이 알고리즘은 다른 알고리즘들과 달리 파라미터를 조절하지 않아도 뛰어난 성능을 보여준다는 장점을 가지고 있다.
우선, 시계열분류에서 사용했던 10년간의 월별 배추 값 데이터를 이용하여 단변량 시계열 예측을 시험해보자. Neural Prophet 을 이용할 때는 데이터의 컬럼명을 날짜는 ds, 그리고 예측하려는 변수는 y라고 이름으로 바꿔줘야한다.
예측 성능을 검증하기 위해 최근 5개월치(23.6~10월)를 삭제하고 코랩에 업로드 후 아래 코드를 이용해 X변수에 데이터를 할당한다.
import pandas as pd
X = pd.read_csv('napa_cabbage_10year_train.csv')코랩은 사용하려는 라이브러리가 설치되어 있지 않을 경우 !pip명령어를 이용해서 추가로 설치할 수 있는데, 보통 라이브러리명만 기재하면 되지만, 최신버전에 오류가 있어 아래처럼 다운받을 라이브러리가 위치한 주소를 기재하여 설치한다.
!pip install git+https://github.com/ourownstory/neural_prophet.git이제, 시계열 예측 모델을 만들어보자.
from neuralprophet import NeuralProphet
model = NeuralProphet()
metrics = model.fit(X, freq="MS")첫줄에서 라이브러리를 호출하고, 두번째줄에 라이브러리를 model이라는 이름으로 지정한다. 그리고 마지막 세번째줄에 업로드한 데이터 X, 그리고 월별 데이터라는 의미의 파라미터 freq="MS"를 입력해주면 된다.
(freq세팅시 월:MS / 일:D / 시간:H를 이용한다.)
이제 생성한 모델을 이용하여 원하는 기간만큼 예측을 해보자. 아래 2줄의 코드를 입력하면 된다.
future = model.make_future_dataframe(X, periods=5)
forecast = model.predict(future)첫번째줄은 데이터X의 형태를 참고하여 5개의 기간(periods)에 해당하는 데이터를 생성하는 코드이며, 두번째줄은 먼저 생성한 모델을 이용해 데이터에 예측값을 추가하는 명령어이다.
이렇게 하면 forecast라는 변수에 추가한 5개월간의 예측값이 yhat1이라는 컬럼으로 생성된다.
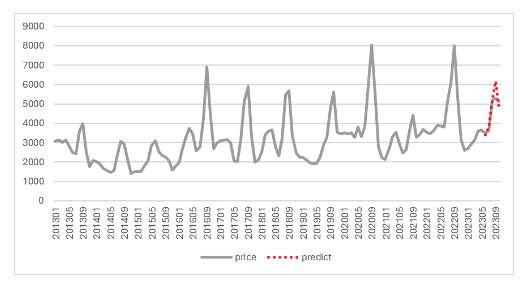
yhat1값을 복사하여 원본데이터에 추가해준 후 차트를 그려보니 위와 같은 그래프가 생성되었다. 대부분은 실제값이 가격이 일치하여 훌륭한 예측성능을 보여주었지만, 가격이 급등하는 9월의 실제 배추 값은 5,309원으로 예측값 6,182원보다 낮게 나온 것을 알 수 있다.
다변량 시계열 예측하는 방법
수입 김치와 수입 배추에 대한 데이터를 추가하여 테스트
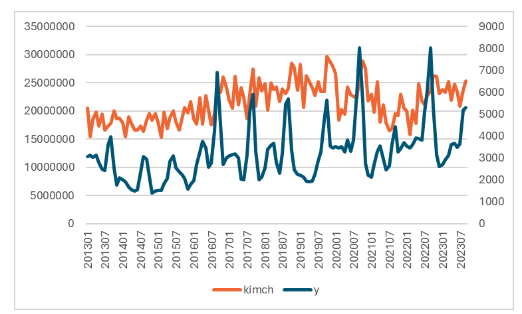
우선 수입김치(중량)와 배추 가격에 대한 월별 차트를 살펴보자. 월별 변동폭은 다르지만 2016년부터 2020년까지는 수입김치의 수입량이 이전보다 증가하였고, 같은 시기에 배추값도 상승한 것을 보면 어느정도 상관관계가 있는 것처럼 보인다. 이후 수입량과 가격이 같이 감소했지만 작년 9월에는 또 다시 치솟았다.
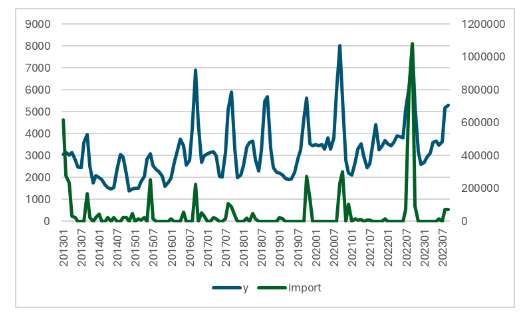
다음으로는 배추 수입현황이다. 배추는 수입량이 전혀 없는 달도 많아 물량을 조절하는 것으로 보이는데, 이 역시 배추값이 상승했을 때는 덩달아 오르는 경향을 보이고 있다.
김치와 배추사입량이 추가된 데이터를 코랩에 업로드하고 X변수에 할당한다.
import pandas as pd
X = pd.read_csv('napa_cabbage_10year_multi.csv')다변량 시계열분석에서는 예측에 사용되는 데이터를 지정해줘야하는데, 2번째줄에 파라미터가 추가되었으며 3번째 줄이 추가된다.
from neuralprophet import NeuralProphet
model = NeuralProphet(n_forecasts=5, n_lags=1)
model = model.add_lagged_regressor(names=['kimch', 'import'])
metrics = model.fit(X, freq="MS")두번째줄에서 n_forecasts=5는 향후 5개의 값을 예측한다는 의미로 다변량에서는 모델 설정 시 지정해줘야 한다. 그리고 n_lags=1은 1달 전의 데이터를 참고하여 예측한다는 의미로 이 또한 다변량 예측에서는 미리 지정해줘야한다. 만약 n_lags를 2로 바꾼다면 2달전의 데이터를 참고하여 예측하는 것이며 보통은 1로 설정해두면 된다.
세번째줄은 kimch(김치 수입량)와 import(배추 수입량)데이터를 예측 시 추가하는 코드로 변수가 늘어날 경우 이 부분을 수정해주면 된다.
future = model.make_future_dataframe(X)
forecast = model.predict(future)예측하려는 기간은 모델 개발 시 설정했으므로 make_futre_dataframe에서 예측하려는 기간을 입력하는 periods를 삭제하고 코드를 입력하면 아래와 같은 결과를 얻을 수 있다.
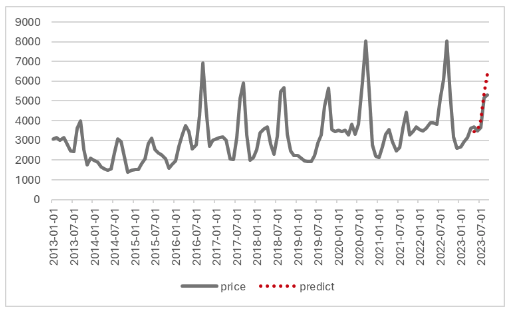
9월의 실제 배추 값은 5,309원으로 예측 값은 6,395원으로 단변량 예측 시보다 오차가 크게 나타났다. 예측결과가 좋아지지 않은 걸 보면 김치와 배추의 수입량이 시계열 예측에는 크게 도움이 되지 않거나 방법을 바꿔 볼 필요가 있어 보인다.
